

CLarET:实现上下文到事件相关感知的预训练模型
描述
作者:Yucheng Zhou, Tao Shen, Xiubo Geng, Guodong Long, Daxin Jiang
自然语言文本里描述的“事件”,通常是由一个谓词及其论点组成的一个文本片段(span),是一个细粒度的语义单元,描述了实体的状态和行为,如 He looks very worried 和 I grab his arms。理解事件并建模它们之间的相关性是许多推理任务的基础。在图1的例子中,想要生成事件[E],模型需要先知道这里有四个事件,“it tries the knob”、“[E]”、“the creature starts pounding on the door”、“(the creature) to break it down”,然后根据其他三个事件及其相关性,如“but”表达的对比关系和“so”表达的因果关系,来预测[E]。

现有的基于事件的推理工作中,很多是针对某个特定的任务设计的,包括溯因推理、故事结尾的分类和生成、反事实推理、脚本推理等具体的任务,算法的应用范围较窄。预训练模型时代,更好的方案是直接训练一个基于事件的预训练模型,然后推广到各种下游推理任务上。当然,倒也不必从0到1,通常情况下,只需在通用的预训练语言模型(如BERT、GPT、BART、T5)上做微量的 continue pre-training,就能得到适用于某个领域的较好的模型了。
CLarET
ClarET由三个预训练任务组成,分别是Whole Event Recovering,Contrastive Event-correlation Encoding和Prompt-based Event Locating。
Whole Event Recovering(WER)
WER 的目的非常直接,就是让 encoder-decoder 架构的生成式模型还原被 mask 的整句事件描述。具体的,给定一段文本 ,其中某句话描述了事件 ,现在要做的就是用一个特殊标签 [M] 把这句话在原文中替换掉,这里用 表示被 mask 的原文。然后将文本 给到 encoder,再由 decoder 还原事件 的描述。用数学公式表示的话,就是求解给定上下文 和模型 的前提下, 的概率值:
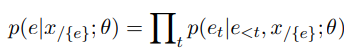
参照 Transformer 序列生成,这部分的训练目标就是优化事件 上的最大似然估计,因此损失函数定义为 :
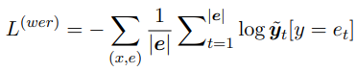
其中, 表示被 mask 的整个事件的描述, 则表示 的 tokenized tokens,即 。 是 decoder 的预测概率分布, 表示 在 t-step, 的概率。decoder 的预测依赖 encoder 部分的输出 :
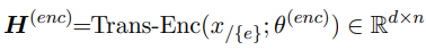
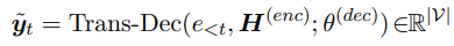
这个目标类似于span recovering,但不同之处在于,在这里:
是按照一个完整的事件描述来选取 masked span 的,所以 masked span 的长度远大于普通的 span recovering 中的 masked span(普通的 span 最多只有22个 tokens,图4提供了长度分布);
另外,为了促进事件及其上下文之间的事件相关性建模,ClarET 每次只会 mask 一个事件,而其他的 MLM 工作通常会有多个 masked span。
事实上,由于现在这种 event-level 的 masked spans 比较长,就会一定程度上影响模型学习事件及其上下文之间的关系,具体体现在:
