

文本分类中处理样本不均衡和提升模型鲁棒性的trick
描述
写在前面
文本分类是NLP中一个非常重要的任务,也是非常适合入坑NLP的第一个完整项目。
文本分类看似简单,但实则里面有好多门道。作者水平有限,只能将平时用到的方法和trick在此做个记录和分享,并且尽可能提供给出简洁、清晰的代码实现。希望各位看官都能有所收获。
本文主要讨论文本分类中处理样本不均衡和提升模型鲁棒性的trick。
1. 缓解样本不均衡
样本不均衡现象
假如我们要实现一个新闻正负面判断的文本二分类器,负面新闻的样本比例较少,可能2W条新闻有100条甚至更少的样本属于负例。这种现象就是样本不均衡。
在样本不均衡场景下,样本会呈现一个长尾分布(如图中所示会出现长长的尾巴),头部的标签包含了大量的样本,而尾部的标签拥有很少的样本,这种现象也叫长尾现象。岔开说下,听过二八定律的人大多知道长尾现象其实很普遍,比如80%的财富掌握在20%的人手中。

样本不均衡问题
样本不均衡会带来很多问题。模型训练的本质是最小化损失函数,当某个类别的样本数量非常庞大,损失函数的值大部分被其所影响,导致的结果就是模型分类会倾向于该类别(样本量较大的类别)。
咱拿上面文本分类的例子来说明。现在有2W条用户搜索的样本,其中100条是负面新闻,即负样本,那么当模型全部将样本预测为正例,也能得到 99.5% 的准确率。但实际上这个模型跟盲猜没什么区别,而我们的目的是让模型能够正确的区分正例和负例。
1.1 模型层面解决样本不均衡
在模型层面解决样本不均衡问题,可以选择加入 Focal Loss 学习难学样本,具体原理可以参考文章《何恺明大神的「Focal Loss」,如何更好地理解?》[1]。
1.1.1 Focal Loss pytorch代码实现
class FocalLoss(nn.Module): """Multi-class Focal loss implementation""" def __init__(self, gamma=2, weight=None, reduction='mean', ignore_index=-100): super(FocalLoss, self).__init__() self.gamma = gamma self.weight = weight self.ignore_index = ignore_index self.reduction = reduction def forward(self, input, target): """ input: [N, C] target: [N, ] """ log_pt = torch.log_softmax(input, dim=1) pt = torch.exp(log_pt) log_pt = (1 - pt) ** self.gamma * log_pt loss = torch.nn.functional.nll_loss(log_pt, target, self.weight, reduction=self.reduction, ignore_index=self.ignore_index) return loss
代码链接:blog_code/nlp/focal_loss.py[2]
1.2 数据层面解决样本不均衡
假如我们的正样本只有100条,而负样本可能有1W条。如果不采取任何策略,那么我们就是使用这1.01W条样本去训练模型。从数据层面解决样本不均衡的问题核心是通过人为控制正负样本的比例,分成欠采样和过采样两种。
1.2.1 欠采样
简单随机
欠采样的基本做法是这样的,现在我们的正负样本比例为1:100。如果我们想让正负样本比例不超过1:10,那么模型训练的时候数量比较少的正样本也就是100条全部使用,而负样本随机挑选1000条。
通过这样人为的方式,我们把样本的正负比例强行控制在了1:10。需要注意的是,这种方式存在一个问题:为了强行控制样本比例我们生生的舍去了那9000条负样本,这对于模型来说是莫大的损失。
迭代预分类
相比于简单的对负样本随机采样的欠采样方法,实际工作中更推荐使用迭代预分类的方式来采样负样本。具体流程如下图所示:
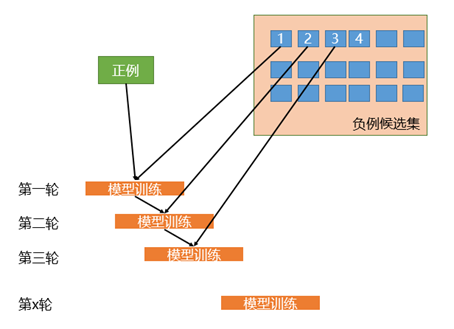
首先我们会使用全部的正样本和从负例候选集中随机采样一部分负样本(这里假如是100条)去训练第一轮分类器;
然后用第一轮分类器去预测负例候选集剩余的9900条数据,把9900条负例中预测为正例的样本(也就是预测错误的样本)再随机采样100条和第一轮训练的数据放到一起去训练第二轮分类器;
同样的方法用第二轮分类器去预测负例候选集剩余的9800条数据,直到训练的第N轮分类器可以全部识别负例候选集,这就是使用迭代预分类的方式进行欠采样。
相比于随机欠采样来说,迭代预分类的欠采样方式能最大限度地利用负样本中差异性较大的负样本,从而在控制正负样本比例的基础上采样出了最有代表意义的负样本。
欠采样的方式整体来说或多或少的会损失一些样本,对于那些需要控制样本量级的场景下比较合适。如果没有严格控制样本量级的要求那么下面的过采样可能会更加适合你。
1.2.2 过采样
过采样和欠采样比较类似,都是人工干预控制样本的比例,不同的是过采样不会损失样本。
还拿上面的例子,现在有正样本100条,负样本1W条,最简单的过采样方式是我们使用全部的负样本1W条。但是,为了维持正负样本比例,我们会从正样本中有放回的重复采样,直到获取了1000条正样本,也就是说有些正样本可能会被重复采样到,这样就能保持1:10的正负样本比例了。这是最简单的过采样方式,这种方式可能会存在严重的过拟合。
实际的场景中会通过样本增强的技术来增加正样本。
2. 提升模型鲁棒性
提升模型鲁棒性的方法有很多,其中对抗训练、知识蒸馏、防止模型过拟合和多模型融合是常见的稳定提升方式。
2.1 对抗训练
对抗训练是一种能有效提高模型鲁棒性和泛化能力的训练手段,其基本原理是通过在原始输入上增加对抗扰动,得到对抗样本,再利用对抗样本进行训练,从而提高模型的表现。
由于自然语言文本是离散的,一般会把对抗扰动添加到嵌入层上。为了最大化对抗样本的扰动能力,利用梯度上升的方式生成对抗样本。为了避免扰动过大,将梯度做了归一化处理。
