

应用语言模型技术创作人工智能音乐
描述
诸如 NVIDIA Megatron LM 和 OpenAI GPT-2 和 GPT-3 等语言模型已被用于提高人类生产力和创造力。具体而言,这些模型已被用作编写、编程和绘制的强大工具。相同的架构可以用于音乐创作。
在这些领域中使用语言模型需要大型数据集。从 50GB 的未压缩文本文件开始生成语言并不奇怪。这意味着需要 GPU 计算日志来有效地训练模型,以进行快速开发、原型制作和迭代。
这篇文章介绍了在人工智能音乐领域使用 NVIDIA DGX-2 站台 DGX-2 极大地促进了数据预处理和训练语言模型的进步。
人工智能音乐数据集
计算音乐数据集有两大类。一种方法涉及对表示为纯音频( WAV 文件或 MP3 )的音乐进行训练。第二种方法不适用于纯音频。相反,您可以将任何类似于乐谱的内容映射到标记表示。
通常,这需要标记哪个音符开始( C 、 D 、 E 、 F 、 G ),经过多少时间(例如四分之一音符或八分之一音符),以及哪个音符结束。在研究和应用中, MIDI 文件已被证明是丰富的音乐素材来源。 MIDI 标准被设计用于电子存储音乐信息。
这些实验使用了几组 MIDI 文件,包括:
JS Fake Chorales Dataset 有 500 首 J.S.巴赫风格的假合唱
运行 MIDI 数据库 以及其干净的子集(分别为 176K 和 15K MIDI 文件),混合了各种类型和风格
MetaMIDI 数据集 具有 463K MIDI 文件,同样具有不同的类型和风格
MIDI 格式是非人类可读的音乐表示,为了训练因果语言模型,必须将其映射到可读的标记表示。对于此表示,我们从 mmmtrack 编码 。
这种编码将音乐片段表示为层次结构。一段音乐由不同乐器的不同曲目组成:例如鼓、吉他、贝司和钢琴。每个轨道由几个条组成( 4 、 8 或 16 条,取决于使用情况)。每个条都包含一系列音符开启、时间增量和音符关闭事件。尽管这种层次结构可以被视为一棵树,但可以将所有内容编码为一个线性序列,使其成为仅用于解码器的语言模型的理想表示。
