

一个全新的无监督不需要明确物体种类的实例分割算法
描述
摘要
对于自动驾驶来说,精细化的场景理解至关重要。由于在行驶的过程中,场景周围信息会发生剧烈的变化,因此很难识别和理解出场景中的不同对象。尽管有很多工作者在语义/全景分割上推动了场景理解的发展,但目前来说,仍然是一个挑战任务。目前的方法大多依赖于标注数据,对于训练数据中缺少的类别,我们将其称为拖尾(长尾)类。
然而,拖尾(长尾)类对于自动驾驶来说缺失至关重要,如婴儿车和未知动物,都会对自动驾驶的安全性能造成巨大的挑战。在本篇文章中,我们将集中对这种类无关的实例分割问题进行研究,进一步解决这种拖尾(长尾)类问题。我们提出一个全新的算法和验证算法用的数据集,并且在真实场景数据中验证我们算法效果。
算法通过一个已经训练好的自监督神经网络抽取出点特征,构建出点云表示对应的图表征。然后,我们用图割算法来将前后背景分离出来。结果证明了我们的算法可以实现实例分割,并且相比于其他自监督算法,我们方法具有不错的竞争力。
主要贡献
在这篇论文中,我们关注的问题是基于激光点云的实例分割,更确切的来说,我们关注的是不需要明确类别的激光点云实例分割算法。相比于需要把城镇街道上所有可能出现的物体打上标签,我们更关注的是如何摆脱区分物体的类别属性而直接将其打上标签。因此,我们的问题被简化为如何能区分出点云中的单个物体,并且将它们分割出来。
这个问题的最大难度是对未知物体的分割,因为本身并不存在于标记数据中,但在推理过程中,该部分数据又特别重要。
这个问题也可以被解读于:我们如何通过对现实世界中的部分信息来进行训练学习,实现对激光点云中的实例物体进行推理。目前先进的方法也有通过语义分割的训练预测器来解决这个问题,这些方法通过不同的启发式方法和优化过程来对点进行聚类,这些方法依然需要标注数据。
这篇文章的主要贡献是提出了一个全新的无监督不需要明确物体种类的实例分割算法。鉴于目前表示学习的发展,我们可以使用自监督的方法来抽取出点对特征,并且通过邻接图的方式来表示相邻点对之间的相似性。然后,我们在不需要任何标注的情况下,通过图割的算法来从背景信息中抽取出实例物体。
我们将Semantic KITTI benchmark进行了扩展,分别在已经物体类别和未知物体类别下评估了我们的算法。实验结果证明了相比于State-Of-Art算法,我们的算法可以在没有标签,没有语义背景去除的情况下进行实例分割,并有较好的算法性能。
算法流程

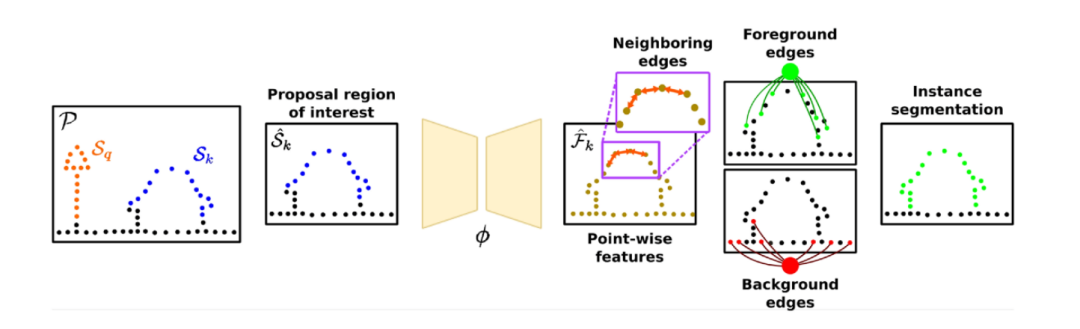
图2:算法整体流程图
算法整体流程可以用上图来表示。我们通过Graph-Cut和自监督学习特征的方法来讲场景中的实例区分开。我们将点云整体表示成图,通过自监督网络计算出点显著性分布图,来对前景图和后景图进行采样,实现实例分割。因为点云中可能存在多个物体实例,这也给前后背景分离增加了难度。
