

基于训练阶段使用知识库+KNN检索相关信息辅助学习方法
描述
在prompt learning中一个核心问题是模型存在死记硬背现象。Prompt learnin主要应用在few-shot learning场景,先将训练数据转换成prompt的形式,在训练过程模型侧重于记忆训练数据,然后使用记忆的信息做预测。这个过程会导致模型缺乏泛化能力,一些长尾的case预测效果不好。
NIPS 2022中浙大和阿里提出使用检索方法增强prompt learning,利用训练数据构造知识库,在训练阶段使用知识库+KNN检索相关信息辅助学习,通过这种方式将需要记忆的信息从模型中拆分出来,直接输入到模型中。通过这种方式,可以让模型参数更侧重泛化信息的学习,而不是过拟合训练数据。下面为大家详细介绍一下这篇工作。
NLP Prompt系列——Prompt Engineering方法详细梳理
1 Prompt Learning回顾
Prompt learning主要面向的是训练数据较少的场景。首先需要一个预训练模型,然后将下游任务转换成完形填空的形式。对于分类问题,判断某个text属于哪个label,转换成如下的文本输入到预训练语言模型中:
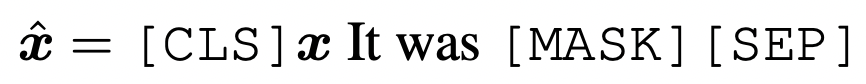
利用预训练语言模型,预测出[MASK]对应的文本,后面接一个文本到label的映射函数,即可实现文本分类任务。Prompt learning的好处是可以充分利用预训练语言模型的知识,让下游任务和预训练任务更加适配,以提升样本量不足情况下的效果。我在之前的文章NLP Prompt系列——Prompt Engineering方法详细梳理详细介绍过prompt相关工作,感兴趣的同学可以进一步阅读。
虽然这种方法充分运用了预训练语言模型的知识,但毕竟finetune的数据少,模型更像在死记硬背训练prompt数据中的信息。这对于长尾样本或非典型的句子的预测效果不友好。为了解决上述问题,本文的核心思路是,如果我们把这些需要记忆的信息单独拿出来存储到一个知识库中,在需要的时候检索它们并作为模型额外输入,就能让模型参数没必要再死记硬背这些信息了,从而实现记忆和泛化更好的平衡,有点【好记性不如烂笔头】的感觉。下图是本文提出的基本框架示意图。
