

新型非易失存储器静态损耗均衡算法
存储技术
描述
前言
新型非易失存储器正在逐渐成熟,有望在未来成为工作存储器。然而,在工业实践中,我们发现一些非易失存储器,包含阻变随机存储器(RRAM)、相变随机存储器(PCM)和闪存(Flash)等在使用时会面临使用耐久性有限的问题,即对于一个地址的写入次数是有限的,而实际对存储器进行写操作时,往往会很频繁的访问部分地址,一旦存储器任何部分的写入次数超过了耐久极限,整个器件就会被认为无法工作。因此,需要设计一些算法使得能对整个存储器做均衡的访问,而不是仅仅去对几个特定的区域持续写入,将对某些块的操作分布到整片存储器上,实现各块写入的平衡,这类算法就称为损耗均衡(wear leveling)算法。
硬件损耗均衡算法简介
硬件损耗均衡算法大致可以分为静态和动态损耗均衡。
动态损耗均衡:这些算法通过重复使用擦除次数较少的块来实现损耗平衡[1]。即当下写入地址的被写入量超过规定的阈值时就让其与一个认为的写入次数不大的地址做交换。然而对于原本就存在于那些被写入次数不多的地址里面的数据,不做移动。
静态损耗均衡:与动态相反,静态损耗均衡算法试图通过整个物理地址的移动,从而促进损耗的更均匀分布。
与动态方法相比静态方法优势在于空间开销小,不需要考虑具体程序的动态运行也能达到延长存储器寿命的目的,但正因为于此静态的方法不能充分的挖掘存储器的生命潜力。而动态方法借助记录每个地址被写入的次数、建立地址映射表、定期清理垃圾数据等方式,虽然存储开销相比静态方法增加了但可以获得更好地延长存储器寿命的结果。当然最好的均衡损耗算法一定是根据具体的应用场景去相应调整的,没有最好的算法只有最适合的算法。
下面将先介绍一些静态损耗均衡算法:
1. 基于 PCM 存储器的 Start-Gap 算法[2]
借助两个寄存器 Start、Gap 以及一个缓存区,周期性将每一行(包括很多个地址,具体怎么划分依照设计者的需求决定)移动到其相邻的位置来实现损耗均衡。实质上就是建立了一个代数关系,完成逻辑地址到物理地址的映射。
Gap 记录缓存区的物理地址,Start 记录的是所有块均移动一次的次数。每当写入次数达到设定的阈值时,通过 Gap 存储的地址指引,将缓存区(图中红色块)不断向前移动,当缓存区到达第一块时,下一次就移动到最后一块,如此循环。具体每一次移动操作为(如图1):
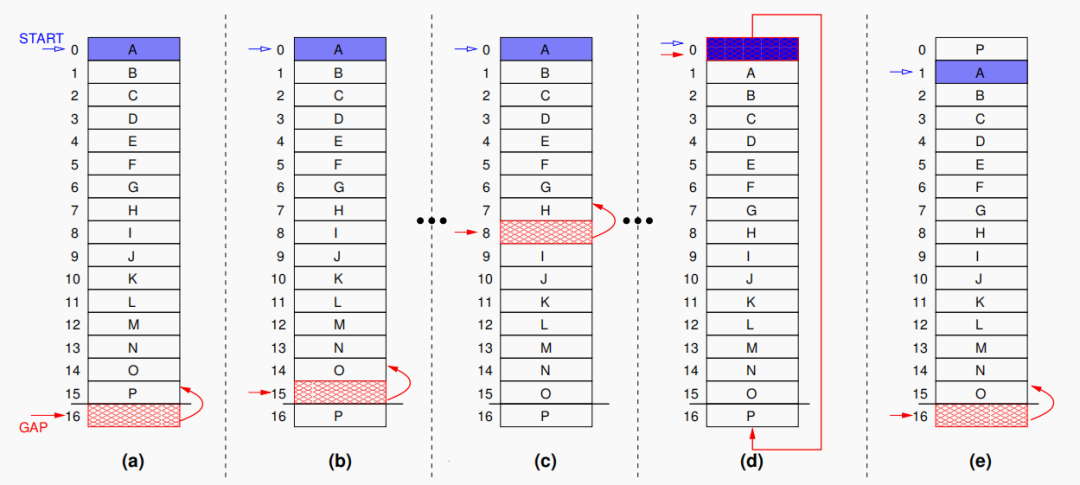
图1:在一个包含16行的存储器上进行Start-Gap算法
逻辑地址(LA——logical address)与物理地址(PA——physical address)间的代数关系为:(N等于内存中不包含缓冲区的行数)
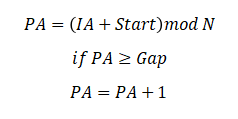
由于 CPU 在访问寄存器时,无论是存取数据还是存取指令,都趋于聚集在一片区域——局部性原理,可以看出仅依靠这样相邻位的移动,会将一个大量写入的行移动到另一个大量写入的行,这可能导致早期的磨损。于是引入静态地址随机化,将原本连续的地址重映射为彼此间隔很大的新地址。
