

基于金字塔的激光雷达和摄像头深度融合网络
描述
摘要
自动驾驶汽车的鲁棒环境感知是一项巨大的挑战,这使得多传感器配置与例如相机、激光雷达和雷达至关重要。在理解传感器数据的过程中,3D 语义分割起着重要的作用。因此,本文提出了一种基于金字塔的激光雷达和摄像头深度融合网络,以改进交通场景下的 3D 语义分割。单个传感器主干提取相机图像和激光雷达点云的特征图。一种新颖的 Pyramid Fusion Backbone 融合了这些不同尺度的特征图,并将多模态特征组合在一个特征金字塔中,以计算有价值的多模态、多尺度特征。Pyramid Fusion Head 聚合这些金字塔特征,并结合传感器主干的特征在后期融合步骤中进一步细化。该方法在两个具有挑战性的户外数据集上进行了评估,并研究了不同的融合策略和设置。论文基于range view的lidar方法已经超过迄今为止提出的所有融合策略和结构。 论文的主要贡献如下:
模块化多尺度深度融合架构,由传感器主干和新颖的金字塔融合网络组成;
金字塔融合主干用于激光雷达和图像在range view空间中的多尺度特征融合;
金字塔融合头用于聚合和细化多模态、多尺度的金字塔特征。
相关工作
2D语义分割
全卷积网络(FCN)开创了2D语义分割的新局面。全卷积网络专为端到端像素级预测而设计,因为它们用卷积替换全连接层。由于最初的 FCN 难以捕捉场景的全局上下文信息 [7],因此出现了新的结构 [7]-[9] — 基于金字塔特征进行多尺度上下文聚合,在收集全局上下文的同时保留精细细节。PSPNet [7] 应用了一个金字塔池化模块(PPM),其结合最后一个特征图的不同尺度。因此,网络能够捕获场景的上下文以及精细的细节。HRNetV2 [9] 等其他方法利用主干中已经存在的金字塔特征进行特征提取。对于全景分割的相关任务,EfficientPS [8] 通过应用双向特征金字塔网络 (FPN) [10],自底向上和自顶向下结合各种尺度的特征,之后使用语义头,包含大规模特征提取器 (LSFE)、密集预测单元 (DPC) [11] 和不匹配校正模块 (MC),以捕获用于语义分割的大尺度和小尺度特征。
3D语义分割
与将 CNN 应用于规则网格排列的图像数据相比,它们不能直接应用于 3D 点云。目前得到广泛应用的已经有几种表示形式和专门的体系结构。 直接处理非结构化原始数据的先驱方法是 PointNet [3],它应用共享的多层感知器来提取每个输入点云的特征。由于必须对任何输入排列保持不变,因此使用对称操作来聚合特征。进一步PointNet++ [4] 通过点云的递归分层组合来利用特征之间的空间关系。 不处理原始点云而将其转换为离散空间的方法,例如 2D 或 3D 栅格。一种基于球面投影的新颖的2D栅格表示,即range view。SqueezeSeg [12] 是最早利用这种表示进行道路目标分割的方法之一。最新的方法 SqueezeSegV3 [13] 使用空间自适应卷积来消除range view的变化特征分布。RangeNet++ [1] 提出了一种有效的基于 kNN 的后处理步骤,以克服球面投影引起的一些缺点。与以前的方法相比,SalsaNext [2] 改进了网络结构的各个方面,例如用于解码的pixel-shuffle和 Lovasz-Softmax-Loss [14] 的使用。[15]中使用了卷积的另一种适应,这种方法应用轻量级harmonic dense卷积来实时处理range view,并取得了不错的结果。此外,出现了利用多种表示的混合方法 [16]、[17]。
