

有效防御基于查询分数的攻击
描述
上海交通大学自动化系图像处理与模式识别研究所黄晓霖副教授团队,与鲁汶大学、加州大学圣克鲁兹分校的研究者合作,关注真实场景的防御,提出主动对攻击者实施攻击,在保证用户正常使用模型(无精度/速度损失)的同时,有效阻止黑盒攻击者通过查询模型输出生成对抗样本。经Rebuttal极限提分(2 4 4 5 -> 7 7 4 7),该研究已被机器学习顶级会议 NeurIPS 2022 录用,代码已开源。
【 研究背景 】
基于查询分数的攻击(score-based query attacks, SQAs)极大增加了真实场景中的对抗风险,因为其仅需数十次查询模型输出概率,即可生成有效的对抗样本。
然而,现有针对worst-case扰动的防御,并不适用于真实场景中,因为他们通过预处理输入或更改模型,显著降低了模型的推理精度/速度,影响正常用户使用模型。
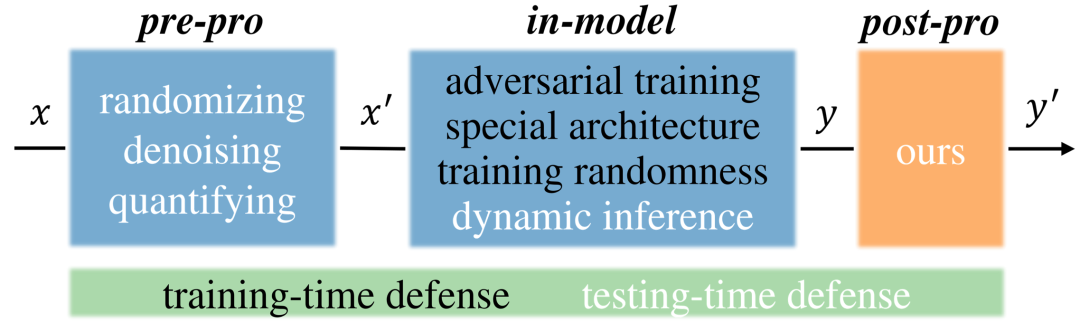
因此,本文考虑通过后处理来防御,其自带以下优点
· 有效防御基于查询分数的攻击
· 不影响模型精度,甚至还能使模型的置信度更加准确
· 是一种轻量化,即插即用的方法
可是在真实的黑盒场景中,攻击者和用户得到的,是相同的模型输出信息,如何在服务用户的同时,防御潜在攻击者?
【 本文方法 】
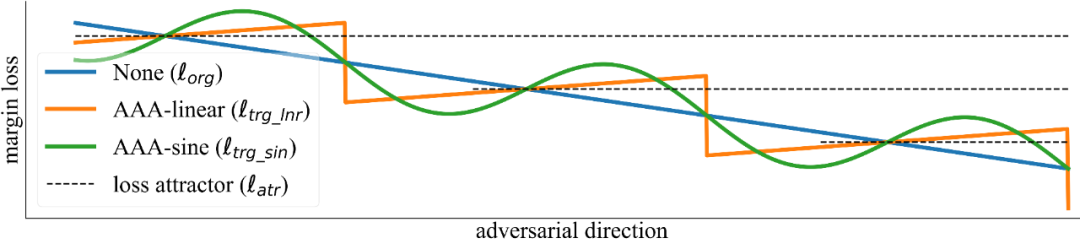
