

使用FasterTransformer和Triton推理服务器部署GPT-J和T5
描述
这是关于 NVIDIA 工具的两部分系列的第二部分,这些工具允许您运行大型Transformer模型以加速推理。
简介
这篇文章是大型Transformer模型(例如 EleutherAI 的 GPT-J 6B 和 Google 的 T5-3B)的优化推理指南。这两种模型在许多下游任务中都表现出良好的效果,并且是研究人员和数据科学家最常用的模型之一。
NVIDIA Triton 中的 NVIDIA FasterTransformer (FT) 允许您以类似且简单的方式运行这两个模型,同时提供足够的灵活性来集成/组合其他推理或训练管道。相同的 NVIDIA 软件堆栈可用于在多个节点上结合张量并行 (TP) 和管道并行 (PP) 技术来推断万亿参数模型。
Transformer模型越来越多地用于众多领域,并表现出出色的准确性。更重要的是,模型的大小直接影响其质量。除了 NLP,这也适用于其他领域。
来自谷歌的研究人员证明,基于转换器的文本编码器的缩放对于他们的 Imagen 模型中的整个图像生成管道至关重要,这是最新的也是最有前途的生成文本到图像模型之一。缩放转换器可以在单域和多域管道中产生出色的结果。本指南使用相同结构和相似尺寸的基于Transformer的模型。
主要步骤概述
本节介绍使用 FasterTransformer 和 Triton 推理服务器在优化推理中运行 T5 和 GPT-J 的主要步骤。 下图展示了一个神经网络的整个过程。
您可以使用 GitHub 上的逐步快速transformer_backend notebook 重现所有步骤。
强烈建议在 Docker 容器中执行所有步骤以重现结果。 有关准备 FasterTransformer Docker 容器的说明可在同一notebook 的开头找到。
如果您已经预训练了其中一个模型,则必须将框架保存模型文件中的权重转换为 FT 可识别的二进制格式。 FasterTransformer 存储库中提供了转换脚本。
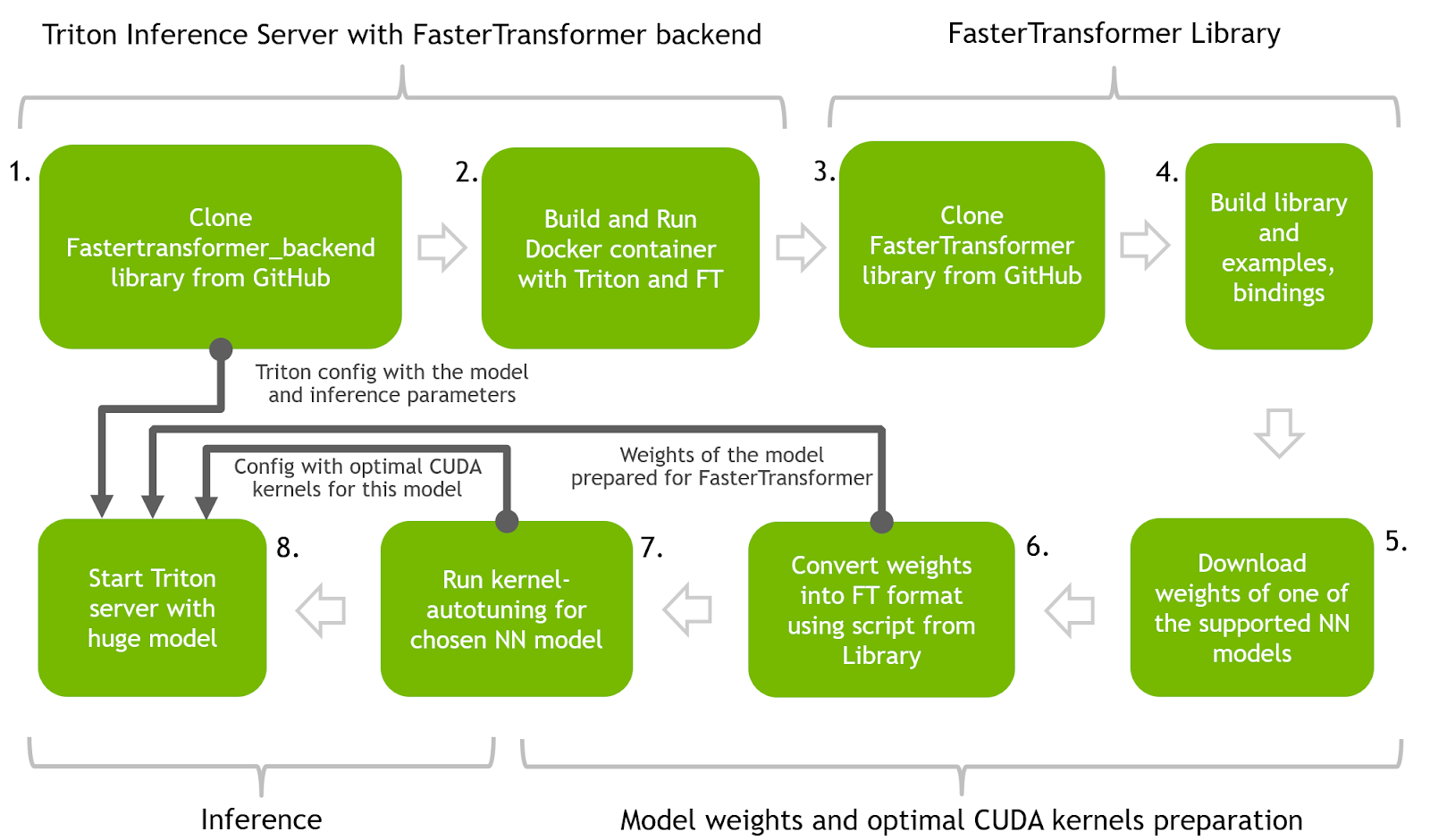
图 1.具有 FasterTransformer 和 Triton ®声波风廓线仪的 transformer 神经网络的整体管道
步骤 1 和 2 :使用 Triton 推理服务器和 FasterTransformer 后端构建 Docker 容器。 使用 Triton 推理服务器作为向 FasterTransformer 后端代理请求的主要服务工具。
步骤 3 和 4 :构建 FasterTransformer 库。 该库包含许多用于推理准备的有用工具以及多种语言的绑定以及如何在 C++ 和 Python 中进行推理的示例。
步骤 5 和 6 :下载预训练模型(T5-3B 和 GPT-J)的权重,并通过将它们转换为二进制格式并将它们拆分为多个分区以实现并行性和加速推理,为使用 FT 进行推理做好准备。 此步骤中将使用 FasterTransformer 库中的代码。