Encoder-Decoder 架构的生成式模型,如 BART 或 T5,依赖的是 token-level 的隐式共现来恢复事件描述,但是上下文 和事件 之间那种 event-level 的相关性就没有被模型利用到,所以就目前以 WER 为预训练任务得到的这个模型,在事件推理的任务上表现并不好。
由于现在直接将整个事件描述都 mask了,它的前一部分语义完整,后一部分也语义完整,它自己也语义完整,所以某种程度上来说,这个被 mask 的部分,出现什么句子都有道理,也就是说模型要正确还原一整段完整的话还是有相当的难度的,具体可以参考一些autoencoding MLM的工作。
为了解决这两个问题,作者增加了两个预训练任务,分别是,在 encoder 端增加事件相关的对比学习任务来增强上下文和事件之间的相关性,以及prompt-based event locating,意图降低 decoder 端的生成难度。
Contrastive Event-correlation Encoding
对于第一个问题,本文提出的解决方案是,在 encoder 端显示地强调缺失事件的上下文和被 mask 的事件之间的相关性,并使用对比学习来实现。对比学习通过对比来学习区分事物,通常的做法是将数据分别与正例样本和负例样本在特征空间进行对比,并构造合适的 loss 函数,拉近数据与正样例的距离,同时尽可能远离负样例。因此,可以通过构造与上下文不相关的负例事件,和正确的事件一起提供给模型,增强模型学习正确的事件描述及其上下文的相关性的能力。正例事件 和它的负样例 的 encoder embeddings 为 和 :
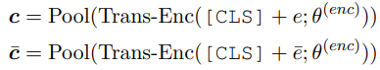
在以下对比学习 loss 中, 和 增强了 里 [M] 这个 token 在 中的表示 。本文中使用的距离函数 d(·,·)是欧几里得距离。
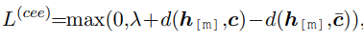
经过负样本增强的 也会在 decode 阶段提供事件级信息,一定程度上也会对缓解第二个问题有帮助吧。
Prompt-based Event Locating
不过针对第二个问题,作者有更加直接的方案,就是利用 prompt,将 WER 目标简化为提取生成任务,模型仅需从提示中定位(有助于模型缕清句子之间的承接关系)和复制一个候选的提示出来(限制模型的搜索范围)。
首先第一种提示,“选正确的事件描述”。作者参考 prompt-based multi-choice QA,也设计了一个 Option prompt。这里稍微讲一下 Multi-choice question answering(MCQA) 任务,MCQA 就是根据给定的问题,从候选答案中选择正确的答案[2]。现有 MCQA 存在以下两种做法:1) Text-to-Text:通过BART或T5等生成预训练模型,将问题和各个候选项同时编码,让模型直接生成正确的答案;2) Encoder-Only:通过 BERT 或 RoBERTa 等预训练模型,将候选项分别与问题一起编码,得到每个候选项的表示,再比较各个候选项的表示,选出答案。在本文中,使用的是 Text-to-Text 范式来设计 Option prompt。
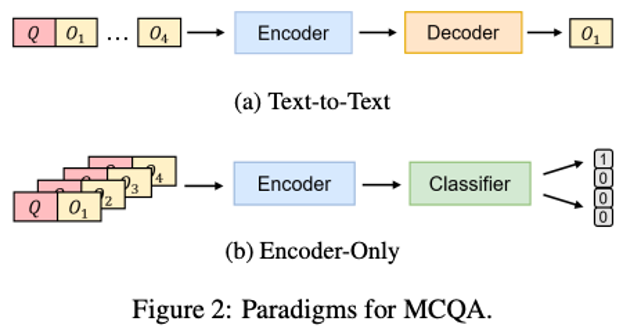