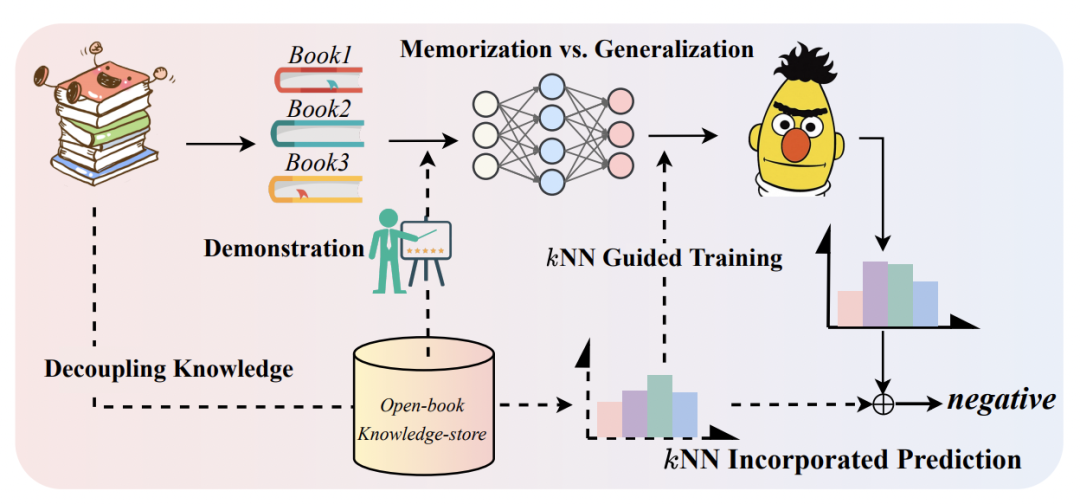
2 从知识库中检索信息
实现上面的框架核心是从知识库中检索信息,这也就涉及到两个问题,一个是如何构造知识库,另一个是如何进行信息检索和利用。
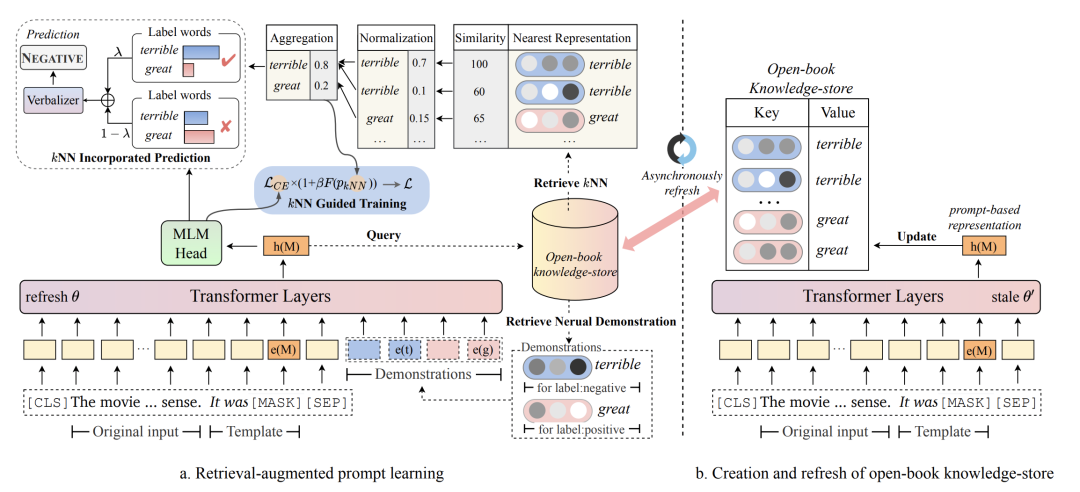
在知识库的构造上,文中构造的是一个{K, V}格式的数据,训练集中的每条样本对应一个{K, V}。K代表这个样本的prompt输入模型后[MASK]位置的隐向量,V代表这个样本的label对应的单词。由于K是模型输出的向量,因此每训练几轮,就会动态更新知识库中的Key,避免Key和模型最新参数隔代太多不匹配。
在信息检索和利用上,对于当前样本模型先得到其[MASK]位置的向量,然后用这个向量在知识库中进行KNN检索,每个类别的样本都取出topK个,检索的距离度量是向量内积。对于每个类别检索出的向量,使用内积做softmax后进行加权融合,得到这个类别最终向量,拼接到当前样本embedding后面输入到模型中:
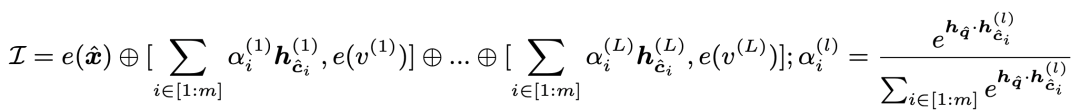
这部分检索出来的样本就是将需要记忆的知识直接引入到了当前样本中,不再需要模型参数去记忆了。此外,这种将向量引入而不是引入对应的token,可以让信息的扩展更方便,直接引入样本的token会拉长输入样本长度,导致模型性能下降,且长度也有上限。
3 使用KNN指导模型训练和预测
上面收的引入知识库+KNN的方法,缓解了模型参数需要强记忆训练样本的问题。此外,文中还通过KNN检索结果来指导模型的学习过程。KNN检索的好处是不需要模型训练,直接根据预训练的表示计算距离,利用邻居样本的label,就能预测当前样本的label。这对于模型来说是另一个维度的信息补充,文中通过区分难样本指导训练和在inference阶段指导预测两个方面进一步指导模型的训练和预测。
KNN的检索结果可以用来区分难样本和简单样本。通过KNN检索以及检索邻居的label,可以得到当前样本各个类别的预测概率。这个KNN的预测结果可以作为是否是难样本的参考,如果模型预测预测结果和KNN结果不一致,就是难样本。对于难样本,加大其学习权重,通过将KNN预测概率引入到交叉熵损失中实现:
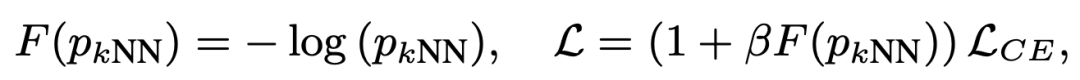
另一方面,在预测阶段,也直接将KNN的预测结果拿出来和模型对于[MASK]的预测结果做插值,得到最终的预测结果:
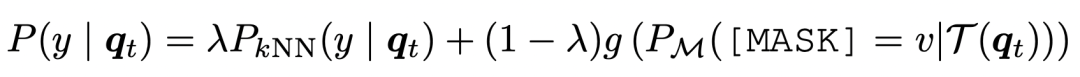
4 实验结果
文中在9个NLU数据集的few-shot和zero-shot learning上对比了效果,可以看到本文提出的方法对于效果的提升还是非常明显的。
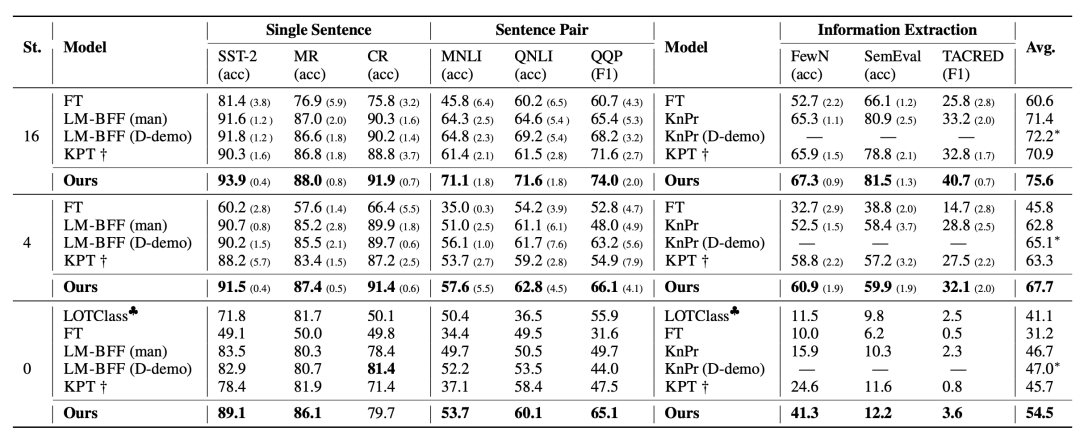
此外,文中也对比了跨领域的效果,在source domain进行prompt learning,对比在target domain上的效果:
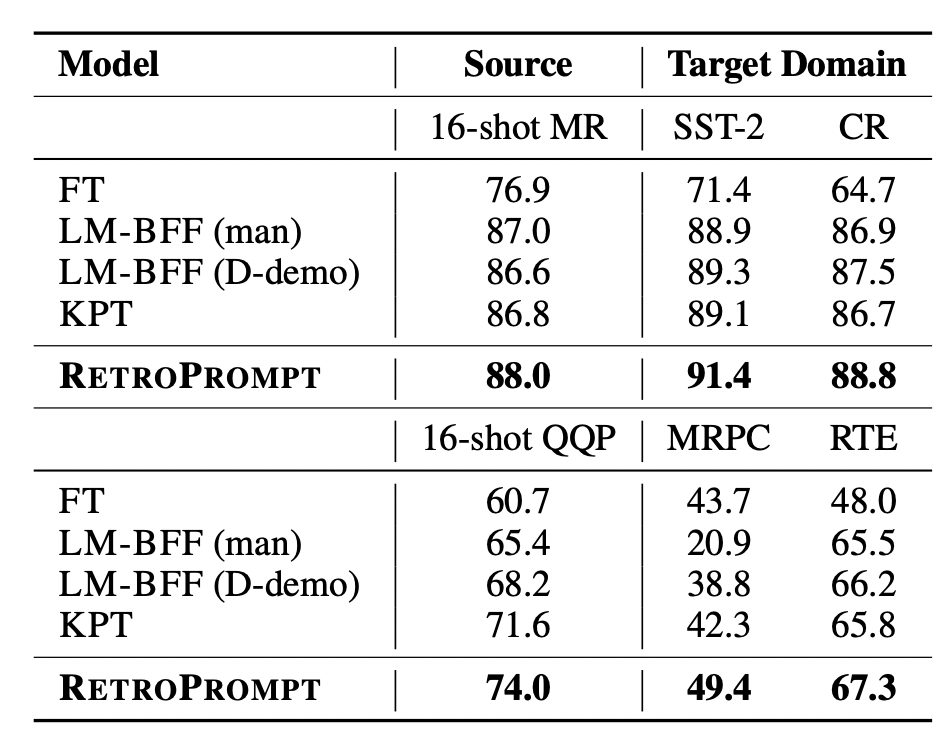
5 总结
检索在NLP各类任务中的应用越来越多,本文也将检索用于分离可记忆的信息来提升模型的泛化能力,并取得了显著效果。检索通过信息记忆+查询的方式,引入了丰富的外部信息,能够让模型更多的容量服务于学习泛化性,而非简单的记住训练数据。
-
鸿蒙智能体开发知识库---创建知识库2026-03-06 278
-
《AI Agent 应用与项目实战》阅读心得3——RAG架构与部署本地知识库2025-03-07 1677
-
如何手撸一个自有知识库的RAG系统2024-06-17 1787
-
无监督域自适应场景:基于检索增强的情境学习实现知识迁移2023-12-05 1748
-
如何基于亚马逊云科技LLM相关工具打造知识库2023-11-23 2334
-
使用KNN进行分类和回归2022-10-28 3751
-
复杂知识库问答任务的典型挑战和解决方案2021-06-13 3521
-
面向异质信息的网络表示学习方法综述2021-06-09 988
-
学习STM32必备的知识库2019-04-01 4554
-
本体知识库的模块与保守扩充2017-11-24 913
-
NXP NFC知识库2016-12-30 1291
-
领域知识库的研究与设计2011-08-29 739
-
一种基于解释的知识库综合2009-05-07 914
-
基于知识库的智能策略翻译技术2009-04-22 1187
全部0条评论

快来发表一下你的评论吧 !
