

Java进程所使用的内存情况介绍
描述
0.引言
我们经常会好奇,我启动了一个 JVM,他到底会占据多大的内存?他的内存都消耗在哪里?为什么 JVM 使用的内存比我设置的 -Xmx 大这么多?我的内存设置参数是否合理?为什么我的 JVM 内存一直缓慢增长?为什么我的 JVM 会被 OOMKiller 等等,这都涉及到 JAVA 虚拟机对内存的一个使用情况,不如让我们来一探其中究竟。
1.简介
除去大家都熟悉的可以使用 -Xms、-Xmx 等参数设置的堆(Java Heap),JVM 还有所谓的非堆内存(Non-Heap Memory)。
可以通过一张图来简单看一下 Java 进程所使用的内存情况(简略情况):
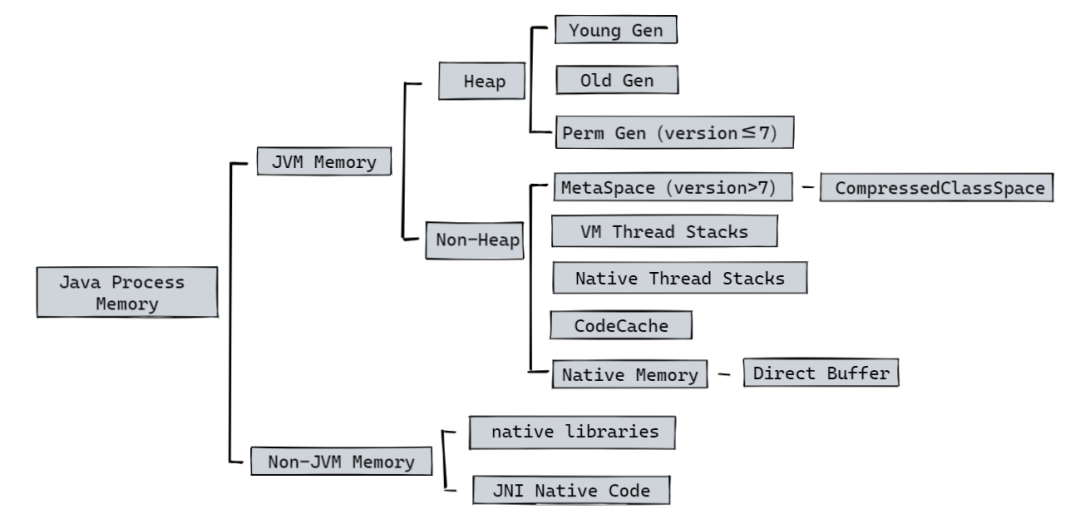
非堆内存包括方法区和Java虚拟机内部做处理或优化所需的内存。
方法区:在所有线程之间共享,存储每个类的结构,如运行时常量池、字段和方法数据,以及方法和构造函数的代码。方法区在逻辑上(虚拟机规范)是堆的一部分,但规范并不限定实现方法区的内存位置和编译代码的管理策略,所以不同的 Java 虚拟机可能有不同的实现方式,此处我们仅讨论 HotSpot。
除了方法区域外,Java 虚拟机实现可能需要内存用于内部的处理或优化。例如,JIT编译器需要内存来存储从Java虚拟机代码转换的本机代码(储存在CodeCache中),以获得高性能。
从 OpenJDK8 起有了一个很 nice 的虚拟机内部功能:Native Memory Tracking (NMT) 。我们可以使用 NMT 来追踪了解 JVM 的内存使用详情(即上图中的 JVM Memory 部分),帮助我们排查内存增长与内存泄漏相关的问题。
2.如何使用
2.1 开启 NMT
默认情况下,NMT是处于关闭状态的,我们可以通过设置 JVM 启动参数来开启:-XX:NativeMemoryTracking=[off | summary | detail]。
注意:启用NMT会导致5% -10%的性能开销。
NMT 使用选项如下表所示:
| NMT 选项 | 说明 |
|---|---|
| off | 不跟踪 JVM 本地内存使用情况。如果不指定 -XX:NativeMemoryTracking 选项则默认为off。 |
| summary | 仅跟踪 JVM 子系统(如:Java heap、class、code、thread等)的内存使用情况。 |
| detail | 除了通过 JVM 子系统跟踪内存使用情况外,还可以通过单独的 CallSite、单独的虚拟内存区域及其提交区域来跟踪内存使用情况。 |
我们注意到,如果想使用 NMT 观察 JVM 的内存使用情况,我们必须重启 JVM 来设置 XX:NativeMemoryTracking 的相关选项,但是重启会使得我们丢失想要查看的现场,只能等到问题复现时才能继续观察。
笔者试图通过一种不用重启 JVM 的方式来开启 NMT ,但是很遗憾目前没有这样的功能。
JVM 启动后只有被标记为 manageable 的参数才可以动态修改或者说赋值,我们可以通过 JDK management interface (com.sun.management.HotSpotDiagnosticMXBean API) 或者 jinfo -flag 命令来进行动态修改的操作,让我们看下所有可以被修改的参数值(JDK8):
java -XX:+PrintFlagsFinal | grep manageable
intx CMSAbortablePrecleanWaitMillis = 100 {manageable}
intx CMSTriggerInterval = -1 {manageable}
intx CMSWaitDuration = 2000 {manageable}
bool HeapDumpAfterFullGC = false {manageable}
bool HeapDumpBeforeFullGC = false {manageable}
bool HeapDumpOnOutOfMemoryError = false {manageable}
