

可视化操作的告警软件背景现状
描述
云原生报警背景现状
在云原生的生态下,kubernetes 已经被越来越多地应用到公司实际生产环境中。在这样的生态环境下系统监控、业务监控和数据库监控指标都需要在第一时间获取到,目前用的最多的也是prometheus、exporter、grafana、alertmanager这几个软件组建起来构建自己的监控系统。以上这几款软件组建监控系统比较容易。可是在告警这一环节,只能依靠终端vim来编辑规则文件。今天给大家推荐一款可以可视化操作的告警软件,这个软件是将prometheus和alertmanager进行了结合可以把数据分散存储起来,通过可视化的操作添加 prometheus 告警规则,这个软件就是 grafana 公司开发的mimir。
Mimir 是做什么的
Mimir 为 prometheus 提供水平可扩展、高度可用、多租户的长期存储。它的工作架构如下图展示:
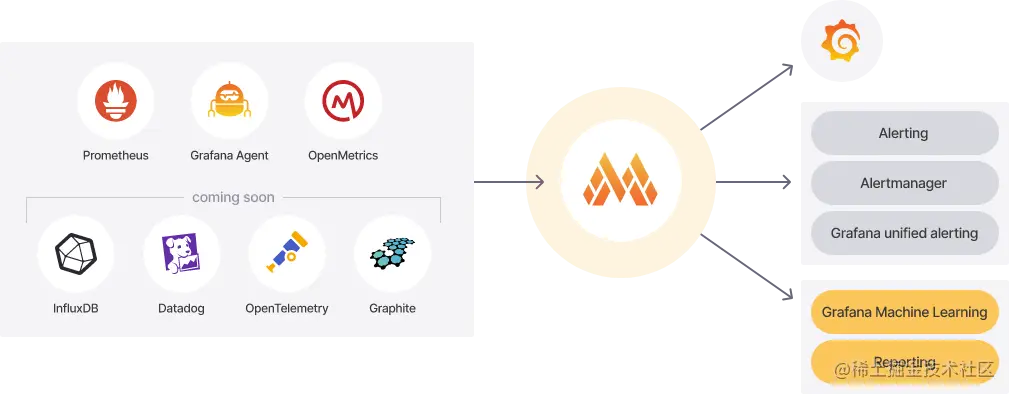 Mimir 架构
Mimir 架构
存储 Prometheus metrics 使用 Prometheus 从应用程序中提取指标,并将这些指标远程写入 Mimir,或者使用 Grafana Agent、PrometheusAgent 或其他 Prometheus 远程写入兼容软件直接发送数据。
扩展性强 Mimir 群集不需要手动进行切分、复制或重新平衡。要增加容量,只需向集群添加新实例。
在 grafana 中可视化 Mimir 允许用户运行查询,通过记录规则创建新数据,并利用租户联合在多个租户之间设置警报规则。所有这一切都可以与 Grafana 仪表盘联系在一起。
Mimir 组件都有哪些,它们是做什么的?
| 类型 | 组建名称 |
|---|---|
| 可选 | alertmanager,ruler,overrides-exporter,query-scheduler | |
| 必选 | compactor,distributor,ingester,querier,query-frontend,store-gateway |
以上列举出了 Mimir 的一些组件,下面介绍一下它们分别是做什么的
Compactor(数据压缩器,无状态应用)
compactor 通过组合块提高查询性能并减少长期存储使用。负责以下工作:
将给定租户的多个数据块压缩为单个优化的较大数据块。这可以消除数据块并减小索引的大小,从而降低存储成本。查询更少的块更快,因此也提高了查询速度。
保持每租户的数据存储桶索引更新,存储桶索引被queriers、store-gateway和rulers使用,用来发现数据中新增加的数据块和删除数据块
删除那些不再在可配置保留期内的数据块。
工作原理
按租户以固定、可配置时间间隔进行数据块压缩。垂直压缩将接收器在同一时间范围(默认情况下为 2 小时内)上传的租户的所有块合并到单个块中。它还对最初由于复制而写入 N 个块的样本执行重复数据消除。垂直压缩减少了单个时间范围内的块数。垂直压缩后触发水平压缩。它将几个具有相邻范围周期的块压缩为一个较大的块。水平压缩后,关联块块的总大小不变。水平压缩可以显著减小存储网关保存在内存中的索引和索引头的大小。如下图:
