

NVIDIA 与飞桨团队合作开发基于 ResNet50 的模型示例
描述
你还在头疼于经典模型的复现吗?不知何处可以得到全面可参照的 Benchmark?
为了让飞桨开发者可以快速复现顶尖的精度和超高的性能,NVIDIA 与飞桨团队合作开发了基于 ResNet50 的模型示例,并将持续开发更多的基于 NLP 和 CV 等领域的经典模型,后续陆续发布的模型有 BERT、PP-OCR、PP-YOLO 等,欢迎持续关注。
深度学习模型是什么?
深度学习包括训练和推理两个环节。训练是指通过大数据训练出一个复杂的神经网络模型,即用大量标记过的数据来“训练”相应的系统,使之可以适应特定的功能。推理是指利用训练好的模型,使用新数据推理出各种结论。深度学习模型是在训练工作过程中生成,并将其保存,用于推理当中。
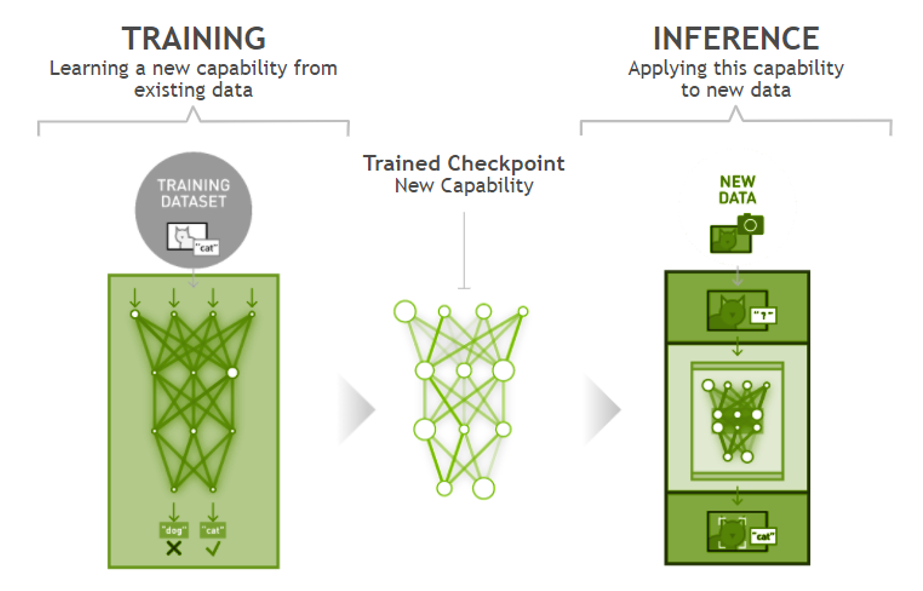
深度学习训练推理示意图
NVIDIA Deep Learning Examples
全新上线飞桨 ResNet50
NVIDIA Deep Learning Examples 仓库上线了基于飞桨实现的 ResNet50 模型的性能优化结果,该示例全面适配各类 NVIDIA GPU 和各种硬件拓扑(单机单卡,单机多卡),极致优化性能。值得一提的是,Deep Learning Examples 中飞桨 ResNet50 模型训练速度已超过对应的 PyTorch 版 ResNet50。
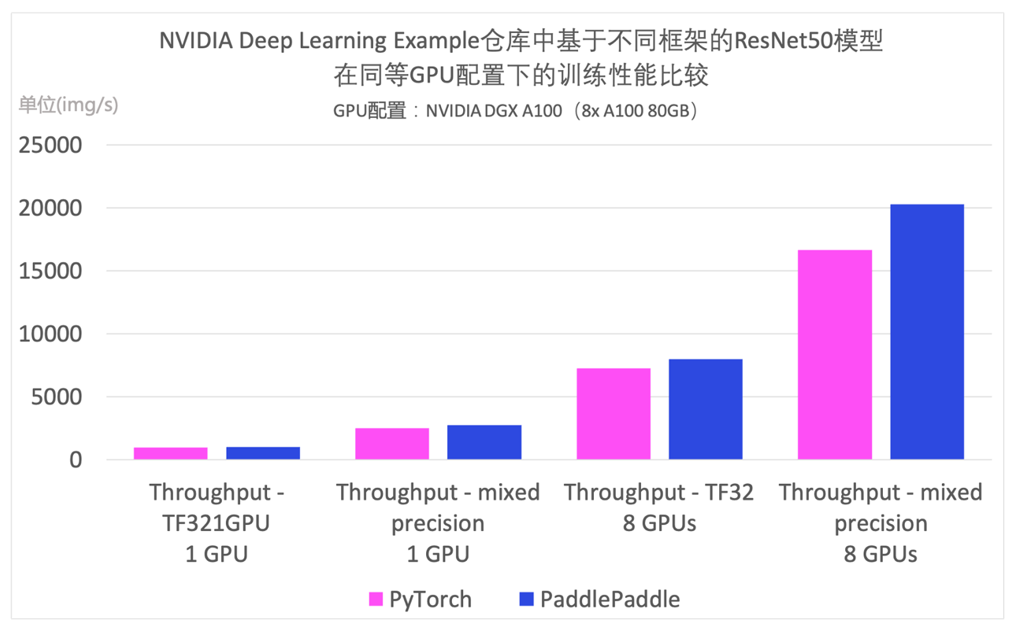
NVIDIA Deep Learning Examples 仓库中基于飞桨与 PyTorch 的 ResNet50 模型在同等 GPU 配置下的训练性能比较,GPU 配置为 NVIDIA DGX A100(8x A100 80GB)。
