

使用语音AI开发下一代扩展现实应用程序
描述
由于身临其境的体验,虚拟现实( VR )、增强现实( AR )和混合现实( MR )环境可以感觉到难以置信的真实。在扩展现实( XR )应用程序中添加基于语音的界面可以使其看起来更真实。
想象一下,用你的声音在一个环境中导航,或者发出口头命令,然后听到虚拟实体的回应。
在 XR 环境中利用 speech AI 的可能性非常诱人。语音人工智能技能,如自动语音识别( ASR )和文本到语音转换( TTS ),使 XR 应用程序变得有趣、易于使用,并使有语音障碍的用户更容易使用。
本文介绍了如何在 XR 应用程序中使用语音识别,也称为语音到文本( STT ),有哪些 ASR 自定义,以及如何开始在 Windows 应用程序中运行 ASR 服务。
为什么要在 XR 应用程序中添加语音 AI 服务?
在当今大多数 XR 体验中,用户无法使用键盘或鼠标。 VR 游戏控制器通常与虚拟体验交互的方式既笨拙又不直观,当您沉浸在环境中时,很难通过菜单进行导航。
当我们沉浸在虚拟世界中时,我们希望我们的体验感觉自然,无论是我们如何感知它,还是我们如何与它互动。言语是我们在现实世界中最常见的交流方式之一。
在 XR 应用程序中添加支持语音 AI 的语音命令和响应,使交互更加自然,并大大简化了用户的学习曲线。
支持语音 AI 的 XR 应用程序示例
如今,有各种各样的可穿戴技术设备,使人们能够在使用声音的同时体验身临其境的现实:
AR 翻译眼镜可以在 AR 中提供实时翻译,或者只在 AR 中转录语音,以帮助有听力障碍的人。
品牌化语音是为元宇宙中的数字化身定制和开发的,使体验更加可信和真实。
社交媒体平台提供语音激活 AR 过滤器,便于搜索和使用。例如, Snapchat 用户可以使用免提语音扫描功能搜索所需的数字滤波器。
VR 设计审查
虚拟现实可以帮助企业通过自动化汽车行业的许多任务来节省成本,例如汽车建模、装配工人培训和驾驶模拟。
添加的语音 AI 组件使免提交互成为可能。例如,用户可以利用 STT 技能向 VR 应用程序发出命令,应用程序可以通过 TTS 以听起来很人性化的方式响应。
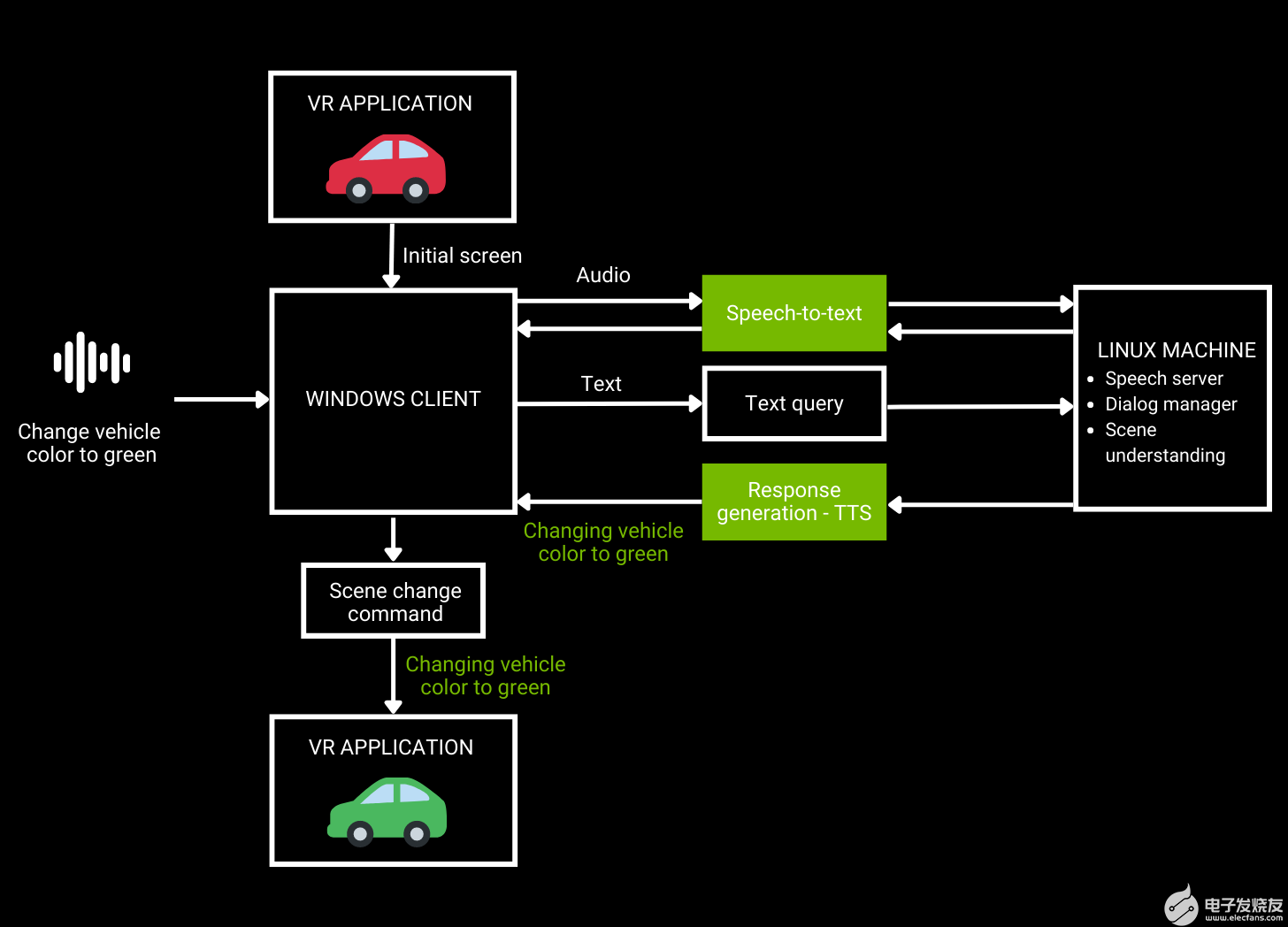
图 1.VR 汽车设计审查工作流架构
如图 1 所示,用户向 VR 应用程序发送音频请求,然后使用 ASR 将其转换为文本。自然语言理解将文本作为输入并生成响应,然后使用 TTS 将其反馈给用户。
开发语音 AI 管道并不像听起来那么容易。传统上,在构建管道时,总是要在准确性和实时响应之间进行权衡。
这篇文章只关注 ASR ,我们研究了目前 XR 应用程序开发人员可用的一些定制。我们还讨论了使用 GPU 加速语音 AI SDK NVIDIA Riva 构建针对特定用例定制的应用程序,同时提供实时性能。
通过 ASR 定制解决特定领域和语言的挑战
一个 ASR 管道包括一个特征抽取器、声学模型、解码器或语言模型以及标点符号和大写模型(图 2 )。
