
资料下载


Agouti智能防风雨的声学监测设备
石胜厚
分享资料个
描述
动机与背景
传统的基于视觉的野生动物监测方法受到天气条件、相机的视野、目标生物的大小及其接近程度的限制。可以通过其他渠道更可靠地监测野生动物的替代技术有很大的空间:如声学监测。
声学监测为监测野生动物提供了一种可靠、低成本且可扩展的替代方案,并具有检测有害人类活动的额外好处:虽然偷猎和伐木可能无法看到,但它们更容易听到。
当然,声学监测并不是一个新概念。但是,大多数产品只记录;他们不分析。这会产生大量原始数据,超出研究人员单独分析的人力。目前,保护组织经常求助于大型科技公司来处理他们的原始数据。这不仅使保护主义者处于被动状态,将重点放在历史数据上,而且还为小规模的地方保护工作构成了重大障碍。此外,这也阻碍了声学监测系统充当警报的潜力。
Agouti:我们的产品
鉴于这些考虑,Agouti 是一款智能、防风雨的声学监测设备,可以轻松部署用于音频数据的记录和分析。
我们使用 edgeML 来自动标记关键事件类的麦克风数据,例如昆虫声音和鸟鸣、人类活动(例如车辆)和日志记录(例如电锯噪音),并将这些标签与其各自的音频一起存储以供人工检查。我们还记录温度、湿度和光传感器的读数,以将音频与现实世界联系起来,准确量化环境如何影响物种的行为。
Agouti 广泛涉及“挑战 2:野生动物/生物多样性保护”。具体来说,我们同时解决两个问题:
- 对濒临灭绝的野生动物进行非侵入式监控:我们的声学记录系统会定期对其周围的音景进行 5 秒的录音,然后对其进行分析并与音频一起存储。
- 人类与野生动物冲突预防/缓解:通过检查音频中的可疑活动声音(如伐木或运输噪音),我们可以检测对环境有害的非法活动。
简而言之,刺豚鼠
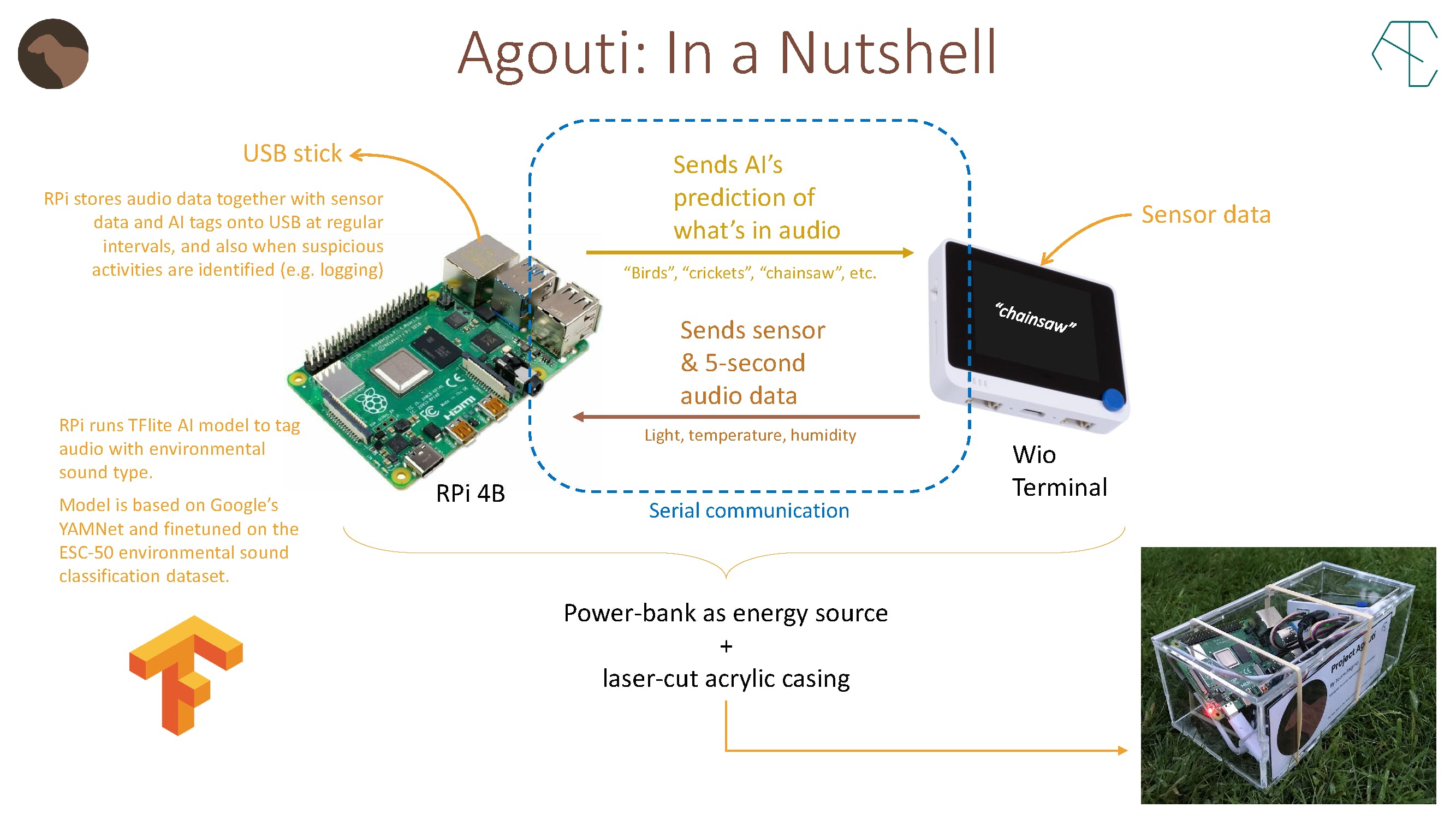
因此,如上所示,Agouti 使用 Wio 终端来收集数据和显示预测,而 Raspberry Pi 用于处理和存储数据。我们决定使用 Raspberry Pi 有两个原因
1. 我们尝试的一些更简单的模型根本无法以合理的准确度进行音频分析。所以我们不得不使用一个太大而无法在 Wio 上运行或运行的 AI 模型,但又足够小以适应 RPi。
2. RPi 可以写入容量远大于 Wio 16GB SD 卡槽的 USB 存储设备。
现在,让我们来看看我们是如何创建 Agouti 的。此处引用的所有代码和其他支持文件都可以在我们的GitHub存储库中访问,其中包含设置我们系统每个部分的详细说明。