*数据来源:[1][2]
NVIDIA Deep Learning Examples 仓库中飞桨 ResNet50 有哪些优势?
优势一:通过使用 DALI 等工具,加速 GPU 数据预处理性能
NVIDIA Data Loading Library( DALI )专注于使用 GPU 加速深度学习应用中的数据加载和预处理。深度学习数据预处理涉及到复杂的、多个阶段的处理过程,如 ResNet50 模型训练过程中,在 CPU 上处理图片的加载、解码、裁剪、翻转、缩放和其他数据增强等操作会成为瓶颈,限制训练和推理的性能和可扩展性。DALI 将这些操作转移到 GPU 上,最大限度地提高输入流水线的吞吐量,并且其中数据预取,并行执行和批处理的操作对用户是透明的。
优势二:通过使用 AMP,ASP 等工具,提高推理性能
飞桨内置支持 AMP(自动混合精度)及 ASP(自动稀疏化)模块,AMP 模块可在模型训练过程中,自动为算子选择合适的计算精度(FP32/FP16),充分利用 Tensor Cores 的性能,在不影响模型精度的前提下,大幅加速模型训练。
ASP 模块实现了一个工作流将深度学习模型从稠密修剪为 2:4 的稀疏模式,经过重训练之后,可恢复到与稠密模型相当的精度。稀疏模型可以充分利用 A100 Tensor Core GPU 的加速特性,被修剪的权重矩阵参数存储量减半,并且可以获得理论上 2 倍的计算加速,从而大幅提高推理性能。
优势三:通过集成 TensorRT,优化推理模型
飞桨推理集成了 TensorRT,称为 Paddle-TRT。它可以把部分模型子图交给 TensorRT 加速,而其他部分仍然用飞桨执行,从而达到最佳的推理性能。
优势四:丰富的 Benchmark
NVIDIA Deep Learning Examples 仓库中
有哪些 Benchmark?
