

基于神经网络的2D到3D的机器学习
人工智能
描述
Twitter Hacker @Tristan公布了他破解的FSDbeta内部的3Dvoxel NN,形态仿佛狂野的《西部世界》,看起来虽然粗糙,无法实现纤毫毕现,但是关键信息——尤其是落在识别结果分类范围之外的长尾目标和场景,可以识别。
@Tristan是一个活跃在Twitter.com和github.com上的技术工程师(小编:Tristan现供职于Facebook),其个人公开的兴趣是机器学习和逆向工程——这就不难理解Tristan和长期活跃在互联网上一批汽车科技黑客,对于破解Tesla车机系统尤其是自动驾驶系统的热情了。小编要是有这个实力也会这么干,毕竟这是在公众可以接触到的AI完整系统中,凤毛麟角的批量商用产品了。
11月25日,@Tristan在twitter上公布了他所破解的Autopilot感知堆栈内的新功能,大致的名字可以被称作“Voxel 3D Birdseye view Model”——基于体素的3D矢量空间感知模型。这个功能首次被发现于大概一个半月前的2021.36版本,再次发现是在当前正在接受测试的FSD beta10.5版本。目前尚不确定这部分的NN模型是否在实际的识别堆栈中online参与识别,但功能肯定是存在的,而且这部分NN模型针对性也很明显,就是针对在纯视觉系统下表现不佳的静态物体识别。我们可以先看一段被hacked出来的Voxel 3D Birdseye view模型识别结果,如下:
@Tristan并未提供这段视频的对比真实世界场景,但大致上读者应该还是可以理解这是车辆行驶在道路上,从Camera提供的2D视觉信号所“恢复”出来的3D voxel静态物信息,包含但不限于:道路区域内的隔离物体、道路边缘大致轮廓,以及道路外围的第一排临街建筑物和各种交通实体。
读者可以先不着急理解FSD beta是如何将视频信号转换为3D voxel构成的场景的,理解这种技术的关键在于,什么是voxel体素的概念。

图二【Tesla voxel 3d model-2.png】来自spatial.com的体素概念截图,URLhttps://blog.spatial.com/the-main-benefits-and-disadvantages-of-voxel-modeling;
体素本质上是 3D 像素,但它们不是正方形,而是完美的立方体。理论上,体素是复制现实的完美建模技术。我们可以理解现实的世界是由类似于体素的东西组成的(小编:但它们要小得多,我们称之为“亚原子粒子”)。如果您有足够高的密度(或2D平面下的“分辨率”)和适当的渲染技术,您就可以使用体素来复制现实世界中的对象,这些对象在外观和行为上都无法与真实事物区分开来。下图为例,如果计算机的渲染能力足够强,就可以构建出基于立方体voxel的虚拟物理实体。只要Voxel有足够的细腻,虚拟的实体就可以逼真到肉眼在一定距离上无法辨识。(小编:你能识别下图中的房屋实际是由voxel构成的吗?)

图三【Tesla voxel 3d model-3.png】来自spatial.com的体素概念截图,URLhttps://blog.spatial.com/the-main-benefits-and-disadvantages-of-voxel-modeling;
基于voxel的体素建模在今天有一些非常具体的用例。许多科学学科都使用体素来快速确定体积数据。例如,在基于体素的形态测量学中,研究人员可以使用体素比较脑组织浓度的差异;地质学家经常使用体素建模技术来模拟地形和高程等地质特征。更广泛地说,科学家可以使用基于体素的建模来可视化和测量城市中心从流体到绿色空间的任何事物的体积。体素在需要对单个粒子进行建模的模拟技术中也很有用,就像智能材料模拟的情况一样。(小编:以上信息来自于spatial.com对于体素和体素建模的论证)
但我们今天所要关注的重点在于自动驾驶领域对于3D目标实时建模的特殊需求,显著区别于以上科学领域的精密应用。这里会带出两个问题,如下:
1 为什么说自动驾驶领域,是特殊的3D目标实时的建模需求?