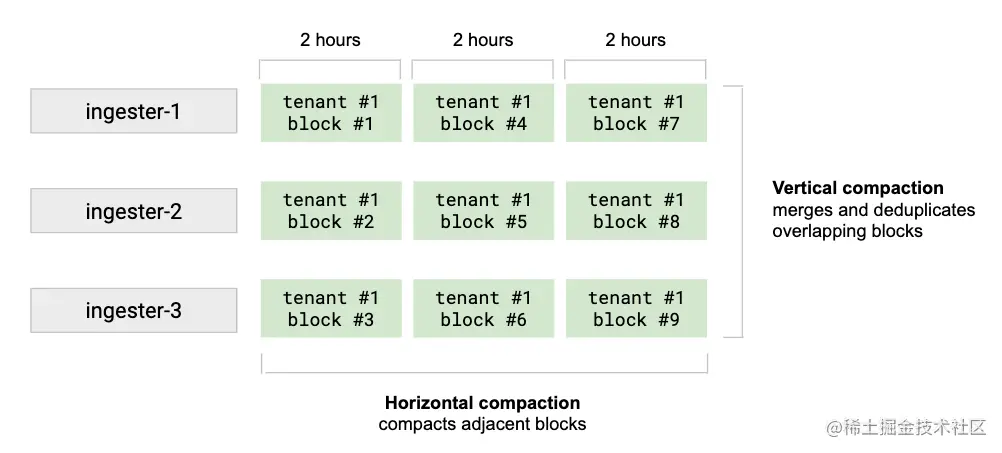 压缩器
压缩器
缩放
可以针对具有大型租户的集群调整压缩。配置指定了压缩程序在按租户压缩时如何运行的垂直和水平缩放。垂直缩放:-compactor.compaction-concurrency选项配置了单个压缩实例中运行的最大并发压缩数。每次压缩使用一个 CPU 内核。水平缩放:默认情况下,租户区块可以使用任何 Mimir 进行数据压缩。当通过将-compactor.compactor-tenant-shard-size(或其相应的 YAML 配置选项)设置为大于 0 且小于可用 compactors 实例数量的值来启用压缩随机分片时,仅指定 compactor 的数量才有资格为给定的租户压缩数据块。
压缩算法
Mimir 使用了一种称为拆分和合并的复杂压缩算法。通过设计,拆分和合并算法克服了时间序列数据库(TSDB)索引的局限性,并且它避免了压缩块在任何压缩阶段对一个非常大的租户无限期增长的情况。这种压缩策略是一个两阶段的过程:拆分和合并,默认配置禁用拆分阶段。
拆分阶段第一级是压缩。例如:2 小时内 compactor 将所有源数据库分割成 N 个组(通过-compactor.split-groups设置)。对待每一个组 compactor 压缩数据块而不是生成单个的结果块,输出 M 个分割块(通过-compactor.split-and-merge-shards设置)。每个分割块只包含了属于 M 碎片中给定碎片的序列子集。在分割阶段结束时,compactor 会参考块文件(meta.json)中各自碎片信息的引用来产生N*M个数据块。Compactor 合并每个碎片的分割块,将压缩给定碎片的所有 N 个分割块。合并将块数从N*M减少到M。对于给定的压缩时间范围,每个 M 碎片都将有一个压缩块。如下图所展示的说明
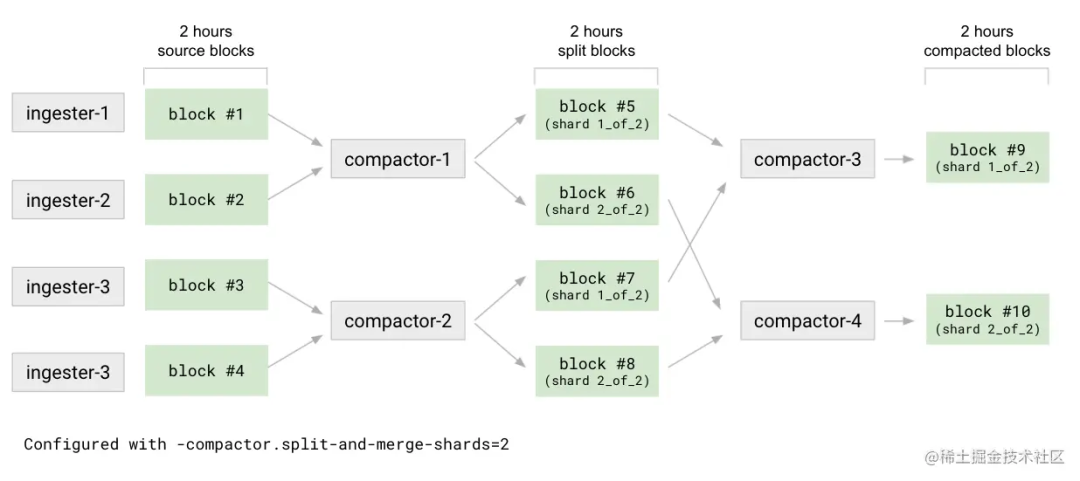
压缩共享
Compactor 将来自单租户或者多租户的压缩作业进行碎片化处理。单个租户的压缩可以由多个压缩器实例分割和处理。无论压缩器实例的数量何时增加或减少,租户和任务岗位都会在可用压缩器实例中重新分配,而无需任何手动干预。压缩器使用哈希环进行分片。在启动时,压缩器生成随机令牌并将自身注册到压缩器哈希环。在运行时,它每隔一段时间(通过-compactor.compaction-interval-compactor.compaction-interval设置)定期扫描存储桶,以发现每个租户的存储和压缩块中的租户列表,这些租户的哈希与哈希环中分配给实例本身的令牌范围相匹配。
阻止删除
成功压缩后,将从存储中删除原始块。块删除不是立即进行的;它遵循两步过程:
1.原始块标记为删除;这是软删除
2.一旦一个块被标记为删除的时间超过了可配置压实机的时间。删除延迟,从存储器中删除块;这是一个硬删除。
压缩器负责标记块和硬删除。软删除基于存储在 bucket 中块位置中的一个小文件(deletion-mark.json)。成功压缩后,将从存储中删除原始块。块删除不是立即进行的;它遵循两步过程:1.原始块标记为删除;这是软删除 2.一旦一个块被标记为删除的时间超过了可配置压实机的时间。删除延迟,从存储器中删除块;这是一个硬删除。