NVIDIA Deep Learning Examples 仓库中的 Benchmark 主要包含训练精度结果、训练性能结果、推理性能结果、Paddle-TRT 性能结果几个方面。
1、训练精度结果
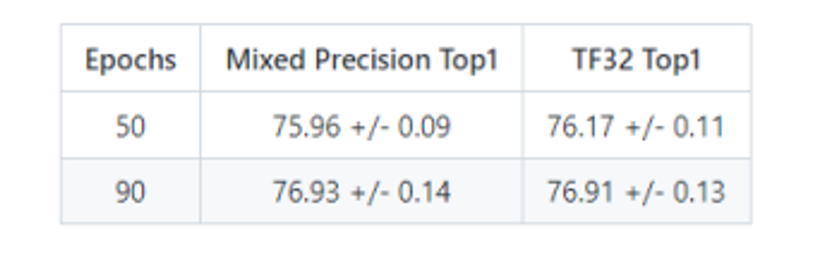
训练精度: NVIDIA DGX A100 (8x A100 80GB)
*数据来源:[1]

集成 ASP 的提高精度: NVIDIA DGX A100 (8x A100 80GB)
*数据来源:[1]
2、训练性能结果

训练性能: NVIDIA DGX A100 (8x A100 80GB)
*数据来源:[1]

集成 ASP 的训练性能: NVIDIA DGX A100 (8x A100 80GB)
*数据来源:[1]
3、推理性能结果
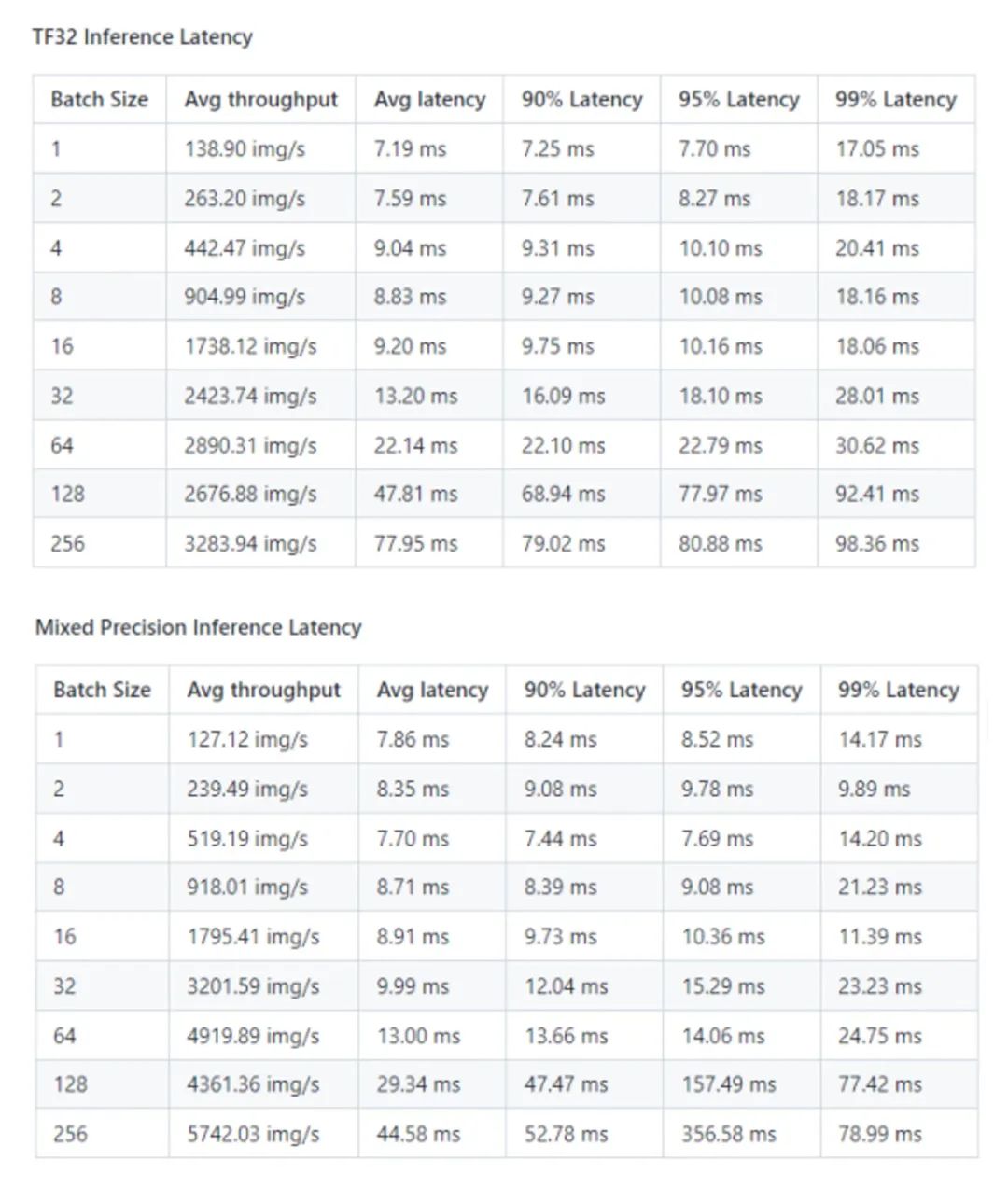