第 1 部分:人工智能训练
这是最难的一点。我们尝试了许多各种规模的模型架构,最终我们坚持的方法是迁移学习。与训练新模型相反,迁移学习显着减少了所需的训练时间和资源。通过利用预训练模型的高级模型架构,它还可以提高准确性。
对于我们的训练,我们使用了谷歌的预训练模型YAMNet 。YAMNet 分析输入音频数据的 Mel Spectrogram,这是一个根据人类听觉对不同频率的敏感度有偏差的频谱图。它是一个主要由卷积层组成的模型,在 Google 的 AudioSet 数据集上进行训练,并输出对应于 521 个预定义类中的每一个的分数数组。
然后我们选择了另一个数据集ESC-50 ,它主要包含环境噪声,因此更适合我们的目的。这里的音频数据为 5s 16khz。YAMNet 从音频生成嵌入,我们在这些嵌入上训练最终分类器。因为 YAMNet 将音频数据切成 0.96 秒的帧,所以我们 5 秒的记录产生了一个嵌入数组。为了解决这个问题,我们采用了一个 128 单元的 LSTM 模型,该模型对这个数据数组进行循环操作。
为了进一步提高我们模型的鲁棒性,我们添加了音频增强:时间轴的拉伸/压缩、频率调制、随机噪声的混合、谐波失真等。这不可避免地会降低训练时的准确性,但会在训练中获得更好的性能应用。
为了使模型的最终预测更加直观,我们还创建了模型混合内容的混淆矩阵。如下所示:
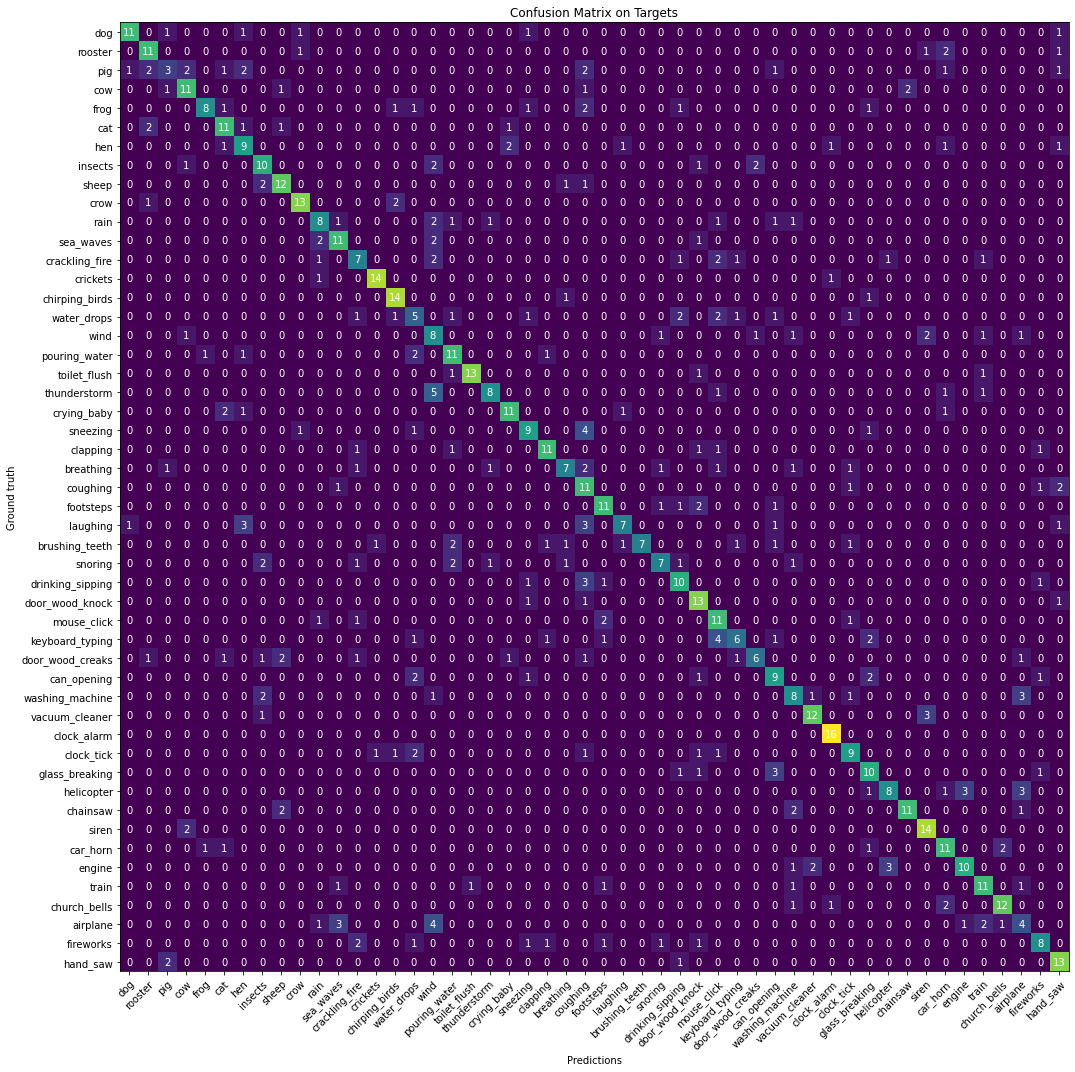
一旦最终的分类器层被训练出来,我们就对其进行量化并将其转化为可以在 Pi 上轻松运行的 TFlite 模型。
您可以在此处使用我们在 Google Colab 上的实际实现。
以下是人工智能分析 YouTube 音频的一些片段:
第 2 部分:Wio + RPi 串行
我们非常感谢 Seeed Studios 为我们提供免费的 SenseCAP K1100 传感器原型套件。我们使用 Wio 终端从其内置的光传感器和 microhpone 以及附加的 Grove SHT40 温度和湿度传感器中获取读数。
您会记得,Wio 终端负责所有传感器数据并通过其麦克风记录音频,而 Raspberry Pi 运行大型 AI 声学模型(太大而无法安装在 Wio 上)并使数据能够存储到 USB具有大存储空间的驱动器。两者之间的通信是通过串口实现的:
- Raspberry Pi 在启动时向 Wio 发送命令