对于每段文本 ,会 sample 出 M 个 negative event ,和正确的 event 一起,共 M+1 句话,将它们随机排列之后,拼接到 的后边得到 。这里给出 的一个样例:“Dan’s parents were overweight. [M] The doctors told his parents it was unhealthy. His parents understood and decided to make a change. Options: (a)They got themselves and Dan on a diet. (b)Dan was overweight as well. (c) They went to see a doctor.” 其中正确的选项是 (b),即,模型需要生成“Dan was overweight as well.”这句话。参照 WER,这部分的目标表示为 。

其次第二种提示,“找错误的事件描述”。类比不连贯推理,原文中的目标事件 会被某个错误的事件 所替换,模型的任务就是指认出 ,相应的 prompt 可以构造成如下形式:
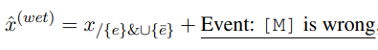
同样以刚刚的文本为例,这里的输入应该是:“Dan’s parents were overweight.They got themselves and Dan on a diet. The doctors told his parents it was unhealthy. His parents understood and decided to make a change. Event: [M] is wrong.”模型的输出则是“They got themselves and Dan on a diet.”,因为这句话是错的。这部分的目标表示为 。
基于以上两种 prompt 范式,这部分的优化目标为:
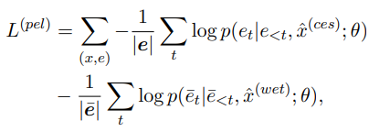
模型预训练和 fine-tuning 的过程
ClarET 基于上面的三个任务进行 pre-training,相应的 loss 就是直接线性相加它们各自的 loss:
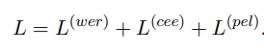
不过有监督的 fine-tuning 会因为下游任务而不太一样。对于生成式任务,只会 fine-tuning 第一个任务。对于判别式任务,如 multi-choice,既可以类似 GPT/T5 那样定制 prompt,以生成式的方式来做,使用 negative log-likelihood loss;也可以像 BART 那样取 classifying heads 做分类式的 fine-tuning,使用 cross-entropy loss。实验发现 BART 这种效果更好,所以接下来的相关实验都采用了这种形式。
与其他基于事件的预训练模型对比
本文还稍微对比了一下 ClarET 和另外两个事件预训练模型 EventBERT 和 COMeT。ClarET 跟 EventBERT 的数据处理以及动机是一致的,但是 EventBERT 是“discriminative-only”,即仅适用于分类任务,ClarET 则在是生成式的范式,能支持更加“unified”的场景;另外,ClarET 的对比学习和基于 prompt 的事件定位这两个任务,能显示并有效地学习上下文和事件之间的 event-level corrections,相比 EventBERT 的“event-backfilling and contextualizing”更高效。另一个,COMeT,它虽然也是一个生成式模型,但侧重于 triple-level 的常识推理——给定(head event, relation)来生成 tail events,动机、范围、评价指标,跟 ClarET 都是正交的。
实验/分析
主要结果
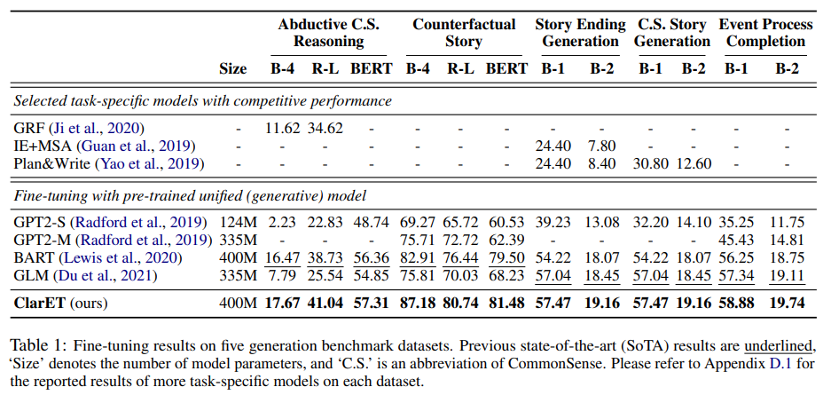