因此,我们改变策略,先对点云中的地面进行分割,区分出地面点和非地面点,并对非地面点进行聚类。然后我们迭代地遍历每个地方,并对每个兴趣点附近规划出一个立方体区域。对于这个区域,我们将立方体中的实例作为前景对象,地面点和其他实例点作为背景区域。然后我们可以通过该区域来构建图,并依据图分割成前景和背景。
A. 实例提案
为了更好地分割出实例,我们的算法依赖于初始猜测(也被称为提案),随后可以被精细化为更好地分割。为了和之前的工作(SegContrast)的符号保持统一,我们定义实例如下:对于一组N个点的点云P={p1,p2,...,pN},我们通过地面分割的算法将它分为地面点G和非地面点P′,然后通过HDBSCAN聚类算法来将非地面点聚类成m个类,被定义成m个类的过程我们则称为提案。其中I={S1,...Sm} ,这里Sk∈P′并且对于不属于同类来说,Sk∩Sl=∅,l≠k。
图3:点云中实例分割提案
如图3所示,这些分割是实例表示的起点,并不是实例表示的最后结果。我们的算法之后将其映射到特征图中来计算相同提案中不同点之间的相似性。之后,我们将从这个背景图中分割出这些物体来做为实例分割。
B.自监督特征
我们的方法充分运用了自监督表征学习来抽取出点对特征。我们使用MinkUNet来作为特征抽取模型。该方法是一种自监督方法,依赖于对场景中的地面点进行去除,并对剩余点进行聚类。它的对比损失函数逐段运用,通过判别的方式学习出特征空间。
对于每一个学习出的提案Sk∈I,我们定义兴趣区域S^∈P,然后用SegContrast预训练模型抽取出点对特征F^k,之后我们通过这些特征来计算出点对相似性,而不是直接计算出其测量的特征。到此,我们有描述性特征可以用来识别实例段和背景之间的差异。
C. Saliency Maps.
Saliency Map通常是分析网络学习到的特征空间。为了计算显著性地图,我们通常计算它的梯度并可视化对它影响更大的区域。这些年也有人通过transformer来提取和制作对应的可视化,即使在没有标签的情况下也可以很好的计算出对应的对象边界。尽管在SegContrast中使用的是稀疏卷积神经网络,我们观察到它也可以在显著性图中找到实例注意力的地方。这种显著性的值可以更好地解释为哪里是前景,哪里是背景,是后面用于GraphCut的随机初始种子。
对于前面的实例提案,我们计算出每个特征向量中的均值δ。
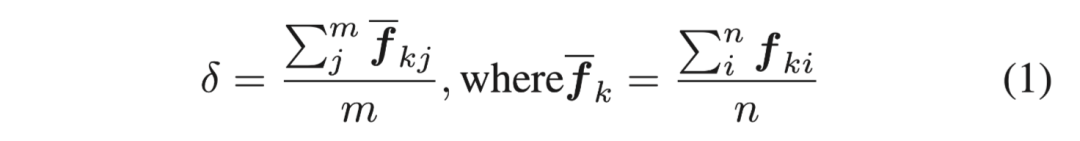
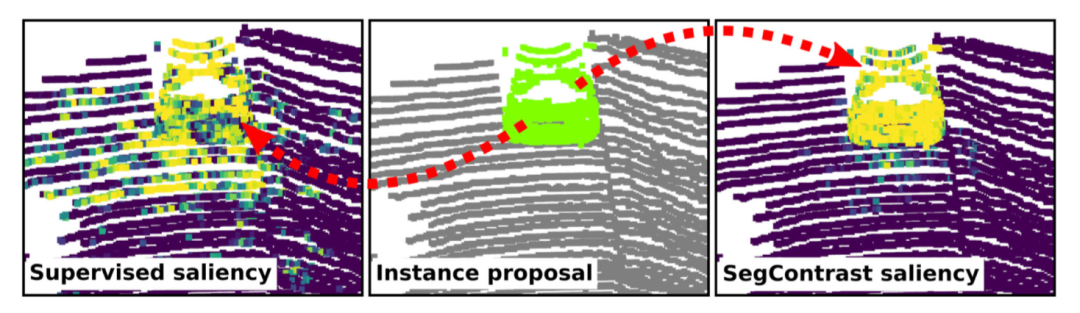
图4. 受监督的语义分割网络与用SegContrast进行自我监督的网络,两个网络得到的显著性图(saliency map,左图与右图)与该算法得到的proposal实例点特征图(中间)进行对比。该图用不同颜色区分不同物体,因此最好查看原本彩图
