

会议系统设计组成及功能
描述
01. 设计概述 1.1 设计目的
随着疫情的出现,线上会议的应用越来越广泛,相关的技术也越来越成熟,但当前的线上会议系统大都基于电脑和手机,便于个人使用,但由于其摄像头拍摄方向固定,当会议一端有多人参与时,就需要每人都单独开一个窗口才能有较好的效果,较为不便。基于此,我们设计了一个新的会议系统,以更好地适应多人会议的需求。
本系统以 Xilinx PYNQ-Z2 FPGA 为控制核心,将声源定位与图像识别相结 合。通过对环境声音的实时检测,实现对声源目标的定位,并基于特征提取和模式匹配的方法对目标进行图像识别,根据提前训练的数据模型,在显示屏上框出 目标并显示目标的个人信息。同时,也可以通过 socket 通信将识别后的图像信息 直接发送至客户端(PC 机等)显示,从而实现远程会议的效果。
1.2 应用领域
本系统理念较为新颖,将声源定位与图像识别相结合,并在 FPGA 上实现, 使得系统整体体积与功耗都较小,可以在各种线上会议中使用,在疫情防控常态 化的当下,应用前景十分广泛。例如,该系统可以用于在企业之间进行的大型会 议,声源定位功能可以使摄像头实时跟踪讲话人,并对其进行识别,显示人员信 息,这就使得只使用一个客户端就可以较好地实现多人会议,节省资源;另外, 该系统在多方参与的学术会议或国际会议中也都比较适用。
1.3 主要技术特点
(1)采用四麦克风阵列采集声音信息,并通过硬件电路将麦克风阵列输出 PDM 信号直接转换为 I2S 信号送入 FPGA 中处理。 (2)使用 python 编写的 TDOA 算法进行声源定位,即先通过 GCC-PHAT 算法 得出不同麦克风芯片接收到声音的时延,再通过几何关系计算出声源所在的角度。 (3)采用 Haar 特征提取算法检测人脸区域,速度快,识别率较高;采用 LBPH 特征识别算法对数据集中的图片进行训练,训练完成后,建立标签与真实人员姓 名的直接映射表,从而实现身份识别。 (4)基于 socket 通信,使用 UDP 通信协议,将图像从 FPGA 中实时传输到客户 端 (PC 机等)中显示,从而实现远程会议的功能。 1.4 关键性能指标
(1)声源定位速度与准确率 本系统在环境噪声较小的情况下可在 1 秒之内完成声源定位,准确率几乎为 100%;在环境噪声较大的情况下定位时间会稍长,在 2 秒左右也基本可以完成 定位,准确度在 90%以上。 (2)人脸检测与身份识别速度与准确率 本系统人脸检测速度较快,当人脸进入摄像头中部区域后就可立即框出 人脸,在摄像头中部区域人脸检测准确率几乎为 100%;身份识别速度较人脸检 测稍慢,但识别时间都在 0.5s 左右,当人员处于拍摄区域中部时识别准确率较 高,在 90%以上,当人员处于拍摄区域边缘时准确度较低,但也基本都在 80%以 上。 (3)数据无线传输速率与延时 本系统无线数据传输时,客户端(PC)接收到图像信息的延时在 1s 左右,延时 较低;其传输速率也较快,显示的图像基本都在 3 帧/秒以上。 1.5 主要创新点
(1)采用了数字麦克风芯片,抗干扰能力较强,且在使用时外围电路简单;使 用四芯片麦克风阵列采集声音信号,使得其在 360°平面内对声源方向角度的分 辨率大大提高。 (2)采用 AC108 芯片将 PDM 信号转换为 I2S 信号,再送入 FPGA 中处理。 (3)采用 TDOA 算法,并在高速、并行的 FPGA 中实现,使得声源定位的速度 较快,延迟较低。 (4)使用舵机搭建了水平 360°云台,使摄像头可以更方便地跟踪声源。 (5)系统支持现场录入人员并学习,且识别率较高。 (6)基于 socket 通信,实现将图像信息从 FPGA 中实时传输到客户端(PC 机等) 显示的功能。 (7)该会议系统功耗低、体积小、易安装并且可供多人在同一客户端使用。
02. 系统组成及功能部分
2.1 整体介绍
本系统由麦克风阵列模块、FPGA 处理器模块、摄像头模块、远程数据传输 模块和显示模块共同组成。麦克风阵列模块在检测声音信号后,将转换后的 PCM 码送入 FPGA 处理器模块处理,实现对声源目标的定位;摄像头模块在接收到 FPGA 处理器模块发出的位置信号后,控制摄像头转向声源方向,并将摄像头拍 摄到的图像信息传入 FPGA 处理器模块进行处理,识别其是否为检测目标,若为 检测目标则显示检测到的人员信息;若没有检测到相关目标,则重新进行声源定 位。图 2.1 为系统整体框图。
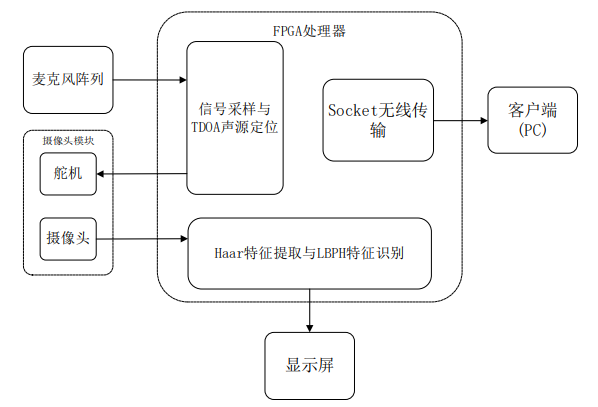
▲图2.1系统整体框图
2.2 各模块介绍
2.2.1 麦克风阵列模块
系统采用由 KNOWLES 公司制造的性能优良的 MEMS 数字麦克风芯片 SPU0414HR5H,可识别频率在 100Hz~10kHz 范围内的声音信号。选用四芯片麦 克风阵列采集声音信号,输出四路 PDM 信号到 AC108 芯片中进行解调,输出 PCM 信号送入 FPGA 中进行处理。其实物图如下图所示:

▲图2.2.1麦克风阵列
2.2.2 FPGA 处理器模块
处理器模块主要采用 Xilinx PYNQ-Z2 开发板,其由 650MHz 双核 Coryex-A9 处理器与 FPGA 组成。PYNQ-Z2 开发板支持 Python 语言开发,也支持使用传统 的 Xilinx Vivado 开发工具流程平台开发编写 Verilog 来开发嵌入式系统应用。同 时,PYNQ-Z2 开发板也具有极其丰富的外设接口,如千兆以太网口、USB 接口、 UART 接口、HDMI 输出/输出接口等常用接口,还提供了兼容 Ardunio、RPi、 Pmod 的扩展接口。
声源定位算法和图像识别的算法均在处理器模块中实现。
(1)TDOA 声源定位算法
TDOA 定位算法是一种利用时间差进行定位的方法,通过测量信号到达的时 间,可以确定信号源的距离,利用信号源到各个信号接受点的距离,就能确定信 号的位置。采用 GCC-PHAT 算法,先对输入 FPGA 中的 PCM 信号通过 I2S 协议 采样,得到四路数字信号,以两个信号为一组,采用广义互相关的方法求出时延, 即求两路信号的互频谱,得出其频谱峰值索引,即为声音到这两路信号采集点的 时延。得到时延后,根据几何关系,即可求出声源与两对角信号采集点连线的角 度,进而得到摄像头需要旋转的角度信息。
(2)Haar 特征提取算法
系统使用 Haar 特征提取的识别算法进行人脸检测。Haar 特征提取过程是将 一副图像中所有黑色矩形框和白色矩形框中所包含的全部像素进行差值运算,得到该图像的 Haar 特征值,但由于一副图像中包含的 Haar 特征的个数较多,对于其中矩形特征的特征值的提取相对比较复杂,因此采用积分图像的转换来缩减其计算量,以提高运算速度。
在提取出 Haar 特征后,将其分别转化为弱分类器,然后根据弱分类器处理样本数据,根据其正确分类样本的情况来改变其权值大小,进而产生多个强分类器,然后将这些训练产生的强分类器继续迭代,最终获得一个识别率较高的最终强分类器,从而实现对人脸区域的准确识别。
(3)LBPH 特征识别算法
系统采用了基于 LBP(局部二值模式)特征的 Adaboost(级联分类器)进行人脸 识别。LBP 是典型的二值描述算子,其更多的是整数计算,可以通过各种逻辑操 作对运算过程进行优化,因此效率较高。此外,通常光照对图像中物体的影响是 全局的,即图像中物体的明暗程度通常是往同一个方向改变的,只是改变的幅度 会因距离光源的远近而有所不同,故图像中局部相邻的像素间受光照影响后的相 对大小不会改变,LBP 特征也因此对光照具有比较好的鲁棒性。Adaboost 是一种 迭代算法,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些弱 分类器集合起来,构成一个更强的最终分类器。Adaboost 算法系统具有较高的 检测速率,且不易出现过适应现象。
2.2.3 摄像头模块
采用 GUCEE 摄像头,1200 万像素,动态分辨率支持 1920*1080,其机身小 巧,易于安装,适合在各种环境下使用。同时,系统搭建了一个摄像头云台,使 用一个舵机来控制云台上摄像头的转向,使其能在水平 360°范围内跟踪声源方位。
2.2.4 远程数据传输模块
系统基于 socket 通信,编写 python 创建 UDP 服务端程序,在同一局域网下 可以将图像信息直接从 FPGA 中发送到任一客户端(PC 机等)中,客户端只需打 开使用 python 编写好的上位机程序,即可接收到信息并同步显示。其无线传输延迟较小,传输速度较快且输出图像较为清晰。2.2.5 显示模块 采用 Creatblock7 寸 iPS 高清显示屏,使用 FPGA 中的显示模块将识别后的 图像直接显示在显示屏上。
03.
完成情况及性能参数
3.1 声源定位
系统可较好实现 360°声源定位,在环境噪声较小的情况下,识别很精准, 误差不超过 5°,在有一定噪声干扰的情况下,其识别度也能稳定在一定水平, 识别误差不超过 15%。下表为声源定位测试结果:
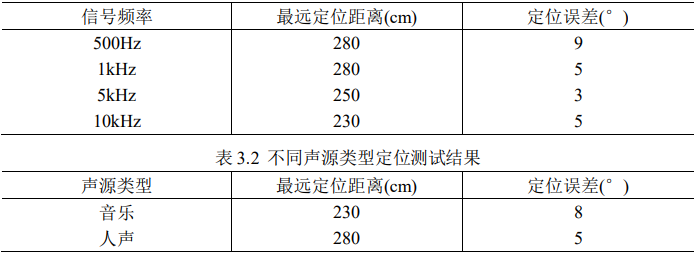
▲表3.1 单频声源定位测试结果
3.2 身份识别与显示
系统能够很好地实现人脸检测与身份识别功能,且运算速度较快,在识别到 人脸后能够迅速框出人脸,并将其人脸特征与数据库中录入特征进行匹配,若匹 配到相应的人脸信息则直接在方框上方显示当前人员信息,若未匹配到相应人脸 信息,则只框出人脸。人脸检测识别率很高,识别速度较快;身份识别速度较快, 在单人识别时成功率较高,达到 90%以上,当同时有多人在识别范围内时识别准 确度会受到影响,但也基本在 80%以上。识别后的图像可以清晰地在显示屏上显 示,并且显示延迟较小。下图为人脸检测与身份识别显示画面:

3.3 无线数据传输
系统通过 socket 通信,可以将图像信息直接通过局域网传输到客户端中,这 里使用 PC 机作为客户端,在运行上位机程序后即可接收到从 FPGA 中实时传输的图像。通过 FPGA 上的拨码开关可以控制传输图像的模式,即实时显示模式和 身份识别模式。下图为 PC 机接收到的图像:

04.
完成情况及性能参数
4.1 可扩展之处
(1)当前系统声源定位在特定位置处定位误差会略大,同时,在环境噪音较大 的情况下,也会对声源定位造成一定影响。可通过增加麦克风数量,改变麦克风阵列结构或改进声源定位算法等进一步提高系统声源定位的精度与抗干扰性。
(2)拓展图像处理功能,将摄像头拍到的图像降噪,并根据图像的具体情况自 动将图像的亮度和对比度等特性调节到合适的值。
(3)当前系统无线数据传输功能只能将FPGA拍摄到的图像数据发送到和FPGA 连接在同一局域网内的客户端中,可以进一步完善无线传输功能,使得 FPGA可以直接将图像数据发送到外网的客户端中,增加系统的实用性。
(4)优化图像处理算法,进一步提高人脸识别算法的准确度与鲁棒性。
-
无线数字会议系统的设计理念与功能2024-01-24 2139
-
【转】数字会议系统功能之解析2020-05-20 1572
-
多功能会议系统的解决方案2018-09-21 2163
-
多功能电话会议系统与视频会议设计方案参考2017-09-10 5059
-
什么牌子的视频会议系统好?2016-04-26 3933
-
视频会议系统稳定性更重要2013-02-21 2375
-
视频会议系统原理2012-08-20 6437
-
WIFI技术在会议系统中的应用2012-04-09 4753
-
技术浅析:启拓会议系统五步选择2012-03-14 2958
-
视频会议系统,视频会议系统是什么意思2010-03-24 3704
-
完整视频会议系统的组成部分有哪些?2010-02-21 7579
全部0条评论

快来发表一下你的评论吧 !
