

DPDK技术原理与架构
电子说
描述
01 技术原理与架构
由于采用软件转发和软件交换技术,单服务器内部的转发能力是 NFV 系统的主要性能瓶颈。在各类高速转发的 NFV 应用中,数据报文从网卡中接收,再传送到虚拟化的用户态应用程序(VNF)处理,整个过程要经历 CPU 中断处理、虚拟化 I/O 与地址映射转换、虚拟交换层、网络协议栈、内核上下文切换、内存拷贝等多个费时的 CPU 操作和 I/O 处理环节。
业内通常采用消除海量中断、旁路内核协议栈、减少内存拷贝、CPU 多核任务分担、Intel VT 等技术来综合提升服务器数据平面的报文处理性能,普通用户较难掌握。业界迫切需要一种综合的性能优化方案,同时提供良好的用户开发和商业集成环境,DPDK 加速技术方案成为其中的典型代表。
DPDK 是一个开源的数据平面开发工具集,提供了一个用户空间下的高效数据包处理库函数,它通过环境抽象层旁路内核协议栈、轮询模式的报文无中断收发、优化内存/缓冲区/队列管理、基于网卡多队列和流识别的负载均衡等多项技术,实现了在 x86 处理器架构下的高性能报文转发能力,用户可以在 Linux 用户态空间开发各类高速转发应用,也适合与各类商业化的数据平面加速解决方案进行集成。
英特尔在 2010 年启动了对 DPDK 技术的开源化进程,于当年 9 月通过 BSD 开源许可协议正式发布源代码软件包,并于 2014 年 4 月在 www.dpdk.org 上正式成立了独立的开源社区平台,为开发者提供支持。开源社区的参与者们大幅推进了 DPDK 的技术创新和快速演进,而今它已发展成为 SDN 和 NFV 的一项关键技术。
02 软件架构
DPDK 的组成架构如图所示,相关技术原理概述如下:
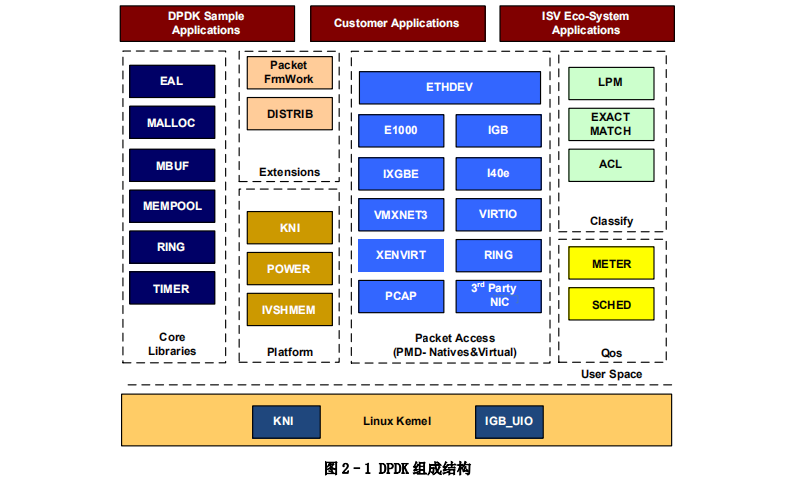
在最底部的内核态(Linux Kernel)DPDK 有两个模块:KNI 与 IGB_UIO。其中,KNI 提供给用户一个使用 Linux 内核态的协议栈,以及传统的 Linux 网络工具(如ethtool, ifconfig)。IGB_UIO(igb_uio.ko 和 kni.ko. IGB_UIO)则借助了 UIO 技术,在初始化过程中将网卡硬件寄存器映射到用户态。
如图,DPDK 的上层用户态由很多库组成,主要包括核心部件库(Core Libraries)、平台相关模块(Platform)、网卡轮询模式驱动模块(PMD-Natives&Virtual)、QoS 库、报文转发分类算法(Classify)等几大类,用户应用程序可以使用这些库进行二次开发,下面分别简要介绍。
核心部件库:该模块构成的运行环境是建立在 Linux 上,通过环境抽象层(EAL)的运行环境进行初始化,包括:HugePage 内存分配、内存/缓冲区/队列分配与无锁操作、CPU 亲和性绑定等;其次,EAL 实现了对操作系统内核与底层网卡 I/O 操作的屏蔽(I/O 旁路了内核及其协议栈),为 DPDK 应用程序提供了一组调用接口,通过 UIO 或 VFIO 技术将 PCI 设备地址映射到用户空间,方便了应用程序调用,避免了网络协议栈和内核切换造成的处理延迟。
另外,核心部件还包括创建适合报文处理的内存池、缓冲区分配管理、内存拷贝、以及定时器、环形缓冲区管理等。
平台相关模块:其内部模块主要包括 KNI、能耗管理以及 IVSHMEM 接口。其中,KNI 模块主要通过 kni.ko 模块将数据报文从用户态传递给内核态协议栈处理,以便用户进程使用传统的 socket 接口对相关报文进行处理;能耗管理则提供了一些 API,应用程序可以根据收包速率动态调整处理器频率或进入处理器的不同休眠状态;另外,IVSHMEM 模块提供了虚拟机与虚拟机之间,或者虚拟机与主机之间的零拷贝共享内存机制,当 DPDK 程序运行时,IVSHMEM 模块会调用核心部件库 API,把几个 HugePage 映射为一个 IVSHMEM 设备池,并通过参数传递给 QEMU,这样,就实现了虚拟机之间的零拷贝内存共享。
