

基于BlockNeRF的大场景规模化神经视图合成
描述
作者:Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, Henrik Kretzschmar
我们提出了 Block-NeRF,一种神经辐射场的变体,可以表示大规模的场景。具体来说,我们发现,当使用 NeRF 渲染跨越多个街区的城市规模场景时,将场景分解为单独训练的子 NeRF 至关重要。这种分解将渲染时间与场景大小分离,使渲染能够扩展到任意大的场景,并允许对环境进行逐块更新。我们采用了几项架构更改,以使 NeRF 对在不同环境条件下数月捕获的数据具有鲁棒性。我们为每个单独的 NeRF 添加了外观嵌入、可学习的位姿细化和可控曝光,并引入了校准相邻 NeRF 之间外观的程序,以便它们可以无缝组合。我们从 280 万张图像中构建了一个 Block-NeRF 网格,以创建迄今为止最大的神经场景表示,能够渲染旧金山的整个社区。
主要贡献
为了在大场景中应用神经辐射场(NeRF)模型,文章提出将大型场景分解为相互重叠的子场景 (block),每一个子场景分别训练,在推理时动态结合相邻 Block-NeRF 的渲染视图。 文章在 mip-NeRF 的基础上增加了外观嵌入、曝光嵌入和位姿细化,以解决训练数据横跨数月而导致的环境变化和位姿误差。 为了保证相邻 Block-NeRF 的无缝合成,文章提出了在推理时迭代优化这些 Block-NeRF 的输入外观嵌入以校准它们的渲染结果。
方法概述
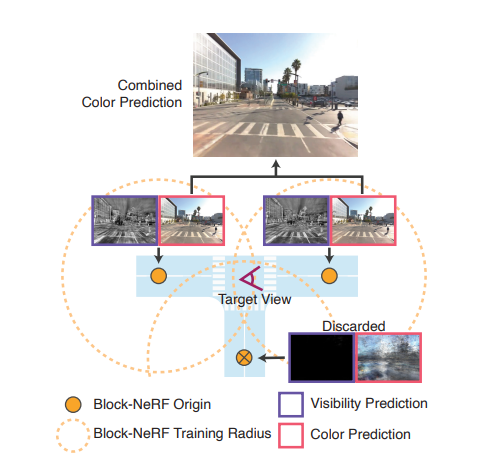
神经辐射场 (NeRF)是使用神经网络拟合辐射场,用于视图渲染的方法。然而,传统的 NeRF 很难被直接扩展到大场景应用。这是因为拟合大场景所需的神经网络也会很大,这会导致训练和推理渲染变得很困难。本文提出将大的场景划分为数个相互重合的小场景 (block)。如下图所示的丁字路口被划分为三个小场景(黄圈),针对每一个小场景单独训练一个 Block-NeRF。推理时合并覆盖目标视图范围的 Block-NeRF 渲染生成最终的视图。
mip-NeRF 拓展文章基于 mip-NeRF,但是由于训练视图在长达数月的时间内采集,不可避免地出现场景光照不同、相机曝光不同、视图位姿存在误差等问题。为了解决这些问题,文章在 mip-NeRF 的基础上增加了外观嵌入和曝光作为神经网络的输入(如下图所示,其中 fσ 和 fc 分别为预测密度 σ 和颜色 RGB 的神经网络,x 为场景中的三维坐标点,d 表示视角)。
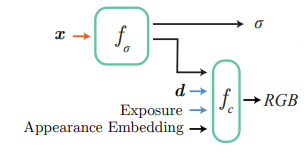
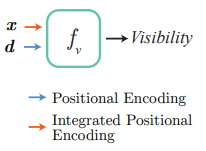
训练时使用生成式潜码优化的方法学习外观嵌入,消除天气光照等原因的影响。曝光则直接可以读取采集记录,只需对其进行正弦位置编码即可。 与此同时,训练视图的采集跨越了多个驾驶段,这些驾驶轨迹之间不可避免地存在位姿误差。Block-NeRF 训练时还同时优化每一个驾驶段的位姿偏移以降低位姿误差带来的影响。 街道视图中存在汽车、行人等瞬时物体,然而场景渲染通常只关注建筑、街道等静态结构。文章于是使用语义分割网络对训练视图中的动态物体进行掩蔽,这样神经辐射场就不会学习这些动态物体,而是只关注静态场景结构。 有时目标视图的相邻 Block-NeRF 可能距离上很近,但并不在目标视图的视野之内,文章在传统 NeRF 的两个神经网络 fσ 和 fc 之外,还增加了一个预测能见度的网络 fv。给定三维坐标 x 和视角 d , fv 预测该点在给定视角下的能见度。合成多个 Block-NeRF 的渲染时,能见度低于阈值的渲染不会被用于最终的合成。训练时能见度可以由相应点的透光率作为监督目标。
Block-NeRF 融合为提高渲染效率,渲染目标视图时文章仅融合: 中心点在阈值半径内 且平均能见值高于阈值的 Block-NeRFs 满足这两个条件的 Block-NeRFs 以反距离加权的方式融合渲染视图。这里的距离选择相机到 Block-NeRFs 的二维空间距离。这样的融合方法既保证了渲染真实度又能够满足时空一致性。 为了保证不同视角下渲染的天气、光线等外观的一致性,文章还在推理时引入了外观嵌入迭代优化。给定一个 Block-NeRF 的外观嵌入,文章在锁定神经网络权重不变的基础上,优化相邻 Block-NeRFs 的外观嵌入,最大化其渲染视图的一致性。
实验结果
文章采集并开源了两个数据集:San Francisco Alamo Square Dataset 和 San Francisco Mission Bay Dataset,分布包含280万和1.2万图片。Alamo Square Dataset覆盖大约 0.5km2 ,采集自3个月周期内,包括不同光线条件和天气的数据。Mission Bay Dataset 涵盖的地理范围远远小于 Alamo Square Dataset,主要被用来与 NeRF做比较。 Table 2 显示 Block-NeRF 相较于NeRF 渲染效果更好。并且 block 数量越多越好。即便是保持神经网络总参数量不变,Block-NeRF 仍然优于 NeRF 并且推理速度在不考虑并行计算的前提下也大大提高。
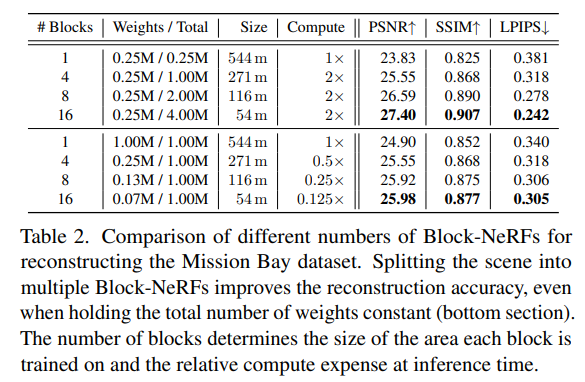
Table 1 和 Figure 7 分别定量和定性地显示外观嵌入、曝光输入以及位姿优化都对提高渲染效果有帮助。
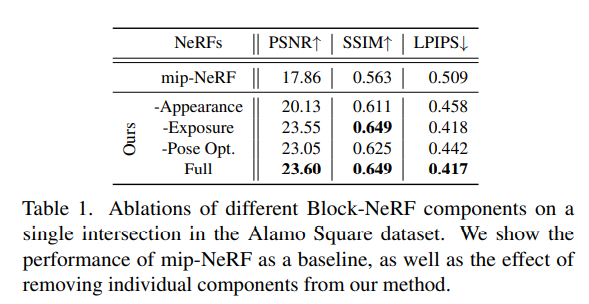