压实机负责标记块和硬删除。软删除基于存储在 bucket 中块位置中的一个小文件。软删除机制为queriers,rulers和store-gateways提供了时间,以便在删除原始块之前发现新的压缩块。如果这些原始块被立即硬删除,则涉及压缩块的某些查询可能会暂时失败或返回部分结果。
distributor(数据分发器)
分发服务器是一个无状态组件,从 Prometheus 或 Grafana 代理接收时间序列数据。分发服务器验证数据的正确性,并确保数据在给定租户的配置限制内。然后,分发服务器将数据分为多个批次,并将其并行发送给多个接收程序,在接收程序之间切分序列,并通过配置的复制因子复制每个序列。默认情况下,配置的复制因子为 3。
工作原理
验证
分发服务器在将数据写入 ingester 之前验证其接收的数据。因为单个请求可以包含有效和无效的度量、样本、元数据和样本,所以分发服务器只将有效数据传递给 ingester。分发服务器在其对接收程序的请求中不包含无效数据。如果请求包含无效数据,分发服务器将返回 400 HTTP 状态代码,详细信息将显示在响应正文中。关于第一个无效数据的详细信息无论是普罗米修斯还是格拉夫纳代理通常由发送方记录。分发器验证包括以下检查:
度量元数据和标签符合普罗米修斯公开格式。
度量元数据(名称、帮助和单位)的长度不超过通过validation.max-metadata-length定义的长度
每个度量的标签数不高于-validation.max-label-names-per-series
每个度量标签名称不得长于-validation.max-length-label-name
每个公制标签值不长于-validation.max-length-label-value
每个样本时间戳都不晚于-validation.create-grace-period
每个示例都有一个时间戳和至少一个非空标签名称和值对。
每个样本不超过 128 个标签。
速率限制
分发器包括适用于每个租户的两种不同类型的费率限制。
请求速率每个租户每秒可以跨 Grafana Mimir 集群处理的最大请求数。
接受速率每个租户在 Grafana Mimir 集群中每秒可接收的最大样本数。如果超过其中任何一个速率,分发服务器将丢弃请求并返回 HTTP 429 响应代码。
在内部,这些限制是使用每个分发器的本地速率限制器实现的。每个分发服务器的本地速率限制器都配置了limit/N,其中 N 是正常分发服务器副本的数量。如果分发服务器副本的数量发生变化,分发服务器会自动调整请求和接收速率限制。因为这些速率限制是使用每个分发服务器的本地速率限制器实现的,所以它们要求写入请求在分发服务器池中均匀分布。可以通过下面的这几个参数进行限制:
-distributor.request-rate-limit
-distributor.request-burst-size
-distributor.ingestion-rate-limit
-distributor.ingestion-burst-size
高可用跟踪器