ccstr HeapDumpPath = {manageable}
uintx MaxHeapFreeRatio = 100 {manageable}
uintx MinHeapFreeRatio = 0 {manageable}
bool PrintClassHistogram = false {manageable}
bool PrintClassHistogramAfterFullGC = false {manageable}
bool PrintClassHistogramBeforeFullGC = false {manageable}
bool PrintConcurrentLocks = false {manageable}
bool PrintGC = false {manageable}
bool PrintGCDateStamps = false {manageable}
bool PrintGCDetails = false {manageable}
bool PrintGCID = false {manageable}
bool PrintGCTimeStamps = false {manageable}
很显然,其中不包含 NativeMemoryTracking 。
2.2 使用 jcmd 访问 NMT 数据
我们可以通过 jcmd 命令来很方便的查看 NMT 相关的数据:
jcmdVM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
jcmd 操作 NMT 选项如下表所示:
| jcmd NMT 选项 | 说明 |
|---|---|
| summary | 打印按类别汇总的摘要信息 |
| detail |
打印按类别汇总的内存使用情况 打印虚拟内存映射 打印按 call site 汇总的内存使用情况 |
| baseline | 创建一个新的内存使用状况的快照,用以进行比较 |
| summary.diff | 根据上一个 baseline 基线打印新的 summary 对比报告 |
| detail.diff | 根据上一个 baseline 基线打印新的 detail 对比报告 |
| shutdown | 停止NMT |
NMT 默认打印的报告是 KB 来进行呈现的,为了满足我们不同的需求,我们可以使用 scale=MB | GB 来更加直观的打印数据。
创建 baseline 之后使用 diff 功能可以很直观地对比出两次 NMT 数据之间的差距。
看到 shutdown 选项,笔者本能的一激灵,既然我们可以通过 shutdown 来关闭 NMT ,那为什么不能通过逆向 shutdown 功能来动态的开启 NMT 呢?笔者找到 shutdown 相关源码(以下都是基于 OpenJDK 8):
# hotspot/src/share/vm/services/nmtDCmd.cpp
void NMTDCmd::execute(DCmdSource source, TRAPS) {
// Check NMT state
// native memory tracking has to be on
if (MemTracker::tracking_level() == NMT_off) {
output()->print_cr("Native memory tracking is not enabled");
return;
} else if (MemTracker::tracking_level() == NMT_minimal) {
output()->print_cr("Native memory tracking has been shutdown");
return;
}
......
//执行 shutdown 操作
else if (_shutdown.value()) {
MemTracker::shutdown();
output()->print_cr("Native memory tracking has been turned off");
}
......
