

基于COCO的预训练模型mAP对应关系
描述
torchvision对象检测介绍
Pytorch1.11版本以上支持Torchvision高版本支持以下对象检测模型的迁移学习:
- Faster-RCNN - Mask-RCNN - FCOS - RetinaNet - SSD - KeyPointsRCNN其中基于COCO的预训练模型mAP对应关系如下:
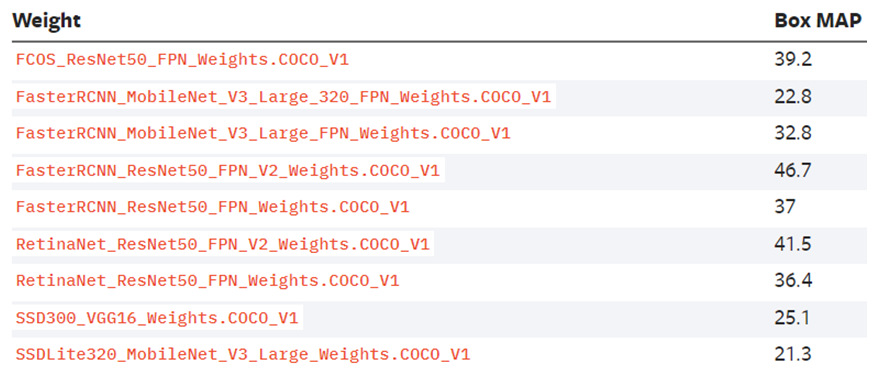