推理性能: NVIDIA DGX A100 (1x A100 80GB)
*数据来源:[1]
4、Paddle-TRT 性能结果
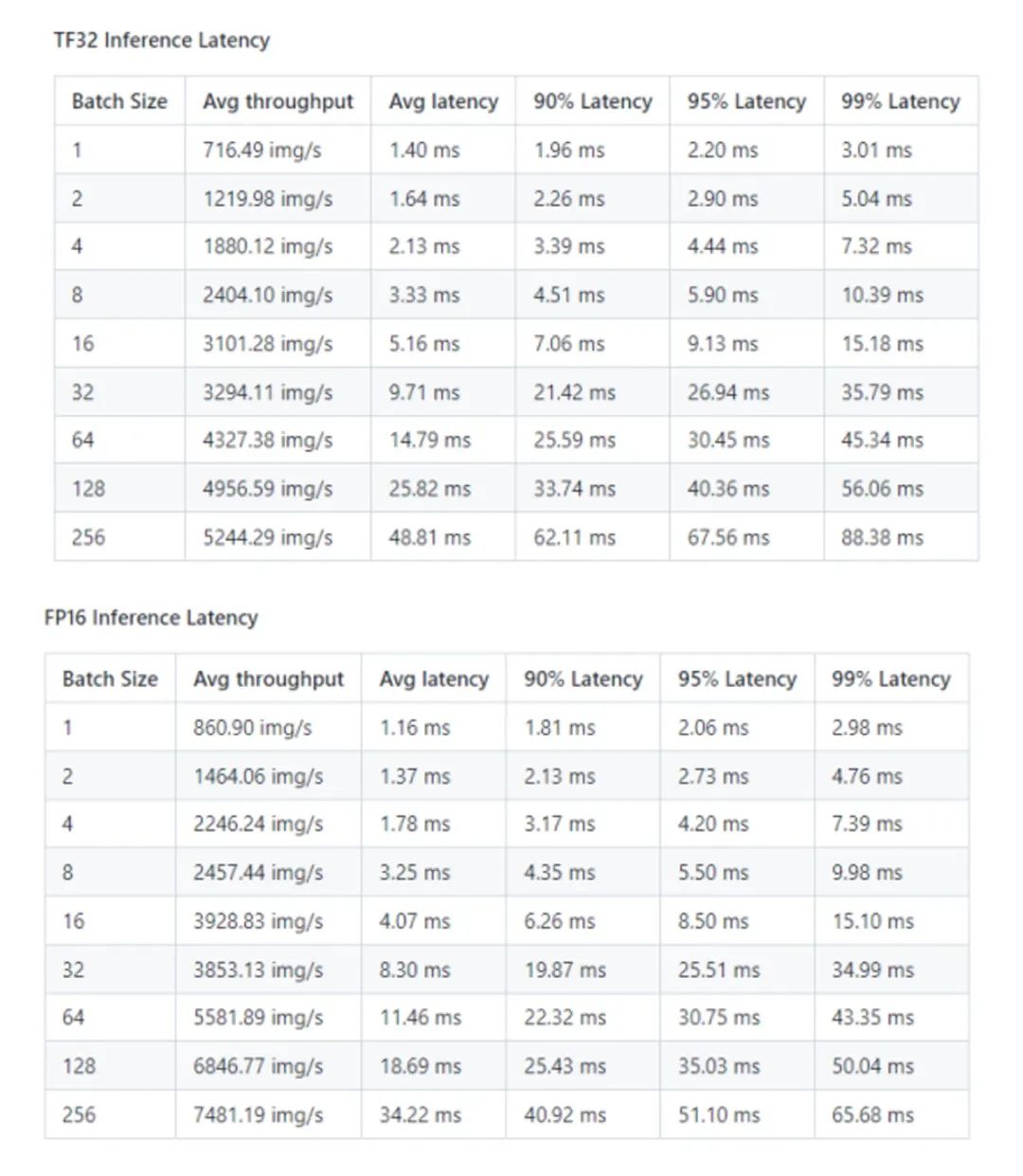
Paddle-TRT 性能结果: NVIDIA DGX A100 (1x A100 80GB)
*数据来源:[1]
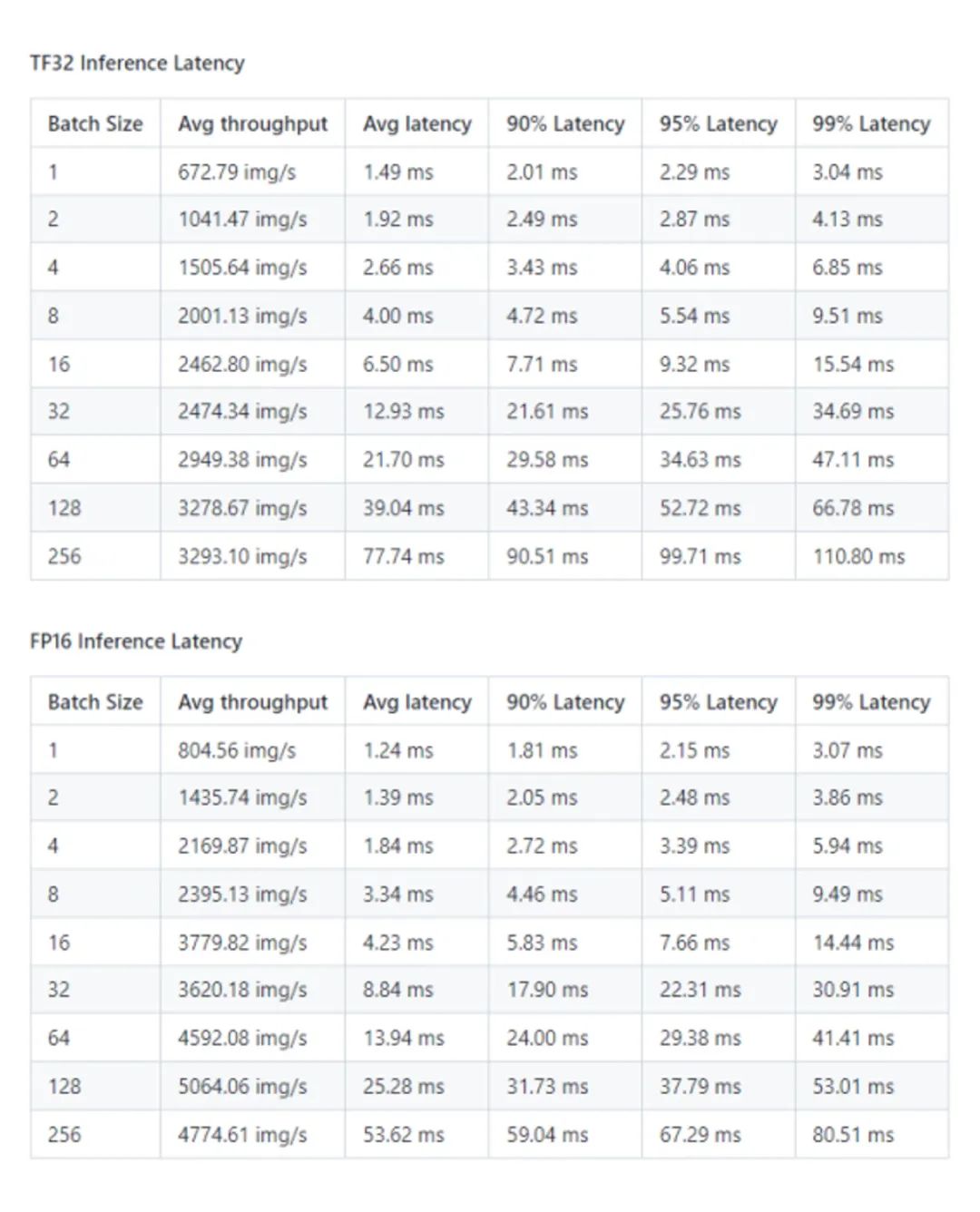