通过计算δ的梯度变化,我们得到每个提案附近的显著性图。如上图所示,通过该方法得到的显著性地图可以更精细地区分出场景中的实例对象。
D. Seeds Sampling.
我们采用实例提案Sk和他们对应的显著性值来做前景和背景信息的采样。由于实例信息中对应的是不同的物体,所以固定数量的采样方式并不一定合适。因此,我们依据提案Sk和他们对应的兴趣区域大小来定义具体的采样点数量。这里我们选取τ_f=nf/γf作为前景种子,选取τ_b=nb/γb作为背景种子,这里γf和γb都是预先定义的参数。
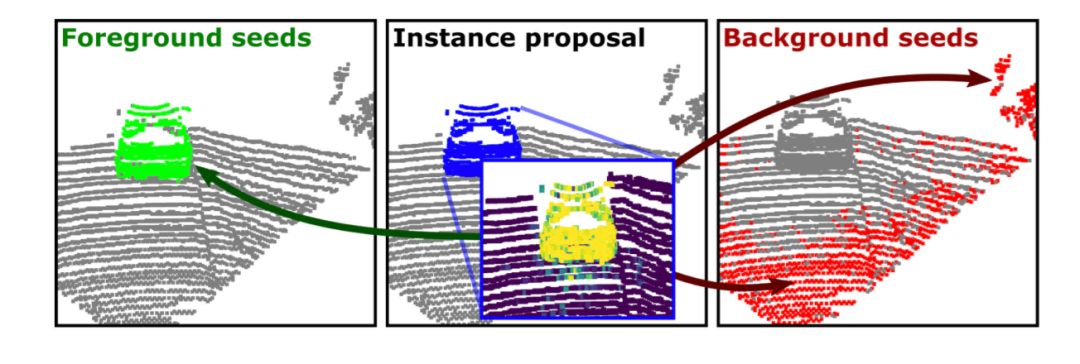
图5.我们基于蓝色点的提议下,将前景点和背景点计算出来,分辨用绿色和红色来表示.
上图是种子信息选取的过程。我们对每个前景种子周围的k个邻居点进行采样,来计算前景信息的相似性。同时我们在提案之内删除任何背景种子,在提案之外删除任何前景种子来避免显著性图中产生异常值。通过这样的方式,我们可以避免错误的种子采样从而影响到图割算法的性能。
E.图割算法
为了更好地从点云中分割出实例对象,我们采用图割算法,一种用于图像分割的经典算法,现在用在点云数据上。这种方法主要通过一种图的表示来描述各个节点中和他们邻节点之间的关系,从而找出前景和背景数据。然后,我们再对图用最小切歌方法,切除当中最弱的关系数据。我们采用SegContrast算法来计算每个点上的特征,然后计算相邻点之间的相似性作为非终端边缘。最后我们计算显着性图以对种子进行采样并确定点和终端节点之间的边。
在我们的定义下,一个图包含一系列的节点Z={z1,...,zn+2},其中每个节点表示的一个点信息在提出的区域Sk中,对应着n个点和2个虚拟的节点,分别代表着前景信息和背景信息。
(1)终端边缘
每一个点都有两个虚拟的边缘节点,我们根据这些节点的归类方式对这些变进行加权。每一个边缘的初始概率我们设置成0,然后选择的节点和对应的终端边缘节点我们设置为1.0。最后,节点i和一个终端节点t的权重可以定义为:
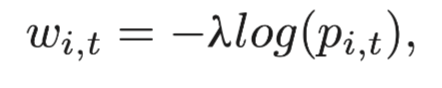
其中λ是预先定义的参数,pi,t的定义表示节点i属于终端节点t的概率值的大小。
(2)非终端边缘
对于非终端节点,我们通过坐标选取每个点和它周围的k歌邻居点来确定变。为了对边进行加权,我们计算每个点的特征并计算它与相邻点之间的差异。我们使用L1范数来定义fi和fj之间的特征区别。
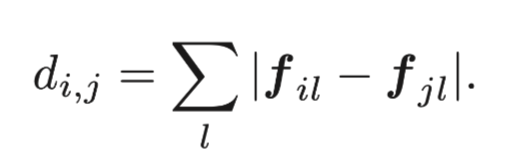