远程写发送器(如 Prometheus)可以成对配置,这意味着即使其中一个远程写发送机停机进行维护或由于故障而不可用,度量也会继续被擦除并写入 Grafana Mimir。我们将此配置称为高可用性(HA)对。分发服务器包括一个 HA 跟踪器。启用 HA 跟踪器后,分发服务器会对来自 Prometheus HA 对的传入序列进行重复数据消除。这使您能够拥有同一 Prometheus 服务器的多个 HA 副本,将同一系列写入 Mimir,然后在 Mimir 分发服务器中对该系列进行重复数据消除。
切分和复制
分发服务器在 ingester 之间切分和复制传入序列。您可以通过-ingester.ring.replication-factor配置每个系列写入的摄取器副本的数量。复制因子默认为 3。分发者使用一致哈希和可配置的复制因子来确定哪些接收者接收给定序列。切分和复制使用 ingester 的哈希环。对于每个传入的序列,分发服务器使用度量名称、标签和租户 ID 计算哈希。计算的哈希称为令牌。分发服务器在哈希环中查找令牌,以确定向哪个接收程序写入序列。
仲裁一致性
因为分发服务器共享对同一哈希环的访问,所以可以向任何分发服务器发送写请求。您还可以在它前面设置一个无状态负载平衡器。为了确保一致的查询结果,Mimir 在读写操作上使用了 Dynamo 风格的仲裁一致性。分发服务器等待 n/2+1 接收程序的成功响应,其中 n 是配置的复制因子,然后发送对 Prometheus 写入请求的成功响应。
分发器之间的负载平衡
在分发服务器实例之间随机进行负载平衡写入请求。如果在 Kubernetes 集群中运行 Mimir,可以将 KubernetesService 定义为分发器的入口。
ingester(数据接收器)
接收程序是一个有状态组件,它将传入序列写入长期存储的写路径,并返回读取路径上查询的序列样本。
工作原理
来自分发服务器的传入序列不会立即写入长期存储,而是保存在接收服务器内存中或卸载到接收服务器磁盘。最终,所有系列都会写入磁盘,并定期(默认情况下每两小时)上传到长期存储。因此,查询器可能需要在读取路径上执行查询时,从接收器和长期存储中获取样本。任何调用接收器的 Mimir 组件都首先查找哈希环中注册的接收器,以确定哪些接收器可用。每个接收器可能处于以下状态之一:
pending
joining
active
leaving
unhealthy
写放大
Ingers 将最近收到的样本存储在内存中,以便执行写放大。如果接收器立即将收到的样本写入长期存储,由于长期存储的高压,系统将很难缩放。由于这个原因,接收器在内存中对样本进行批处理和压缩,并定期将它们上传到长期存储。写反放大是 Mimir 低总体拥有成本(TCO)的主要来源。
接收失败和数据丢失
如果接收程序进程崩溃或突然退出,则所有尚未上载到长期存储的内存中序列都可能丢失。有以下方法可以缓解这种故障模式:
Replication
Write-ahead log (WAL)
Write-behind log (WBL), out-of-order 启用时
区域感知复制
区域感知复制可确保给定时间序列的接收副本跨不同的区域进行划分。分区可以表示逻辑或物理故障域,例如,不同的数据中心。跨多个区域划分副本可防止在整个区域发生停机时发生数据丢失和服务中断。
