

采用GPU求解大幅提升性能的CFD模型
电子说
描述
你可以设想一下,如果每项任务都能节省几分钟、几小时甚至几天的时间,那一整年下来能节省多少时间啊。如果任务涉及计算流体动力学(CFD)仿真,且希望减少求解时间,那么Ansys Fluent GPU求解器正是您想要的解决方案。
无论是求解10万个单元还是1亿个单元的模型,传统的减少仿真时间的方法都是使用大量CPU进行求解。近年来,另一种方法开始受到行业的关注,那就是使用图形处理单元,简称GPU。这种方法首先是将CPU求解的某些部分交给GPU来处理,从而加速整体求解时间,这种做法被称为“转移”到GPU。
早在2014年,Ansys Fluent就采用了这项“转移”技术,而今年我们则将GPU技术的使用发挥到全新的高度,在Fluent中推出了原生多GPU(multi-GPU)求解器。本地部署方案能提供GPU上的所有求解器特性,避免CPU和GPU之间因交换数据造成的开销,从而相对于转移技术能实现更好的提速。
释放GPU对CFD的全部潜力需要将整个代码运行在GPU上。
在系列博客的上半部分中,我们重点介绍了大型汽车外气动仿真的32倍提速案例,不过并非所有用户的仿真模型能达到如此大的规模。本文作为系列内容的下半部分,将重点介绍GPU针对包含更多物理功能的小规模模型的优势,如多孔介质和共轭传热(CHT)。
各种不同规模的CFD仿真提速
从51.2万个单元到700多万个单元,本文介绍的模型采用GPU求解都能大幅提升性能。而且无需采用最昂贵的服务器级GPU就能大幅提升性能,因为Fluent GPU求解器可以使用您的笔记本或工作站GPU就能显著缩短求解时间。口说无凭,请继续往下看,了解原生多GPU求解器如何实现提速:
进气系统提速8.32倍
牵引逆变器提速8.6倍
两种不同的换热器设计分别提速15.47倍和11倍
通过多孔过滤器的气流
汽车进气系统吸入的气体通过过滤器清除杂物,让清洁空气进入引擎。这个仿真涉及710万个单元,过滤器模型为多孔介质,粘滞阻力为1e+8m-2,惯性阻力为2,500m-1。空气流入进气系统的质量流率为0.08kg/s。
用一个NVIDIA A100 GPU求解后,优化进气系统可实现8.32倍的提速。
我们采用四种不同的硬件配置求解该模型,三种配置采用Intel Xeon Gold 6242核心,一种配置采用一个NVIDIA A100 Tensor Core GPU。
使用单个NVIDIA A100 GPU相对于采用32个Intel Xeon Gold核心求解而言,能提速8.3倍。
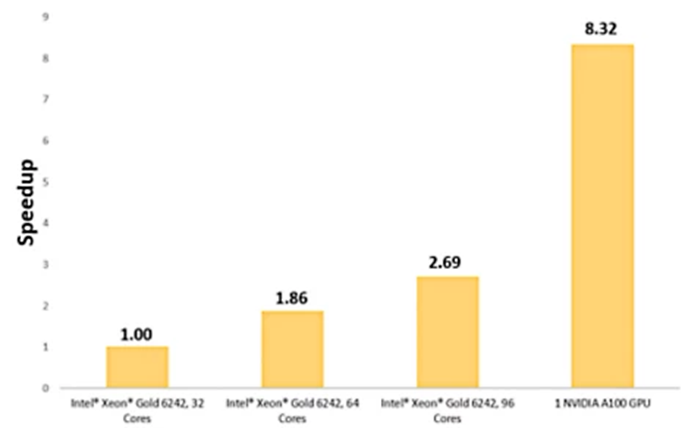
使用单个NVIDIA A100 GPU仿真通过多孔介质的气流相对于32个Intel Xeon Gold核心而言,能实现8.3倍的提速
使用共轭传热建模(CHT)进行热管理
在许多工业应用中,考虑到流体流动时造成的热效应至关重要。为准确捕获系统的热行为,流体的传热与相邻金属的热传导耦合往往非常重要。我们的原生GPU求解器针对这种耦合CHT问题展示出了强大的提速特性。
以下给出三种涉及CHT的不同热仿真,一个为400万个单元的水冷式牵引逆变器,一个为140万个单元的百叶窗翅片换热器,还有一个为512,000个单元的立式散热器。
水冷式牵引逆变器
涉及CHT的牵引逆变器仿真采用一个NVIDIA A100 GPU求解,可实现8.6倍的提速。
牵引逆变器从高压电池获得直流电(DC),并将其转为交流电(AC)发送给电机。热管理对牵引逆变器确保安全性和长期使用寿命至关重要。
以上所示模型为400万个单元的水冷式牵引逆变器,其具有4个绝缘栅双极晶体管(IGBT),热负载为400 W。25℃的水以0.5 kg/s的速度流过外壳实现制冷,并使用对流边界条件对周围空气的热消耗进行建模。