两点之间的权重也是依据给定出的dij计算出来:
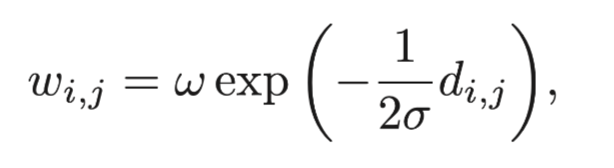
其中σ和w都是预先定义的参数。按照以上的定义,我们可以将点和边构建清楚,然后通过最小图割算法来将实例从背景信息中分割出来。我们迭代地重复以上过程,最后将物体从背景信息中分割出来。
实验分析
在这一节中,我们主要介绍我们基于SemanticKITTI的扩展。
A. 问题定义
现有的实例分割模型假设在推理过程中出现的所有对象类都被手动标记并在训练时出现。我们将这些对象类称为已知类。在本文中,我们还想关注那些可能只在推理过程中出现的对象实例分割,我们把它们表示为未知类。
更正式地说,所有对象类的集合X有可能很大,并且许多实例会很少出现。在实践中,我们无法记录、标记和评估在所有可能的对象类别上的算法性能,因为这些会出现在对象类别分布中的拖尾类。因此,实际上只有对这些类别的固定子集进行标记才是可行的。
为此,我们进行了如下划分。我们将SemanticKITTI提供的标签用于整个数据集(训练集、验证集和测试集)的已知类集。这个集合包含经常出现的物体类别,如汽车、人、卡车和类似的物体。我们只在验证集和测试集中标注一个额外的、不相交的对象实例集,即未知的对象实例U⊂X, 且U∩K=∅。
因此,我们的测试集提供了一个“代理”,用于评估算法在只在很少情况下出现的未知物体上的性能。我们注意到,这些实例的例子可能出现在训练集和验证集中,但没有被标记为实例。
由于我们解决了实例分割的问题,我们只标记了事物(thing)类:在文献[21]中,东西(stuff)类被认为是不可计数的类,例如,植被或道路。而事物类,如汽车和行人,通常有明确的边界,在单个扫描中是可见的,并且是可计算的。
B. 评价
对于开放世界的实例分割,我们评估了 算法能将LiDAR点云分解为单独一组物体实例的能力。为了量化性能,一种可能性是采用基于召回(recall)的变体:泛光质量(Panoptic Quality, PQ)的,未知质量(Unknown Quality, UQ),他们基于召回(recall)用的方法代替了识别质量(recognition quality,RQ)项(F1-Score)。
然而,这种度量将点云的东西(stuff)区域作为一个单一的实例,这并不可取[29]。例如,植被类可以被分解成几个实例(树干、小灌木)--这些没有被手工注释者标记,但可以依据任务的不同,被认为是有效的实例,例如, segment-based LiDAR odometry或SLAM[16]。