小编:按照目前的自动驾驶感知系统硬件配置,除了Tesla剑走偏锋选择了“纯视觉”路线而只依赖camera/s硬件以外,几乎所有的其它主流自动驾驶厂商,都选择了视觉+超视觉的机器感知的方案,而需要配置完整的camera + Lidar + mmRadar硬件阵列。(小编:针对低速泊车场景的超声波雷达supersonic我们不做讨论)对于后者的综合性传感器配置来说,获取静态场景/物体的测量信息并不算难题。无外界干扰因素的前提下,Lidar通过激光反射点云信息可以直接测量和描述主车四周的的环境信息,从而直接获取3D建模结果。可能和Lidar在车身上不同的安装位置和角度相关会有一些具体差异,如果是Waymo那种车顶360度大型旋转Lidar布局,则可以直接获取最终3D结果。对,直接!但对于Tesla Vision纯视觉解决方案来说,通过成像平面的感光原理,只能是拿到主车四周的部分信息(小编:缺失了关键的深度信息),所以必须有这么一个看起来类似“悖论”的数据处理过程:
真实的物理世界——>小孔成像投影变换——>像平面成2D像——>NN神经网络——>voxel 3D场景信息
单一的视觉传感器的优势,也正是它自身的劣势。
2 为什么说自动驾驶领域的voxel 3D建模需求和以上科学领域有显著区别?
小编:从视频一中的voxel 3D场景信息我们也能看得出来,自动驾驶领域中,至少在Tesla的技术实现中,尤其针对静态周围场景的voxel 3D场景信息的voxel体素的体积较大,视觉上看远大于我们以上提到的各种科学应用中的3D建模中的voxel,最终的呈现效果上也就没那么细腻。小编不敢确定的是,大尺寸的voxel是否能够带来显著降低的建模算力需求?是否带来更高的建模结果置信度?或者说是否足够补充Tesla Vision纯视觉信息对于道路静态场景的理解力不足的现状?以下我们通过参考一个FSD beta系统camera捕捉的视觉场景,和其对应的实际voxel 3D建模结果,来尝试解答以上问题:

图四【Tesla voxel 3d model-4.png】来自@Tristan推特视频截图,URLhttps://twitter.com/rice_fry/status/1463628678445756416/photo/1;

图五【Tesla voxel 3d model-5.png】来自@Tristan推特视频截图,URLhttps://twitter.com/rice_fry/status/1463628678445756416/photo/3 ;
上图四和图五对应显示了一个道路中央带有隔离标识的双向车道。可能读者第一视觉感官是这两张图实在是看不出来有什么2D—3D的对应关系,实际上这就是大型voxel体素的3D化处理效果。注:图五中的绿色方块为模拟出的主车位置(小编:图四和图五之间位置上有些不匹配,请忽略这个问题,不影响我们的对比分析)