步骤 7 :使用 FasterTransformer 库中的代码为 NN 找到最佳的低级内核。
步骤 8 :启动 Triton 服务器,该服务器使用前面步骤中的所有工件并运行 Python 客户端代码以向具有加速模型的服务器发送请求
步骤 1 :从 Triton GitHub 存储库中克隆 fastertransformer_backend
克隆 fastertransformer_backend GitHub 的回购协议:
git clone https://github.com/triton-inference-server/fastertransformer_backend.git
cd fastertransformer_backend && git checkout -b t5_gptj_blog remotes/origin/dev/t5_gptj_blog
步骤 2 :使用 Triton 和 FasterTransformer 库构建 Docker 容器
使用以下文件构建 Docker 映像:
docker build --rm --build-arg TRITON_VERSION=22.03 -t triton_with_ft:22.03 \ -f docker/Dockerfile .
cd ../
运行 Docker 容器并使用以下代码启动交互式 bash 会话:
docker run -it --rm --gpus=all --shm-size=4G -v $(pwd):/ft_workspace \ -p 8888:8888 triton_with_ft:22.03 bash
所有进一步的步骤都需要在 Docker 容器交互式会话中运行。这个容器中还需要 Jupyter Lab 来处理提供的笔记本。
apt install jupyter-lab && jupyter lab -ip 0.0.0.0
Docker 容器是用 Triton 和 FasterTransformer 构建的,并从内部的 FasterTransformer _ backend 源代码开始。
步骤 3 和 4 :克隆 FasterTransformer 源代码并构建库
FasterTransformer 库是预先构建的,并在 Docker 构建过程中放入我们的容器中。
从 GitHub 下载 FasterTransformer 源代码,使用额外的脚本,将 GPT-J 或 T5 的预先训练的模型文件转换为 FT 二进制格式,在推断时使用。
git clone https://github.com/NVIDIA/FasterTransformer.git
该库能够在以后运行内核自动调谐代码:
mkdir -p FasterTransformer/build && cd FasterTransformer/build
git submodule init && git submodule update
cmake -DSM=xx -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON ..