我们转而采用LiDAR分段和跟踪质量( LiDAR Segmentation and Tracking Quality,LSTQ)指标。它由两个术语组成,一个分类Scls和一个分割Sassoc。然而,由于我们任务与类别无关,我们删除了Scls,只依靠Sassoc来评估实例段的质量如何。
关联项Sassoc衡量我们将点分配给它们的实例的程度,与语义无关:
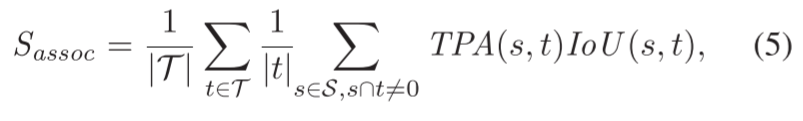
其中,IoU输入是真值物体t∈T和预测s∈S对、这个对通过真阳性关联(TPA)、假阴性关联(FNA)和假阳性关联(FPA)的集合来计算的。这些集合是以class-agnostic的方式评估的,但与Aygün等人[1]的工作不同,因为这些集合由每个扫描都进行计算得来而不是按整个序列计算的。
直观地说,TPA集量化了有多少个点被正确地分配给它们相应的实例,TPA和FPA集表面两种不同类型的“点到实例”关联错误。更确切地说,TPA集包含所有相互重叠的点。FPA集表示s中所有与t不重叠的点,最后,FNA代表属于t中但不包含在s中的点(Aygün等)。
关联项是class-agnostic的,并且只表征将点分配给标记的物体实例的表现如何。这使我们能够评估区别于语义的实例分割,使这个指标独特地适用于开放世界LiDAR实例分割的评估。
C. 开放世界的SemanticKITTI数据集和基准
为了合理评价将出现在对象分布中拖尾类物体分割出来的算法,其对应数据集应该为最常见的物体(如交通参与者)提供实例标签,并为东西(stuff)类提供语义标签。SemanticKITTI[3]或nuScenes-lidarseg[7]提供了这样的标签,与之相反的是对象检测数据集,只提供三维边界框。
我们选择了SemanticKITTI数据集,该数据集扩展了KITTI数据集,对每个LiDAR扫描都进行了密集的逐点语义和实例标签。它包含训练中的23,000个标记扫描和测试集中的20,000个标记扫描,为6,315个属于几个已知物体类别的物体实例,总共418,649个边界框,提供语义和物体实例标签。
我们建立了开放世界的SemanticKITTI基准,该基准适合于评估开放世界环境中的算法性能。我们用3,587个实例扩展了SemanticKITTI的隐藏测试集,总共有292,871个额外的对象实例标签,这些对象类别不一定属于原来的对象类别中语义类别--未知对象。