红色箭头:此处为场景中最有代表性的景物,也是Tesla Vision所面临的最大的长尾问题之一:如果针对静态景物的NN识别Head并没有针对这种黄色的道路隔离指示牌进行预分类定义和针对性训练,则类似道路中央的障碍物可能会被Tesla Vision所忽略;(小编:各位还记得我们之前公众号里贴过的那个西雅图轻轨所特有的单支柱结构嘛?如果没有针对性分类和训练、或者本文所讨论的针对静态场景信息的3D voxel识别结果,那就是存在于“可驾驶区域“内极大的驾驶风险;图五中我们可以看到识别结果为一个稳定的、叠加增高的体素voxel立柱;
紫色箭头:图五中的紫色箭头所指的边界高度voxel,整齐划一,对应为图四当中的马路边的路缘石。高于路面一个voxel高度的路缘石结构被准确地、连续地识别出来,可以有力地补充Tesla Vision中针对马路可行驶区域边界的识别置信度。在这里我们也可以思考一下,精准地模拟路缘石可能的高度和各种形状和缺损,实际上对于“可行驶区域”边界的界定没有什么特别好的增益。连贯地、稳定地识别出来路缘石边界即可;
蓝色箭头:图五中高出路缘石高度的voxel是对应与图四当中的灌木绿化带,因为面积较大,所以也是呈现出连贯的趋势;
紫色箭头:图五中绿色箭头的voxel柱状结构,对应于图四当中的路边电线杆。目前尚不清楚不同voxel体素的不同颜色所代表的具体含义,可能是识别结果置信度,也可能是高度。
综上可以看到,路侧更远处的更高高度的场景识别,目前是么有输出的,仿佛被人切了一刀。其实很好理解,在距离“可行驶区域”以外一定距离上的高度信息对于自动驾驶系统并无增益,可以忽略。后面我们还会看到一个例子,Tesla的这种voxel场景识别技术,可以识别地下车库的顶棚。对于带有顶棚结构的室内场景和隧道场景,高度识别还是有实际意义的。
在经过这个理解过程之后,小编相信读者再看图五的voxel 3D输出,就不会是之前那种一头雾水的感觉了。当然图五所代表的voxel 3D场景识别结果依然是低信息密度的识别输出。但考虑到Tesla Vision识别堆栈的识别结果不会是以voxel 3D场景为唯一准绳,针对静态场景尤其是障碍物的voxel 3D识别结果一定是视觉识别输出的补充,从而实现对于“防撞”等关键任务的保障。
我们可以再看一个实际的静态场景处理前后对比:

图六【Tesla voxel 3d model-6.png】来自@Tristan推特视频截图,URLhttps://twitter.com/rice_fry/status/1463628811321311236/photo/1;

图七【Tesla voxel 3d model-7.png】来自@Tristan推特视频截图,URLhttps://twitter.com/rice_fry/status/1463628811321311236/photo/3;