我们的核心思路是,测试阶段主动误导攻击者进入错误的攻击方向,也就是对攻击者发动攻击(adversarial attack on attackers, AAA)。如下图所示,若我们将模型的(未经防御的)蓝色损失函数曲线,轻微扰动至橙色或绿色的曲线,那么当攻击者贪婪地沿梯度下降方向搜索对抗样本时,将会被愚弄至错误的攻击方向。
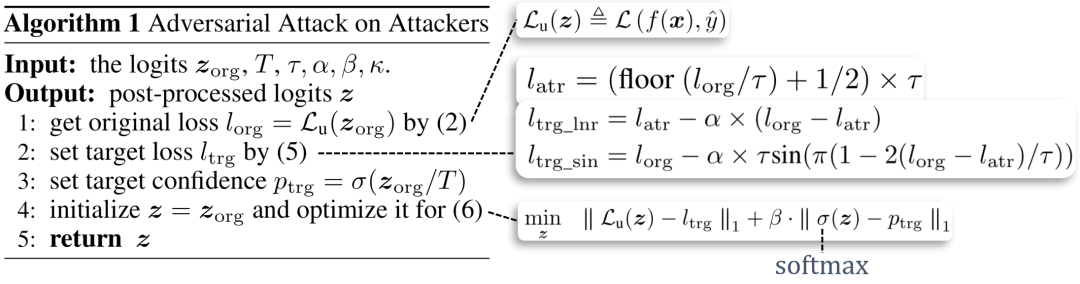
具体的,我们的算法分为4步,对应上图中的4行
1. 计算未经修改的原损失函数值,也就是上图中的蓝色曲线
2. 根据原损失函数值,计算出目标损失函数值,即橙色或绿色曲线
3. 根据预先标定的温度T,计算出目标置信度
4. 优化输出的logits,使其同时拥有目标损失函数值和目标置信度
【 实验结果 】
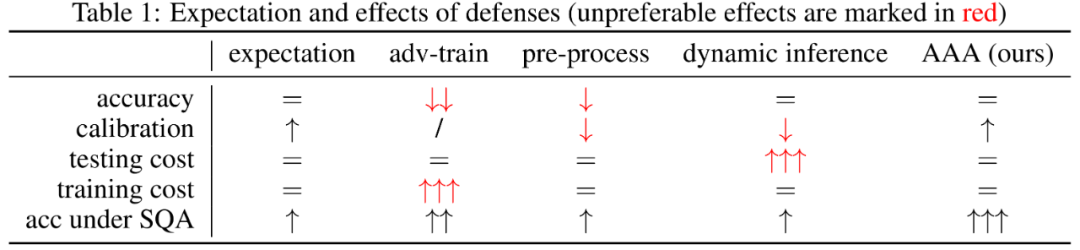
如下左图所示,对比蓝线和橙线,我们的方法AAA,最小程度地扰动输出,却最大限度保留精度(Acc ↑),提升置信度的准确度(expected calibration error, ECE ↓)。如右图和下表所示,AAA相比现有方法,能有效地防止真实场景攻击下的精度损失。
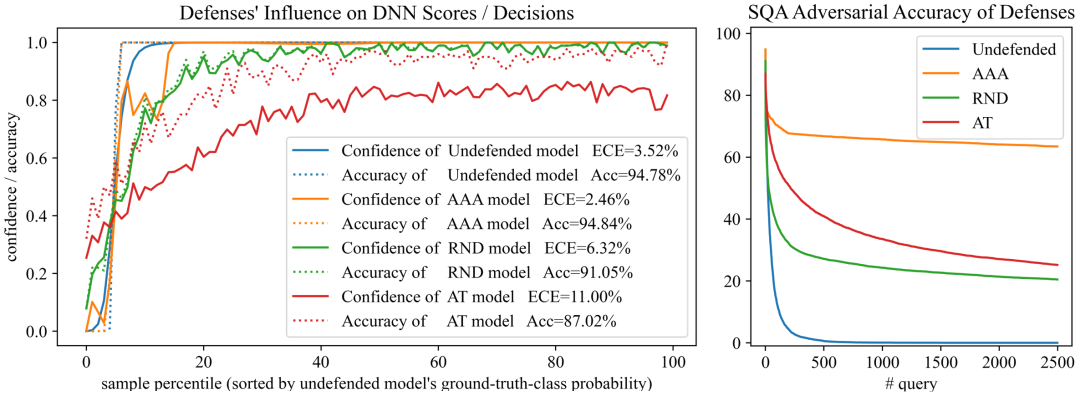
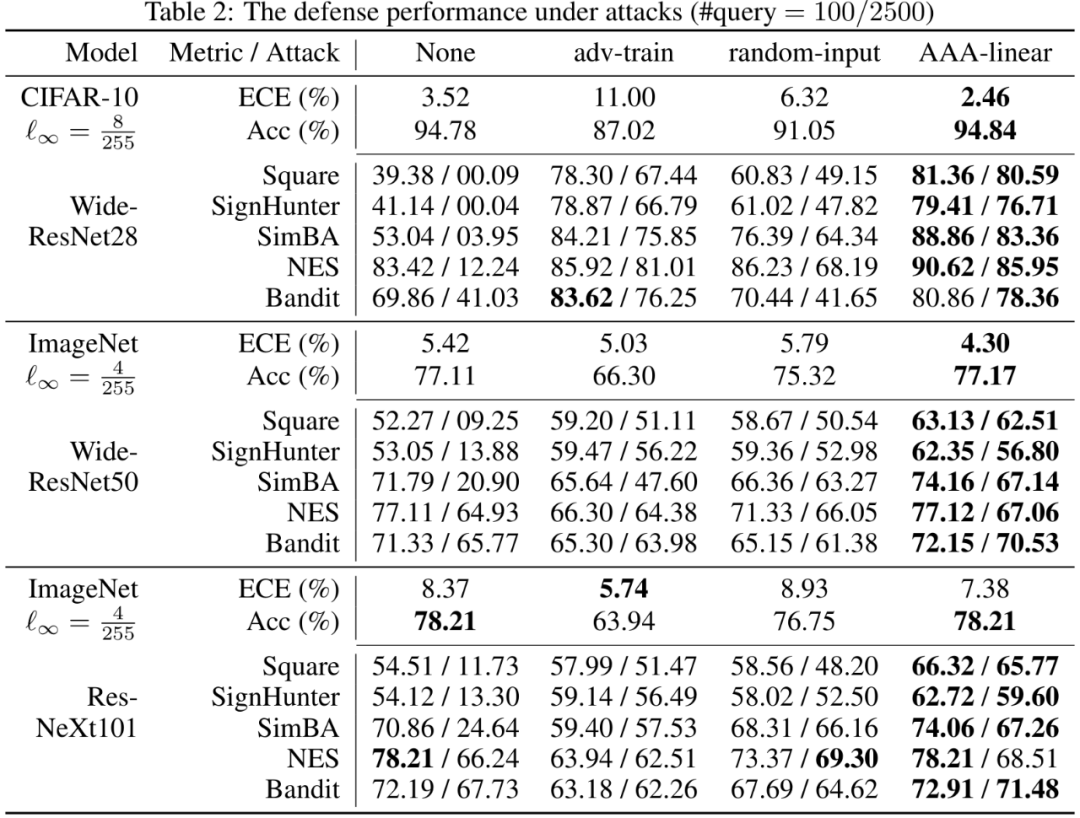