参见Tab. I以了解关于类别分布的统计数据。我们还在验证集中为未知类的实例贴上标签,但是只提供了一种用服务端(server-side)评估的方式来评估性能,以便在训练时保持实例的未知。

V. 试验评估
我们工作的主要重点是一个与类别无关的实例分割。与以前的方法不同,我们的工作不需要实例或语义标签来去除背景。我们展示了我们的实验,以显示我们的方法它能够在不去除语义背景的情况下分割实例的能力,并且与最先进的监督方法相比,性能不弱下风。
在我们所有的实验中,我们使用相同的参数,这些参数根据经验来定义。对于实例,我们使用预先定义的大小为实例周围1米的余量来定义感兴趣的区域。对于种子采样,我们使用γf=2, γb=2。对于GraphCut,我们使用σ=1,ω=10和λ=0.1,我们选择k=8个最近的邻居来定义非终端的边缘,并建立图形。对于自我监督的预训练模型,我们使用SegContrast[28]中描述的相同预训练。训练了200个epochs。
我们在两种设置中比较了我们的方法:只使用来自GraphCut的分割,命名为Ours;以及使用后处理步骤,即从用于生成proposals的地面分割中过滤点,命名为Ors†。我们将我们的结果与不同的无监督聚类方法和基于监督学习的方法进行比较。
对于聚类方法,我们使用与我们的方法相同的实例proposals过程,即去除地面,然后对剩余的点进行聚类。我们评估了HDBSCAN[8]和Euclidean聚类[30]。此外,我们还比较了一种在点云的鸟瞰图上操作的技术、带有快速移动算法的聚类以及一种基于快速范围图像的建议生成方法。
此外,我们评估了两种基于监督学习的方法:Hu等人提出的方法[20]用语义分割网络去除背景,并给定一个学习的对象性值对剩余的点进行聚类,还有一种完全数据驱动的方法4D-PLS[1]用于封闭世界的实例分割。
A. 关联质量
这个实验评估了测试集上的预测实例和基础真值实例之间的关联。结果表明,我们的方法,即使不使用标签,也达到了非常先进的性能。
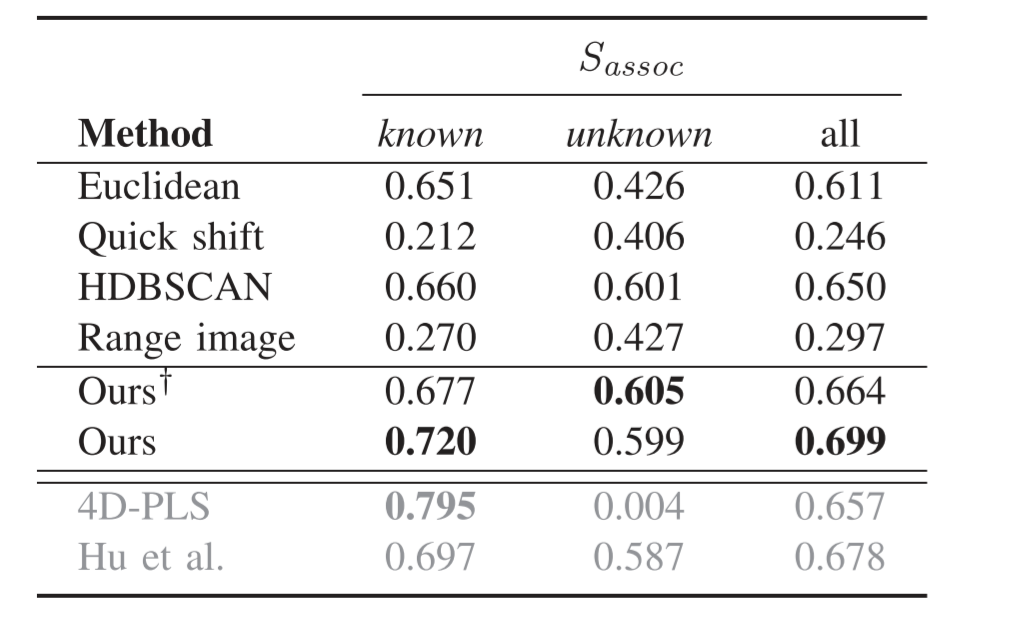
表二显示了用度量对不同方法,在已知和未知实例以及class-agnostic的情况(即已知和未知)三种情况下的性能评估。通过比较不同的聚类方法,我们发现,HDBSCAN呈现出最好的性能,这也侧面说明了我们选择使用它来进行实例proposal的理由。
4D-PLS方法在已知实例方面取得了最好的性能,而我们的方法在无监督的情况下具有最好的性能。我们的方法在很大程度上改善了HDBSCAN的实例建议,甚至超过了Hu的方法。对于未知实例,有监督的方法的性能下降。我们的方法在去除地面点后,对未知实例取得了最好的性能。