实现静态随机化处理可以借助随机可逆的二进制矩阵(Random Invertible Binary Matrix),如图2,RIB 内部的元素由0,1随机序列,当逻辑地址与该矩阵相乘后,可以使得原本连续的 LA 值分散开。
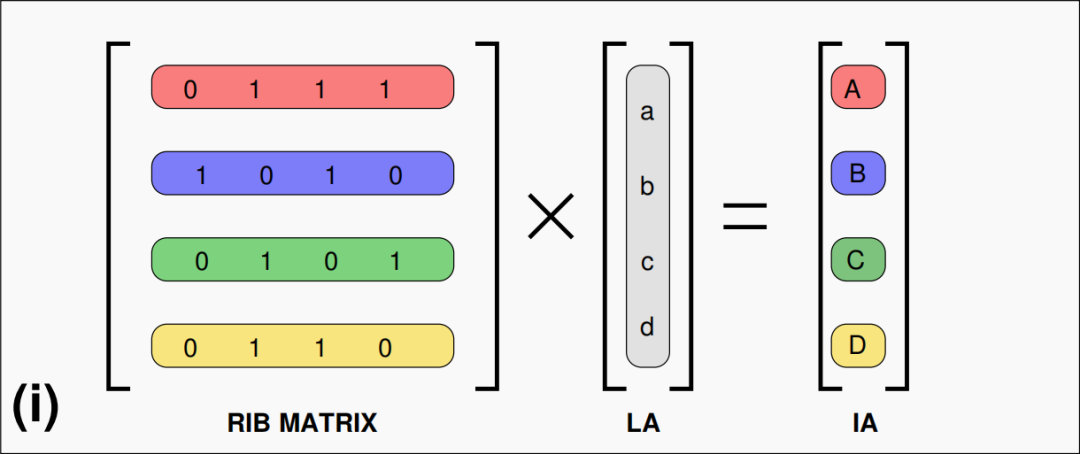
图2:4位地址随机化
综上所述,完整的 Start-Gap 算法框架如图3:
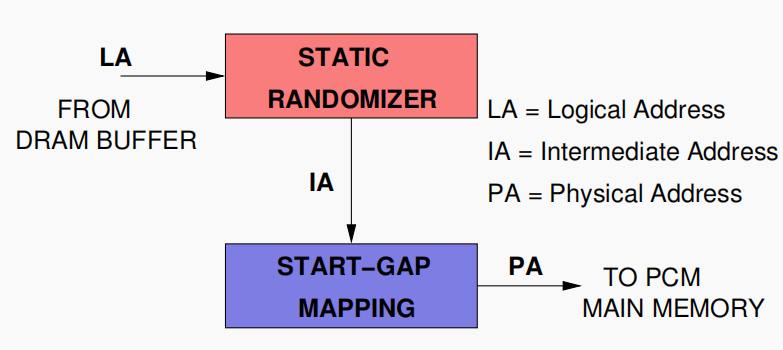
图3:Start-Gap架构
2.基于 RRAM 为主存储器的细颗粒度均衡[3]
与上面介绍的 Start-Gap 算法思路比较相似,Start-Gap 算法是每到一个写入阈值执行一个行的数据迁移,而细颗粒度则是以时间为周期,每一周期将所有的地址均迁移一次,移动间隔为一个随机数,每一周期生成一个新的随机数。所谓细颗粒,意思就是均衡的对象是具体到每一个地址而不是将一些地址集合在一起视为一个整体来做处理。
3. 基于 Flash 的 SW Leveler 算法[4]
考虑 Flash 在更新数据时需要写入另一个地址,将原地址标记为无效(垃圾),需要擦除后才能继续写入。算法设计的目的就是让存储器的各个地址擦除次数分布均匀。
具体为:触发清洁器对选定的区块进行垃圾收集,让 SW 均衡器与块擦除表(BET,建立的目的是记住哪个块在预定的时间范围内被擦除,以便找到冷数据的地址。)相关联,以记住在选定的时间段内哪个块被擦除了。当 SW 均衡器运行时,它要么重置 BET,要么捡起一个至今未被擦除的块(基于BET信息),并触发清洁器对该块进行垃圾收集。区块的选择过程必须在有限的时间内以有效的方式完成。每当一个区块被擦除时,BET 同步更新。
4. 基于 Flash 的 Rejuvenator 算法[1]
Rejuvenator 的基本原则为防止区块更快地达到其使用寿命,并使它们保持年轻,即保持区块写入次数不会很多。只有在 Flash 写入次数达到设定阈值时才会积极地平衡,以此来最大限度地减少搬移冷数据(不经常被访问但是需要长期保存的数据)的开销,可用于大容量 Flash 的扩展。
根据区块当前的擦除次数将其分为不同的组。
Rejuvenator 维护一个列表,将热数据(经常别访问的数据)放在编号较低的区块中,将冷数据放在编号较高的区块中。集群的范围被限制在一个阈值内。这个阈值是根据区块的擦除次数来调整的。
每个区块可以有三种类型的页面:有效页面、无效页面和清洁页面。有效页包含有效的或活的数据。无效页包含不再有效的数据。清洁页不包含任何数据。
当一个写入操作到来时,如果该逻辑地址有一个现有的映射(映射的物理块中的相应页面将是空闲或无效的)。数据将被写入映射的物理块中的相应页面。如果没有与 LBA 相关的块映射,它将被写到属于较高编号列表的一个干净的块中。