}
# hotspot/src/share/vm/services/memTracker.cpp
// Shutdown can only be issued via JCmd, and NMT JCmd is serialized by lock
void MemTracker::shutdown() {
// We can only shutdown NMT to minimal tracking level if it is ever on.
if (tracking_level () > NMT_minimal) {
transition_to(NMT_minimal);
}
}
# hotspot/src/share/vm/services/nmtCommon.hpp
// Native memory tracking level //NMT的追踪等级
enum NMT_TrackingLevel {
NMT_unknown = 0xFF,
NMT_off = 0x00,
NMT_minimal = 0x01,
NMT_summary = 0x02,
NMT_detail = 0x03
};
遗憾的是通过源码我们发现,shutdown 操作只是将 NMT 的追踪等级 tracking_level 变成了 NMT_minimal 状态(而并不是直接变成了 off 状态),注意注释:We can only shutdown NMT to minimal tracking level if it is ever on(即我们只能将NMT关闭到最低跟踪级别,如果它曾经打开)。
这就导致了如果我们没有开启过 NMT ,那就没办法通过魔改 shutdown 操作逆向打开 NMT ,因为 NMT 追踪的部分内存只在 JVM 启动初始化的阶段进行记录(如在初始化堆内存分配的过程中通过 NMT_TrackingLevel level = MemTracker::tracking_level(); 来获取 NMT 的追踪等级,视等级来记录内存使用情况),JVM 启动之后再开启 NMT 这部分内存的使用情况就无法记录,所以目前来看,还是只能在重启 JVM 后开启 NMT。
至于提供 shutdown 功能的原因,应该就是让用户在开启 NMT 功能之后如果想要关闭,不用再次重启 JVM 进程。shutdown 会清理虚拟内存用来追踪的数据结构,并停止一些追踪的操作(如记录 malloc 内存的分配)来降低开启 NMT 带来的性能耗损,并且通过源码可以发现 tracking_level 变成 NMT_minimal 状态后也不会再执行 jcmd
2.3 虚拟机退出时获取 NMT 数据
除了在虚拟机运行时获取 NMT 数据,我们还可以通过两个参数:-XX:+UnlockDiagnosticVMOptions和-XX:+PrintNMTStatistics ,来获取虚拟机退出时内存使用情况的数据(输出数据的详细程度取决于你设定的跟踪级别,如 summary/detail 等)。
-XX:+UnlockDiagnosticVMOptions:解锁用于诊断 JVM 的选项,默认关闭。
-XX:+PrintNMTStatistics:当启用 NMT 时,在虚拟机退出时打印内存使用情况,默认关闭,需要开启前置参数 -XX:+UnlockDiagnosticVMOptions 才能正常使用。
3.NMT 内存 & OS 内存概念差异性
我们可以做一个简单的测试,使用如下参数启动 JVM :
-Xmx1G -Xms1G -XX:+UseG1GC -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=256m -XX:ReservedCodeCacheSize=256M -XX:NativeMemoryTracking=detail
然后使用 NMT 查看内存使用情况(因各环境资源参数不一样,部分未明确设置数据可能由虚拟机根据资源自行计算得出,以下数据仅供参考):
jcmdVM.native_memory detail
NMT 会输出如下日志:
Native Memory Tracking: Total: reserved=2813709KB, committed=1497485KB - Java Heap (reserved=1048576KB, committed=1048576KB) (mmap: reserved=1048576KB, committed=1048576KB) - Class (reserved=1056899KB, committed=4995KB) (classes #442) (malloc=131KB #259) (mmap: reserved=1056768KB, committed=4864KB) - Thread (reserved=258568KB, committed=258568KB) (thread #127) (stack: reserved=258048KB, committed=258048KB) (malloc=390KB #711) (arena=130KB #234) - Code (reserved=266273KB, committed=4001KB) (malloc=33KB #309) (mmap: reserved=266240KB, committed=3968KB) - GC (reserved=164403KB, committed=164403KB) (malloc=92723KB #6540) (mmap: reserved=71680KB, committed=71680KB) - Compiler (reserved=152KB, committed=152KB) (malloc=4KB #36) (arena=148KB #21) - Internal (reserved=14859KB, committed=14859KB) (malloc=14827KB #3632) (mmap: reserved=32KB, committed=32KB) - Symbol (reserved=1423KB, committed=1423KB) (malloc=936KB #111) (arena=488KB #1) - Native Memory Tracking (reserved=330KB, committed=330KB) (malloc=118KB #1641) (tracking overhead=211KB) - Arena Chunk (reserved=178KB, committed=178KB) (malloc=178KB) - Unknown (reserved=2048KB, committed=0KB) (mmap: reserved=2048KB, committed=0KB) ......