当看class-agnostic的情况时,我们的方法在去除地面的情况下比无监督方法好,不去除地面也比有监督方法好。
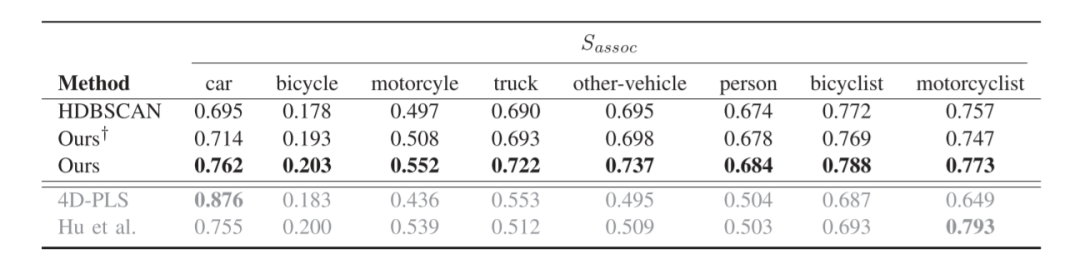
表三显示了每个已知类别的Sassoc。监督方法的性能在最有代表性的类别,即汽车上呈现出最佳性能。对于其他类别,它们的性能会下降,因为这些类别在训练集中的样本较少。我们的方法在大多数类别上超过了HDBSCAN实例proposal和监督方法。通过使用无监督学习的特征,我们的方法对经常出现的类的过拟合程度较低,更适合于对class-agnostic的实例分割。
B. 实例分割质量
本实验评估了预测实例和地面实况之间的交叉联合(intersection-over-union, IoU)和召回率。我们通过不同的IoU阈值来计算IoU和召回率,并计算不同阈值的平均值来评估方法的整体性能。
表四显示了不同阈值的IoU和召回率的结果。在高阈值下,即IoU90,有监督的方法比其他方法表现更好。由于4D-PLS是一种全景分割方法,其在所有的阈值上对已知实例取得了最好的性能。然而,它在分割未知实例时失败了。随着阈值的降低,我们的方法性能越来越接近监督方法,并在未知实例中超过了它们。在整体评估中,我们的方法与监督方法不相上下,并且在召回率方面表现最好。
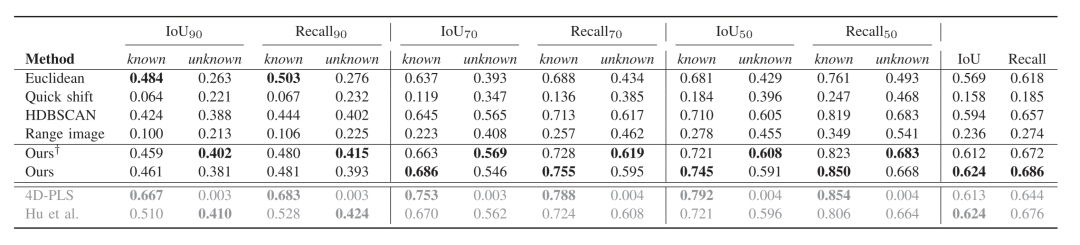
C. 限制条件
此外,我们还比较了我们的方法在有和没有去除地面后处理的情况下,讨论了其局限性。从上一节中可以看出,在没有去除地面后处理的情况下,我们的方法取得了最好的整体性能,特别是对已知实例。然而,在去除地面的情况下,它在未知实例上的表现更好。
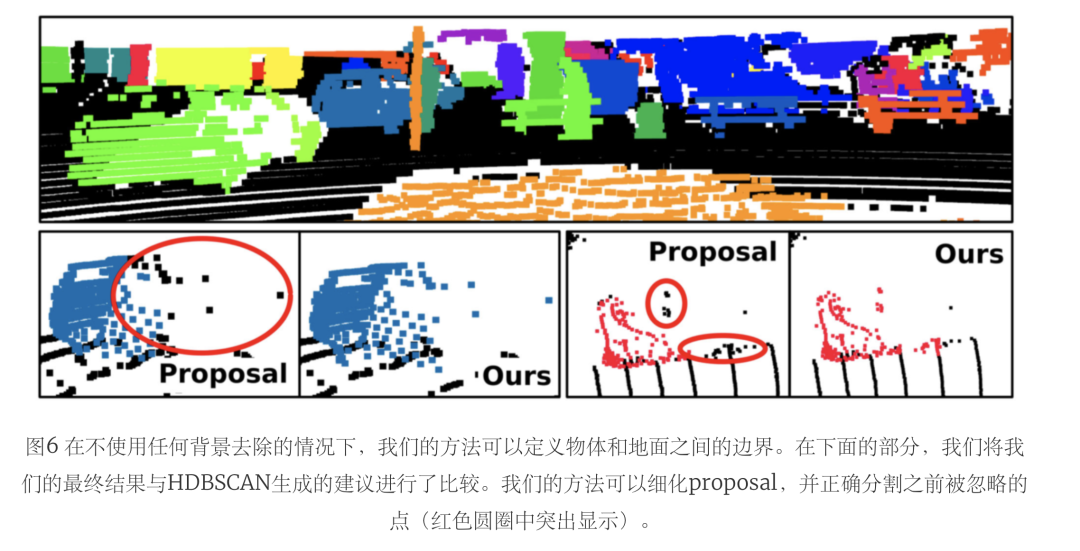
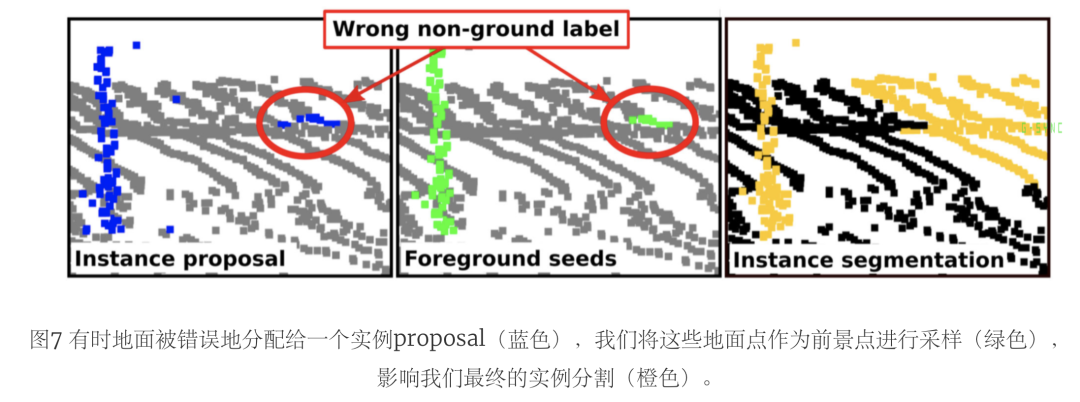
表五将这两种设置与HDBSCAN proposal进行了比较。尽管去除地面点会导致对未知实例的更好分割,但它对已知实例的影响更大,使性能下降了很多。在图7中,我们举了一个例子来解释这种行为。由于地面分割是由一个无监督的方法完成的,它可能会有点被错误分配为地面和非地面。
因此,我们的方法可以通过正确分配以前被错误地认为是地面的实例点来改善分割。然而,由于地面分割的不完善,一些proposal可能会将地面视为实例点。在这种情况下,我们的方法可能会将地面点作为前景种子进行采样,导致会将更广泛的地面区域分割做为实例的一部分。