采用一个NVIDIA A100 GPU求解问题,相对于32个Intel Xeon Gold 6242核心而言,可提速8.6倍。
百叶窗翅片换热器
换热器模型通过百叶窗翅片换热器实现强制对流。这个待求解的问题涉及20℃的空气以4 m/s的速度通过铝制百叶窗翅片,以实现铜管制冷。
为获得基准,我们在8个Intel Xeon Gold 6242核心上运行了140万个单元的模型。在一个NVIDIA A100 GPU上运行完全相同的模型,可实现15.5倍的提速。
百叶窗翅片换热器的温度分布在一个NVIDIA A100上求解速度快15.47倍。
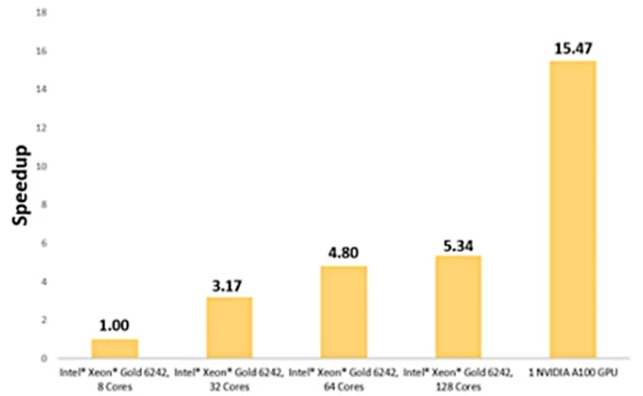
对百叶窗翅片换热器而言,单GPU求解可实现15.47倍的提速
立式散热器
最后一个问题涉及一个自由对流五翅片铝制散热器,基座保持恒温76.85℃,周边空气环境温度为16.85℃。
使用安装有一个NVIDIA Quadro RTX 5000 GPU的一台笔记本电脑求解包含512,000个单元的外壳,相对于采用六核Intel Core i7-11850H的笔记本电脑而言,可实现11倍的提速。
即便只采用一个NVIDIA Quadro RTX 5000笔记本显卡GPU,使用Fluent中的原生多GPU求解器也能大幅缩短求解时间。如果采用类似的工作站图形卡,还能进一步提高性能。
采用一个NVIDIA Quadro RTX 5000 GPU进行求解,512,000个单元的散热器仿真能实现11倍的提速。
通过GPU实现CFD仿真变革
Fluent用户现在能在只有一个GPU的笔记本或工作站上获得强大功能和灵活性,当然也可以扩展至多GPU服务器上。利用您已有的硬件加速CFD仿真,获得的提速超过您的想象。
Fluent中的原生多GPU求解器能运行在2016年之后推出的任何NVIDIA卡上,安装的驱动程序版本不低于11.0或更新版本。
Ansys在GPU技术运用于仿真领域一直是领军者,凭借新型求解器技术,将我们的技术水平提升到新的高度。原生GPU求解器中的所有特性都采用与Fluent CPU求解器相同的离散和数值方法,能在更短的时间内为用户提供他们所期待的准确结果。
审核编辑:刘清
-
FLOEFD:告别低效CFD分析!2025-11-28 1116
-
Altair CFD 以技术赋能工程创新?2026-02-28 1774
-
GPU编程的平台模型、执行模型、内存模型及编程模型2019-04-29 2538
-
怎样去提升高性能示波器的通用性和扩充能力?求解2021-05-07 1158
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2533
-
韩国成功改良NOR芯片 可大幅提升手机性能2010-01-28 1436
-
iPhone7 A10处理器与iPhone6s GPU架构相同 仅最高性能有提升2016-12-05 5698
-
芯片开发商ARM宣布对CPU与GPU的一系列改进,性能大幅提升2018-06-04 4620
-
Intel下一代移动平台采用10nm工艺制造,大幅提升AI性能2020-03-22 2793
-
基于CFD领域的GPU加速设计解决方案2021-03-27 10485
-
选择GPU服务器需要考虑哪些情况如何才能提升GPU存储性能2021-02-08 4252
-
成功案例 I 丰田利用自动 CFD 预处理大幅缩短仿真用时2022-11-21 1820
-
求解大型COMSOL模型需要多少内存?2023-10-29 3903
-
英伟达发布性能大幅提升的新款B200 AI GPU2024-03-20 2247
-
大模型时代,国产GPU面临哪些挑战2024-04-03 6337
全部0条评论

快来发表一下你的评论吧 !