此外还有一些已被提出来并且获得了不错效果的动态损耗均衡算法:
1. 基于硬件损耗均衡的 Flash 控制器[5]
将 Flash 中的块分为三类,空闲块,有效块和垃圾块。空闲块指的是尚未被使用,可以直接写入新数据的块。有效块指的是该块中存放着有效数据,该块的地址已存在与地址映射表(记录物理地址和逻辑地址映射关系的表格)中,存放的数据为最新写入的正确的数据。垃圾块指该块中存放的数据已经无效,之前对应该块的地址已经被映射到新的物理地址。
动态损耗均衡主要关注的是保证每次写操作都会写入到Flash中擦除(每次对一个块写入时需要先将原有的数据擦除掉才能写入)次数最小的空闲块中,从而避免某些块被擦写过多。
具体过程为:写操作到来时,在空闲块中找出擦除次数最小的块,将其物理地址与收到的逻辑地址相对应,并存放在地址映射表中,同时将该逻辑地址原来对应的物理地址块标记为垃圾块,最后就将需要写入的数据写入到新的物理地址块中。
2.基于PCM的双重布隆滤波器(DLBF)算法[6]
上面介绍的基于 Flash 算法中提及了空闲块、有效块和垃圾块的概念,与之相近的有冷地址和热地址的概念,顾名思义,热是指该地址被频繁访问,冷地址定义与之相反。
DLBF 算法借用 Bloom Filter(一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。)来识别读、写热页。
将布隆滤波器映射得到的布隆表的每一位扩展为一个计数器就能记录每个地址被写入的次数从而能根据阈值(阈值是会随着时间改变的以此来提高识别的正确率)与计数器记录的数据大小来判断该地址是否为热地址。以此来建立一个候选表(记录现有的冷页),每次写操作到来时,先判断这个地址是否已经存在于地址映射表中,如果不在则先更新布隆表,然后判断该地址是否为需要做交换的热地址,如果是则将它与候选表中的冷地址做交换并更新地址映射表,如果不是热地址则执行正常的写操作即可。
3.基于年龄的PCM损耗均衡算法[7]
算法的核心思想也是令热地址与冷地址交换。但不需要维护一个候选表而是通过一个指针始终指向没有被检测到的所有页面中最前的那个。总的来说就是利用指针的均匀移动使得所有地址都可以被均匀地使用,指针就像一个领队员带领着每一个写入请求命令去到合适的地方。
4.基于PCM的动态损耗均衡算法[8]
同样借助于布隆滤波器,根据 EV(电子伏特)和写入数量来选择要交换的数据。动态管理布隆滤波器来提高所使用的滤波器的有效性(即通过动态更新写数来避免计数器溢出),判断地址是否为热的阈值yes1动态变化的。
采用一种动态的冷热列表(HCL)管理方法,试图在 HCL 中保留尽可能长的热逻辑地址(因此,减少交换开销),同时从列表中删除冷地址。
除此之外相关研究人员还从其他方向提出了实现损耗均衡的方法,例如:用新的缓存替换策略使回写最小化以及避免不必要的写,只写实际改变的位单元[9]。通过在选择替换页时,优先选择一个未被修改过的页面进行替换。尽可能让频繁修改的页面长期保持在缓存中。方案中避免非必要的写操作策略通过分页技术和“读—写—读”存储页差异识别方法实现。