无序切分
乱序切分可以用来减少多个租户对彼此的影响。
无序样本接收
默认情况下会丢弃无序样本。如果将样本写入 Mimir 的系统产生无序样本,您可以启用此类样本的接收。
querier(查询器)
查询器是一个无状态组件,它通过在读取路径上获取时间序列和标签来评估 PromQL 表达式,使用存储网关组件查询长期存储,使用接收组件查询最近写入的数据。
工作原理
为了在查询时查找正确的块,查询器需要一个关于长期存储中存储桶的最新视图。查询器只需要来自 bucket 的元数据信息的,元数据包括块内样本的最小和最大时间戳。查询器执行以下操作之一,以确保更新 bucket 视图:
定期下载 bucket 索引(默认)
定期扫描 bucket
Bucket 索引已启用(默认)
当查询器收到给定租户的第一个查询时,它会对 bucket 索引进行懒下载。查询器将 bucket 索引缓存在内存中,并定期更新。bucket 索引包含租户的块列表和块删除标记。查询器稍后使用块列表和块删除标记来定位给定查询需要查询的块集。当查询器在启用 bucket 索引的情况下运行时,查询器的启动时间和对对象存储的 API 调用量都会减少。我们建议您保持启用 bucket 索引。
Bucket 索引已禁用
当禁用 bucket 索引时,查询器会迭代存储 bucket 以发现所有租户的块,并下载每个块的 meta.json 文件。在这个初始 bucket 扫描阶段,查询器无法处理传入的查询,其/ready ready 探测端点将不会返回 HTTP 状态代码 200。运行时,查询器定期迭代存储桶以发现新的租户和最近上载的块。
查询请求解析
连接到存储网关
连接到接收器
支持元数据缓存
query-frontend
查询前端是一个无状态组件,它提供与查询器相同的 API,并可用于加快读取路径。尽管查询前端不是必需的,但我们建议您部署它。部署查询前端时,应该向查询前端而不是查询器发出查询请求。集群中需要查询器来执行查询,在内部队列中保存查询。在这种情况下,查询器充当从队列中提取作业、执行作业并将结果返回到查询前端进行聚合的工作者。要将查询器与查询前端连接,通过-querier.frontend-address配置,在使用高可用情况下建议部署至少 2 个查询前端。
工作原理
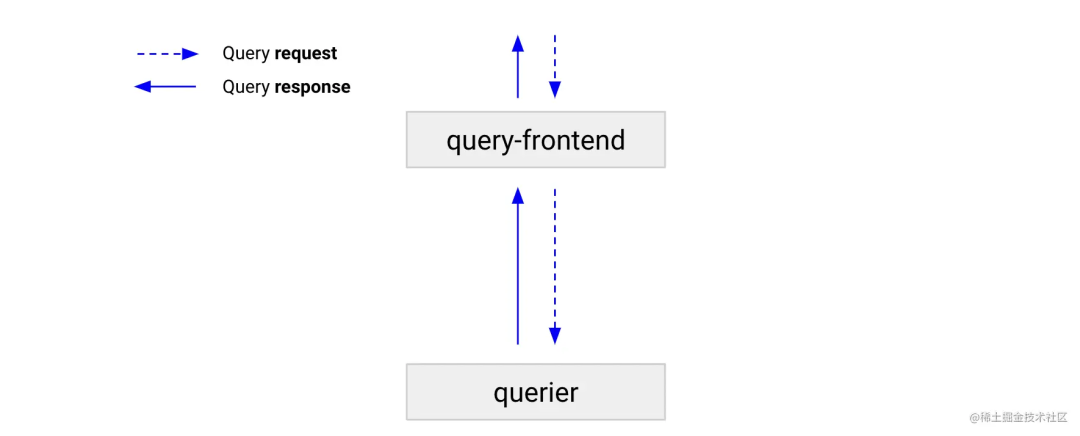
队列
查询前端使用排队机制来:
如果查询失败,请确保重试可能导致查询器内存不足(OOM)错误的大型查询。这使管理员能够为查询提供不足的内存,或并行运行更多的小型查询,这有助于降低总体拥有成本。
通过使用先进先出队列在所有查询器之间分发查询,防止在单个查询器上保护多个大型请求。
通过在租户之间公平地安排查询,防止单个租户拒绝为其他租户提供服务。
拆分
查询前端可以将远程查询拆分为多个查询。默认情况下,分割间隔为 24 小时。查询前端在下游查询器中并行执行这些查询,并将结果组合在一起。拆分可防止大型多天或多月查询导致查询器内存不足错误,并加快查询执行速度。
缓存
查询前端缓存查询结果并在后续查询中重用它们。如果缓存的结果不完整,查询前端将计算所需的部分查询,并在下游查询器上并行执行它们。查询前端可以选择将查询与其步骤参数对齐,以提高查询结果的可缓存性。结果缓存由 Memcached 支持。