以上图六和图七的对比非常明确,主要表达对于公路路面上的三角锥的voxel 3D识别。因为三角锥本身的椎体结构(底部粗顶部细),因此voxel识别结果也基本是这个趋势。当然针对单个三角锥来说,voxel 3D的识别结果是不能令人满意的,太过粗糙以至于如果你单独观察图七,实际上你并不能分清楚这些堆状障碍物的本质属性到底是什么东西。但其所能表达的指定位置上有障碍物的这个性质是足够有价值的:FSD beta的路径规划模块需要考虑这些障碍物,并避让。当然,从历史经验上看,Tesla Vision的静态物体识别Head是可以提供对于三角锥这种交通常见物体的识别和分类的,并不需要依赖额外的voxel 3D NN识别输出,但如果遇到交通场景长尾现象中各种可能的障碍物属性无法穷尽的客观事实,那么voxel 3D的输出就显得十分必要了。
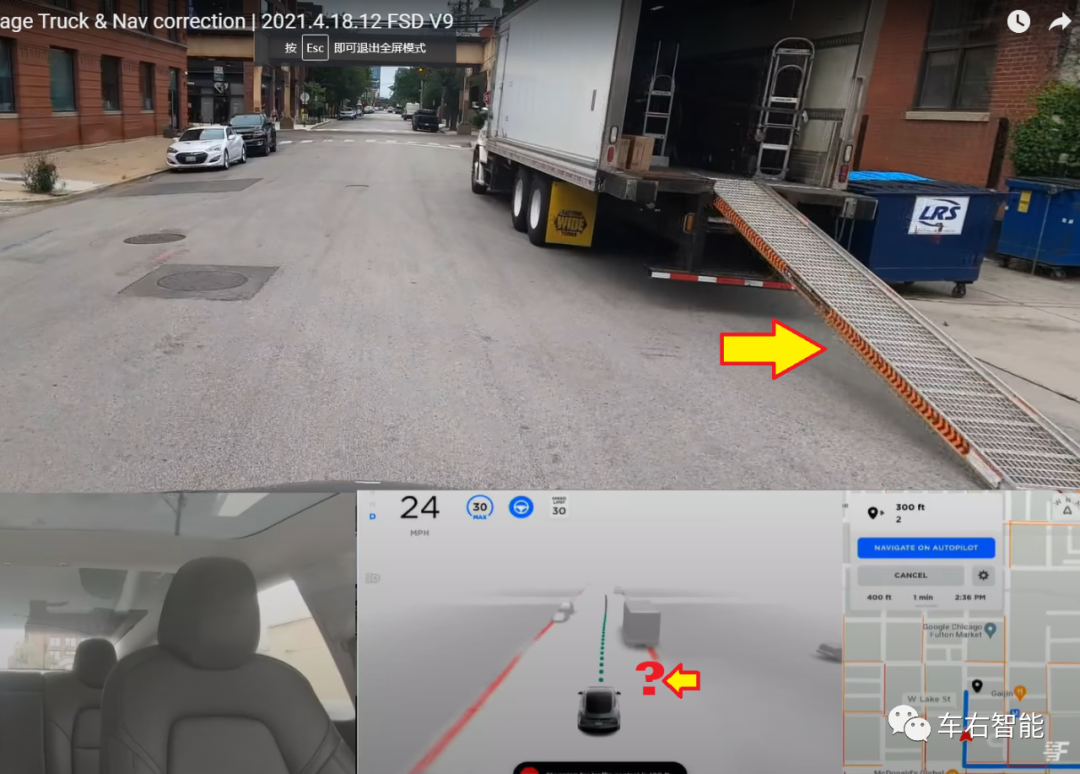
图八【Tesla FSD beta v9-18.png】,图片来源请参考本公众号之前的历史文章插图;

图九【Tesla FSD beta v9-31.png】,图片来源请参考本公众号之前的历史文章插图;
以之前我们公众号文章中曾经捕捉到的FSD beta路测场景,我们可以实地看到大量存在的Tesla Vision无法识别的长尾现象。图八中的货车卸货斜板结构;图九中西雅图轻轨支柱位于道路可行驶区域内部等等。对于Lidar、mmradar等有源传感器,识别类似障碍物并非难题,但对于纯视觉方案来说,如果不按照视觉+NN的标准数据收集和训练方法,针对道路中央的支柱、货车尾部的卸货斜板等目标物体提前建立分类并进行训练,就永远不会被Tesla Vision的HydraNets所识别,从而对自动驾驶系统构成真实的威胁。(小编:读者可能会想到车体上还有四周12个supersonic雷达可以用于最后的防撞告警?但大量事实证明Tesla autopilot系统不会在正常行驶中使用超声波感知数据做防撞操作,仅作障碍物提示使用)
FSD beta所采用的voxel 3D NN的技术细节并未得到披露,从类似的一般性的公开方法来说,从2D单个图像中恢复出voxel 3D信息的方法是基于标准的Encoder—Decoder结构的。小编以一篇公开论文(V3DOR网络)为例,大致论述一下其背后的技术原理。
V3DOR=Visual 3D Object Reconstruction,属于典型的encoder-decoder架构的NN。Encoder编码部分将从camera相平面输出的2D图像中获取“合适的”特征,Decoder将在这些特征的基础上恢复目标物或者场景的3D信息。整体的训练数据来自于一个叫做ShapeNet的数据集,因数据集在近期数据规模的不断丰富和演进,因此V3DOR的性能在稳步进化,号称State of the art。实际上利用Lidar技术或者结构光学摄影技术,部署在消费电子产品上,比如手机,来拍摄实际物体并生成矢量化的目标物3D成像,还是一个比较成熟的技术。(小编:毕竟已经进入消费电子行列了)以从iphone12pro开始进入iphone系列的Lidar模块为例,如下效果:
【小编:请注意,以下关于iPhone Lidar的资料来自于少数派站点文章《iPhone12 Pro的激光雷达能做哪些有趣的事?》】