通过后处理去除地面,我们过滤了被采样为前景的地面区域,同时也过滤了被正确分配为实例的点,这些点之前被错误地标记为地面。因此,我们的方法的主要局限性依赖于用于采样前景和背景种子的初始proposal。

结论
在本文中,我们提出了一种新的无监督的、class-agnostic的实例分割方法。我们的方法使用无监督聚类来定义实例proposal,并使用图形优化算法来完善这些建议,以便更恰当地进行实例分割。我们的方法将点云表示为一个图,并利用自我监督的表示学习法来提取点的特征,从而映射图中的点邻域相似性。
这使我们能够从背景点中分离出前景实例,而不需要标签。此外,我们还提出了一个新的开放世界数据集,以评估已知和未知实例类的class-agnostic实例分割,并提出了该基准的评估程序。实验表明,我们的方法更适合于class-agnostic的实例分割,因为它取得了与最先进的监督方法相竞争的性能,甚至在未知类中超过了它。我们希望我们的工作能激励对自监督实例分割的进一步研究,并且希望我们的基准对研究界能有所贡献。
审核编辑:刘清
-
做一个网关需不需要ucos系统?2020-05-13 2707
-
不需要场效应管的多路传输开关2009-04-13 1121
-
机器学习不需要数学,调包就行?2018-09-30 5928
-
华盛顿大学推出一部不需要电池的手机2018-12-04 1539
-
NBIoT智能门锁,真正不需要网关的智能门锁2020-06-22 9834
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6821
-
不需要电感器2021-04-29 905
-
基于无监督空间一致性约束的心脏MRI分割2021-06-27 986
-
快速HAC聚类算法的改进及应用于无监督语音分割2021-07-26 1090
-
深度学习部分监督的实例分割环境2021-10-21 2685
-
首个无监督3D点云物体实例分割算法2022-11-09 3701
-
一种不需要复杂新硬件的监测呼吸健康的设备2023-02-03 2270
-
AI算法说-图像分割2023-05-17 3009
-
TLDR: 视频分割一直是重标注的一个task,这篇CVPR 2023文章研究了完全不需要标注的视频物体分割。2023-07-12 1363
-
CVPR 2023 | 完全无监督的视频物体分割 RCF2023-07-16 1573
全部0条评论

快来发表一下你的评论吧 !