尽管将 step 参数与查询时间范围对齐可以提高 Mimir 的性能,但它违反了 Mimir 对 PromQL 的一致性。如果 PromQL 一致性不是优先事项,可以设置-query-frontend.align-queries-with-step=true。
store-gateway(数据存储网关)
存储网关组件是有状态的,它查询来自长期存储的块。在读取路径上,querier和ruler在处理查询时使用存储网关,无论查询来自用户还是来自正在评估的规则。为了在查询时找到要查找的正确块,存储网关需要一个关于长期存储中存储桶的最新视图。存储网关使用以下选项之一更新存储段视图:
定期下载 bucket 索引(默认)
定期扫描 bucket
工作原理
bucket 索引启用
bucket 索引禁用
数据块分片和复制
分片策略
自动忘记
区域意识
块索引头
索引头懒加载
索引缓存
inmemory
memcached
元数据缓存
区块缓存
Alertmanager
Mimir Alertmanager 为 Prometheus Alertmanagers 添加了多租户支持和水平伸缩性。Mimir Alertmanager 是一个可选组件,它接受来自 Mimir 标尺的警报通知。Alertmanager 对警报通知进行重复数据消除和分组,并将其路由到通知通道,如电子邮件、PagerDuty 或 OpsGenie。
Override-exporter
Mimir 支持按租户应用覆盖。许多覆盖配置了限制,以防止单个租户使用过多资源。覆盖导出器组件将限制公开为普罗米修斯度量,以便运营商了解租户与其限制的接近程度。
query-scheduler
查询调度程序是一个可选的无状态组件,它保留要执行的查询队列,并将工作负载分配给可用的查询器。
工作原理
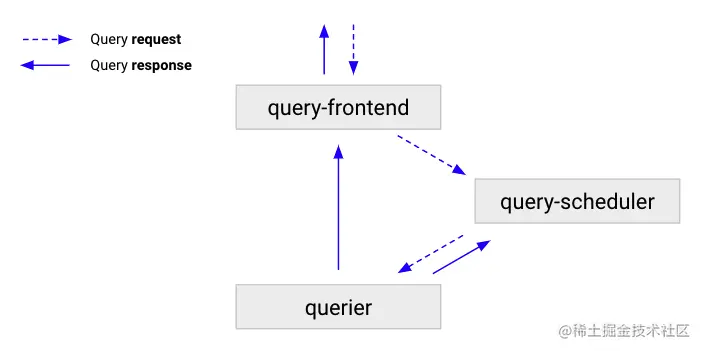
ruler
规则是一个可选组件,用于评估记录和警报规则中定义的 PromQL 表达式。每个租户都有一组记录和警报规则,可以将这些规则分组到名称空间中。
安装
说明:安装 mimir 需要在官方下载这个二进制程序或者直接在 k8s 集群里面直接部署即可。在这里以未启用多租户为介绍。
注意事项:
target 默认为 all,不包含可选组件.要启用可选组件需要额外添加
replication_factor 默认为 3,如果只有一台机器或者只需要启动一个实例,需要改为 1(单需要只要 alertmanager 为 1 的时候只能发送 1 条报警信息,直到 2.3.1 版本官方都没有解决)
裸机部署
准备配置文件
alertmanager: external_url: http://127.0.0.1:8080/alertmanager sharding_ring: replication_factor: 2 ingester: ring: replication_factor: 1 multitenancy_enabled: false ruler: alertmanager_url: http://127.0.0.1:8080/alertmanager