图十【Tesla voxel 3d model-9.png】来自互联网,URLhttps://sspai.com/post/63498/ ;
从近景的货柜开始,打开iPhone的Lidar传感器进行扫描,从图中你会发现,Lidar传感器与肉眼不同,它看到的只有远近关系而没有材质。受限于机身尺寸和需求差异,iPhone Pro 和 iPad Pro 上的雷达传感器只能识别几米的距离。上图中可以看到深度信息只包含镜头周边的场景,包括左手的冰柜和左手的货架,而过远的地方则无法识别。

图十一【Tesla voxel 3d model-10.png】来自互联网,URLhttps://sspai.com/post/63498/ ;
如果综合利用iPhone机体内的其他传感器,比如陀螺仪和网格系统,iPhone 会通过陀螺仪来对设备姿态进行记录(小编:这意味着拿着iPhone的你可以亦步亦趋地朝前走,而陀螺仪/IMU可以记录你和iPhone的姿态从而生成基准网格,并将运动过程中Lidar所有的记录信息按照相对位置保存并纳入网格系统)。当扫描开始后,它会通过一套网格系统来记录被拍摄物品所处的位置。上图所示,便是拍摄过程中的网格视图。

图十二【Tesla voxel 3d model-11.png】来自互联网,URLhttps://sspai.com/post/63498/ ;
Lidar扫描到的信息是无数的位置关系,仅仅整理成网格形式还不够精细、准确。为将这些信息变成可用的模型,我们可以使用多边形网面图,它也被称作 Mesh。上图所示,货柜被进一步处理成一个个三角形组成的一张网。这个网所具备的凹凸代表,便是真实世界中物品所具备的形状和深度关系。Mesh+Grid的后台技术,将Lidar结构化的深度信息,很条理地整理出来了。当然,除了这些深度信息外,最后一步需要获取的便是从iPhone的光学摄像头拍照。这一步与Lidar传感器无关,使用的是设备上的普通摄像头,用于记录场景的材质 Texture。
下一步可以在Mesh+Grid的基础上遍历整个便利店,则可以得到整体的深度信息图。继续将这些深度信息组合所得的网面图所得三角填充基础色(小编:我的理解是光线强度和阴暗,不涉及颜色),得到结果如下图所示:

图十三【Tesla voxel 3d model-14.png】来自互联网,URLhttps://sspai.com/post/63498/ ;
最后将拍到的图片根据位置一一还原到扫描到的场景中,会得到完整的,带有纹理的图片。

图十四【Tesla voxel 3d model-15.png】来自互联网,URLhttps://sspai.com/post/63498/ ;
小编没有iPhone搭载的Lidar相机的使用体验,但想必以上这个流程应该不是实时的。对于自动驾驶来说,拥有Lidar传感器当然是件好事儿,但对于选择纯视觉方案的Tesla来说,没有Lidar,可相关自动驾驶的识别和感知能力、尤其是对于未分类障碍物的需求,却丝毫不能缺失。因此,从视觉出发、甚至苛刻到必须从单张2D视觉像文件出发,要实时构造出道路环境下的深度信息,难!且必要!!