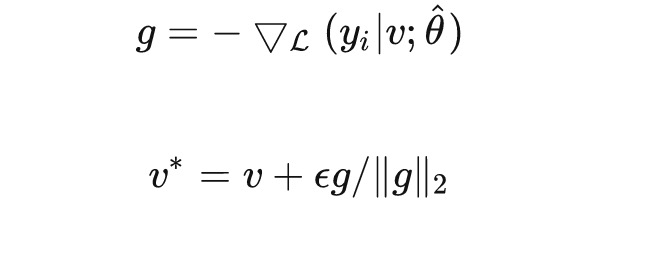
其中, 为嵌入向量。在实际训练过程中,我们会在训练完一个batch的原始输入数据时,保存当前batch对输入词向量的梯度,得到对抗样本后,再使用对抗样本进行对抗训练。
2.1.1 对抗训练pytorch代码实现
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
训练中加入几行代码
# 初始化 fgm = FGM(model) for batch_input, batch_label in data: # 正常训练 loss = model(batch_input, batch_label) loss.backward() # 对抗训练 fgm.attack() # 修改embedding # optimizer.zero_grad() # 梯度累加,不累加去掉注释 loss_sum = model(batch_input, batch_label) loss_sum.backward() # 累加对抗训练的梯度 fgm.restore() # 恢复Embedding的参数 optimizer.step() optimizer.zero_grad()
代码链接:blog_code/nlp/at.py [3]
2.2 知识蒸馏
与对抗训练类似,知识蒸馏也是一种常用的提高模型泛化能力的训练方法。
知识蒸馏这个概念最早由Hinton在2015年提出。一开始,知识蒸馏通往往应用在模型压缩方面,利用训练好的复杂模型(teacher model)输出作为监督信号去训练另一个简单模型(student model),从而将teacher学习到的知识迁移到student。
Tommaso在18年提出,若student和teacher的模型完全相同,蒸馏后则会对模型的表现有一定程度上的提升。
2.3 防止模型过拟合
2.3.1 正则化
L1和L2正则化
L1正则化可以得到稀疏解,L2正则化可以得到平滑解,原因参考文章《为什么L1稀疏,L2平滑?》[4]。
2.3.2 Dropout
Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
Dropout为什么能防止过拟合,可以通过以下几个方面来解释:
它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力;
类似于bagging的集成效果;
对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次dropout其实都相当于增加了样本。
Dropout在测试时,并不会随机丢弃神经元,而是使用全部所有的神经元,同时,所有的权重值都乘上1-p,p代表的是随机失活率。
2.3.3 数据增强
数据增强即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
1)从数据源头采集更多数据;
2)复制原有数据并加上随机噪声;
3)重采样;
4)根据当前数据集估计数据分布参数,使用该分布产生更多数据等。
2.3.4 Early stopping
在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。因为在初始化网络的时候一般都是初始为较小的权值,训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
2.3.5 交叉验证
交叉验证的基本思想就是将原始数据进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。我们常用的交叉验证方法有简单交叉验证、S折交叉验证和留一交叉验证。
2.3.6 Batch Normalization
一种非常有用的正则化方法,可以让大型的卷积网络训练速度加快很多倍,同时收敛后分类的准确率也可以大幅度的提高。
BN在训练某层时,会对每一个mini-batch数据进行标准化(normalization)处理,使输出规范到 的正态分布,减少了Internal convariate shift(内部神经元分布的改变),传统的深度神经网络在训练是每一层的输入的分布都在改变,因此训练困难,只能选择用一个很小的学习速率,但是每一层用了BN后,可以有效的解决这个问题,学习速率可以增大很多倍。
2.3.7 选择合适的网络结构
通过减少网络层数、神经元个数、全连接层数等降低网络容量。
3.多模型融合
Baggging &Boosting,将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好,三个臭皮匠顶一个诸葛亮。
-
pyhanlp文本分类与情感分析2019-02-20 3404
-
NLPIR平台在文本分类方面的技术解析2019-11-18 2433
-
文本分类中CTM模型的优化和可视化应用研究2017-11-22 1432
-
不均衡数据集上基于子域学习的复合分类模型2017-12-12 853
-
结合BERT模型的中文文本分类算法2021-03-11 1823
-
融合文本分类和摘要的多任务学习摘要模型2021-04-27 1658
-
基于不同神经网络的文本分类方法研究对比2021-05-13 1401
-
胶囊网络在小样本做文本分类中的应用(下)2021-09-27 3206
-
基于主题分布优化的模糊文本分类方法2021-05-25 1216
-
如何解决样本不均的问题?2021-05-26 3163
-
基于LSTM的表示学习-文本分类模型2021-06-15 1330
-
基于注意力机制的新闻文本分类模型2021-06-27 1667
-
PyTorch文本分类任务的基本流程2023-02-22 2170
-
鲁棒性的含义以及如何提高模型的鲁棒性?2023-10-29 6230
-
深度学习模型的鲁棒性优化2024-11-11 2893
全部0条评论

快来发表一下你的评论吧 !