最近一段时间本人已经全部亲测,都可以转换为ONNX格式模型,都可以支持ONNXRUNTIME框架的Python版本与C++版本推理,本文以RetinaNet为例,演示了从模型下载到导出ONNX格式,然后基于ONNXRUNTIME推理的整个流程。
RetinaNet转ONNX
把模型转换为ONNX格式,Pytorch是原生支持的,只需要把通过torch.onnx.export接口,填上相关的参数,然后直接运行就可以生成ONNX模型文件。相关的转换代码如下:
model = tv.models.detection.retinanet_resnet50_fpn(pretrained=True)
dummy_input = torch.randn(1, 3, 1333, 800)
model.eval()
model(dummy_input)
im = torch.zeros(1, 3, 1333, 800).to("cpu")
torch.onnx.export(model, im,
"retinanet_resnet50_fpn.onnx",
verbose=False,
opset_version=11,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input': {0: 'batch', 2: 'height', 3: 'width'}}
)
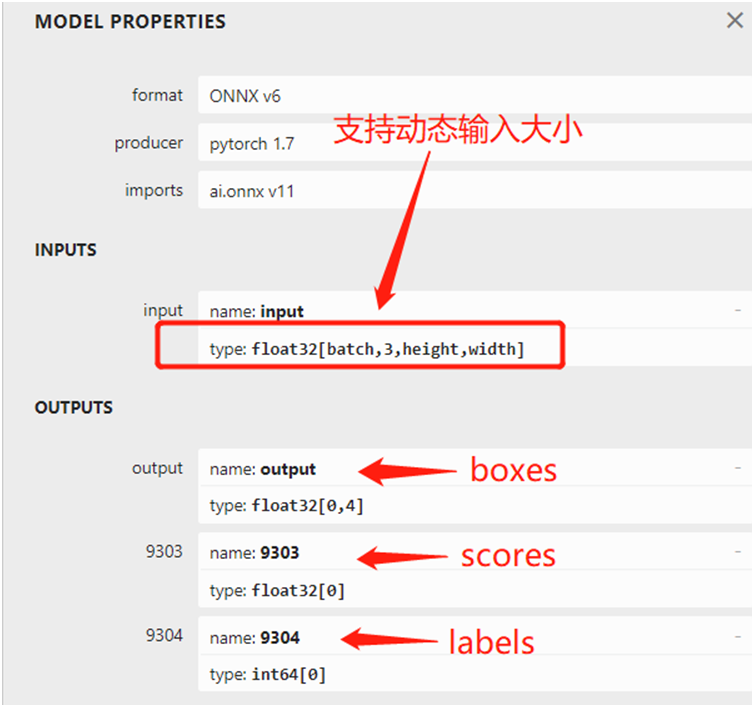
运行时候控制台会有一系列的警告输出,但是绝对不影响模型转换,影响不影响精度我还没做个仔细的对比。 模型转换之后,可以直接查看模型的输入与输出结构,图示如下:
RetinaNet的ONNX格式推理
基于Python版本的ONNXRUNTIME完成推理演示,这个跟我之前写过一篇文章Faster-RCNN的ONNX推理演示非常相似,大概是去年写的,链接在这里: 代码很简单,只有三十几行,Python就是方便使用,这里最需要注意的是输入图像的预处理必须是RGB格式,需要归一化到0~1之间。对得到的三个输出层分别解析,就可以获取到坐标(boxes里面包含的实际坐标,无需转换),推理部分的代码如下:
import onnxruntime as ort
import cv2 as cv
import numpy as np
import torchvision
coco_names = {'0': 'background', '1': 'person', '2': 'bicycle', '3': 'car', '4': 'motorcycle', '5': 'airplane', '6': 'bus',
'7': 'train', '8': 'truck', '9': 'boat', '10': 'traffic light', '11': 'fire hydrant', '13': 'stop sign',
'14': 'parking meter', '15': 'bench', '16': 'bird', '17': 'cat', '18': 'dog', '19': 'horse', '20': 'sheep',
'21': 'cow', '22': 'elephant', '23': 'bear', '24': 'zebra', '25': 'giraffe', '27': 'backpack',
'28': 'umbrella', '31': 'handbag', '32': 'tie', '33': 'suitcase', '34': 'frisbee', '35': 'skis',
'36': 'snowboard', '37': 'sports ball', '38': 'kite', '39': 'baseball bat', '40': 'baseball glove',
'41': 'skateboard', '42': 'surfboard', '43': 'tennis racket', '44': 'bottle', '46': 'wine glass',
'47': 'cup', '48': 'fork', '49': 'knife', '50': 'spoon', '51': 'bowl', '52': 'banana', '53': 'apple',
'54': 'sandwich', '55': 'orange', '56': 'broccoli', '57': 'carrot', '58': 'hot dog', '59': 'pizza',
'60': 'donut', '61': 'cake', '62': 'chair', '63': 'couch', '64': 'potted plant', '65': 'bed',
'67': 'dining table', '70': 'toilet', '72': 'tv', '73': 'laptop', '74': 'mouse', '75': 'remote',
'76': 'keyboard', '77': 'cell phone', '78': 'microwave', '79': 'oven', '80': 'toaster', '81': 'sink',
'82': 'refrigerator', '84': 'book', '85': 'clock', '86': 'vase', '87': 'scissors', '88': 'teddybear',
'89': 'hair drier', '90': 'toothbrush'}
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
sess_options = ort.SessionOptions()
src = cv.imread("D:/images/mmc.png")
cv.namedWindow("Retina-Net Detection Demo", cv.WINDOW_AUTOSIZE)
image = cv.cvtColor(src, cv.COLOR_BGR2RGB)
blob = transform(image)
c, h, w = blob.shape
input_x = blob.view(1, c, h, w)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(input_x)}
ort_outs = ort_session.run(None, ort_inputs)
# (N,4) dimensional array containing the absolute bounding-box
boxes = ort_outs[0]
scores = ort_outs[1]
labels = ort_outs[2]
print(boxes.shape, boxes.dtype, labels.shape, labels.dtype, scores.shape, scores.dtype)
index = 0
for x1, y1, x2, y2 in boxes:
if scores[index] > 0.65:
cv.rectangle(src, (np.int32(x1), np.int32(y1)),
(np.int32(x2), np.int32(y2)), (140, 199, 0), 2, 8, 0)
label_id = labels[index]
label_txt = coco_names[str(label_id)]
cv.putText(src, label_txt, (np.int32(x1), np.int32(y1)), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 1)
index += 1
cv.imshow("Retina-Net Detection Demo", src)
cv.imwrite("D:/mmc_result.png", src)
cv.waitKey(0)
cv.destroyAllWindows()
审核编辑:彭静
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
基于不同量级预训练数据的RoBERTa模型分析2023-03-03 2903
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1507
-
在不使用任何额外数据的情况下,COCO数据集上物体检测结果为50.9 AP的方法2018-11-24 9278
-
小米在预训练模型的探索与优化2020-12-31 3939
-
基于预训练模型和长短期记忆网络的深度学习模型2021-04-20 1360
-
2021 OPPO开发者大会:NLP预训练大模型2021-10-27 2249
-
如何实现更绿色、经济的NLP预训练模型迁移2022-03-21 3064
-
Multilingual多语言预训练语言模型的套路2022-05-05 4190
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2463
-
利用视觉语言模型对检测器进行预训练2022-08-08 2349
-
使用 NVIDIA TAO 工具套件和预训练模型加快 AI 开发2022-12-15 2100
-
什么是预训练 AI 模型?2023-04-04 2578
-
什么是预训练AI模型?2023-05-25 2071
-
预训练模型的基本原理和应用2024-07-03 5944
-
大语言模型的预训练2024-07-11 1823
全部0条评论

快来发表一下你的评论吧 !