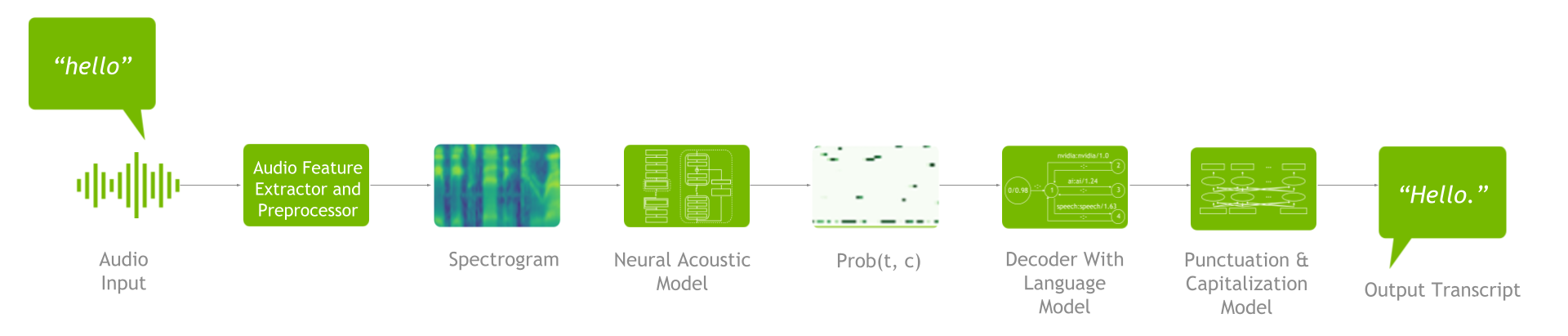
图 2.ASR 管道
要了解可用的 ASR 定制,掌握端到端流程很重要。首先,进行特征提取,将原始音频波形转换为频谱图/梅尔频谱图。然后将这些频谱图输入声学模型,该模型生成一个矩阵,其中包含每个时间步长的所有字符的概率。
接下来,解码器与语言模型一起使用该矩阵作为输入来生成文本。然后,您可以通过标点符号和大写模型运行生成的文本,以提高可读性。
高级语音 AI SDK 和工作流(如 Riva )支持语音识别管道定制。自定义可帮助您解决一些特定于语言的挑战,例如了解以下一项或多项:
多重口音
单词语境化
领域专用术语
多种方言
多种语言
噪音环境中的用户
Riva 中的定制可以应用于训练和推理阶段。从培训级别定制开始,您可以微调声学模型、解码器/语言模型以及标点符号和大写模型。这可以确保您的管道能够理解不同的语言、方言、口音和行业特定的行话,并且对噪音具有鲁棒性。
当涉及到推理级自定义时,可以使用 word boosting 。通过单词增强,在解码声学模型的输出时, ASR 管道更可能通过给某些感兴趣的单词更高的分数来识别它们。
开始使用 NVIDIA Riva 为 XR 开发集成 ASR 服务
Riva 作为客户机 – 服务器模型运行。要运行 Riva ,您需要访问带有 NVIDIA GPU 的 Linux 服务器,在那里您可以安装和运行 Riva 服务器(本文提供了详细信息和说明)。
Riva 客户端 API 集成到 Windows 应用程序中。在运行时, Windows 客户端通过网络向 Riva 服务器发送 Riva 请求,而[ZDK0 :服务器则发送回复。单个 Riva 服务器可以同时支持多个 Riva 客户端。
ASR 服务可以在两种不同的模式下运行:
Offline mode: 捕获完整的语音段,完成后发送到 Riva 以转换为文本。
Streaming mode: 语音片段正在实时流式传输到 Riva 服务器,文本结果正在实时流回。流模式有点复杂,因为它需要多个线程。
本文稍后将提供两种模式的示例。
在本节中,您将学习几种将 Riva 集成到 Windows 应用程序中的方法:
Python ASR 离线客户端
Python 流式 ASR 客户端
使用 Docker 的 C ++脱机客户端
C ++流媒体客户端
首先,这里介绍了如何设置和运行 Riva 服务器。
先决条件
访问 NGC 。有关分步说明,请参阅 NGC Getting Started Guide
执行所有步骤,以便能够从命令行界面( CLI )运行ngc命令。
访问 NVIDIA Volta 、 NVIDIA -Turing 或基于 A100 GPU 的 NVIDIA 安培架构。带有 NVIDIA GPU 的 Linux 服务器也可从主要 CSP 获得。有关更多信息,请参阅 support matrix 。
Docker 安装,支持 NVIDIA GPU 。