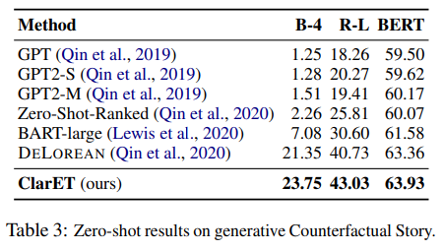
本文选取了5个生成任务和4个分类任务作为下游任务进行模型的评估,每个任务使用一种数据集。生成任务包括 ART (αNLG) 上的溯因常识推理、TIMETRAVEL 上的反事实故事生成、故事结尾生成、常识故事生成和 APSI 上的事件过程完成。分类任务包括 MCNC 上的脚本推理、ART (αNLI)上的诱导常识推理、ROCStories 上的叙事不连贯检测和故事完形填空测试。
从表1看来,ClarET 在生成式任务上表现相当优异,都达到了 SOTA,一定程度上说明了基于 event-level 做 few steps continual pre-training 是可行的方案。当然,在生成式范式的加持下,ClarET 很自然地能为“各种以事件为中心的相关推理任务提供一个通用的解决方案”。
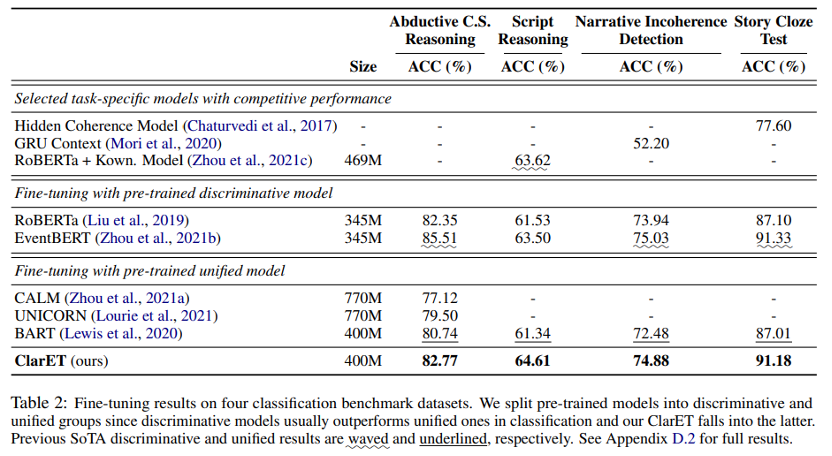
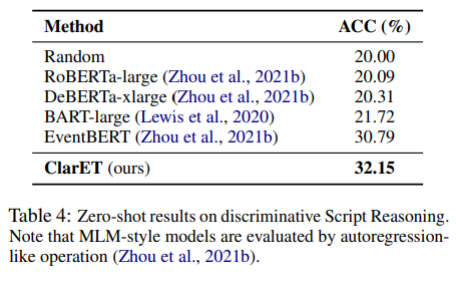
再来看看表2,ClarET 在分类任务上也挺不错的,可以跟强判别式模型比如 EventBERT 拼一拼,虽然某些任务的精度稍差一点,但是 GPU 小时比 EventBERT 少了5.6倍,而且泛化性比判别式好。有一点需要注意,EventBERT 的预训练任务范式和下游任务范式其实是差不多的,而 ClarET 预训练是生成式的,下游任务则换成分类,还是差挺多的,这样还能有如此结果,说明 ClarET 还是有一定优势的。后续也可以把 ClarET 作为统一的基于事件的预训练模型,用在以事件为中心的相关任务上。
一些定量分析
Zero-shot Learning
这部分实验主要想验证 ClarET 有没有学到事件信息,对比对象是其他的 MLM 模型,结果看表3和表4,还是按生成式和分类式划分。通用的预训练模型没有针对事件进行任何处理,可想而知结果跟 ClarET 是比不了的。Zero-shot 设定下,ClarET 显然是最好的。
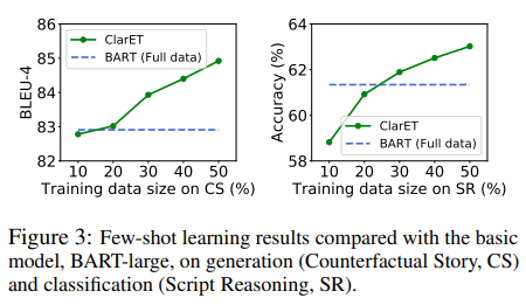
Few-shot Learning
因为 ClarET 减少了预训练和微调在事件上的不一致,所以只需要10%-30%的训练数据进行微调,就可以实现与强基线类似的性能(图3)。
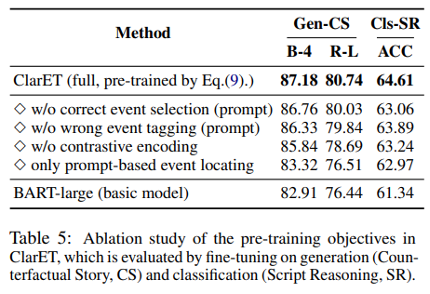
Ablation study
表5在生成和分类任务上分别进行了三个预训练目标任务的消融实验,每个预训练任务都能在基准模型 BART-large 的基础上带来提升。
Comparison with Larger Model
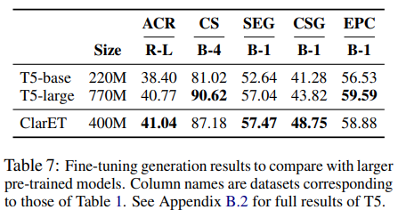
表7验证了事件相关知识能使预训练模型在参数量较少的情况下也能有较好的表现。
Difficulty of Event Generation
表6,验证只使用 WER 的预训练存在学习困难问题,而额外的两个预训练任务能缓解这个问题。用的评价指标是事件级困惑度 ePPT。我们都知道,当我们在比较几个语言模型的优劣时,我们希望更好的语言模型能赋予测试集中的正确句子更高的概率值,相应的,模型的困惑度(Perplexity)就越低;那么类比 PPL,ePPL 就可以理解为,期望更好的语言模型能够赋予相关事件的句子更高的概率值,且相应的整体 ePPL 越低越好。所以当表6中 ClarET 的 ePPL 明显低于 WER-Only Model 时,说明额外的两个预训练任务能有效改善 WER。
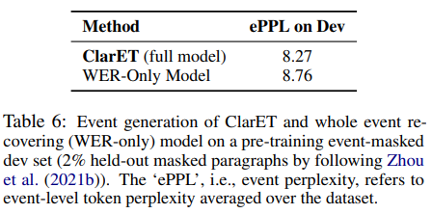
Long-span Event Generation.