大家可能会发现 NMT 所追踪的内存(即 JVM 中的 Reserved、Committed)与操作系统 OS (此处指Linux)的内存概念存在一定的差异性。
首先按我们理解的操作系统的概念:
操作系统对内存的分配管理典型地分为两个阶段:保留(reserve)和提交(commit)。保留阶段告知系统从某一地址开始到后面的dwSize大小的连续虚拟内存需要供程序使用,进程其他分配内存的操作不得使用这段内存;提交阶段将虚拟地址映射到对应的真实物理内存中,这样这块内存就可以正常使用[1]。
如果使用 top 或者 smem 等命令查看刚才启动的 JVM 进程会发现:
top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 36257 dou+ 20 0 10.8g 54200 17668 S 99.7 0.0 13:04.15 java
此时疑问就产生了,为什么 NMT 中的 committed ,即日志详情中 Total: reserved=2813709KB, committed=1497485KB 中的 1497485KB 与 top 中 RES 的大小54200KB 存在如此大的差异?
使用 man 查看 top 中 RES 的概念(不同版本 Linux 可能不同):
RES -- Resident Memory Size (KiB) A subset of the virtual address space (VIRT) representing the non-swapped physical memory a task is currently using. It is also the sum of the RSan, RSfd and RSsh fields. It can include private anonymous pages, private pages mapped to files (including program images and shared libraries) plus shared anonymous pages. All such memory is backed by the swap file represented separately under SWAP. Lastly, this field may also include shared file-backed pages which, when modified, act as a dedicated swap file and thus will never impact SWAP.
RES 表示任务当前使用的非交换物理内存(此时未发生swap),那按对操作系统 commit 提交内存的理解,这两者貌似应该对上,为何现在差距那么大呢?
笔者一开始猜测是 JVM 的 uncommit 机制(如 JEP 346[2],支持 G1 在空闲时自动将 Java 堆内存返回给操作系统,BiSheng JDK 对此做了增强与改进[3])造成的,JVM 在 uncommit 将内存返还给 OS 之后,NMT 没有除去返还的内存导致统计错误。
但是在翻阅了源码之后发现,G1 在 shrink 缩容的时候,通常调用链路如下:
G1CollectedHeap::shrink ->
G1CollectedHeap::shrink_helper ->
HeapRegionManager::shrink_by ->
HeapRegionManager::uncommit_regions ->
G1PageBasedVirtualSpace::uncommit ->
G1PageBasedVirtualSpace::uncommit_internal ->
os::uncommit_memory
忽略细节,uncommit 会在最后调用 os::uncommit_memory ,查看 os::uncommit_memory 源码:
bool os::uncommit_memory(char* addr, size_t bytes) {
bool res;
if (MemTracker::tracking_level() > NMT_minimal) {
Tracker tkr = MemTracker::get_virtual_memory_uncommit_tracker();
res = pd_uncommit_memory(addr, bytes);
if (res) {
tkr.record((address)addr, bytes);
}
} else {
res = pd_uncommit_memory(addr, bytes);
}
return res;
}
可以发现在返还 OS 内存之后,MemTracker 是进行了统计的,所以此处的误差不是由 uncommit 机制造成的。
既然如此,那又是由什么原因造成的呢?笔者在追踪 JVM 的内存分配逻辑时发现了一些端倪,此处以Code Cache(存放 JVM 生成的 native code、JIT编译、JNI 等都会编译代码到 native code,其中 JIT 生成的 native code 占用了 Code Cache 的绝大部分空间)的初始化分配为例,其大致调用链路为下:
InitializeJVM ->
Thread::vreate_vm ->
init_globals ->
codeCache_init ->
CodeCache::initialize ->
CodeHeap::reserve ->
VirtualSpace::initialize ->
VirtualSpace::initialize_with_granularity ->
VirtualSpace::expand_by ->
os::commit_memory
查看 os::commit_memory 相关源码:
bool os::commit_memory(char* addr, size_t size, size_t alignment_hint,
bool executable) {
bool res = os::pd_commit_memory(addr, size, alignment_hint, executable);
if (res) {
MemTracker::record_virtual_memory_commit((address)addr, size, CALLER_PC);
}
return res;
}
我们发现 MemTracker 在此记录了 commit 的内存供 NMT 用以统计计算,继续查看 os::pd_commit_memory 源码,可以发现其调用了 os::commit_memory_impl 函数。
查看 os::commit_memory_impl 源码:
int os::commit_memory_impl(char* addr, size_t size, bool exec) {
int prot = exec ? PROT_READ|PROT_WRITE|PROT_EXEC : PROT_READ|PROT_WRITE;
uintptr_t res = (uintptr_t) ::mmap(addr, size, prot,
MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0);