下面的例子是一首四部分的合唱,以钢琴卷的形式呈现。合唱团有四种声音:女高音、中音、男高音和低音。女高音和女低音是女声,男高音和男低音是男声。通常,四种声音同时演唱,但音调不同。
图 1 显示了带有音调颜色编码的语音。女高音为绿色,中音为橙色,男高音为蓝色,低音为红色。您可以将这些具有时间和音调维度的音乐事件编码为一系列符号。
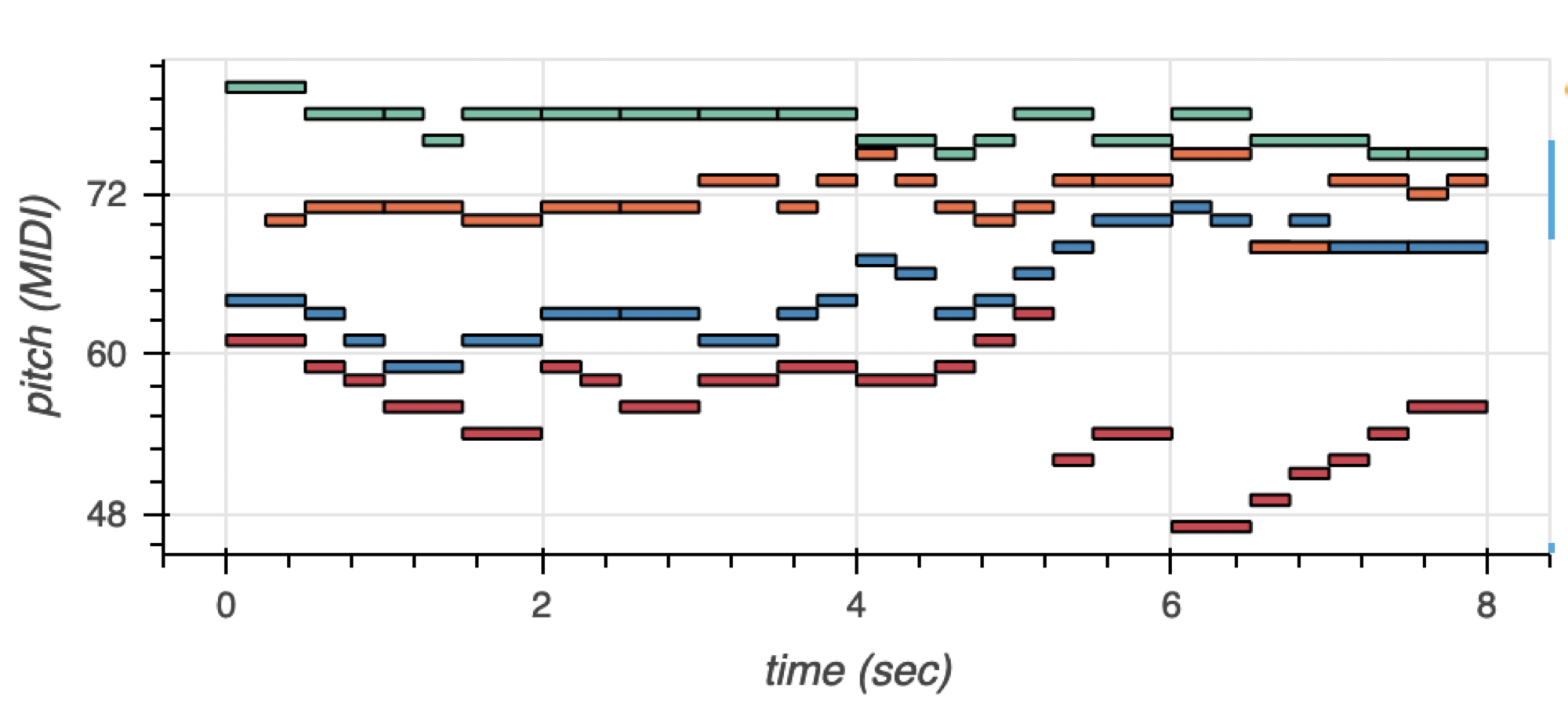
图 1.使用音高颜色编码可视化生成的音乐标记示例
在 mmmtrack 编码之后,低音部分将映射到以下令牌表示:
PIECE_START TRACK_START INST=BASS BAR_START NOTE_ON=61 TIME_DELTA=4 NOTE_OFF=61 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=58 TIME_DELTA=2 NOTE_OFF=58 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=4 NOTE_OFF=59 BAR_END BAR_START NOTE_ON=58 TIME_DELTA=4 NOTE_OFF=58 NOTE_ON=59 TIME_DELTA=2 NOTE_OFF=59 NOTE_ON=61 TIME_DELTA=2 NOTE_OFF=61 NOTE_ON=63 TIME_DELTA=2 NOTE_OFF=63 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=4 NOTE_OFF=54 BAR_END BAR_START NOTE_ON=47 TIME_DELTA=4 NOTE_OFF=47 NOTE_ON=49 TIME_DELTA=2 NOTE_OFF=49 NOTE_ON=51 TIME_DELTA=2 NOTE_OFF=51 