对于上面动态损耗均衡算法中提及的垃圾数据处理,也有人提出了以最小化清理成本的损耗算法——CAT(cost age times)算法[10],将 memory 细分为固定大小的块。每一段有一个 segment header 来描述块信息,该信息被用来加快清洁器加快选择段进行清洁,当所有空闲段的数量低于一定阈值时,清洁器开始工作,在清理时,被清理段中的有效冷数据被迁移至专门存放冷数据的段中。同理有效热数据被迁移至专门存放热数据的段。这样分别聚集,清理这些热数据可以将迁移成本降到最低,因为被复制的有效数据量最少,而回收的垃圾量最大。CAT 算法的基本思想是最小化清理成本,给刚清理过的段更多时间来积累垃圾,以避免无用的迁移。
包括广泛使用的布隆滤波器,关于它也有很多衍生的算法,例如在管理计数器时,因为不同地址会公用一个计数器,那么如果每次都将一个地址对应的所有计数器值都加一,这样会增加将冷地址误判为热地址的概率。为了解决这个问题,除了动态调整判断阈值,还可以令每次只有值最小的计数器加一。
识别冷热地址的方式其实很简单,就把地址被访问的次数记录下来即可,问题就在于我们无法事先得知谁会是热地址,所以在给每个地址分配计数器时预留的空间都必须按照热地址的写入次数赋予,但实际上热地址所占整个地址的比例不会很大,这样就会造成很大的空间资源浪费,而往往我们需要集成密度大的电路这样的存储开销是有些不合理的,所以才产生了各种各样以减少存储开销的算法。
总结
总的来说,损耗均衡算法都是通过各种方式在写入操作会集中在一些地址的情况下通过监督地址的写入情况或者直接在物理地址层面进行额外的数据迁移的方式来使得经常被访问的地址块的损耗分担到那些不怎么经常被访问的块。
均衡损耗算法虽然不能提升存储器实际的寿命,但可以提高存储器实际使用寿命,对于存储器的应用具有很大的意义。
需要提醒的是本文着重于介绍各个算法的设计思路,没有具体提及、分析其功耗,时间、空间复杂度,实际电路所占面积等,而这些在实际的整体系统设计中同样是重要的。诚然我们要实现一些功能总是会以其他功能受到影响为代价,比如加入了均衡损耗模块会使得写操作的延时增加,降低了 CPU 访问存储器的速度但是延长了存储器的寿命,所以还是回到介绍各个算法前说的,最好的算法一定是根据具体应用场景去设计、调整的。
// 参考文献 //
[1] Murugan M, Du D H C. Rejuvenator: A static wear leveling algorithm for NAND flash memory with minimized overhead[C]//2011 IEEE 27th Symposium on Mass Storage Systems and Technologies (MSST). IEEE, 2011: 1-12.