Figure 6 显示推理时外观嵌入优化可以将渲染从白天场景转换成黑夜场景,从而更好地与基准 Block-NeRF 匹配,增强渲染地时空一致性。

总结
本文提出了Block-NeRF,采用 divide-and-conquer 的方法使用多个 Block-NeRFs 学习大型场景的不同分块,最终将这些Block-NeRFs 的渲染合成目标视图。这样的方法使得利用 NeRF 模型渲染城市规模的场景成为了可能。 此外 Block-NeRF 还在 mip-NeRF 的基础上,引入了外观嵌入优化、曝光输入和位姿细化等扩展,以解决训练数据横跨数月而导致的环境变化和位姿误差。
审核编辑:郭婷
- 相关推荐
- 热点推荐
- 神经网络
-
OpenWay与Visa合作,助力银行快速且规模化推出新支付产品2026-06-09 271
-
NVIDIA Vera Rubin正全面迈向规模化量产2026-06-05 1221
-
精彩演讲·不容错过 | 智能规模化:平台驱动,赋能半导体全生态AI分析规模化落地2026-03-26 549
-
2026研运一体化趋势:CICD平台如何适配信创与规模化研发场景?2026-03-24 410
-
2025 RISC-V产业发展大会 | 赛昉科技全景展示规模化商用成果2025-11-27 1645
-
飞腾CPU在济南机场实现规模化应用2025-07-10 1075
-
Block nerf:可缩放的大型场景神经视图合成2022-10-19 2561
-
后摩智能与新石器无人车合作加速无人配送车的规模化应用2022-09-02 1791
-
机器人为何难以实现规模化场景落地2022-07-07 3078
-
无线射频识别技术在规模化奶牛场中有哪些应用?2021-05-20 1778
-
华为鸿蒙有望下月规模化推送_流畅度和动画效果大有提升2021-05-07 3377
-
阿里携手物联网合作伙伴成立ICA,推动IoT产业规模化2018-05-04 6603
-
何勉:第一性原理和精益敏捷的规模化实施2018-01-26 4274
-
规模化FTTH建设下的ODN质量探讨2011-12-12 1609
全部0条评论

快来发表一下你的评论吧 !