按照说明安装 NVIDIA Container Toolkit ,然后安装nvidia-docker软件包。
服务器设置
通过运行以下命令从 NGC 下载脚本:
ngc registry resource download-version nvidia/riva/riva_quickstart:2.4.0
初始化 Riva 服务器:
bash riva_init.sh
启动 Riva 服务器:
bash riva_start.sh
运行 Python ASR 脱机客户端
首先,运行以下命令来安装riva客户端软件包。确保您使用的是 Python 版本 3.7 。
pip install nvidia-riva-client
以下代码示例以脱机模式运行 ASR 转录。您必须更改服务器地址,给出要转录的音频文件的路径,并选择语言代码。目前, Riva 支持英语、西班牙语、德语、俄语和普通话。
import io
import IPython.display as ipd
import grpc
import riva.client
auth = riva.client.Auth(uri='server address:port number')
riva_asr = riva.client.ASRService(auth)
# Supports .wav file in LINEAR_PCM encoding, including .alaw, .mulaw, and .flac formats with single channel
# read in an audio file from local disk
path = "audio file path"
with io.open(path, 'rb') as fh:
content = fh.read()
ipd.Audio(path)
# Set up an offline/batch recognition request
config = riva.client.RecognitionConfig()
#req.config.encoding = ra.AudioEncoding.LINEAR_PCM # Audio encoding can be detected from wav
#req.config.sample_rate_hertz = 0 # Sample rate can be detected from wav and resampled if needed
config.language_code = "en-US" # Language code of the audio clip
config.max_alternatives = 1 # How many top-N hypotheses to return
config.enable_automatic_punctuation = True # Add punctuation when end of VAD detected