3D 多传感器融合
多传感器融合在计算机视觉的不同任务中受到广泛关注。相机和激光雷达功能的结合主要用于 3D 目标检测。语义分割等密集预测所需的特征的密集融合只有少数工作[18]-[21]进行了研究。 在 [18] 中,将基于密集和roi的融合应用于多个任务,包括 3D 目标检测。另一种 3D 目标检测方法 [19] 使用连续卷积来结合密集相机和激光雷达的BEV特征。融合层将多尺度图像特征与网络中不同尺度的激光雷达特征图融合在一起。 LaserNet++ [20] 实现目标检测和语义分割两个任务。其首先通过残差网络处理相机图像。使用投影映射,将相机特征转换为range view。之后,concat的特征图被输入到 LaserNet [22]。Fusion3DSeg [21] 对相机和激光雷达特征使用迭代融合策略。在 Fusion3DSeg 中,相机和range view特征按照迭代深度聚合策略进行融合,以迭代融合多尺度特征。最终特征进一步与来自 3D 分支的基于点云的特征相结合,而不是常用的基于 kNN 的后处理 [1]特征。 与 [18] 相比,[19] 所提出的方法是模块化的,并且各个传感器主干彼此独立,因为没有图像特征被送到激光雷达主干。此外,[19]提出了一种新颖的双向金字塔融合策略。而 LaserNet++ [22] 只融合一次,不使用多尺度融合。Fusion3DSeg [21] 是最相关的工作,使用了迭代融合策略,这与本文的并行自底向上和自顶向下的金字塔策略有很大不同。
方法
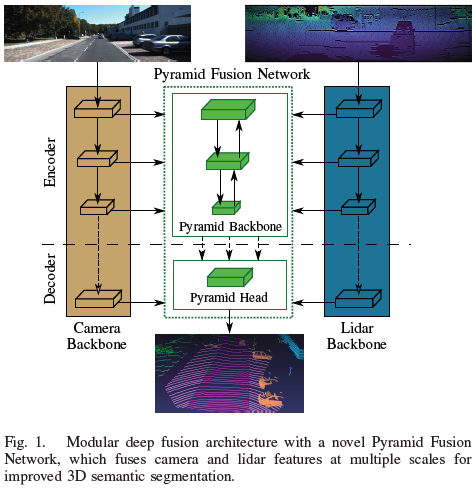
论文提出的深度传感器融合方法PyFu由四个主要部分组成。包含两个主干,分别提取lidar和图像特征,之后是Pyramid Fusion Backbone,以自顶向下和自底向上的方式在不同尺度上融合两种模式的编码器特征。进一步,Pyramid Fusion Head 结合了这些特征,并在后期融合步骤中将它们与两个传感器主干特征结合起来得到最终输出。整体结构如下图a所示。模块化的方式训练策略的选择允许论文的方法处理相机不可用、更换主干或传感器而不影响另一个,并联合预测相机和激光雷达语义分割任务。因此,两个主干都对其传感器数据进行了预训练,并在整个融合架构的训练过程中冻结。所以论文的算法可以预测单个传感器的语义结果,作为无相机或额外相机分割的备选。
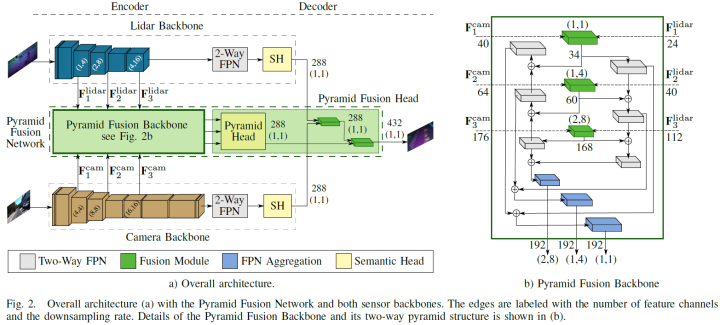
Lidar主干
激光雷达主干根据 [21]、[23] 的球面投影计算输入点云的特征,这些特征在range view中表示。其受 EfficientPS [8] 的启发,并适应了range view。与相机图像相比,range images的分辨率较小,尤其是垂直方向,因此前两个stage的下采样步骤仅在水平方向执行。此外,论文使用 EfficientNet-B1 [24] 作为编码器并删除最后三个stage。因此,双向 FPN 只有三个stage而不是四个stage,并且输出通道减少到 128 个,因为 EfficientNet-B1 使用的特征通道比 EfficientNet-B5 少。如上图 a 所示,第三、第四和第六stage的特征图输入至 Pyramid Fusion Backbone中,用于与相机特征融合。由于移除了 FPN,相应的 DPC 模块 [8] 也从语义头中移除。头部为 Pyramid Fusion Head 的后期融合提供其输出特征。
