

ElasticSearch是什么?应用场景是什么?
电子说
描述
1、什么是搜索
2、如果用数据库做搜索会怎么样
3、什么是全文检索、倒排索引和Lucene
4、ElasticSearch是什么
ElasticSearch的功能
ElasticSearch的应用场景
ElasticSearch的特点
ElasticSearch是一个分布式,高性能、高可用、可伸缩的搜索和分析系统
看了上面这段话,估计很多人都懵了,这个是啥。我们先从搜索说起,先介绍下面几点
1、什么是搜索
百度、Google :我们想寻找一个我们喜欢的电影或者书籍就会去百度或者Google搜索一下。
互联网搜索 :电商搜索商品,招聘网站搜索简历或者岗位
IT系统的搜索 :员工管理搜索,会议管理搜索
2、如果用数据库做搜索会怎么样
在软件开发里面,数据都是存储在数据库里面的,比如电商网站的商品信息,员工的信息等等,如果从员工角度去做搜索功能,我们会这么设计

以上会存在几个问题:
如果表记录上千万上亿了这个性能问题,另外一个如果有一个本文字段要在里面模糊配置,这个就会出现严重的性能问题
还不能将搜索词拆分开来,比如上面这个只能搜索名字是“张三”开头的员工,如果想搜出“张小三”那是搜索不出来的。
总体来说,用数据库来实现搜索,是不太靠谱的,通常性能也会很差
3、什么是全文检索、倒排索引和Lucene
举个简单的例子:比如最近上映的热剧(碟中谍6:全面瓦解),我们想搜索一下全面瓦解这个电视剧,可是在输入的过程,不小心输入了”全瓦解”,我们看看百度这个返回了什么,百度返回的结果确实是我想要找到的内容,现在我们介绍一下全文检索和倒排索引是什么
我们看看下面这个图,假如我们有很多数据”全面瓦解电影,全面瓦解海报,全面瓦解评论,全面瓦解文章”等等信息,从数据到构建倒排索引的过程我们图中标记为“1”,通俗一点讲就是,倒排索引就是讲数据中的词拆分构建一个大表,将关键字拆出来,后面带上这个文章的documentid号,例如中间这个就是倒排索引了。
全文检索就比较好理解的,就是当我们输入“全瓦解”,会被拆分成”全”,“瓦解”2个此,用2个词去倒排索引里面去检索数据,检索到的数据返回。整个过程就叫做全文检索

如果这个用数据库的思维来做的话,假如一共100W的记录,按照之前的思路就是扫描100W次,而且每次扫描,都需要匹配那个文本所有的字符,确认是否包含搜索的关键词,而且还不能将搜索词拆解来进行检索
如果是利用倒排索引的话,假设还是100W,拆分出来的词语,假设有1000W个词语,那么在倒排索引中,就有1000W行。我们可能不需要检索1000W词,有可能检索1次,就能找到我们需要的数据,也有可能是100W次,也有可能是1000W次
lucene:就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候
4、ElasticSearch是什么
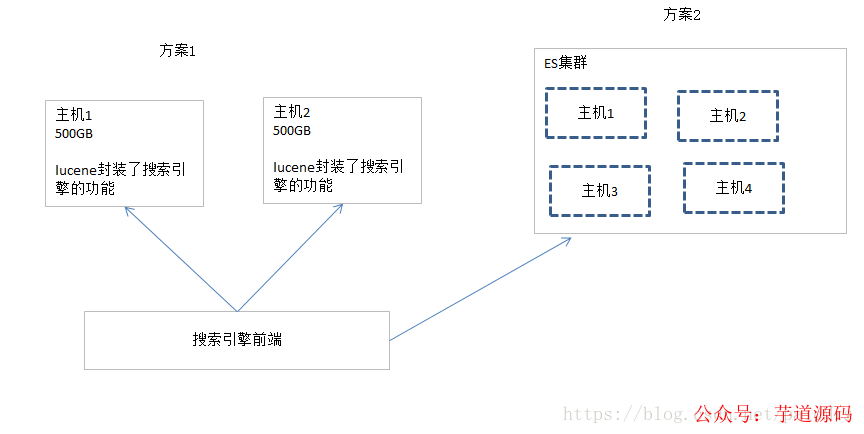
Lucene是单机的模式,如果你的数据量超过了一台物理机的容量,你需要扩容,将数据拆分成2份放在不同的集群,这个就是典型的分布式计算了。需要拷贝容错,机器宕机,数据一致性等复杂的场景,这个实现就比较复杂了。
ES解决了这些问题
自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行
自动维护数据的冗余副本,保证了一旦机器宕机,不会丢失数据
封装了更多高级的功能,例如聚合分析的功能,基于地理位置的搜索
ElasticSearch的功能
1、分布式的搜索引擎和数据分析引擎
搜索:网站的站内搜索,IT系统的检索
数据分析:电商网站,统计销售排名前10的商家
2、全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含某个关键字的商品
结构化检索:我想搜索商品分类为日化用品的商品都有哪些
数据分析:我们分析每一个商品分类下有多少个商品
3、对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
海联数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索数据要花费1小时(这就不要近实时,离线批处理,batch-processing);在秒级别对数据进行搜索和分析
ElasticSearch的应用场景
维基百科
The Guardian(国外新闻网站)
Stack Overflow(国外的程序异常讨论论坛)
GitHub(开源代码管理)
电商网站
日志数据分析
商品价格监控网站
BI系统
站内搜索
ElasticSearch的特点
可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起
对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES
Elasticsearch作为传统数据库的一个补充,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;
- 相关推荐
- 热点推荐
- JAVA
- 数据库
- Elasticsearch
-
Windows安装ElasticSearch2023-02-15 1857
-
CW32L083有哪些应用场景?2025-11-24 249
-
Switch的应用场景2025-12-12 273
-
MOS管的应用场景2018-11-14 6569
-
this的使用场景及与C,Java中的this的区别2019-03-11 1902
-
ElasticSearch的初步环境2020-03-31 1558
-
=>的使用场景有哪些2020-10-27 1761
-
运放电路有哪些应用场景?2021-03-11 3212
-
蓝牙低功耗常见的应用场景及架构2021-06-15 2376
-
FPGA的应用场景2021-07-28 1958
-
ARM的技术特征是什么?应用场景有哪些?2021-11-05 3609
-
MS9331的应用场景是什么?2022-02-11 2131
-
RK3308的特点及应用场景是什么?2022-03-09 2152
-
labview 和 wincc 的区别 使用场景2023-10-27 5658
-
Elasticsearch保姆级入门2023-09-01 1773
全部0条评论

快来发表一下你的评论吧 !