external_url: http://127.0.0.1:8080/ruler query_frontend: address: 127.0.0.1:9095 query_stats_enabled: true rule_path: ./ruler/ ruler_storage: filesystem: dir: ./rules-storage store_gateway: sharding_ring: replication_factor: 1 target: all,alertmanager,ruler
启动服务
/usr/local/mimir/mimir-darwin-amd64 --config.file /usr/local/mimir/mimir.yaml
查看状态
服务启动后可通过浏览器打开查看首页
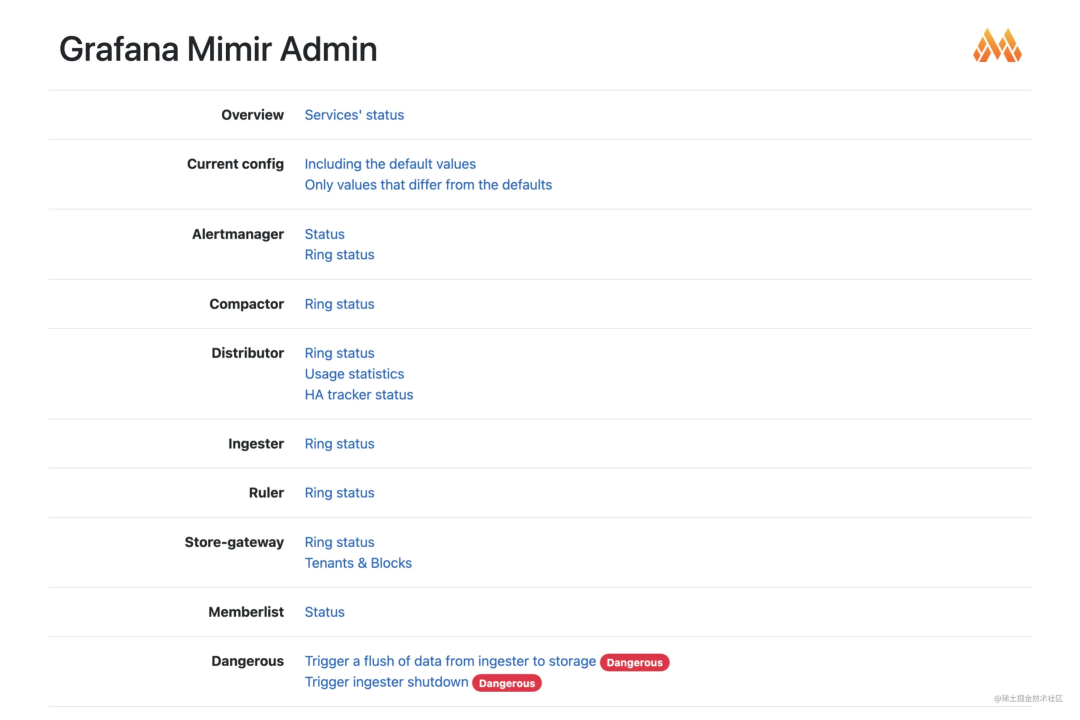 mimir_status
mimir_status
各服务运行状态
 running_status
running_status
查看服务是否就绪
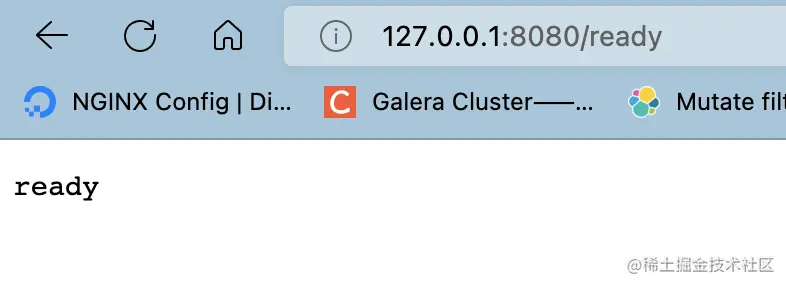
查看当前集群节点
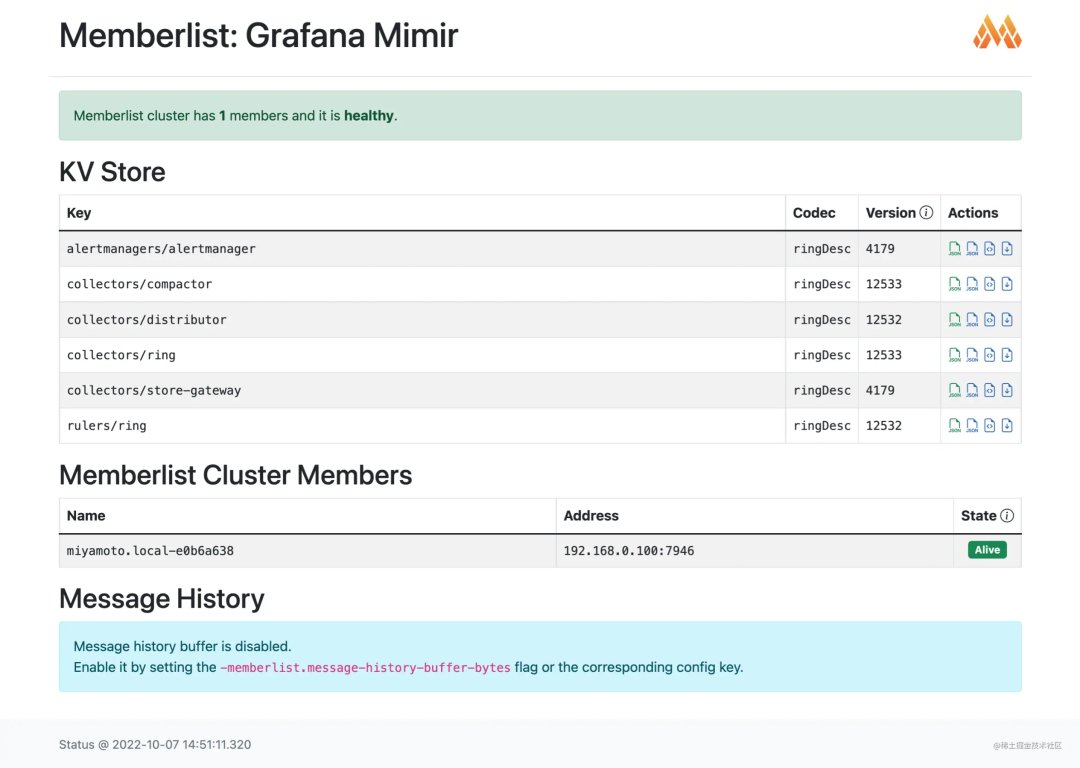
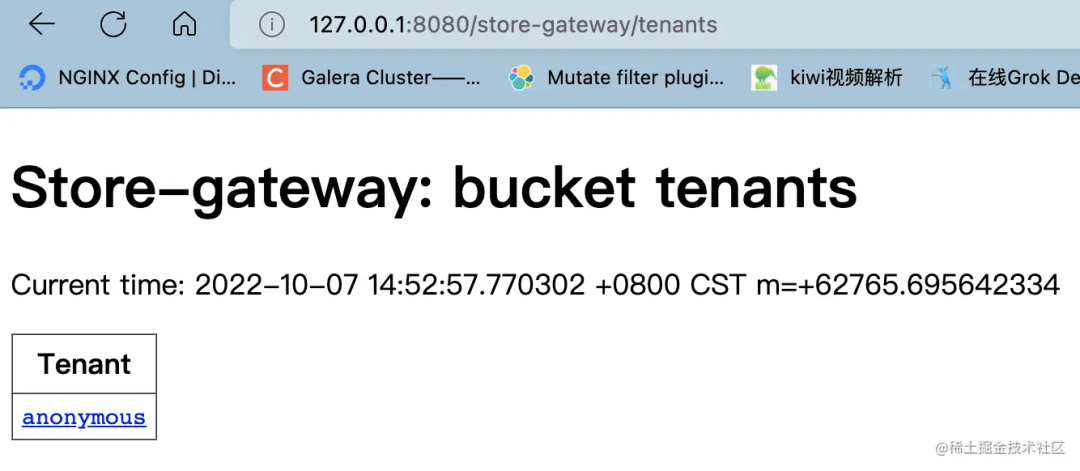
查看多租户
配置 Alertmanager
准备配置文件
cat ./alertmanager.yaml
global:
resolve_timeout: 5m
http_config:
follow_redirects: true
enable_http2: true
smtp_from: qiyx1@qq.com
smtp_hello: mimir
smtp_smarthost: smtp.qq.com:587
smtp_auth_username: qiyx1@qq.com
smtp_require_tls: true
route:
receiver: email
group_by:
- alertname
continue: false
routes:
- receiver: email
group_by:
- alertname
matchers:
- severity="info"
mute_time_intervals:
- 夜间
continue: true
group_wait: 10s
group_interval: 5s
repeat_interval: 6h
inhibit_rules:
- source_match:
severity: warning
target_match:
severity: warning
equal:
- alertname
- instance
receivers:
- name: email
email_configs:
- send_resolved: true
to: xxxx@xxxx.cn
from: qiyx1@qq.com
hello: mimir
smarthost: smtp.qq.com:587