Camera主干
论文研究的第一个主干还是 EfficientPS,但使用原始的 Efficient-B5 作为编码器。与激光雷达主干相比,EfficientPS 可以直接作为相机主干。同样,第三、第四和第六stage的特征图输入至 Pyramid Fusion Backbone。对于 Pyramid Fusion Head 中的后融合步骤,使用语义头的输出。 此外,选择基于ResNet101 [25] 的 PSPNet 作为另一个主干。ResNet101 的 conv3_4、conv4_23 和 conv5_3 层的三个特征图作为 Pyramid Fusion Backbone 的输入提供。PPM 的输出作为后期融合的输入。
金字塔融合网络
融合算法的核心模块是 Pyramid Fusion Network,其融合了激光雷达和相机的特征。融合模块将特征转换至同一空间下,然后对两种模态进行融合。Pyramid Fusion Backbone 在不同尺度下进行融合,并且以自顶向下和自底向上的方式聚合和组合得到的融合特征,如上图 b 所示。Pyramid Fusion Head 在后期融合步骤中对这些多模态、多尺度特征进行组合和进一步细化。
特征转换
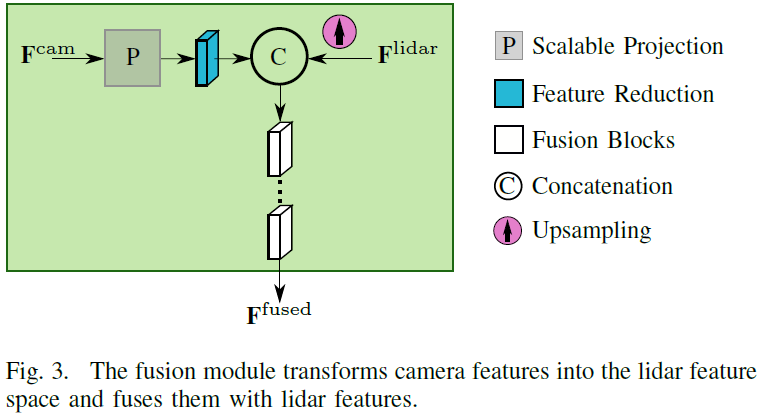
为了实现激光雷达和摄像头的融合,特征需要在同一空间下。因此,需要进行图像到range view空间的特征投影。此外,投影必须适合不同尺度的特征图。为了解决这个任务,论文使用了Fusion3DSeg [21]、[26] 的可扩展投影。总体思路是根据3D点云创建从图像到range view的坐标映射。每个点云都可以投影到range view以及图像中,从而在图像和range view坐标之间创建所需的链接。
融合模块
特征转换和融合由融合模块执行,如下图。首先,两个传感器的特征图都被裁剪至相同的视野,因为融合只能在这个区域进行。图像特征通过上述特征转换在空间上转换到range view空间上,然后学习特征投影以对齐激光雷达和图像的特征空间,由一个反向残差块 (IRB) [8] 实现。lidar特征使用双线性插值对齐图像特征的大小,以方便进行融合。然后将对齐后的两个特征concat,后面使用一个或多个用于学习融合的残差模块。该模块旨在利用不同类型和数量的block来实现不同的融合策略。论文研究了一种基于Bottleneck Residual Block (BRB) [27] 的策略,以及使用 IRB (Inverted Residual Block )的反向残差融合策略。
金字塔融合主干
所提出的融合模块被合并到双向 FPN 中以融合不同尺度的多传感器特征,然后是自底向上和自顶向下的聚合以计算多模态、多尺度特征。从激光雷达主干中,三种不同尺度的特征输入至对应的融合模块。在那里,特征图被上采样到目标输出分辨率,并与来自图像主干的特征图融合,这些特征图也来自三个不同的尺度。然后将融合得到的三个特征图聚合在自底向上和自顶向下的特征金字塔中,以计算多尺度特征。这样,不同尺度的多模态特征的进行融合,一方面是精细的细节,包含越来越多的上下文,另一方面是上下文,添加的细节越来越多。最终组合两个金字塔输出,并将生成的多模态、多尺度金字塔特征传递给 Pyramid Fusion Head。
金字塔融合head