NOTE_ON=52 TIME_DELTA=2 NOTE_OFF=52 NOTE_ON=54 TIME_DELTA=2 NOTE_OFF=54 NOTE_ON=56 TIME_DELTA=4 NOTE_OFF=56 BAR_END TRACK_END TRACK_START INST=TENOR …
只要稍加练习,人类就能阅读和理解这种表示。表示以PIECE_START开始,表示一段音乐的开始。TRACK_START表示音轨(或乐器或语音)的开始,而TRACK_END表示音尾。INST=BASS标记表示此曲目包含低音。其他声音以相同的方式表示。BAR_START和BAR_END分别表示条形图的开始和结束。NOTE_ON=61是音调为 61 的音符的开头。
在钢琴上,这将是音符 C # 5 。TIME_DELTA=4意味着将经过四个十六分音符的持续时间。那将是一张四分之一的钞票。之后,音符将结束,由NOTE_OFF=61表示。等等等等。在这一点上,这种记法也允许复调。几个音轨将同时发出音符,每个音轨可以有平行的音符。这使得编码具有通用性。
每段音乐的小节数不同。很可能对整个歌曲进行编码将需要较长的序列长度,从而使相应 transformer 的训练在计算上非常昂贵。这些实验将大多数数据集编码为四条,少数编码为八条。 16 巴的实验正在进行中。此外,仅使用 4 / 4 计时表中的音乐。这涵盖了西方音乐的大部分。其他节拍,如 3 / 4 (华尔兹)可以作为未来工作的主题。
这一系列不同的实验将许多 MIDI 数据集映射到所描述的令牌格式。整个过程中使用了相同的预处理器。一旦预处理器处理小数据集,它立即处理大数据集。
处理时间取决于要编码的 MIDI 文件的数量,从几分钟到几小时不等。 DGX-2 在所有 96 CPU 上并行运行,最长的预处理时间为 30 小时。据估计,这将需要在最先进的 MacBook Pro 上进行大约 10-14 天的处理。
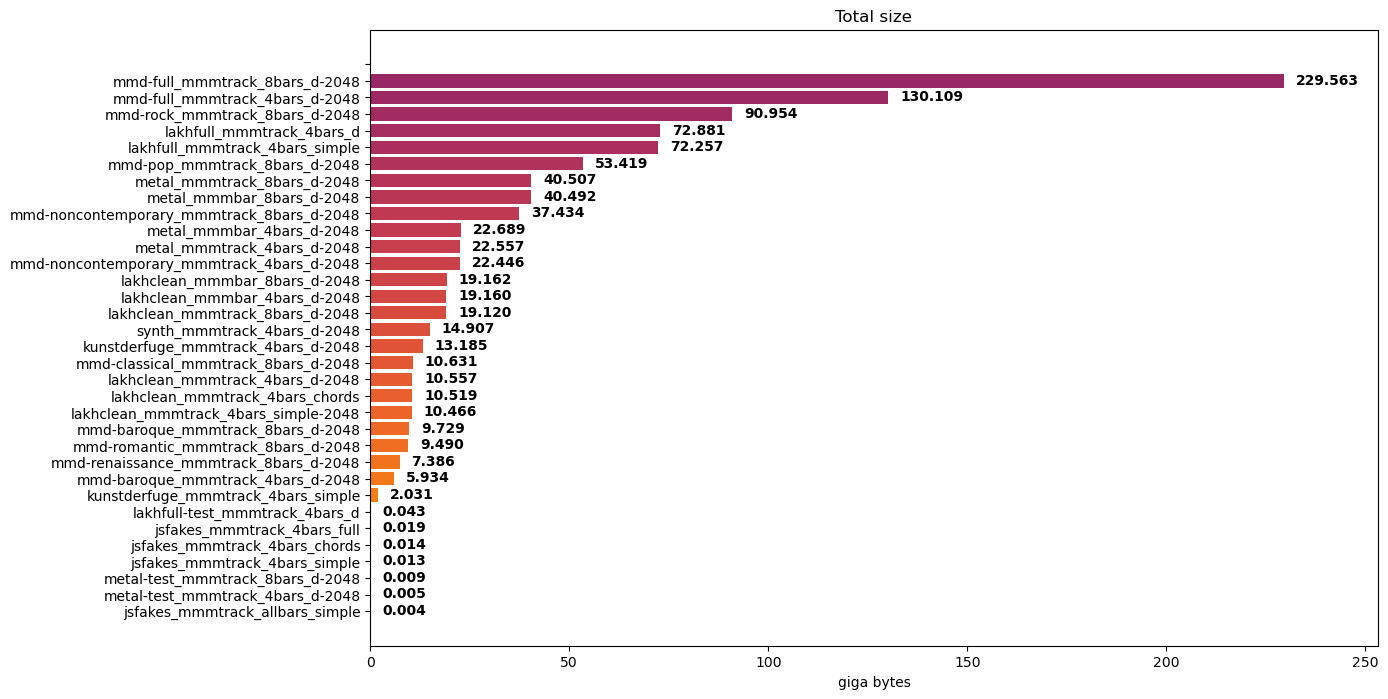