auth_username: qiyx1@qq.com
headers:
From: qiyx1@qq.com
Subject: '{{ template "email.default.subject" . }}'
To: qiyongxiao@elion.com.cn
html: '{{ template "email.default.html" . }}'
text: '{{ template "email.default.html" . }}'
require_tls: true
templates:
- email.default.html
mute_time_intervals:
- name: 夜间
time_intervals:
- times:
- start_time: "00:00"
end_time: "08:45"
- start_time: "21:30"
end_time: "23:59"
将配置文件上传到 mimir,默认 mimir 启动后 alertmanager 的配置信息是空的,报警器无法启动,需要修改配置后才能启动
mimirtool alertmanager load ./alertmanager.yaml --address http://127.0.0.1:8080 --id annoymous
配置 grafana 的 alertmanager
配置 grafana 的 prometheus
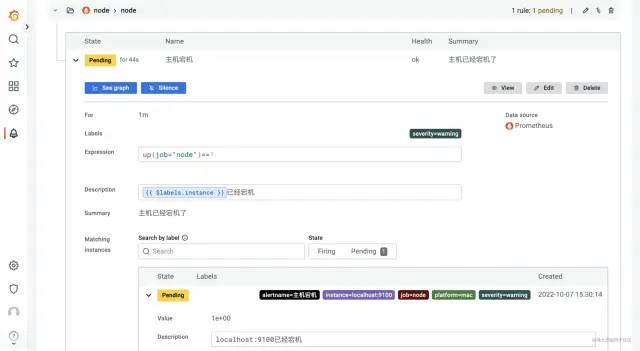
添加报警规则
配置多租户
更改配置文件中multitenancy_enabled: true
上传 alertmanager 配置文件(instance_id 一般为配置的 node 名称,可以自定义)
mimirtool alertmanager load ./alertmanager.yaml --address http://127.0.0.1:8080 --id instance_id
-
可视化MES系统软件2018-11-30 3282
-
如何把AD中非可视化区域物件移到可视化区域?2019-09-10 2400
-
基于STM的可视化门禁系统2020-03-07 2910
-
Python数据可视化2020-07-19 3189
-
三维可视化的应用和优势2020-12-02 2687
-
大屏可视化报表也能自助分析了2021-02-06 4923
-
上位机软件之3D可视化智慧档案库房的应用【图片分享】2021-05-21 5932
-
常见的几种可视化介绍2021-07-12 2790
-
数字化可视化的Web组态软件有哪些2021-09-26 3215
-
经验分享|BI数据可视化报表布局——容器2023-03-15 4391
-
可视化大屏设计模板 | 主题皮肤(报表UI设计)2023-09-12 3596
-
可视化语言技术在软件开发中的应用2009-10-31 758
-
文本可视化综述2016-05-17 728
-
大数据可视化技术现状分析及技术实践2018-02-05 46354
-
FUXA基于Web的过程可视化软件案例2024-04-24 1039
全部0条评论

快来发表一下你的评论吧 !
