

基于用于自然语言生成的“语境调优”技术
描述
一、引言
自然语言生成(又称为文本生成)旨在基于输入数据用人类语言生成合理且可读的文本。随着预训练语言模型的发展,GPT-3,BART等模型逐渐成为了生成任务的主流模型。近年来,为了利用预训练阶段编码的丰富知识,提示学习成为了一个简单而强大的方法。
这篇工作主要聚焦于开放式文本生成,例如故事生成和评论生成。在这种场景下,输入仅包含有限的信息,而任务目标是要生成富含信息量且与主题相关的长文本。例如下表中的例子,我们需要写一段关于“live-action”和“animation”的评论,这需要对这两个主题的背景信息有深入的了解。现有的提示学习方法,会在输入前加上人工的离散提示(例如表中的“Write a story about:”),或者在输入前加上可学习的连续型提示。但是这些提示是静态的,更多是包含任务相关的信息,但与输入无关,很难依靠他们去生成富含信息量的文本。

同时在长文本生成中,一个常见的问题是“跑题”,即生成的文本逐渐和主题无关。为了解决以上两个问题,我们分别提出了语境提示(contextualized prompts)和连续反向提示(continuous inverse prompting),来增强生成文本的信息量和相关性。
二、语境调优(Context-Tuning)
本文提出了一种创新的连续提示方法,称语境调优,用于微调预训练模型来进行自然语言生成,我们的核心贡献有三点:①我们首次提出了输入相关的提示——语境提示,抽取预训练模型中的知识作为提示来丰富生成文本的信息量。②我们使用了连续反向提示,最大化基于输出生成输入的概率,来增强生成文本的相关性。③我们使用了一种轻量化的语境调优方法,在只微调0.12%参数的情况下保持98%的性能。
1.语境提示(contextualized prompts)
语境提示是基于输入文本 生成的提示,我们使用BERT作为提示生成器来抽取模型中有关输入的知识,以此达到丰富信息量的目的。 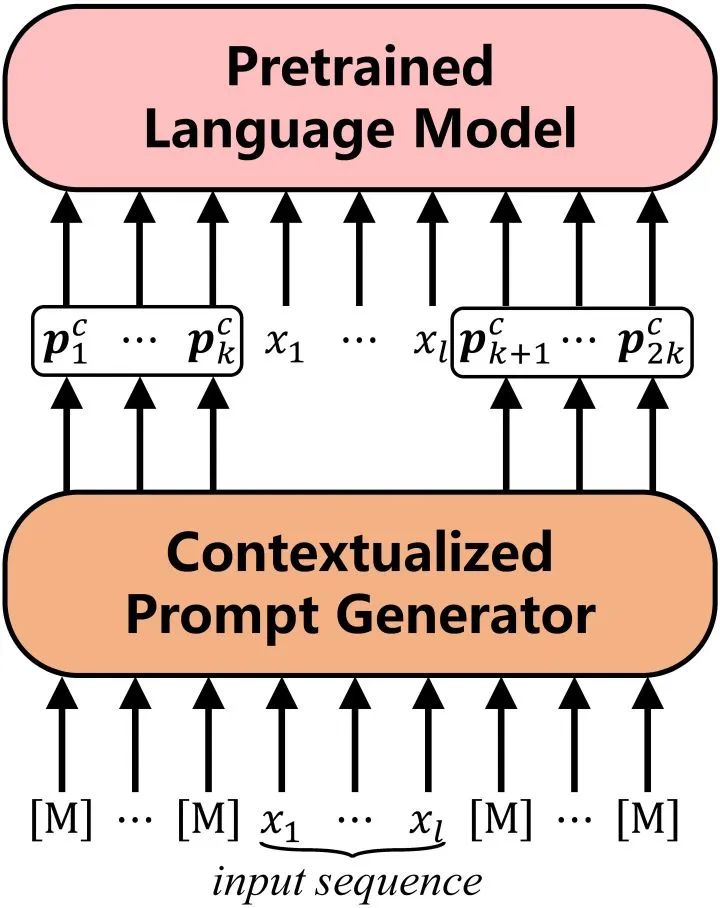 具体的,我们在 两端各放置 个 得到BERT的输入: 经过BERT的编码,我们得到这些 的顶层表示,作为初始提示: 然后我们使用一种“语义对齐”操作,将这些隐提示对应到真实词表空间,得到我们的语境提示 : 其中 是BERT的词表矩阵, 是BERT预测 的映射矩阵。直觉地,我们可以将语义对齐操作看做是预测 的概率分布,然后将相应的词向量加权平均。 最后我们将语境提示加在输入两端,使用BART作为我们的生成模型,建模输入 到输出 的概率: 2.连续反向提示(continuous inverse prompting) 连续反向提示通过建模从输出到输入的反向过程,改进自然语言生成,使生成文本与输入的相关性更强。