Paddle-TRT 性能结果: NVIDIA A30 (1x A30 24GB)
*数据来源:[1]
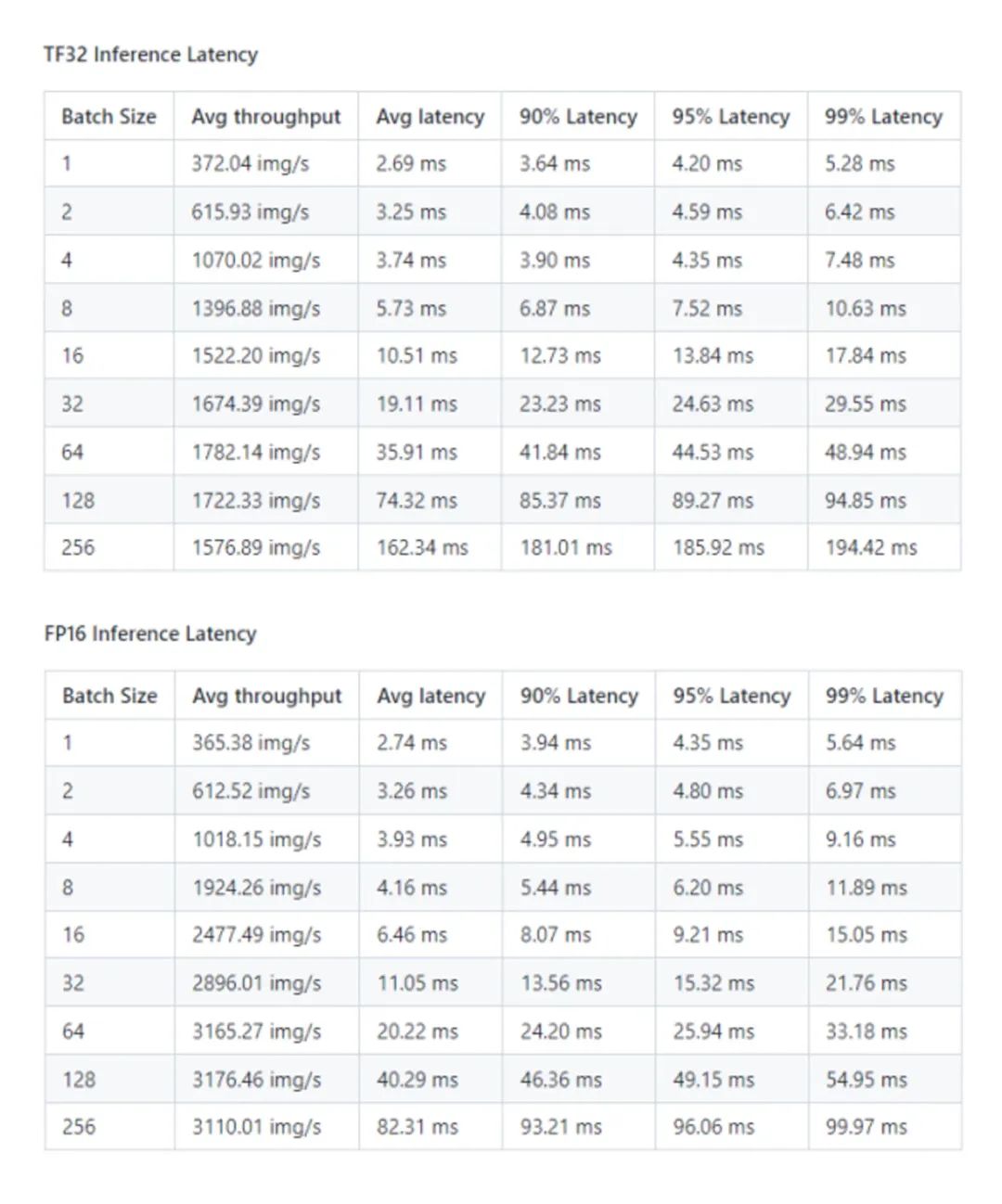
Paddle-TRT 性能结果: NVIDIA A10 (1x A10 24GB)
*数据来源:[1]
如何下载 NVIDIA Deep Learning Examples 中的飞桨 ResNet50?