if (res != (uintptr_t) MAP_FAILED) {
if (UseNUMAInterleaving) {
numa_make_global(addr, size);
}
return 0;
}
int err = errno; // save errno from mmap() call above
if (!recoverable_mmap_error(err)) {
warn_fail_commit_memory(addr, size, exec, err);
vm_exit_out_of_memory(size, OOM_MMAP_ERROR, "committing reserved memory.");
}
return err;
}
问题的原因就在 uintptr_t res = (uintptr_t) ::mmap(addr, size, prot, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0); 这段代码上。
我们发现,此时申请内存执行的是 mmap 函数,并且传递的 port 参数是 PROT_READ|PROT_WRITE|PROT_EXEC 或 PROT_READ|PROT_WRITE ,使用 man 查看 mmap ,其中相关描述为:
The prot argument describes the desired memory protection of the mapping (and must not conflict with the open mode of the file). It is either PROT_NONE or the bitwise OR of one or more of the following flags: PROT_EXEC Pages may be executed. PROT_READ Pages may be read. PROT_WRITE Pages may be written. PROT_NONE Pages may not be accessed.
由此我们可以看出,JVM 中所谓的 commit 内存,只是将内存 mmaped 映射为可读可写可执行的状态!而在 Linux 中,在分配内存时又是 lazy allocation 的机制,只有在进程真正访问时才分配真实的物理内存。所以 NMT 中所统计的 committed 并不是对应的真实的物理内存,自然与 RES 等统计方式无法对应起来。
所以 JVM 为我们提供了一个参数 -XX:+AlwaysPreTouch,使我们可以在启动之初就按照内存页粒度都访问一遍 Heap,强制为其分配物理内存以减少运行时再分配内存造成的延迟(但是相应的会影响 JVM 进程初始化启动的时间),查看相关代码:
void os::pretouch_memory(char* start, char* end) {
for (volatile char *p = start; p < end; p += os::vm_page_size()) {
*p = 0;
}
}
让我们来验证下,开启 -XX:+AlwaysPreTouch 前后的效果。
NMT 的 heap 地址范围:
Virtual memory map: [0x00000000c0000000 - 0x0000000100000000] reserved 1048576KB for Java Heap from [0x0000ffff93ea36d8] ReservedHeapSpace::ReservedHeapSpace(unsigned long, unsigned long, bool, char*)+0xb8 [0x0000ffff93e67f68] Universe::reserve_heap(unsigned long, unsigned long)+0x2d0 [0x0000ffff93898f28] G1CollectedHeap::initialize()+0x188 [0x0000ffff93e68594] Universe::initialize_heap()+0x15c [0x00000000c0000000 - 0x0000000100000000] committed 1048576KB from [0x0000ffff938bbe8c] G1PageBasedVirtualSpace::commit_internal(unsigned long, unsigned long)+0x14c [0x0000ffff938bc08c] G1PageBasedVirtualSpace::commit(unsigned long, unsigned long)+0x11c [0x0000ffff938bf774] G1RegionsLargerThanCommitSizeMapper::commit_regions(unsigned int, unsigned long)+0x5c [0x0000ffff93943f54] HeapRegionManager::commit_regions(unsigned int, unsigned long)+0x7c
对应该地址的/proc/{pid}/smaps:
//开启前 //开启后 c0000000-100080000 rw-p 00000000 00:00 0 c0000000-100080000 rw-p 00000000 00:00 0 Size: 1049088 kB Size: 1049088 kB KernelPageSize: 4 kB KernelPageSize: 4 kB MMUPageSize: 4 kB MMUPageSize: 4 kB Rss: 792 kB Rss: 1049088 kB Pss: 792 kB Pss: 1049088 kB Shared_Clean: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Clean: 0 kB Private_Dirty: 792 kB Private_Dirty: 1049088 kB Referenced: 792 kB Referenced: 1048520 kB Anonymous: 792 kB Anonymous: 1049088 kB LazyFree: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB ShmemPmdMapped: 0 kB Shared_Hugetlb: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB Swap: 0 kB SwapPss: 0 kB SwapPss: 0 kB Locked: 0 kB Locked: 0 kB VmFlags: rd wr mr mw me ac VmFlags: rd wr mr mw me ac
对应的/proc/{pid}/status:
//开启前 //开启后 ... ... VmHWM: 54136 kB VmHWM: 1179476 kB VmRSS: 54136 kB VmRSS: 1179476 kB ... ... VmSwap: 0 kB VmSwap: 0 kB ...