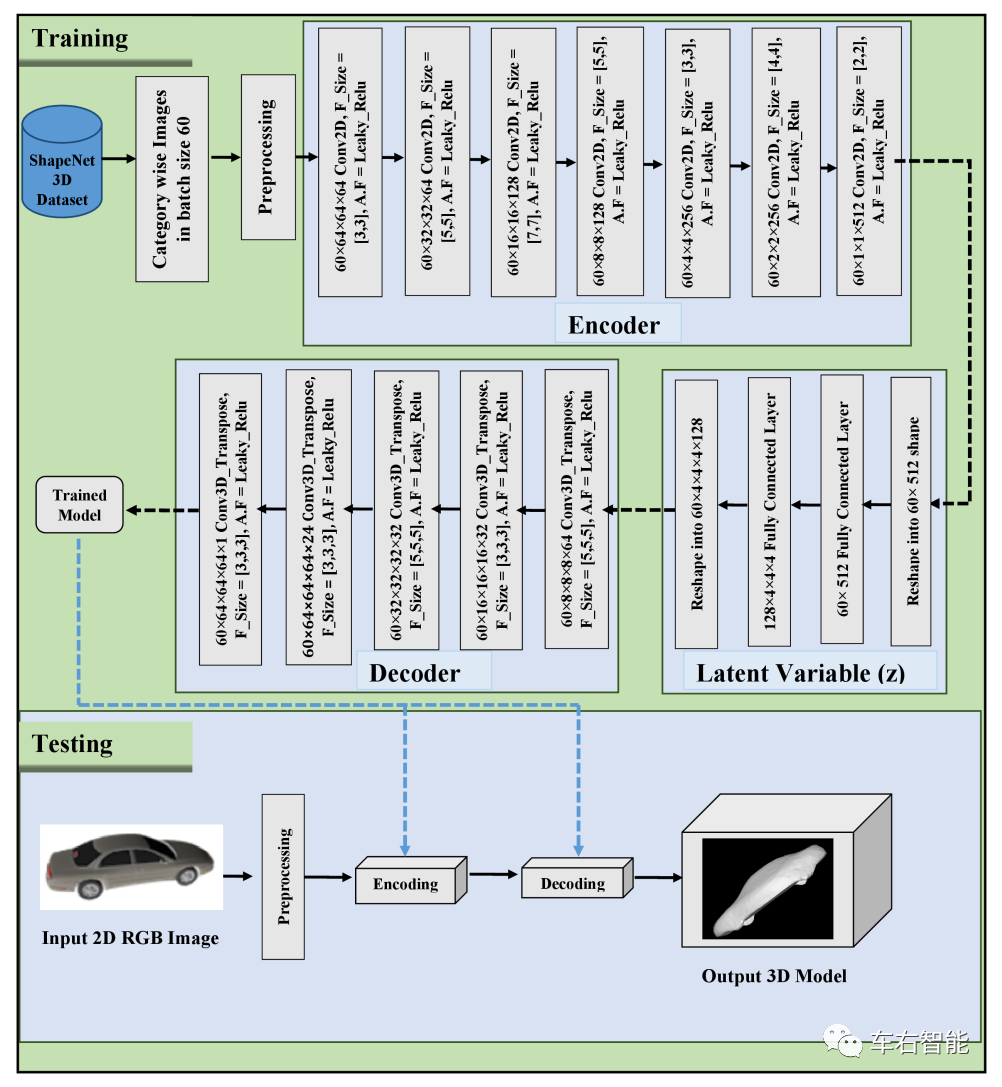
图十五【Tesla voxel 3d model-16.png】来自论文《Voxel-Based 3D Object Reconstructionfrom Single 2D Image Using Variational Autoencoders》插图,作者Rohan Tahir等;
如上图所示,V3DOR=Visual 3D Object Reconstruction网络具备典型的encoder-decoder架构的NN。底部的蓝色框内呈现了2D到3D变换的过程,对于一个标准的2D图像文件,需要如下处理过程:
1 图形文件的预处理过程:
针对任何给定的图形文件,V3DOR需要对其进行灰度处理和Normalize一般化,降低图形文件和图形文件之间的差异。首先,目标是转换成3D信息,目标物体和场景的颜色并不重要,一般化处理则包括统一到固定像素(这里是128*128pixels)以降低CPU和RAM负荷;每像素的灰度尺度为0-255之间的数值表述;同时还需要将目标物尽可能放置在文件的尺寸中心等等,尽可能捕捉尽可能多的可以表征3D信息的特征;
2 Encoder编码部分:
编码部分一共七层的2D卷积层,小编确实没太看懂上图中的卷积层参数,但论文中给出的实际是标准的平面卷积参数,分别是(64, 3 × 3, 2),(64, 5 × 5, 2),(128, 7 × 7, 2),(128, 5 × 5, 2),(256, 3 × 3, 2),(256, 4 × 4, 2),(512, 2 × 2, 2)。以上卷积参数格式为,(filter channels, spatial filter dimensions, stride)。可以看到一个大的趋势,其实和我们日常使用的2D CNN主流参数没有区别,都是越往后channel越大,可以学习到越来越多的高层semantic语义信息。
Encode编码部分最终输出的所谓隐含变量(Latent Variable)是1维的,size为512,是一个数组格式。进入隐含变量表达时,将其通过一个全连接网络扩展为8192维数组。按照作者的说法,可以将更多从2D图像内学到的特征,充分表达出来,以便后续的Decoder解码部分可以据此恢复出较好的立体信息。
3 Decoder解码部分:
隐含变量Latent Variable(一个8192维数组)作为学习来的特征,被送入Decoder执行解码。Decoder就是根据输入的隐含变量来执行一个类似形变的操作,将形变结果填写入一个只有一个channel的3D空间内。注意,这里这个V3DOR的输出空间是一个32*32*32的立体空间,只有一个channel,也就是立体空间内各向等质,不再做任何特征上的区分。可以打个类比,就好像3D打印出来的模型,通体一个材质,但可以充分反映物体的3D属性,就是最大的成功。
具体的Decoder解码器包含5层的3Dtranspose,小编从未见过如此结构,具体参数格式为:((filter channels, filter dimensions, stride),类似于3D CNN?具体指标为:五层(64, 5 × 5 × 5, 2),(32, 3 × 3 × 3, 2),(32, 5 × 5 × 5, 2),(21, 3 × 3 × 3, 2),(1, 3 × 3 × 3, 1)。
至此,V3DOR将2D图形(128*128pixels)转换为3D空间物体表象(32*32*32不清楚何种单位),且为矢量格式。
可能有的读者脑子转不过弯儿,这不是空手套白狼吗?怎么就encoder——decoder就大变活人出来3D信息了呢?我们其实可以这样想,给你一个车辆图片,2D的当然,你必然可以想象出它的3D外观,这是毫无疑问的,建立在大量“先验或者经验”的基础之上,比如汽车就四个轮子,汽车基本是个长方体,车辆顶部结构或者正方或者溜背结构等等,人类大脑内部有大量的逻辑关系提示你你看不到的车体部分是什么结构和尺寸。对于V3DOR也一样,只要有足够大的样本数据库,NN可以用一种最笨的办法学到人类的这种推理经验,本质就是监督学习。
如果我们延伸考虑类似V3DOR的NN结构,如果在FSD beta内部,它大概应该是一个相对独立的应用,而且对于camera raw data的处理,可能在feature的参数要求上和其它识别task不同而独立存在,也可能共用一个backbone,不确定。因为缺乏明确的技术描述,我们只能大概推测voxel 3D场景任务Head在HydraNets中的大致位置,如下图:
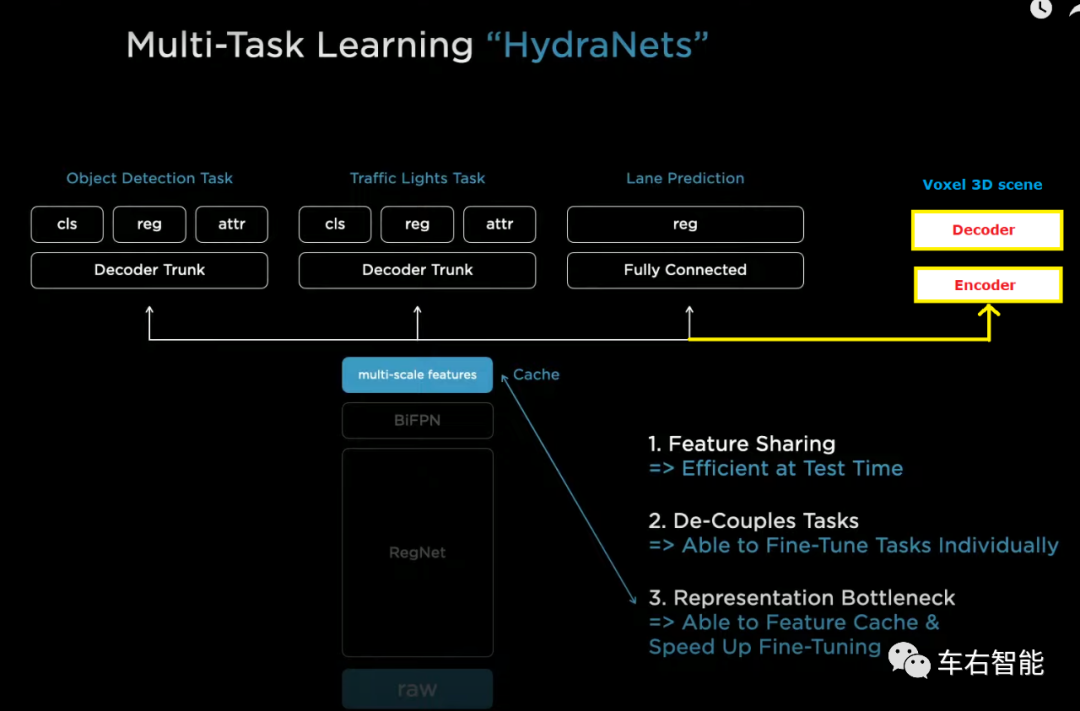
图十六【Tesla voxel 3d model-8.png】来自TeslaAI day主题演讲视频截图以及小编编辑结果,底图URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=4115s ;
这个推测是基于voxel-3D task作为一个标准head,坐落于标准CNN backbone基础之上的。但也有可能不是,不过不影响我们对于这个功能的理解。