图 2.用于训练 GPT 模型的音乐数据集
对 MIDI 文件的数据集进行编码将产生令牌文件的集合。这些标记文件的大小取决于 MIDI 文件的数量和条形图的数量。考虑一些实验数据集及其编码数据集大小:
JS Fake Chorales 数据集: 14 MB ,每个样本有四个条
Lakh MIDI 数据集: 72 GB ,其干净子集为 19 GB ,每个样本有四个小节
MetaMIDI 数据集:每个样本 130 GB , 4 个小节, 230 GB , 8 个小节
你可以想象,在 14 MB 的 JS 假合唱团上训练只需要几个小时。在 130 GB 的 MetaMIDI 数据集上进行训练需要很多天。这些实验的训练持续了 10 至 15 天。
模型训练
许多模型使用 HuggingFace GPT-2 实现进行了训练。一些模型在 GPT-2 模式下使用 NVIDIA Megatron LM 进行了训练。
使用 HuggingFace 进行的训练归结为将数据集上传到 DGX-2 ,然后运行包含所有功能的训练脚本,包括模型和训练参数。使用了相同的脚本,只是对所有数据集进行了一些更改。这只是规模问题。
对于Megatron LM 来说,环境设置就像拉动和运行 NGC 一样简单 PyTorch Docker 容器 ,然后通过 ssh 隧道进入 DGX-2 机器,立即在浏览器中使用 Jupyter 笔记本。
大多数实验使用相同的 GPT-2 架构:六个解码器块和八个注意头;嵌入大小为 512 ,序列长度为 2048 。虽然这绝对不是一个大语言模型( LLM ),它可以有大约 100 个解码器块,但主观评估表明,对于人工智能音乐来说,这种架构工作起来很有魅力。
使用 NVIDIA DGX-2 在快速迭代中确实起到了作用。在单个 GPU 上训练多天的数据集,在 DGX-2 上只训练几个小时。在单个 GPP 上训练数月的数据集在 DGX-2 中最多两周后完成训练。特别是对于数据集< 25 GB 的实验,模型收敛非常快。
一些数据集的培训时间如下:
10 个时代和大约 1.5 万首歌曲的 10 万首 MIDI Clean 数据集耗时 15 小时
10 个时代和大约 175K 首歌曲的 Lakh MIDI 数据集耗时 130 小时
MetaMIDI 数据集历时 290 小时,涵盖了 9 个时代和大约 40 万首歌曲
请注意, JS Fake Chorales 数据集是较早训练的,而不是在 DGX-2 上。由于其体积非常小,因此不需要使用 multi- GPU 设置。它甚至可以在 MacBook Pro 上过夜训练。
NVIDIA DGX-2
本节详细介绍了 NVIDIA DGX-2 规范。如上所述,该平台在加速数据集预处理和训练语言模型方面都非常有效。这一部分将是一个令人愉快的技术部分。

图 3.DGX-2 站
NVIDIA DGX-2 是一个功能强大的系统,具有 16 个完全连接的 Tesla V100 32 GB GPU ,使用 NVSwitch 。它能够提供 2.4 TB /秒的二等分带宽。 DGX-2 专为需要性能和可扩展性的人工智能研究人员和数据科学家设计。
对于 transformer 型号, NVIDIA DGX-2 能够以混合精度提供敢达 517227 个令牌/秒的吞吐量,这使其特别强大。
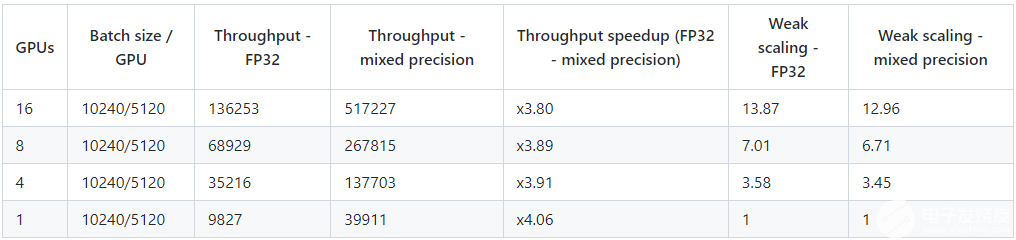
表 1.多 – GPU 性能表e对于 DGX-2
软件框架: NVIDIA Megatron LM
要充分利用强大的计算功能,您需要稳定和优化的软件。使用 NVIDIA Megatron LM 等性能优化框架,随着 GPT 模型尺寸的缩放,性能几乎呈线性缩放。有关相关信息,请参见 Megatron LM :使用模型并行性训练数十亿参数语言模型 。
通过在单个 NVIDIA V100 32 GB GPU 上训练 12 亿个参数的模型来实现基线,该 GPU 支持 39 万亿次浮点运算。这是 DGX-2H 服务器中配置的单个 GPU 的理论峰值触发器的 30% ,因此是一个强基线。