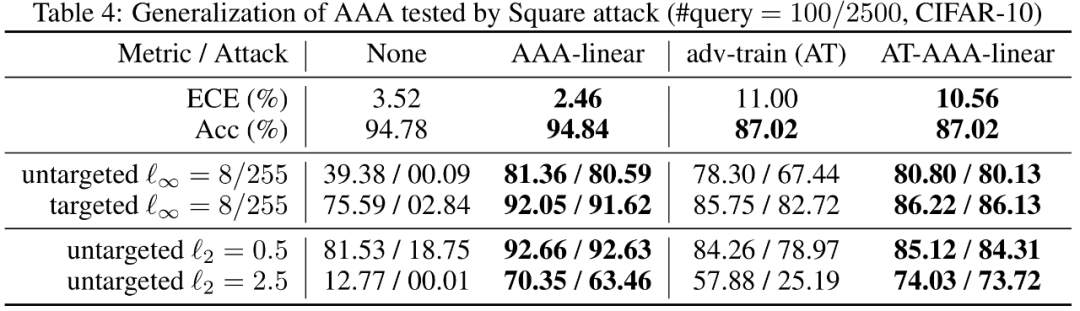
同时,AAA能简单地与现有防御结合,如对抗训练。
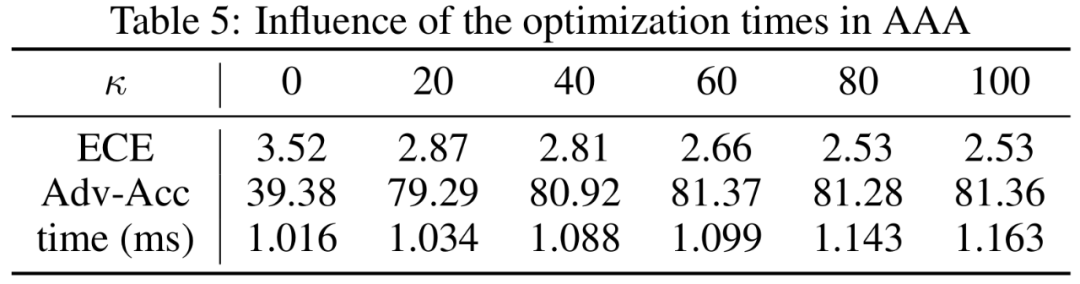
AAA是极其轻量化的防御,因为后处理操作的计算量很小,如下图所示。
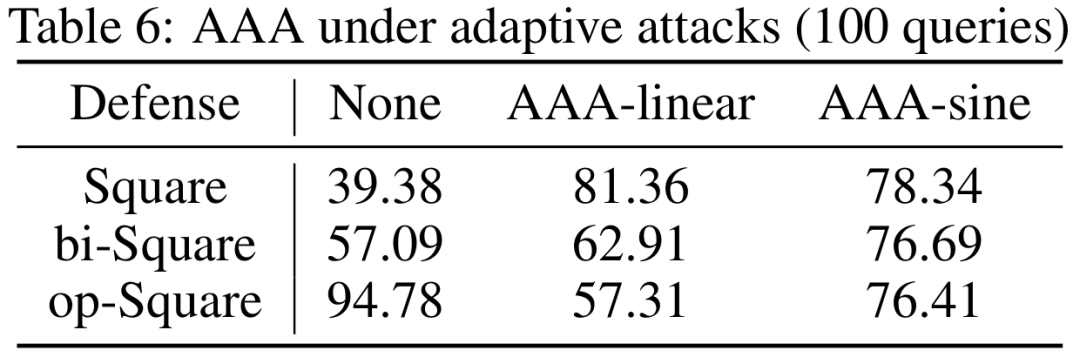
尽管攻击者可以对AAA设计自适应攻击(adaptive attacks),但在真实场景中,自适应攻击的成本非常高。因为黑盒场景下,攻击者完全没有模型的信息,更不用说其防御策略了。探索模型防御策略以设计自适应攻击,需要大量额外的查询。更重要的是,自适应攻击者也很好愚弄,比如使用正弦类的目标损失函数曲线以迷惑攻击者,因为其策略更难被猜测。如下表所示,反向搜索和双向搜索的自适应攻击,都可以被AAA-sine很好的防御。
【 文章总结 】
我们指出在真实场景下,一个简单的后处理模块,就可以形成有效,用户友好,即插即用的防御。为了专门防御基于查询分数的攻击,我们设计了对攻击者的攻击,通过细微的输出扰动干扰攻击者。广泛的实验表明我们的方法在抵御攻击,精度,置信度准确度,速度上,显著优于现有防御。
值得注意的是,抵御其他类型的攻击并非本文关注的重点。我们的方法并不提升worst-case robustness,故不能防御白盒攻击。我们也几乎不改变模型决策边界,故不能防御迁移攻击和基于决策的查询攻击(decision-based query attacks)。
-
最新防攻击教程2012-09-06 2839
-
SCDN的抗CC攻击和抗DDoS攻击防护是什么?2018-01-05 4962
-
面对外部恶意攻击网站,高防服务器如何去防御攻击?2019-05-07 1331
-
防御无线传感器网络中虫洞攻击是什么?2020-04-15 4223
-
公司服务器遭受CC攻击防御的应急记录2020-06-17 2939
-
cc攻击防御解决方法2022-01-22 4161
-
基于主动网的SYN攻击防御2009-02-28 924
-
一种基于SYN 漏洞的DDoS攻击防御算法的实现2009-06-17 583
-
一种全面主动的防御DDoS攻击方案2009-06-20 683
-
CRT-RSA的连分数算法攻击的分析2009-09-07 951
-
基于攻击防御树和博弈论的评估方法2017-11-21 1127
-
浅谈DDoS攻击的类型和防御措施2018-02-10 2230
-
深入浅出DDoS攻击防御——攻击2020-06-20 3024
-
关于GNSS欺骗技术,哪些防御技术对哪些攻击技术有效2021-01-27 3331
-
Linux越来越容易受到攻击,怎么防御?2023-12-23 2017
全部0条评论

快来发表一下你的评论吧 !