登录 GitHub NVIDIA Deep Learning Examples 仓库, 找到 PaddlePaddle/Classification/RN50/1.5,下载模型源代码即可。
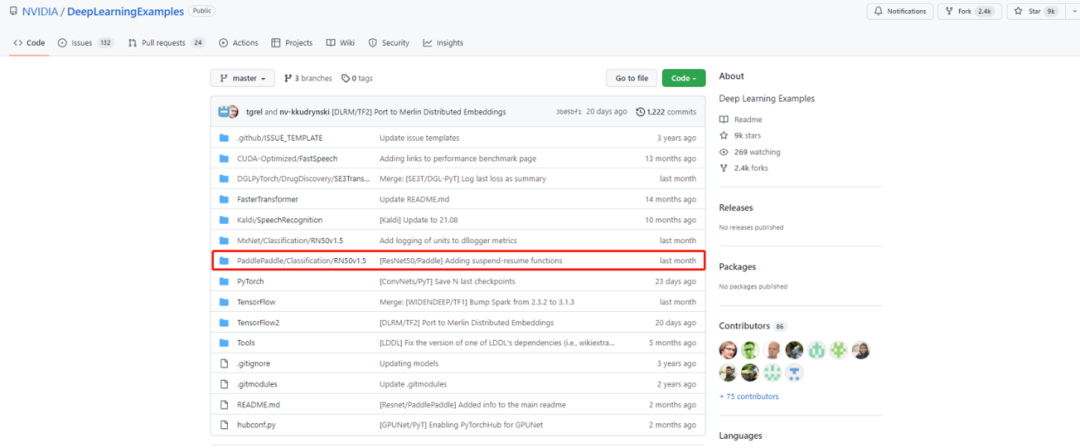
NVIDIA Deep Learning Examples 飞桨 ResNet50 下载页面
飞桨容器如何安装?
容器包含了深度学习框架在运行时所需的所有部件(包括驱动,工具包等),它具有轻量化与可复制性、打包和执行环境合二为一以及简化应用程序部署等优势,因此,被认为是在同一环境中实现“构建、测试、部署”的最佳平台。容器允许我们创建标准化可复制的轻量级开发环境,摆脱来自 Hypervisor 所带来运行开销。应用程序可以基于 Container Runtime 运行在“任意”系统中。
NVIDIA 与百度飞桨联合开发了 NGC 飞桨容器,将最新版本的飞桨与最新的 NVIDIA 的软件栈进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
NGC 飞桨容器已经集成入飞桨官网主页。你可以选择 “飞桨版本”+“Linux”+“Docker”+“CUDA 11.7”找到对应的 Container 下载指令。
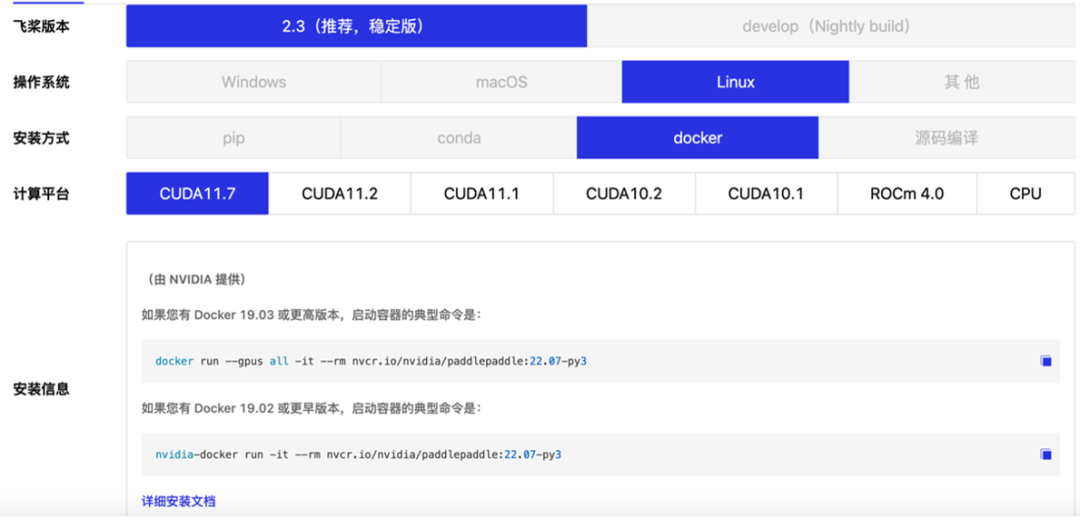
并参考《NGC 飞桨容器安装指南》下载安装:https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
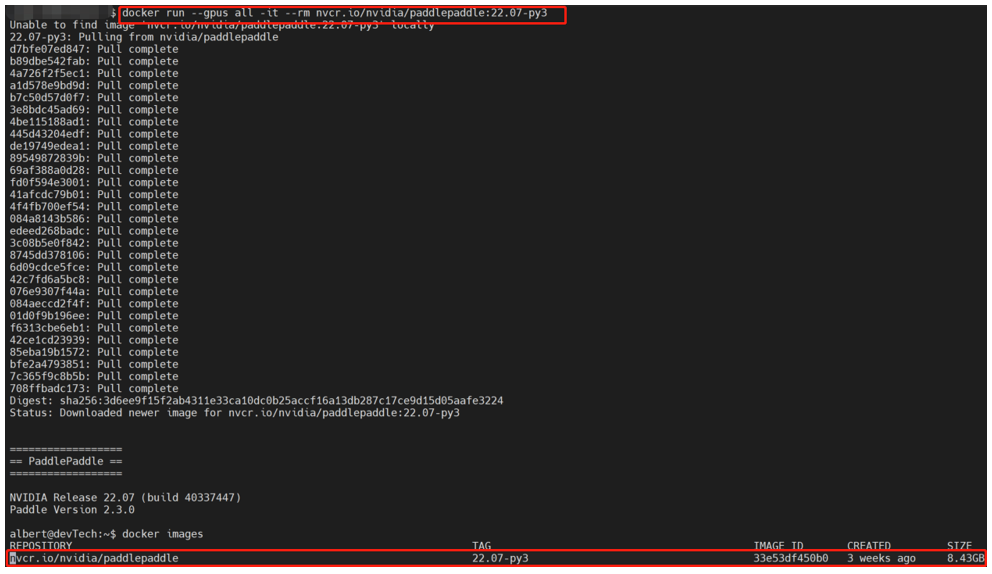