make -j32
GPT-J 推理
GPT-J 是由 EleutherAI 开发的解码器模型,并在 The Pile 上进行了训练,该数据集是从多个来源策划的 825GB 数据集。 GPT-J 拥有 60 亿个参数,是最大的类似 GPT 的公开发布模型之一。
FasterTransformer 后端在 fasttransformer_backend/all_models/gptj 下有一个 GPT-J 模型的配置。这个配置是 Triton 合奏的完美演示。 Triton 允许您运行单个模型推理,以及构建包含推理任务所需的许多模型的复杂管道/管道。
您还可以在任何神经网络之前或之后添加额外的 Python/C++ 脚本,用于可以将您的数据/结果转换为最终形式的预处理/后处理步骤。
GPT-J 推理管道在服务器端包括三个不同的顺序步骤:
预处理 -》 FasterTransformer -》 后处理
配置文件将所有三个阶段组合到一个管道中。下图说明了客户端-服务器推理方案。
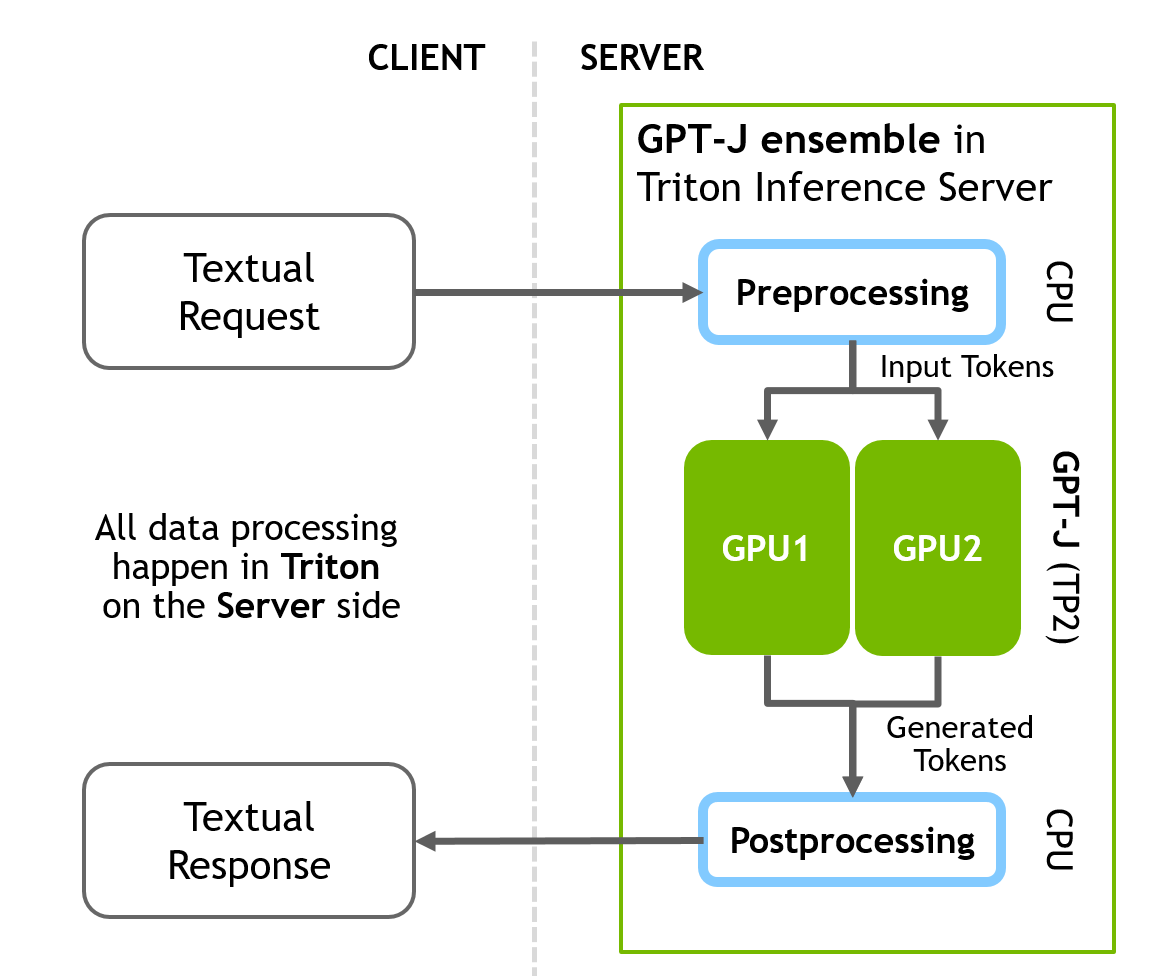
图 2.FasterTransformer 和 Triton ®声波风廓线仪的 GPT-J 推断。集成方案,所有预处理和后处理步骤都发生在服务器端
步骤 5-8 对于 GPT-J 和 T5 都是相同的,如下所示( GPT 先, T5 后)。
步骤 5 ( GPT-J ):下载并准备 GPT-J 模型的权重
wget https://mystic.the-eye.eu/public/AI/GPT-J-6B/step_383500_slim.tar.zstd
tar -axf step_383500_slim.tar.zstd -C ./models/
这些权重需要转换为 C++ FasterTransformer 后端识别的二进制格式。 FasterTransformer 为不同的预训练神经网络提供工具/脚本。
对于 GPT-J 权重,您可以使用以下脚本:
FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py将检查点转换如下:
步骤 6 ( GPT-J ):将权重转换为 FT 格式
python3 ./FasterTransformer/examples/pytorch/gptj/utils/gptj_ckpt_convert.py \ --output-dir ./models/j6b_ckpt \ --ckpt-dir ./step_383500/ \ --n-inference-gpus 2
n-inference-gpus指定张量并行的 GPU 数量。该脚本将创建。/ models / j6b _ ckpt / 2- GPU 目录,并在那里自动写入准备好的权重。这些权重将为张量平行 2 推断做好准备。使用此参数,您可以将权重拆分为更大数量的 GPU ,以使用 TP 技术实现更高的速度。
步骤 7 ( GPT-J ):用于 GPT-J 推理的内核自动调谐
下一步是内核自动调整。 矩阵乘法是基于Transformer的神经网络中主要和最繁重的操作。 FT 使用来自 CuBLAS 和 CuTLASS 库的功能来执行此类操作。 需要注意的是,MatMul 操作可以在“硬件”级别使用不同的低级算法以数十种不同的方式执行。
FasterTransformer 库有一个脚本,允许对所有低级算法进行实时基准测试,并为模型的参数(注意层的大小、注意头的数量、隐藏层的大小)和 你的输入数据。 此步骤是可选的,但可以实现更高的推理速度。
运行在构建 FasterTransformer 库阶段构建的 。/FasterTransformer/build/bin/gpt_gemm 二进制文件。 脚本的参数可以在 GitHub 的文档中找到,或者使用 –help 参数。
./FasterTransformer/build/bin/gpt_gemm 8 1 32 12 128 6144 51200 1 2
步骤 8 ( GPT-J ):准备 Triton 配置并为模型服务
权重就绪后,下一步是为 GPT-J 模型准备 Triton 配置文件。在 fastertransformer _ backend / all _ models / gptj / fasterTransormer / config 打开 GPT-J 模型的主 Triton 配置。用于编辑的 pbtxt 。只有两个强制参数需要在那里更改才能开始推断。