将模型扩展到 512 GPU 上的 83 亿个参数,在整个应用程序中, 8 路模型并行度达到每秒 15.1 万亿次。与单一 GPU 情况相比,这是 76% 的缩放效率。
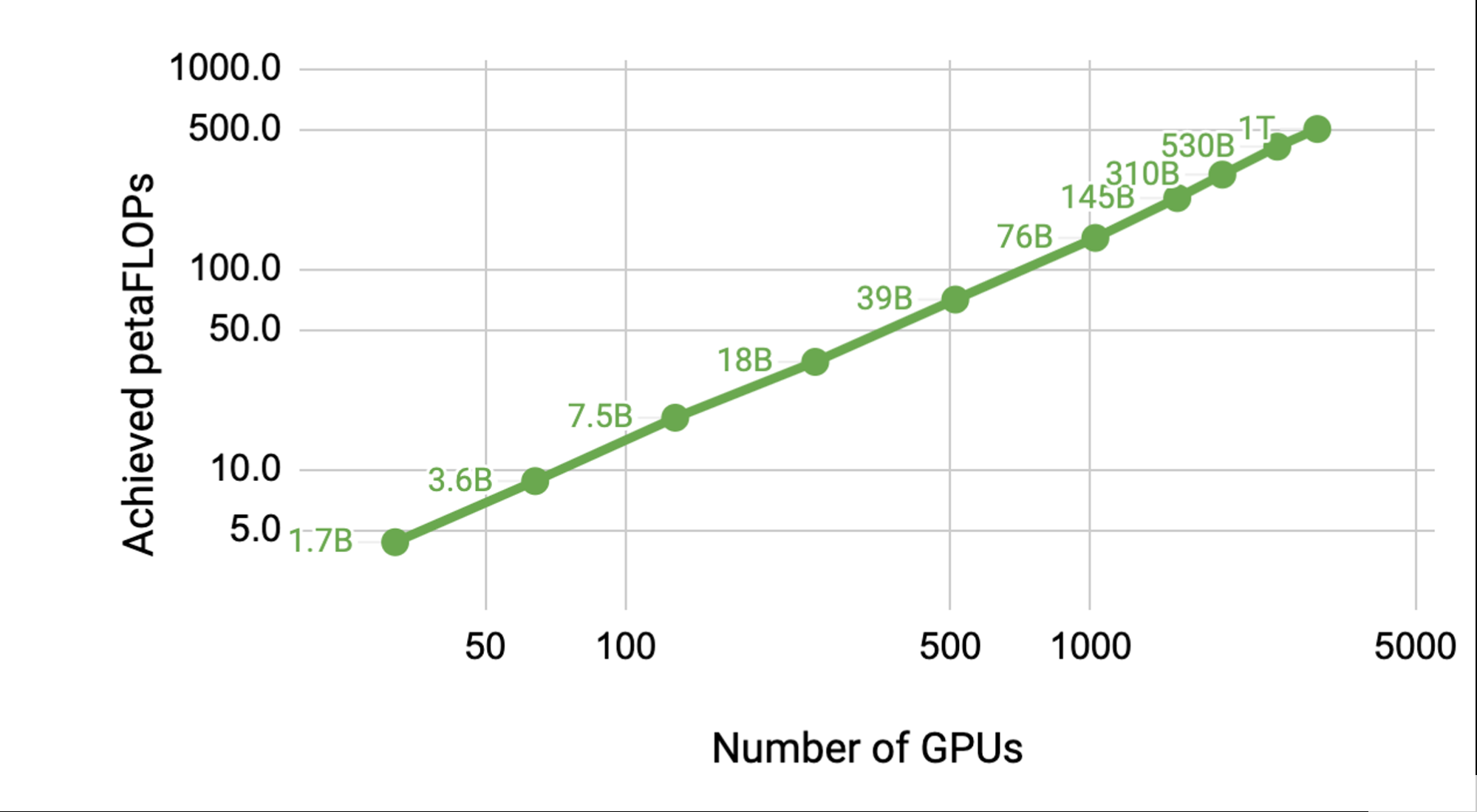
图 4.使用 NVIDIA Megatron LM 扩展到数千个 GPU ,而不损失性能
通过修正seq_len,短指针,等于 4096 ,并修改训练配置,只需几次迭代即可启动训练运行,可以计算实际应用程序作业运行中实现的万亿次浮点百分比。
在本机运行后,分析了nvidia-smi和输出 Nsight 配置文件。测试了不同的配置以获得最高可能的 teraflop ,如下表所示:
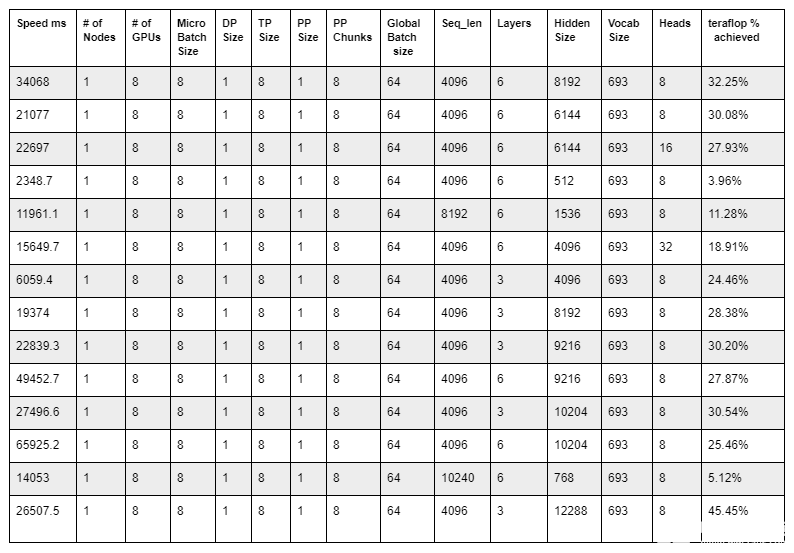
表 2.使用中给出的第三个方程计算万亿次浮点 使用Megatron LM 在 GPU 集群上进行高效大规模语言模型训练
该表最后一行中显示的训练配置提供了 45.45% 的最高 teraflop 。
请注意,使用了 8 个 V100 32 GB GPU 而不是 16 GPU ,以缩短运行每个评测作业所需的时间。nvidia-smi 命令用于验证训练配置实现了 45.45% 的 teraflops 利用率,如下所示。
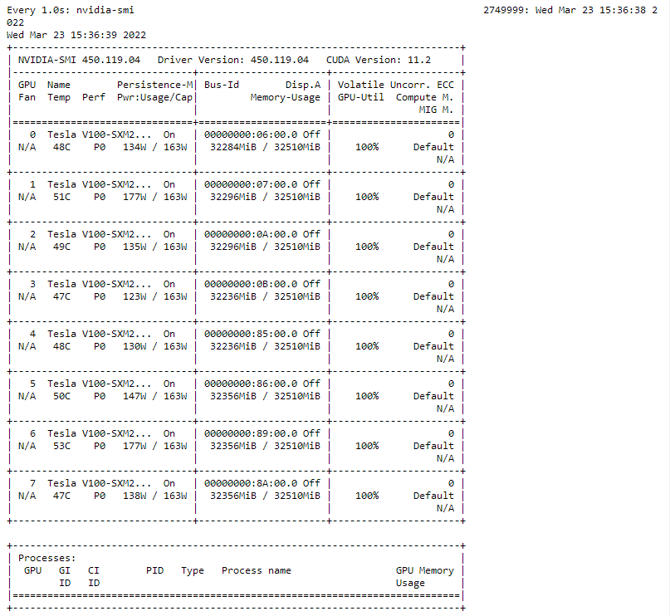
图 5.通过使用 NVIDIA smi 命令以交互方式监控培训性能
总结
这里介绍的人工智能音乐实验是使用 NVIDIA DGX-2 进行的。我们使用大小从几兆字节到 230 GB 的数据集训练语言模型。我们使用了 HuggingFace GPT-2 实现,并表明 NVIDIA Megatron LM 也是一个很好的实验替代品。
NVIDIA DGX-2 在加速数据集预处理(将 MIDI 文件映射到令牌表示和训练模型)方面做出了重大贡献。这允许快速实验。 DGX-2 在训练可用的最大 MIDI 数据集(具有 400K 文件的 MetaMIDI )时发挥了巨大的作用。