轮询模式驱动模块:PMD 相关 API 实现了在轮询方式下进行网卡报文收发,避免了常规报文处理方法中因采用中断方式造成的响应延迟,极大提升了网卡收发性能。此外,该模块还同时支持物理和虚拟化两种网络接口,从仅仅支持 Intel 网卡,发展到支持 Cisco、Broadcom、Mellanox、Chelsio 等整个行业生态系统,以及基于 KVM、VMWARE、 XEN 等虚拟化网络接口的支持。
DPDK 还定义了大量 API 来抽象数据平面的转发应用,如 ACL、QoS、流分类和负载均衡等。并且,除以太网接口外,DPDK 还在定义用于加解密的软硬件加速接口(Extensions)。
03 大页技术
处理器的内存管理包含两个概念:物理内存和虚拟内存。Linux 操作系统里面整个物理内存按帧(frames)来进行管理,虚拟内存按照页(page)来进行管理。内存管理单元(MMU)完成从虚拟内存地址到物理内存地址的转换。内存管理单元进行地址转换需要的信息保存在一个叫页表(page table)的数据结构里面,页表查找是一种极其耗时的操作。
x86 处理器硬件在缺省配置下,页的大小是 4K,但也可以支持更大的页表尺寸,例如2M 或 1G 的页表。使用了大页表功能后,一个 TLB 表项可以指向更大的内存区域,这样可以大幅减少 TLB miss 的发生。早期的 Linux 并没有利用 x86 硬件提供的大页表功能,仅在 Linux内核 2.6.33 以后的版本,应用软件才可以使用大页表功能,具体的介绍可以参见 Linux 的大页表文件系统(hugetlbfs)特性。
DPDK 则利用大页技术,所有的内存都是从 HugePage 里分配,实现对内存池(mempool)的管理,并预先分配好同样大小的 mbuf,供每一个数据包使用。
04 轮询技术
为了减少中断处理开销,DPDK 使用了轮询技术来处理网络报文。网卡收到报文后,直接将报文保存到处理器 cache 中(有 DDIO(Direct Data I/O)技术的情况下),或者保存到内存中(没有 DDIO 技术的情况下),并设置报文到达的标志位。应用软件则周期性地轮询报文到达的标志位,检测是否有新报文需要处理。整个过程中完全没有中断处理过程,因此应用程序的网络报文处理能力得以极大提升。
05 GPU亲和技术
现代操作系统都是基于分时调用方式来实现任务调度,多个进程或线程在多核处理器的某一个核上不断地交替执行。每次切换过程,都需要将处理器的状态寄存器保存在堆栈中,并恢复当前进程的状态信息,这对系统其实是一种处理开销。将一个线程固定一个核上运行,可以消除切换带来的额外开销。另外将进程或者线程迁移到多核处理器的其它核上进行运行时,处理器缓存中的数据也需要进行清除,导致处理器缓存的利用效果降低。
CPU 亲和技术,就是将某个进程或者线程绑定到特定的一个或者多个核上执行,而不被迁移到其它核上运行,这样就保证了专用程序的性能。
DPDK 使用了 Linux pthread 库,在系统中把相应的线程和 CPU 进行亲和性绑定, 然后相应的线程尽可能使用独立的资源进行相关的数据处理。
基于 DPDK 进行应用开发和环境配置时,应用程序性能的影响因素以及相应的优化调整方法。这些因素并非必然劣化性能,可能因硬件能力、OS 版本、各类软硬环境参数配置等的差异产生较大波动,或者存在较大的不稳定性,相关的调优方法需要用户结合自身的VNF应用部署在实践中不断完善。