图4, 验证 ClarET 在 longer-span 事件生成上更有优势。本实验的数据里,大部分事件长度在6-8,但仍然有很多大于9的样例。可以明显看到,随着事件长度的增加,其他模型与 ClarET 之间的差距越来越大,因为通用模型在预训练时只考虑了短的 masked span,导致事件生成较差。
Natural Language Understanding (NLU)
图5,验证 minor event-centric continual pre-training 不会损害 BART-large 本身的 NLU 能力,用 GLUE 基准做的验证实验。结果是 fine-tuning 的 BART 和 ClarET 相差不多,说明 ClarET 仍然保留了相当的 NLU 能力。

案例研究与错误分析
最后是 case study 和 error analysis。
图6给了两个生成溯因推理任务的 case。第一个 case 显示 ClarET 能较好地掌握上下文,生成的结果比 BART 要完整。
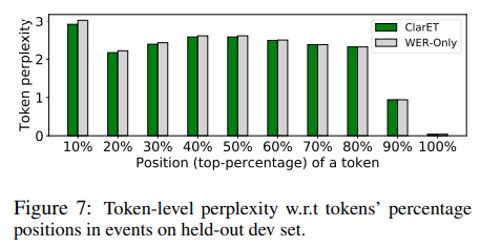
第二个 case 显示,当 gold event 很复杂时,ClarET 的生成结果比较不理想,主要体现在,倾向于忽略比较细微的上下文。具体来说,该模型只关注‘at the end of the day’从而生成‘... spent the whole day ...’,而忽略了‘starting her job ...teacher’和‘they liked her’。更进一步,作者发现模型在解码长事件时普遍存在一个现象,即 ClarET 和 WER-only 之间的 token-level perplexity 的差距逐渐减小(图7)。
作者分析,是因为当 mask 的 span 较长时,模型倾向于在解码过程基于已经生成的 tokens 预测下一个 token,而不是去利用上下文 ,并且 span 越长越明显。这个问题,目前倒是还没有看到很好的解决办法。

结论
本次分享的 ClarET,虽然主要工作是基于事件推理,但是对于其他以事件为中心的任务(如情感分析)还是有不少借鉴之处,特别是后两个预训练任务,从对比学习和提示学习的角度缓解了 long masked span 学习困难的问题,这样的思路也可以推广到其他“从上下文学习语义文本单元”的任务中去,例如当文本单元是实体和概念时,可以用于学习关系和常识知识。
审核编辑:郭婷
- 相关推荐
- 热点推荐
- gpu
-
DeepSeek推出NSA机制,加速长上下文训练与推理2025-02-19 1338
-
我们能否扩展现有的预训练 LLM 的上下文窗口2023-06-30 1639
-
网络安全中的上下文感知2022-09-20 3297
-
如何分析Linux CPU上下文切换问题2022-05-05 3069
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 1129
-
基于Transformer模型的上下文嵌入何时真正值得使用?2020-08-28 3667
-
进程上下文与中断上下文的理解2018-12-11 3436
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 3903
-
Web服务的上下文的访问控制策略模型2018-01-05 969
-
基于上下文相似度的分解推荐算法2017-11-27 991
-
基于Pocket PC的上下文菜单实现2011-07-25 991
-
终端业务上下文的定义方法及业务模型2010-03-06 651
-
移动设备的个性化推荐在上下文感知应用2010-01-15 654
-
基于多Agent的用户上下文自适应站点构架2009-04-11 657
全部0条评论

快来发表一下你的评论吧 !