head的第一步类似于激光雷达主干的语义head,其结合了来自双向 FPN 的三个特征图。进一步,论文使用图像主干和lidar主干的最后一层特征,以改进金字塔融合网络的特征。最终的特征图接一个 1x1 卷积和softmax,得到分割结果。论文也使用了基于 kNN 的后处理 [1]步骤。
实验结果
本文在SemanticKITTI [28] and PandaSet [29]两个数据集上展开实验。
金字塔融合网络
论文首先在SemanticKITTI上展开实验,结果如下表所示。总体而言,PyFu 的性能分别优于两个基线 +3.9% 和 +2.7%,推理时间为 48 毫秒。
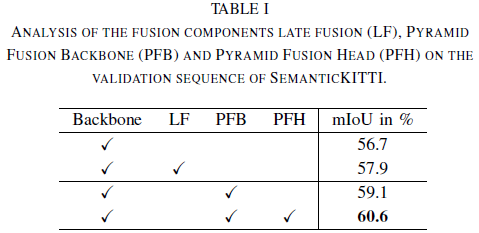
下一步,研究融合模块内部的不同融合策略,结果如下表所示。首先,评估不同策略对金字塔主干 PFB 的影响。使用 BRB 后跟Residual Basic Block (BB) [27] 的bottleneck fusion策略优于IRB 的反向策略。这也适用于整个 Pyramid Fusion Network。
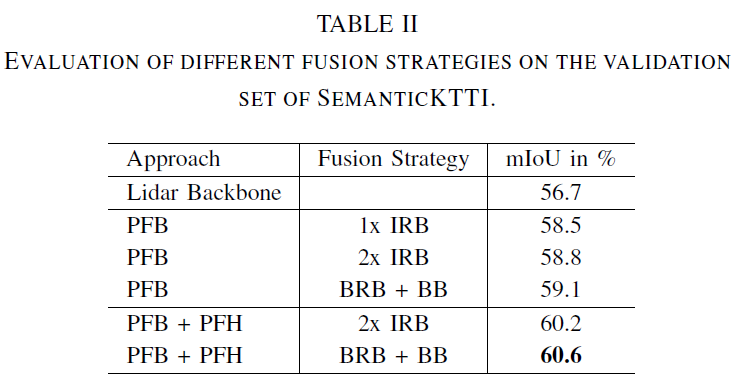
论文进一步在PandaSet上展开实验,相比于基线实现了+8.8% 的显著改进。
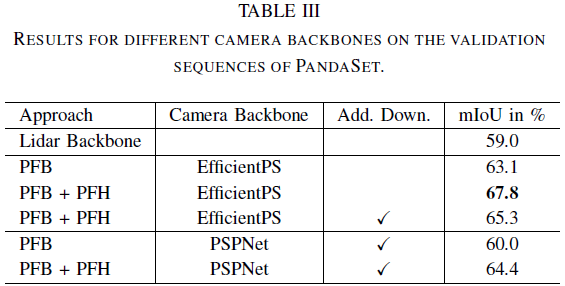
可视化结果如下:

定量结果
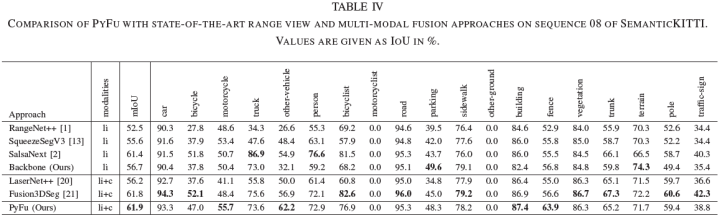
进一步,论文与SOTA的基于range view的方法进行比较,以评估多传感器融合的优势,SemanticKITTI上的结果如下表所示。总体上优于所有激光雷达方法。值得一提的是,增益的主要来自融合,而不是基线。这再次强调了图像特征对改进 3D 语义分割的价值。论文进一步比较了与其他融合网络的性能。金字塔融合策略优于所有其他融合方法,PyFu 和 Fusion3DSeg [21] 的性能优势表明多尺度传感器融合的巨大潜力。
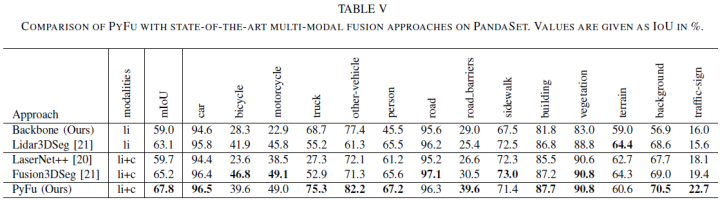
最后,论文在PandaSet数据集上对比了集中方法,结果如下表所示:
审核编辑:郭婷
-
无人驾驶技术中的激光雷达和摄像头都干些什么?2016-12-07 19212
-
自制for循环打印金字塔2016-09-18 6135
-
速腾聚创激光雷达现在实现量产2017-08-21 3535
-
浅析自动驾驶发展趋势,激光雷达是未来?2017-09-06 5540
-
激光雷达是自动驾驶不可或缺的传感器2017-09-08 5358
-
基于深度神经网络的激光雷达物体识别系统2021-12-21 3934
-
绘制金字塔程序实现2017-11-27 1117
-
一种金字塔注意力网络,用于处理图像语义分割问题2018-06-05 13215
-
英特尔实感激光雷达深度摄像头L515解析2020-09-21 18748
-
如何实现多聚焦图像融合的拉普拉斯金字塔方法2021-02-03 1110
-
基于规范化函数的深度金字塔模型算法2021-03-30 1199
-
激光雷达、单目摄像头、双目摄像头原理和优缺点2022-03-26 18794
-
详解无人驾驶传感器:摄像头、激光雷达、雷达、温度传感器2023-12-07 2888
-
激光雷达烧坏摄像头?2023-11-30 2674
-
京瓷发布全球首款“摄像头-激光雷达”融合传感器2025-01-20 2121
全部0条评论

快来发表一下你的评论吧 !