1、硬件结构的影响
DPDK 具有广泛的平台适应性,可以运行在整个 x86 平台,从主流服务器平台(从高性能或者高能效产品系列),到桌面或者嵌入式平台,也可以运行于基于 Power 或者其他架构的运算平台。图展示了一个通用双路服务器的内部架构,它包含了 2 个中央处理器,2个分离的内存控制单元来连接系统内存,芯片组会扩展出大量高速的 PCIe 2.0/3.0 接口,用于连接外设,如 10Gbps 或者 25Gbps 网卡外设。
2、OS 版本及其内核的影响
不同的 Linux OS 发行版使用的 Linux 内核版本不一样,配置的 Linux OS服务也不一样。这些差异都会导致应用程序在网络报文处理能力上有所差别。
由于 Linux 内核还在不断演进,Linux 的发行版也数量众多,本文无法提供最佳 Linux内核版本和配置,而只能给出部分参考建议,如:关闭部分 OS 服务。在后续章节,我们选取了目前比较流行的 Linux 发行版进行了测试,并给出测试结果。从测试结果中显示,同样的硬件配置环境下,不同的 Linux 发行版在小包的处理能力上存在差异。
2.1 关闭 OS 部分服务
在 10G 端口上 64Byte 报文的线速到达率为 14.88Mpps,如果实现零丢包的线速处理,每个报文的平均处理速度应该小于 1/14.48Mpps=67us,DPDK 应用的网卡收发包队列长度缺省配置为 128,网卡队列填充满的时间是 128*67=8579us。也就是说,DPDK 的业务进程,如果被操作系统中断超过 8579us,就会导致网卡收发报的队列被充满,无法接收新的报文,从而导致丢包。而操作系统的中断服务程序、后台服务程序、以及任务调度程序都会导致DPDK 的应用程序被打断。
在 NFV 应用场景下,Host 机器上和 Guest 机器上都运行着操作系统,由此带来了两级的操作任务调度。DPDK 应用程序(NFV 中的 VNF)均运行在虚拟机上,操作系统带来的影响会更加明显。
为了实现 DPDK 应用程序的零丢包,需要对操作系统进行适当的配置,减少操作系统的对 DPDK 应用程序的干扰。操作系统配置的总体思路是:
将运行 DPDK 应用运行的处理器核进行隔离,减少干扰;
停用不需要的后台服务程序。将不需要的中断,转移到其它处理器核上处理;
对于不能转移的中断,减少中断的次数。
2.2 OS 调整示例
下面以 CentOS 7 为例,说明具体的调整方法。绝大部分的操作需要同时在 Host 操作系统和 Guest 操作系统同时应用。
1) 对 DPDK 应用使用处理器核进行隔离。
修改 Linux 的 OS 的 GRUB 参数,设置 isolCPUs=16-23,40-47;2) 打开运行有 DPDK 进程的处理器核上的 nohz_full。nohz_full 可以减少内核的周期性时钟中断的次数。修改 Linux 的 OS 的 GRUB 参数,设置 nohz_full=16-23,40-47;3) 关闭 NMI 监控功能,减少 NMI 中断对 DPDK 任务的干扰。修改 Linux 的 OS 的 GRUB 参数,设置 nmi_watchdog=0;4) 关闭 SELinux 功能修改 Linux 的 OS 的 GRUB 参数,设置 selinux=0;5) 关闭处理器的 P 状态调整和 softlockup 功能。将处理器锁定在固定的频率运行,减少处理器在不同的 P 状态切换带来的处理时延。修改 Linux 的 OS 的 GRUB 参数,设置 intel_pstate=disable nosoftlockup;6) 关闭图形显示,减少 GUI 应用的干扰。