运行结果如下:
-
诚邀项目合作开发2015-12-14 5104
-
【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序2023-09-10 3832
-
【KV260视觉入门套件试用体验】四、学习过程梳理&DPU镜像&Resnet502023-09-26 1224
-
【KV260视觉入门套件试用体验】KV260系列之Petalinux镜像+Resnet 50探索2023-10-16 11902
-
【R329开发板评测】实机测试Resnet502022-01-25 652
-
NVIDIA携手百度飞桨 共创多元AI开发生态2022-05-27 3173
-
NVIDIA与飞桨共同深度适配的NGC飞桨容器在NVIDIA GPU上体验2022-11-01 2811
-
MLPerf世界纪录技术分享:优化卷积合并算法提升Resnet50推理性能2022-11-10 3077
-
“NVIDIA”拍了拍“飞桨”说11月30日深圳见2022-11-16 1247
-
2022 飞桨 X NVIDIA AI 技术开放日将于明日举行!缤纷好礼等你来拿2022-11-23 1261
-
基于改进ResNet50网络的自动驾驶场景天气识别算法2024-11-09 1987
-
基于RV1126开发板的resnet50训练部署教程2025-04-18 1390
-
基于瑞芯微RK3576的resnet50训练部署教程2025-09-10 1592
-
瑞芯微(EASY EAI)RV1126B resnet50训练部署教程2026-05-08 6185
全部0条评论

快来发表一下你的评论吧 !