更新 tensor _ para _ size 。为两个 GPU 准备了权重,因此将其设置为 2 。
parameters { key: "tensor_para_size" value: { string_value: "2" }
}
更新上一步中检查点文件夹的路径:
parameters { key: "model_checkpoint_path" value: { string_value: "./models/j6b_ckpt/2-gpu/" }
}
现在使用 Triton 后端和 GPT-J 启动 Parabricks 推理服务器:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver --model-repository=./triton-model-store/gptj/ &
如果 Triton 成功启动,您将看到输出线,通知模型由 Parabricks 加载,并且服务器正在监听指定端口的传入请求:
# Info about T5 model that was found by the Triton in our directory: +-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+ # Info about that Triton successfully started and waiting for HTTP/GRPC requests: I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002
接下来,将推断请求发送到服务器。在客户端, tritonclient Python 库允许从任何 Python 应用程序与我们的服务器通信。
这个带有 GPT-J 的示例将文本数据直接发送到 Triton 服务器,所有预处理和后处理都将在服务器端进行。完整的客户端脚本可以在 fastertransformer _ backend / tools / end _ to _ end _ test 中找到。 py 或提供的 Jupyter 笔记本中。
主要部分包括:
# Import libraries
import tritonclient.http as httpclient # Initizlize client
client = httpclient.InferenceServerClient("localhost:8000", concurrency=1, verbose=False)
# ... # Request text promp from user
print("Write any input prompt for the model and press ENTER:")
# Prepare tokens for sending to the server
inputs = prepare_inputs( [[input()]])
# Sending request
result = client.infer(MODEl_GPTJ_FASTERTRANSFORMER, inputs)
print(result.as_numpy("OUTPUT_0"))
T5 推理
T5(Text-to-Text Transfer Transformer)是谷歌最近创建的架构。它由编码器和解码器部分组成,是完整Transformer架构的一个实例。它将所有自然语言处理 (NLP) 任务重新构建为统一的文本到文本格式,其中输入和输出始终是文本字符串。
本节准备的 T5 推理管道与 GPT-J 模型的不同之处在于,只有 NN 推理阶段位于服务器端,而不是具有数据预处理和后处理结果的完整管道。预处理和后处理阶段的所有计算都发生在客户端。
Triton 允许您灵活地配置推理,因此也可以在服务器端构建完整的管道,但其他配置也是可能的。
首先,使用客户端的 Huggingface 库在 Python 中将文本转换为标记。接下来,向服务器发送推理请求。最后,在得到服务器的响应后,在客户端将生成的令牌转换为文本。
下图说明了客户端-服务器推理方案。
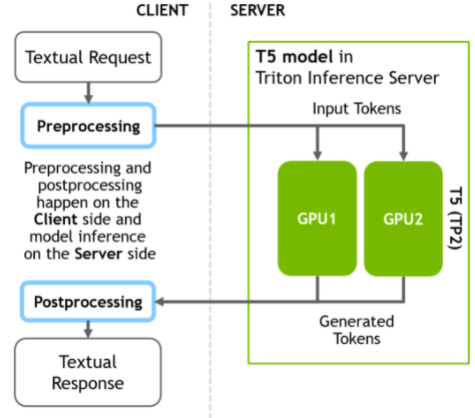