调用命令 systemctl set-default multi-user.target;7) 关闭操作系统的中断调度程序。调用命令 systemctl disable irqbalance.service;8) 关闭操作系统的审计服务。调用命令 systemctl disable auditd.service;9) 关闭蓝牙服务。调用命令 systemctl disable bluetooth.service;10) 关闭 KVM 的内存页合并服务。调用命令 systemctl disable ksm.service;调用命令 systemctl disable ksmtuned.service;
11) 对于 KVM 虚拟的 vCPU 和物理 CPU 进行绑定。使用 QEMU monitor 获取 vCPU 对应的线程号,使用 taskset 命令进行绑定。
2.3 OVS 性能问题
OVS 作为 NFV 的一个重要组成模块,会运行在绝大多数的服务器节点上,提供虚拟机和虚拟机之间,以及虚拟网络和物理网络间的互连接口,其性能至关重要。OVS 2.4 开始正式支持 DPDK 加速,相比传统基于 Linux 内核的 OVS 版本,转发性能提高了数倍,为 VNF 在通用 x86 服务器上部署提供了有力支持。
OVS 缺省会为每一个 NUMA 节点创建一个 pmd 线程,该 pmd 线程以轮询方式处理属于其NUMA 节点上的所有 DPDK 接口。为了高性能,需要利用前面提到的 CPU 亲和技术,把 pmd 线程绑定在一个固定的 CPU core 上处理。此外,为了增加扩展性,OVS 2.4 也支持网卡多队列以及多 pmd 线程数,这些参数均可动态配置,但具体配置应根据具体需求来决定。
3、内存管理
如前所述,DPDK 考虑了 NUMA 以及多内存通道的访问效率,会在系统运行前要求配置Linux 的 HugePage,初始化时申请其内存池,用于 DPDK 运行的主要内存资源。Linux 大页机制利用了处理器核上的的 TLB 的 HugePage 表项,这可以减少内存地址转换的开销。
3.1 内存多通道的使用
现代的内存控制器都支持内存多通道,比如 Intel 的 E5-2600V3 系列处理器,能支持 4个通道,可以同时读和取数据。依赖于内存控制器及其配置,内存分布在这些通道上。每一个通道都有一个带宽上限,如果所有的内存访问都只发生在第一个通道上,这将成为一个潜在的性能瓶颈。
因此,DPDK 的 mempool 库缺省是把所有的对象分配在不同的内存通道上,保证了在系统极端情况下需要大量内存访问时,尽可能地将内存访问任务均匀平滑。
3.2 内存拷贝
很多 libc 的 API 都没有考虑性能,因此,不要在高性能数据平面上用 libc 提供的 API,比如,memcpy()或 strcpy()。虽然 DPDK 也用了很多 libc 的 API,但均只是在软件配置方面用于方便程序移植和开发。
DPDK 提供了一个优化版本的 rte_memcpy() API,它充分利用了 Intel 的 SIMD 指令集,也考虑了数据的对齐特性和 cache 操作友好性。
3.3 内存分配
在某些情况下,应用程序使用 libc 提供的动态内存分配机制是必要的,如 malloc()函数,它是一种灵活的内存分配和释放方式。但是,因为管理零散的堆内存代价昂贵,并且这种内存分配器对于并行的请求分配性能不佳,所以不建议在数据平面处理上使用类似malloc()的函数进行内存分配。
在有动态分配的需求下,建议使用 DPDK 提供的 rte_malloc() API,该 API 可以在后台保证从本 NUMA 节点内存的 HugePage 里分配内存,并实现 cache line 对齐以及无锁方式访问对象等功能。