具体的,我们在 两端各放置 个 得到BERT的输入: 经过BERT的编码,我们得到这些 的顶层表示,作为初始提示: 然后我们使用一种“语义对齐”操作,将这些隐提示对应到真实词表空间,得到我们的语境提示 : 其中 是BERT的词表矩阵, 是BERT预测 的映射矩阵。直觉地,我们可以将语义对齐操作看做是预测 的概率分布,然后将相应的词向量加权平均。 最后我们将语境提示加在输入两端,使用BART作为我们的生成模型,建模输入 到输出 的概率: 2.连续反向提示(continuous inverse prompting) 连续反向提示通过建模从输出到输入的反向过程,改进自然语言生成,使生成文本与输入的相关性更强。 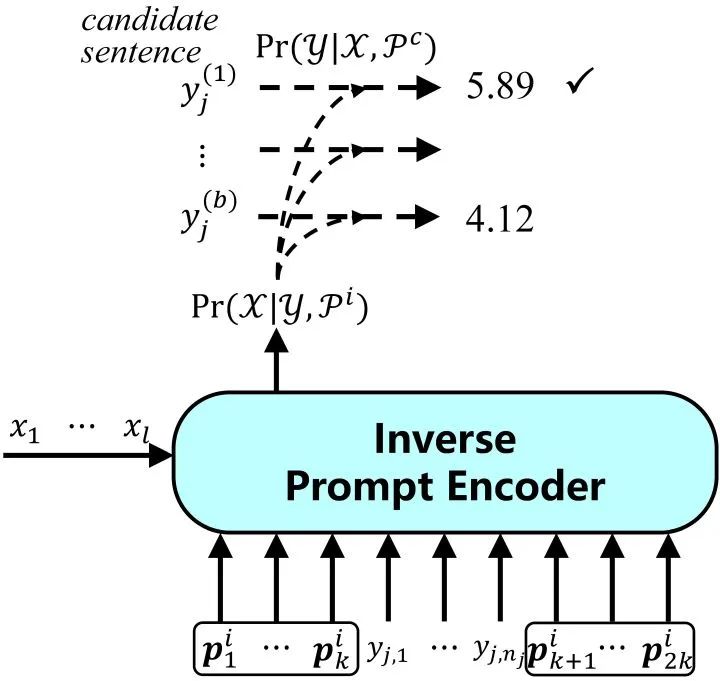 我们有这样一个假设,如果我们可以从输出恢复输入,我们便认为输出与输入相关。但在一些生成场景下,这从输出恢复输入并不自然,因此我们使用连续反向提示来缓解这一现象。我们在输出两端添加连续反向提示 ,并建模输出到输入的概率: 我们期望反向提示可以更好地反映输出到输入的关系,这更多取决于任务本身,因此这里的反向提示是静态的。 最后,我们结合语境提示和连续反向提示,选择联合概率最大的生成文本: 3.轻量化语境调优 考虑到我们的语境提示引入了两个预训练模型,我们使用了一种轻量化微调方法BifFit,即仅微调每个参数的bias项,最终我们仅需要微调全量模型0.12%的参数。因此,我们在实验中考虑了全量微调和轻量化微调两种场景。 三、实验 为了验证语境调优的有效性,我们在四个开放式文本数据集上进行了测试:WritingPrompts,ROCStories,ChangeMyReivew和WikiPlots。 我们考虑了六个基线方法(其中前四个用于全量微调,后两个用于轻量化微调):
我们有这样一个假设,如果我们可以从输出恢复输入,我们便认为输出与输入相关。但在一些生成场景下,这从输出恢复输入并不自然,因此我们使用连续反向提示来缓解这一现象。我们在输出两端添加连续反向提示 ,并建模输出到输入的概率: 我们期望反向提示可以更好地反映输出到输入的关系,这更多取决于任务本身,因此这里的反向提示是静态的。 最后,我们结合语境提示和连续反向提示,选择联合概率最大的生成文本: 3.轻量化语境调优 考虑到我们的语境提示引入了两个预训练模型,我们使用了一种轻量化微调方法BifFit,即仅微调每个参数的bias项,最终我们仅需要微调全量模型0.12%的参数。因此,我们在实验中考虑了全量微调和轻量化微调两种场景。 三、实验 为了验证语境调优的有效性,我们在四个开放式文本数据集上进行了测试:WritingPrompts,ROCStories,ChangeMyReivew和WikiPlots。 我们考虑了六个基线方法(其中前四个用于全量微调,后两个用于轻量化微调):
通用文本生成模型:BART,GPT-2和T5;
专为故事生成设计的方法:HINT;
轻量化方法:Prefix-tuning和Prompt tuning