config.audio_channel_count = 1 # Mono channel
response = riva_asr.offline_recognize(content, config)
asr_best_transcript = response.results[0].alternatives[0].transcript
print("ASR Transcript:", asr_best_transcript)
print("\n\nFull Response Message:")
print(response)
运行 Python 流式 ASR 客户端
要运行 ASR 流客户端,请克隆riva python-clients存储库并运行存储库附带的文件。
要使 ASR 流式处理客户端在 Windows 上运行,请运行以下命令克隆存储库:
git clone https://github.com/nvidia-riva/python-clients.git
从python-clients/scripts/asr文件夹运行以下命令:
python transcribe_mic.py --server=server address:port number
下面是 transcibe_mic.py :
import argparse
import riva.client
from riva.client.argparse_utils import add_asr_config_argparse_parameters, add_connection_argparse_parameters
import riva.client.audio_io
def parse_args() -> argparse.Namespace:
default_device_info = riva.client.audio_io.get_default_input_device_info()
default_device_index = None if default_device_info is None else default_device_info['index']
parser = argparse.ArgumentParser(
description="Streaming transcription from microphone via Riva AI Services",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument("--input-device", type=int, default=default_device_index, help="An input audio device to use.")
parser.add_argument("--list-devices", action="store_true", help="List input audio device indices.")