[2] Qureshi M K, Karidis J, Franceschini M, et al. Enhancing lifetime and security of PCM-based main memory with start-gap wear leveling[C]//2009 42nd Annual IEEE/ACM international symposium on microarchitecture (MICRO). IEEE, 2009: 14-23.
[3] Grossi A, Vianello E, Sabry M M, et al. Resistive RAM endurance: Array-level characterization and correction techniques targeting deep learning applications[J]. IEEE Transactions on Electron Devices, 2019, 66(3): 1281-1288.
[4] Chang Y H, Hsieh J W, Kuo T W. Endurance enhancement of flash-memory storage systems: An efficient static wear leveling design[C]//Proceedings of the 44th annual Design Automation Conference. 2007: 212-217.
[5] 徐书韬.基于硬件损耗均衡算法的片上Nor Flash控制器设计[D].杭州:浙江大学,2017.
[6] Niu N, Fu F, Yang B, et al. DLBF: A low overhead wear leveling algorithm for embedded systems with hybrid memory[J].Microelectronics Reliability, 2021, 123: 114154.
[7] Chen C H, Hsiu P C, Kuo T W, et al. Age-based PCM wear leveling with nearly zero search cost[C]//Proceedings of the 49th Annual Design Automation Conference. 2012: 453-458.
[8] Yun J, Lee S, Yoo S. Dynamic wear leveling for phase-change memories with endurance variations[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2014, 23(9): 1604-1615.
[9] Ferreira A P, Zhou M, Bock S, et al. Increasing PCM main memory lifetime[C]//2010 Design, Automation & Test in Europe Conference & Exhibition (DATE 2010). IEEE, 2010: 914-919.
[10] Chiang M L, Chang R C. Cleaning policies in mobile computers using flash memory[J]. Journal of Systems and Software, 1999, 48(3): 213-231.
编辑:黄飞
-
回顾易失性存储器发展史2023-06-28 2878
-
易失性存储器(VM)2022-11-29 5160
-
NAND Flash非易失存储器简介2022-11-10 3123
-
新型非易失存储器硬件损耗均衡算法简介2022-10-13 1488
-
关于易失性存储器SRAM基础知识的介绍2020-12-07 6627
-
非易失性NVSRAM存储器的详细讲解2020-11-25 1759
-
Mbit非易失性静态随机访问存储器nvSRAM系列2018-09-30 1012
-
新型非易失存储MVM数据管理2018-01-02 954
-
赛普拉斯推出非易失性静态随机访问存储器2012-09-13 952
-
赛普拉斯推出串行非易失性静态随机存取存储器2011-04-06 2013
-
非易失性半导体存储器的相变机制2010-01-11 947
全部0条评论

快来发表一下你的评论吧 !