同时,我们使用BLEU来衡量生成文本的质量,用Distinct来评价生成文本的多样性。 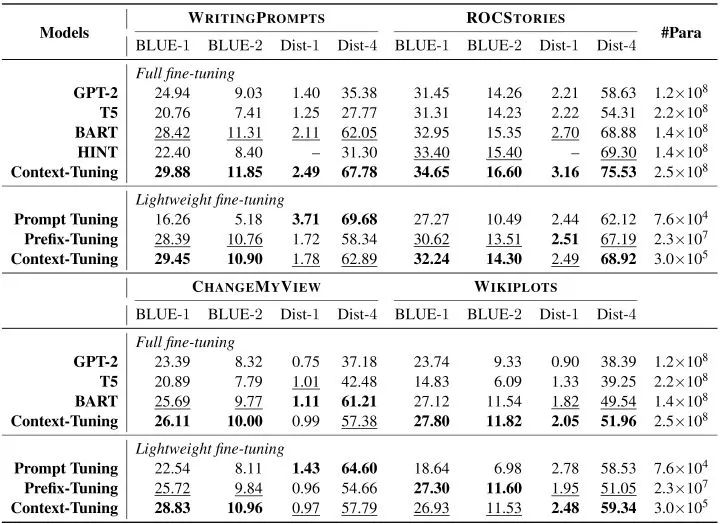 实验结果表明我们在全量微调和轻量化微调两种场景下均优于基线模型,其中轻量化模型在仅微调0.12%参数的情况下可以达到全量微调98%的表现。
实验结果表明我们在全量微调和轻量化微调两种场景下均优于基线模型,其中轻量化模型在仅微调0.12%参数的情况下可以达到全量微调98%的表现。 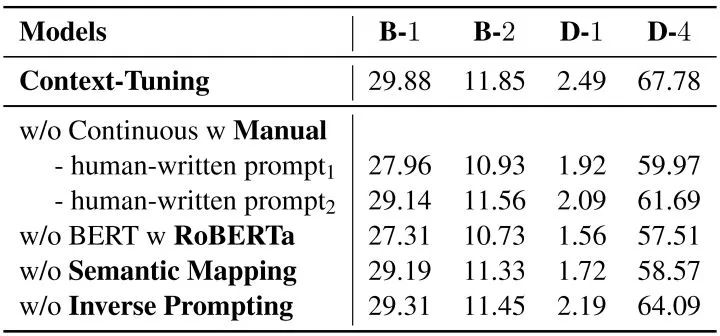 消融实验中,我们尝试替换语境提示、删除语义对齐或反向提示,生成结果均有下降,这验证了我们语境提示和连续反向提示的有效性。
消融实验中,我们尝试替换语境提示、删除语义对齐或反向提示,生成结果均有下降,这验证了我们语境提示和连续反向提示的有效性。 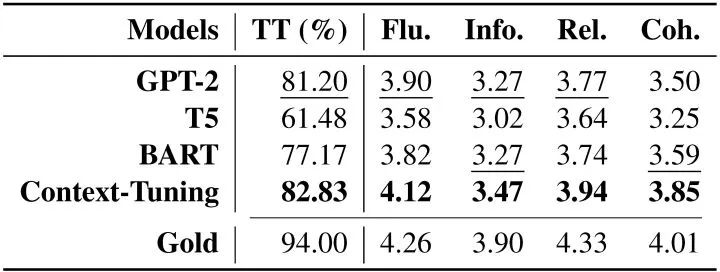 人工评价表明,使用语境调优生成的文本在流畅性、信息量、相关性和一致性上均优于基线模型,且有82.83%的生成文本被认为是人所写的。
人工评价表明,使用语境调优生成的文本在流畅性、信息量、相关性和一致性上均优于基线模型,且有82.83%的生成文本被认为是人所写的。 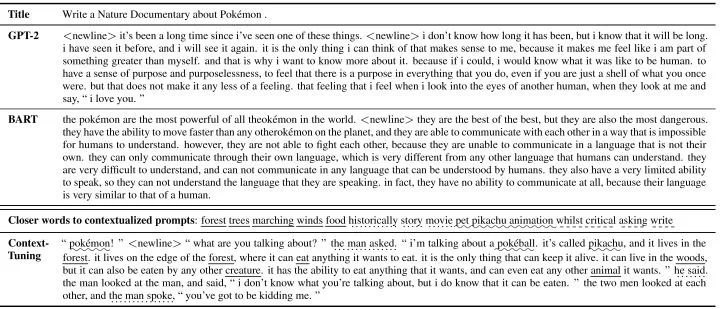 四、总结
四、总结  本文提出了用于自然语言生成的“语境调优”技术:
本文提出了用于自然语言生成的“语境调优”技术:
我们提出“语境提示”,增强生成文本的信息量;
我们使用“连续反向提示”,增强生成文本的相关性;
我们提出轻量化微调语境调优,仅微调0.12%的参数却能保持98%的性能。
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 3012
-
使用LLM进行自然语言处理的优缺点2024-11-08 4517
-
自然语言处理包括哪些内容2024-07-03 3100
-
什么是自然语言处理 (NLP)2024-07-02 4262
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2867
-
自然语言处理包括哪些内容 自然语言处理技术包括哪些2023-08-03 10184
-
什么是自然语言处理2021-09-08 2775
-
自然语言处理的语言模型2020-04-16 2805
-
【推荐体验】腾讯云自然语言处理2019-10-09 2942
-
自然语言处理怎么最快入门?2018-11-28 2732
-
python自然语言2018-05-02 6428
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5694
全部0条评论

快来发表一下你的评论吧 !