parser = add_asr_config_argparse_parameters(parser, profanity_filter=True)
parser = add_connection_argparse_parameters(parser)
parser.add_argument(
"--sample-rate-hz",
type=int,
help="A number of frames per second in audio streamed from a microphone.",
default=16000,
)
parser.add_argument(
"--file-streaming-chunk",
type=int,
default=1600,
help="A maximum number of frames in a audio chunk sent to server.",
)
args = parser.parse_args()
return args
def main() -> None:
args = parse_args()
if args.list_devices:
riva.client.audio_io.list_input_devices()
return
auth = riva.client.Auth(args.ssl_cert, args.use_ssl, args.server)
asr_service = riva.client.ASRService(auth)
config = riva.client.StreamingRecognitionConfig(
config=riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
language_code=args.language_code,
max_alternatives=1,
profanity_filter=args.profanity_filter,
enable_automatic_punctuation=args.automatic_punctuation,
verbatim_transcripts=not args.no_verbatim_transcripts,
sample_rate_hertz=args.sample_rate_hz,
audio_channel_count=1,
),
interim_results=True,
)
riva.client.add_word_boosting_to_config(config, args.boosted_lm_words, args.boosted_lm_score)
with riva.client.audio_io.MicrophoneStream(
args.sample_rate_hz,
args.file_streaming_chunk,
device=args.input_device,
) as audio_chunk_iterator:
riva.client.print_streaming(
responses=asr_service.streaming_response_generator(
audio_chunks=audio_chunk_iterator,
streaming_config=config,
),
show_intermediate=True,
)
if __name__ == '__main__':
main()
使用 Docker 运行 C ++ ASR 脱机客户端
下面是如何在 C ++中使用 Docker 运行 Riva ASR 脱机客户端。
通过运行以下命令克隆/ cpp 客户端 GitHub 存储库:
git clone https://github.com/nvidia-riva/cpp-clients.git
构建 Docker 映像:
DOCKER_BUILDKIT=1 docker build . –tag riva-client
运行 Docker 映像:
docker run -it --net=host riva-client
启动 Riva 语音识别客户端:
Riva_asr_client –riva_url server address:port number –audio_file audio_sample
运行 C ++ ASR 流式处理客户端
要在 C ++中运行 ASR 流式客户端riva_asr,必须首先编译 cpp sample 。在满足以下依赖项之后,使用 CMake 很简单:
gflags
glog
grpc
rtaudio
rapidjson
protobuf
grpc_cpp_plugin
在根源文件夹中创建文件夹/build。在终端上,键入cmake 。.,然后键入make。有关详细信息,请参阅存储库中包含的自述文件。
编译样本后,输入以下命令运行它:
riva_asr.exe --riva_uri={riva server url}:{riva server port} --audio_device={Input device name, e.g. "plughw:PCH,0"}
-
riva_uri:riva服务器的address:port值。默认情况下,riva服务器侦听端口 50051 。 -
audio_device:要使用的输入设备(麦克风)。
该示例实际上实现了四个步骤。这篇文章中只展示了几个简短的例子。有关详细信息,请参阅文件streaming_recognize_client.cc。
使用命令行中指定的输入(麦克风)设备打开输入流。在这种情况下,您使用的是每秒 16K 采样和 16 位采样的一个通道。
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
nr::AudioEncoding encoding = nr::LINEAR_PCM;
adc.setErrorCallback(rtErrorCallback);
RtAudio::StreamParameters parameters;
parameters.nChannels = 1;
parameters.firstChannel = 0;
unsigned int sampleRate = 16000;
unsigned int bufferFrames = 1600; // (0.1 sec of rec) sample frames
RtAudio::StreamOptions streamOptions;
streamOptions.flags = RTAUDIO_MINIMIZE_LATENCY;
…
RtAudioErrorType error = adc.openStream( nullptr, ¶meters, RTAUDIO_SINT16, sampleRate, &bufferFrames, &MicrophoneCallbackMain, static_cast(&uData), &streamOptions);
使用.proto 文件指定的协议 api 接口(在文件夹riva/proto的源中)打开与 Riva 服务器的grpc通信通道:
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
…
std::shared_ptr call = std::make_shared(1, word_time_offsets_);
call->streamer = stub_->StreamingRecognize(&call->context);
// Send first request
nr_asr::StreamingRecognizeRequest request;
auto streaming_config = request.mutable_streaming_config();
streaming_config->set_interim_results(interim_results_);
auto config = streaming_config->mutable_config();
config->set_sample_rate_hertz(sampleRate);
config->set_language_code(language_code_);
config->set_encoding(encoding);
config->set_max_alternatives(max_alternatives_);
config->set_audio_channel_count(parameters.nChannels);
config->set_enable_word_time_offsets(word_time_offsets_);
config->set_enable_automatic_punctuation(automatic_punctuation_);
config->set_enable_separate_recognition_per_channel(separate_recognition_per_channel_);
config->set_verbatim_transcripts(verbatim_transcripts_);
if (model_name_ != "") {
config->set_model(model_name_);
}
call->streamer->Write(request);
开始发送麦克风通过grpc消息接收到的音频数据到riva:
static int MicrophoneCallbackMain( void *outputBuffer, void *inputBuffer, unsigned int nBufferFrames, double streamTime, RtAudioStreamStatus status, void *userData )
通过服务器的grpc应答接收转录的音频:
void StreamingRecognizeClient::ReceiveResponses(std::shared_ptrcall, bool audio_device) { … while (call->streamer->Read(&call->response)) { // Returns false when no m ore to read. call->recv_times.push_back(std::chrono::steady_clock::now()); // Reset the partial transcript call->latest_result_.partial_transcript = ""; call->latest_result_.partial_time_stamps.clear(); bool is_final = false; for (int r = 0; r < call->response.results_size(); ++r) { const auto& result = call->response.results(r); if (result.is_final()) { is_final = true; } … call->latest_result_.audio_processed = result.audio_processed(); if (print_transcripts_) { call->AppendResult(result); } } if (call->response.results_size() && interim_results_ && print_transcripts_) { std::cout << call->latest_result_.final_transcripts[0] + call->latest_result_.partial_transcript << std::endl; } call->recv_final_flags.push_back(is_final); }
开发语音 AI 应用程序的资源
通过识别你的声音或执行命令,语音人工智能正在从在联络中心授权实际人类扩展到在元宇宙授权数字人类。
关于作者
Sirisha Rella 是 NVIDIA 的技术产品营销经理,专注于计算机视觉、语音和基于语言的深度学习应用。 Sirisha 获得了密苏里大学堪萨斯城分校的计算机科学硕士学位,是国家科学基金会大学习中心的研究生助理。
Davide Onofrio 是 NVIDIA 的高级深度学习软件技术营销工程师。他在 NVIDIA 专注于深度学习技术开发人员关注内容的开发和演示。戴维德在生物特征识别、虚拟现实和汽车行业担任计算机视觉和机器学习工程师已有多年经验。
审核编辑:郭婷
-
传苹果正开发下一代无线充电技术2016-02-01 4482
-
用Java开发下一代嵌入式产品2021-11-05 1135
-
S2C与Japan Circuit合作,共同开发下一代超高速2009-08-07 802
-
用CompactRIO和LabVIEW开发下一代机器人控制系2010-01-21 1037
-
安森美开发下一代GaN-on-Si功率器件2012-10-10 1566
-
三星电子与丹麦顶级音响公司合作,共同开发下一代显示器2018-06-08 1317
-
英飞凌与Aaware达成战略合作,开发下一代语音开发平台2018-07-27 5031
-
IBM宣布在纽约投资20亿美元建立一个新的IBMAI硬件中心 旨在开发下一代AI硬件2019-02-11 3040
-
电装将与高通共同开发下一代座舱系统2020-01-10 3495
-
扩展现实或将成为下一代生产力工具2022-08-27 792
-
KYOCERA AVX和VisIC Technologies合作开发下一代电车应用GaN技术2023-03-01 2037
-
Skylark Lasers开发下一代量子导航和计时系统2023-07-18 2290
-
三星电子已开始与Naver合作开发下一代AI芯片Mach-22024-04-18 1444
-
丰田、日产和本田将合作开发下一代汽车的AI和芯片2024-05-20 2082
-
Telechips与Arm合作开发下一代IVI芯片Dolphin72025-10-13 1635
全部0条评论

快来发表一下你的评论吧 !