图 3.更快 transformer 和 Triton ®声波风廓线仪的 T5 推断。所有的预处理和后处理步骤都发生在客户端,只有重推理部分计算在服务器上。
T5 的制备步骤与 GPT-J 相同。 T5 步骤 5-8 的详细信息如下:
步骤 5 ( T5 ):下载 T5-3B 的权重
首先下载 T5 3b 大小的权重。您必须安装 git lfs 才能成功下载权重。
git clone https://huggingface.co/t5-3b
步骤 6 ( T5 ):将权重转换为 FT 格式
同样,权重需要转换为 C++ FasterTransformer 后端识别的二进制格式。 对于 T5 权重,您可以使用 FasterTransformer/blob/main/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py 中的脚本来转换检查点。
转换器需要以下参数。 与 GPT-J 非常相似,但参数 i_g 表示 GPU 的数量将用于 TP 机制中的推理,因此将其设置为 2:
python3 FasterTransformer/examples/pytorch/t5/utils/huggingface_t5_ckpt_convert.py\ -i t5-3b/ \ -o ./models/t5-3b/ \ -i_g 2
步骤 7 ( T5 ): T5-3B 推理的内核自动调谐
下一步是使用 t5_gemm 二进制文件对 T5 进行内核自动调整,该文件将运行实验以对 T5 模型的最重部分进行基准测试,并找到最佳的低级内核。 运行在构建 FasterTransformer 库(步骤 2)阶段构建的 。/FasterTransformer/build/bin/t5_gemm 二进制文件。 此步骤是可选的,但包含它可以实现更高的推理速度。 同样,脚本的参数可以在 GitHub 的文档中找到,或者使用 –help 参数。
./FasterTransformer/build/bin/t5_gemm 1 1 32 1024 32 128 16384 1024 32 128 16384 32128 1 2 1 1
步骤 8 ( T5 ):准备 T5 模型的 Triton 配置
您必须为 T5 模型 triton-model-store/t5/fastertransformer/config.pbtxt 打开复制的 Triton 配置进行编辑。 那里只需要更改两个强制参数即可开始推理。
然后更新 tensor_para_size。 为两个 GPU 准备了权重,因此将其设置为 2。
parameters { key: "tensor_para_size" value: { string_value: "2" }
}
接下来,使用权重更新文件夹的路径:
parameters { key: "model_checkpoint_path" value: { string_value: "./models/t5-3b/2-gpu/" }
}
启动 Triton 推理服务器。更新上一步中准备的转换模型的路径:
CUDA_VISIBLE_DEVICES=0,1 /opt/tritonserver/bin/tritonserver \ --model-repository=./triton-model-store/t5/
如果 Triton 成功启动,您将在输出中看到以下几行:
# Info about T5 model that was found by the Triton in our directory: +-------------------+---------+--------+
| Model | Version | Status |
+-------------------+---------+--------+
| fastertransformer | 1 | READY |
+-------------------+---------+--------+ # Info about that Triton successfully started and waiting for HTTP/GRPC requests: I0503 17:26:25.226719 1668 grpc_server.cc:4421] Started GRPCInferenceService at 0.0.0.0:8001