开启参数后的 top:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 85376 dou+ 20 0 10.8g 1.1g 17784 S 99.7 0.4 14:56.31 java
观察对比我们可以发现,开启 AlwaysPreTouch 参数后,NMT 统计的 commited 已经与 top 中的 RES 差不多了,之所以不完全相同是因为该参数只能 Pre-touch 分配 Java heap 的物理内存,至于其他的非 heap 的内存,还是受到 lazy allocation 机制的影响。
同理我们可以简单看下 JVM 的 reserve 机制:
# hotspot/src/share/vm/runtime/os.cpp
char* os::reserve_memory(size_t bytes, char* addr, size_t alignment_hint,
MEMFLAGS flags) {
char* result = pd_reserve_memory(bytes, addr, alignment_hint);
if (result != NULL) {
MemTracker::record_virtual_memory_reserve((address)result, bytes, CALLER_PC);
MemTracker::record_virtual_memory_type((address)result, flags);
}
return result;
}
# hotspot/src/os/linux/vm/os_linux.cpp
char* os::pd_reserve_memory(size_t bytes, char* requested_addr,
size_t alignment_hint) {
return anon_mmap(requested_addr, bytes, (requested_addr != NULL));
}
static char* anon_mmap(char* requested_addr, size_t bytes, bool fixed) {
......
addr = (char*)::mmap(requested_addr, bytes, PROT_NONE,
flags, -1, 0);
......
}
reserve 通过 mmap(requested_addr, bytes, PROT_NONE, flags, -1, 0); 来将内存映射为 PROT_NONE,这样其他的 mmap/malloc 等就不能调用使用,从而达到了 guard memory 或者说 guard pages 的目的。
OpenJDK 社区其实也注意到了 NMT 内存与 OS 内存差异性的问题,所以社区也提出了相应的 Enhancement 来增强功能:
JDK-8249666[4] :
目前 NMT 将分配的内存显示为 Reserved 或 Committed。而在 top 或 pmap 的输出中,首次使用(即 touch)之前 Reserved 和 Committed 的内存都将显示为 Virtual memory。只有在内存页(通常是4k)首次写入后,它才会消耗物理内存,并出现在 top/pmap 输出的 “常驻内存”(即 RSS)中。
当前NMT输出的主要问题是,它无法区分已 touch 和未 touch 的 Committed 内存。
该 Enhancement 提出可以使用 mincore() [5]来查找 NMT 的 Committed 中 RSS 的部分,mincore() 系统调用让一个进程能够确定一块虚拟内存区域中的分页是否驻留在物理内存中。mincore()已在JDK-8191369 NMT:增强线程堆栈跟踪中实现,需要将其扩展到所有其他类型的内存中(如 Java 堆)。
遗憾的是该 Enhancement 至今仍是 Unresolved 状态。
JDK-8191369[6] :
1 中提到的 NMT:增强线程堆栈跟踪。使用 mincore() 来追踪驻留在物理内存中的线程堆栈的大小,用以解决线程堆栈追踪时有时会夸大内存使用情况的痛点。
该 Enhancement 已经在 JDK11 中实现。
由于内容较多,关于NMT追踪区域分析的内容将在下篇文章进行分享,敬请期待!
-
jmap dump内存的命令是2023-12-05 4327
-
java内存溢出的几种原因和解决办法2023-11-23 7513
-
Java多线程的用法2023-09-30 2153
-
进程虚拟内存布局以及进程的虚拟内存分配释放流程,涉及的代码2020-06-28 5717
-
Linux下进程的内存结构2020-06-01 1806
-
linux内存的进程查看2019-07-16 1596
-
Linux上对进程进行内存分析和内存泄漏定位2019-07-09 4073
-
Java内存模型及原理分析2017-09-28 676
-
java线程内存模型2017-09-27 763
-
Linux 查看进程和删除进程2016-04-24 3311
-
Java程序内存低效使用问题的分析2009-04-09 897
全部0条评论

快来发表一下你的评论吧 !