关于作者
Tristan Behrens 博士是人工智能专家、人工智能作曲家和人工智能教育家。他在成功的深度学习项目中有着广泛的记录。他最大的关注点是合成的深度神经网络。他出版了几张用电脑创作的音乐专辑。
Zenodia Charpy 是高级深度学习解决方案架构师,专注于应用自然语言处理和深度学习技术来应对非英语和低资源语言的挑战,例如瑞典语、丹麦语和挪威语。作为一名数据科学家,她在解决现实世界问题、构建端到端解决方案方面拥有八年的丰富经验,她既是一名内部数据科学家,也是一名数据科学顾问。在空闲时间,她喜欢在森林里散步或跑步,做瑜伽。
审核编辑:郭婷
-
人工智能是什么?2015-09-16 6405
-
人工智能技术—AI2015-10-21 9751
-
人工智能传感技术2016-06-03 34934
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 7981
-
人工智能和机器学习的前世今生2018-08-27 3572
-
适合人工智能开发的5种最佳编程语言优缺点对比2018-09-29 5393
-
初学AI人工智能需要哪些技术?这几本书为你解答2019-01-21 9705
-
路径规划用到的人工智能技术2021-07-20 2376
-
人工智能芯片是人工智能发展的2021-07-27 6633
-
物联网人工智能是什么?2021-09-09 5304
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4643
-
嵌入式人工智能学习路线2022-09-16 4499
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2330
-
人工智能与音乐教育的碰撞2019-06-27 4415
-
人工智能和音乐的融合 是AI技术在音乐创作领域的新突破2019-12-16 6269
全部0条评论

快来发表一下你的评论吧 !