3.4 NUMA 考虑
NUMA(Non Uniform Memory Access Architecture)与 SMP(Symmetric Multi Processing)是两种典型的处理器对内存的访问架构。随着处理器进入多核时代,对于内存吞吐量和延迟性能有了更高的要求,NUMA 架构已广泛用于最新的英特尔处理器中,为每个处理器提供分离的内存和内存控制器,以避免 SMP 架构中多个处理器同时访问同一个存储器产生的性能损失。
在双路服务器平台上,NUMA 架构存在本地内存与远端内存的差异。本地和远端是个相对概念,是指内存相对于具体运行程序的处理器而言,如图所示。
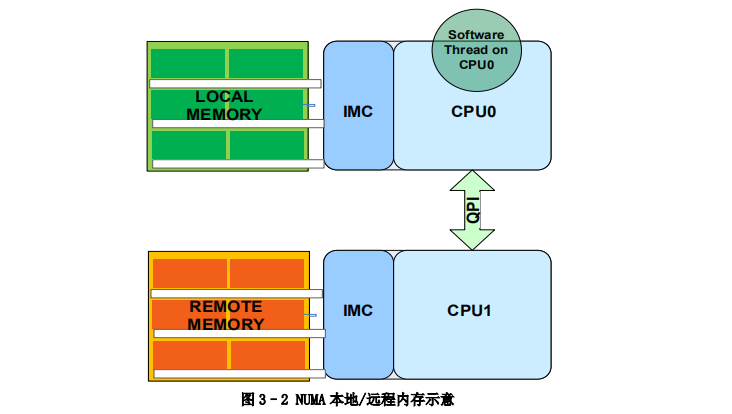
在 NUMA 体系架构中,CPU 进行内存访问时,本地内存的要比访问远端内存更快。因为访问远端内存时,需要跨越 QPI 总线,在应用软件设计中应该尽量避免。在高速报文处理中,这个访问延迟会大幅降低系统性能。尤其是传统嵌入式软件向服务器平台迁移时,需要特别关注。
DPDK 提供了一套在指定 NUMA 节点上创建 memzone、ring, rte_malloc 以及 mempool 的API,可以避免远端内存访问这类问题。在一个 NUMA 节点端,对于内存变量进行读取不会存在性能问题,因为该变量会在 CPU cache 里。但对于跨 NUMA 架构的内存变量读取,会存在性能问题,可以采取复制一份该变量的副本到本地节点(内存)的方法来提高性能。
4、CPU 核间无锁通信
如果想建立一个基于消息传递的核间通信机制,可以使用 DPDK ring API,它是一个无锁的 ring 实现。该 ring 机制支持批量和突发访问,即使同时读取几个对象,也只需要一个昂贵的原子操作,批量访问可以极大地改善性能。
5、设置正确的目标 CPU 类型
DPDK支持CPU微架构级别的优化,可以通过修改DPDK配置文件中的CONFIG_RTE_MACHINE参数来定义。优化的程度根据随编译器的能力而不同,通常建议采用最新的编译器进行编译。
如果编译器的版本不支持该款 CPU 的特性,比如 Intel AVX 指令,那么它在编译时只会选用自己支持的指令集,这可能导致编译 后生成的 DPDK 应用的性能下降。
-
龙芯自主CPU指令系统获得开源DPDK支持2022-12-08 2087
-
国际主流网卡驱动开源社区DPDK已支持LoongArch架构2022-12-06 2339
-
Arm上带DPDK的Open vSwitch测试系列2022-03-31 4547
-
ovs-dpdk sgmii口不能正常转发是为什么2022-01-05 1824
-
DPDK内存的基本概念2020-10-26 2934
-
DPDK内存管理的IOMMU和IOVA技术总结2020-09-25 11622
-
DPDK开源社区更新2018-11-13 5165
-
如何为您的NFV应用设置DPDK2018-11-12 3802
-
使用DPDK打开VSwitch:架构和性能2018-11-08 4481
-
DPDK的设计方法与API应用介绍2018-10-30 4903
-
建立和运行DPDK,使用英特尔QuickAssist设备加密2018-10-17 3135
-
DPDK安装教程和DPDK程序运行收发包示例程序及性能对比实验的详细概述2018-09-03 1470
-
基于Intel dpdk数据包捕获技术研究2017-11-24 1093
全部0条评论

快来发表一下你的评论吧 !