I0503 17:26:25.227017 1668 http_server.cc:3113] Started HTTPService at 0.0.0.0:8000
I0503 17:26:25.283046 1668 http_server.cc:178] Started Metrics Service at 0.0.0.0:8002
现在运行客户端脚本。在客户端,使用 Huggingface 库将文本输入转换为令牌,然后使用 Python 的 tritonclient 库向服务器发送请求。为此实现函数预处理。
然后使用 tritonclient http 类的实例,该类将请求服务器上的 8000 端口(“本地主机”,如果在本地部署)通过 http 向模型发送令牌。
收到包含令牌的响应后,再次使用后处理助手函数将令牌转换为文本形式。
# Import libraries
from transformers import ( T5Tokenizer, T5TokenizerFast
) import tritonclient.http as httpclient # Initialize client
client = httpclient.InferenceServerClient( URL, concurrency=request_parallelism, verbose=verbose
) # Initialize tokenizers from HuggingFace to do pre and post processings # (convert text into tokens and backward) at the client side
tokenizer = T5Tokenizer.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024)
fast_tokenizer = T5TokenizerFast.from_pretrained(MODEL_T5_HUGGINGFACE, model_max_length=1024) # Implement the function that takes text converts it into the tokens using # HFtokenizer and prepares tensorts for sending to Triton
def preprocess(t5_task_input): ... # Implement function that takes tokens from Triton's response and converts # them into text
def postprocess(result): ... # Run translation task with T5
text = "Translate English to German: He swung back the fishing pole and cast the line."
inputs = preprocess(text)
result = client.infer(MODEl_T5_FASTERTRANSFORMER, inputs)
postprocess(result)
添加自定义层和新的 NN 架构
如果您有一些内部带有转换器块的自定义神经网络,或者您已将一些自定义层添加到 FT(T5、GPT)支持的默认 NN 中,则 FT 开箱即用将不支持此 NN。 您可以通过添加对新层的支持来更改 FT 的源代码以添加对此 NN 的支持,或者您可以使用 FT 块和 C++、PyTorch 和 TensorFlow API 将来自 FT 的快速转换器块集成到您的自定义推理脚本/管道中 。
结果
FasterTransformer 执行的优化在 FP16 模式下实现了比原生 PyTorch GPU 推理最高 6 倍的加速,以及对 GPT-J 和 T5-3B 的 PyTorch CPU 推理最高 33 倍的加速。
下图显示了 GPT-J 的推理结果,显示了 T5-3B 模型在批量大小为 1 的翻译任务的推理结果。
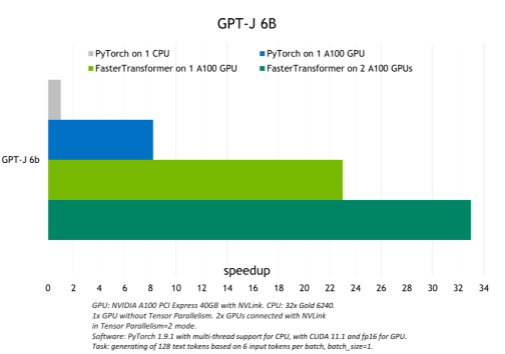
图 4.GPT-J 6B 模型推断和加速比较
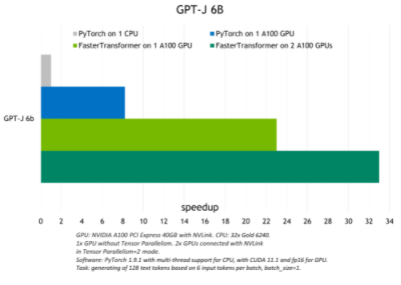
图 5.T5-3B 模型推断加速比较