最后,关于这个话题,我们可以回到我们之前提到过的单一传感器——camera的悖论。Elon Musk也不知道是不是最早被Mobileye的Shashua教授洗了脑,执拗地坚持使用Camera,而且还是独眼camera,放弃mmradar,不屑Lidar,从而不带丝毫的立体信息。从而成功地把自己逼入“感知绝境”。在这个独眼基础上,FSD beta想不聪明都不行,而且至少要等同于人类驾驶智能才有可能迈入L4境界,甚至因为独眼而更难。
在现有的神经网络NN架构下,感知技术普遍是建立在监督学习的基础之上,这意味着机器需要知道通过训练,我要学什么?才有可能学得足够好。但现实是长尾的,千奇百怪层出不穷,此路在可靠性上就行不通。因此必要的机器测量比如Lidar,在面对奇怪长尾场景的时候,就显得尤为必要….. 除非…..Tesla可以从camera中恢复出足够精度和可靠性的类Lidar输出。
这就是这个悖论的起点。不要测量,要感知,可感知结果不能确保安全的前提下,通过感知技术实现基本等效的测量结果,沿着道路环境用camera raw data恢复出3D世界,但并不对其进行识别操作。其本质,又回到了曾极力避免的机器“测量”的本意上。
-
基于3D数据卷积神经网络的物体识别2020-01-16 4375
-
基于隐式神经网络的2D激光雷达定位算法2023-02-20 1213
-
卷积神经网络简介:什么是机器学习?2023-02-23 25564
-
3D卷积神经网络的手势识别2018-01-30 2600
-
2D到3D视频自动转换系统2018-03-06 1791
-
深度学习不是万灵药 神经网络3D建模其实只是图像识别2019-06-17 5456
-
MIT:使用深度卷积神经网络提高稀疏3D激光雷达的分分辨率2020-05-17 2665
-
3D 机器视觉为什么将逐步取代 2D 识别技术?2020-08-21 6035
-
阿里研发全新3D AI算法,2D图片搜出3D模型2020-12-04 4795
-
谷歌发明的由2D图像生成3D图像技术解析2020-12-24 5822
-
3d人脸识别和2d人脸识别的区别2022-02-05 54417
-
数坤科技3D卷积神经网络模型用于肝脏MR图像的精准分割2022-04-02 5445
-
探讨一下2D和3D拓扑绝缘体2022-11-23 5072
-
2D与3D视觉技术的比较2023-12-21 3296
-
一文了解3D视觉和2D视觉的区别2023-12-25 5688
全部0条评论

快来发表一下你的评论吧 !