模型越小,batch size 越大,FasterTransformer 表现出的优化就越好,因为计算带宽增加了。 下图显示了 T5-small 模型,其测试可以在 FasterTrasformer GitHub 上找到。 与 GPU PyTorch 推理相比,它展示了约 22 倍的吞吐量增加。 可以在 GitHub 上找到基于 T5 的模型的类似结果。
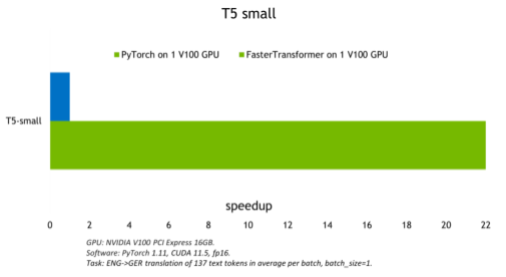
图 6.T5 小模型推断比较
结论
这里演示的代码示例使用 FasterTransformer 和 Triton 推理服务器来运行 GPT-J-6B 和 T5-3B 模型的推理。与 CPU 相比,它实现了高达 33 倍的加速,与 GPU 上的原生 PyTorch 后端相比,它达到了 22 倍。
同样的方法也可以用于小型 transformer 模型,如 T5 small 和 BERT ,以及具有数万亿参数的大型模型,如 GPT-3 。 Triton 和 FasterTransformer 使用张量和管道并行等技术提供优化和高度加速的推理,以实现所有模型的低延迟和高吞吐量。
阅读更多关于 Triton 和 FasterTransformer 或访问 fastertransformer_backend 本文中使用的示例。
大型模型的训练和推理是人工智能和高性能计算之间的一项非常重要的任务。如果您对大型神经网络感兴趣, NVIDIA 发布了多种工具,可以帮助您以最简单、最有效的方式充分利用这些工具。
关于作者
Denis Timonin 是一名深度学习解决方案架构师和工程师,目前在 NVIDIA 从事世界上最大的神经网络的训练和推理,并在计算机视觉、自然语言处理和自动语音识别领域构建人工智能解决方案。在此之前,丹尼斯在华为研究了移动设备的小型精确神经网络,并构建了复杂的人工智能管道,用于金融数据分类、医学图像分割、目标检测和跟踪。
Bo Yang Hsueh 是 FasterTransformer 的领导者和主要开发人员。三年前他参加了 transformer 加速赛。最近,他专注于大型 NLP 模型加速,包括 T5 和 GPT-J 等公共模型。杨波获得国立交通大学计算机科学硕士学位。
Vinh Nguyen 是一位深度学习的工程师和数据科学家,发表了 50 多篇科学文章,引文超过 2500 篇。在 NVIDIA ,他的工作涉及广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。 看所有的位置由 Vinh Nguyen
审核编辑:郭婷
-
NVIDIA Triton 推理服务器助力西门子提升工业效率2021-11-16 4544
-
NVIDIA Triton推理服务器帮助Teams使用认知服务优化语音识别模型2022-01-04 2575
-
使用NVIDIA TensorRT优化T5和GPT-22022-03-31 5117
-
使用MIG和Kubernetes部署Triton推理服务器2022-04-07 4887
-
NVIDIA Triton推理服务器简化人工智能推理2022-04-08 3397
-
使用NVIDIA Triton推理服务器简化边缘AI模型部署2022-04-18 3861
-
利用NVIDIA Triton推理服务器加速语音识别的速度2022-05-13 3243
-
基于NVIDIA Triton的AI模型高效部署实践2022-06-28 3339
-
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求2022-09-05 3689
-
NVIDIA Triton推理服务器的功能与架构简介2022-11-02 4223
-
NVIDIA Triton 系列文章(4):创建模型仓2022-11-15 2453
-
NVIDIA Triton 系列文章(6):安装用户端软件2022-11-29 3648
-
如何使用NVIDIA Triton 推理服务器来运行推理管道2023-07-05 2392
-
最新MLPerf v3.1测试结果认证,Gaudi2在GPT-J模型上推理性能惊人2023-09-12 1445
-
使用NVIDIA Triton推理服务器来加速AI预测2024-02-29 2050
全部0条评论

快来发表一下你的评论吧 !