- Wio 抓取传感器数据并记录 16k 帧音频数据,然后将其发送回 Pi。然后 Pi 做了一些事情:
- Pi 测量 Wio 获取音频数据所需的时间,自动校准每帧之间的延迟,以便 Wio 每秒准确返回 16000 帧。
- Pi 将原始音频数据转换为介于 -1 和 1 之间的 numpy 数组,然后将其传递给 YAMNet 以提取 YAMNet 预测和嵌入
- 然后将 YAMNet 嵌入通过我们的自定义模型传递以提取更高级别的音频信息
- 来自 YAMNet 和我们的自定义模型的预测结合起来给出最终的音频标签
- 如果自上次存储音频以来已经过去了足够长的时间,或者如果音频被标记为危险,则 Pi 将音频数据及其预测标签(作为 JSON)一起写入 USB
- Pi 将预测的音频标签和校准的延迟时间发送回 Wio
- Wio 显示预测的音频标签,再次记录音频数据(这次使用新的延迟值),然后循环继续
同样,我们的 GitHub 存储库中提供了设置RPi和 Wio 的完整说明。
第 3 部分:外壳
为了保护硬件免受外部环境的破坏,我们在 Onshape 上设计了一个防水外壳,使用 3mm 透明亚克力板,使用激光切割机成型。
我们决定使用亚克力板,因为它们耐用且重量轻,并且具有易于激光切割的额外好处。外壳也是完全透明的,以确保屏幕可见。此外,外壳设计中包含一个小窗口,用于将温度和湿度传感器(位于外部)连接到 Wio(位于内部)。保护壳的所有底座部分均采用指接设计,具有很强的稳定性和强度,并最大限度地提高了用于连接和形成整个盒子的丙烯酸水泥的粘合性。
而且……我们做到了!

最终产品
这是一段 Agouti 在行动中的视频,它用背景中的飞机检测人类噪音:
下面是链接到音频文件的 JSON 文件的示例:
{
"category": "chainsaw", # Final audio tag
"class": "sawing", # Big class that tag falls into
"humidity": 51.6, # Humidity value
"light": 170, # Light sensor value
"original": "chainsaw", # Prediction from our model
"temperature": 20.09, # Temperature value
"yamnet": [ # YAMNet prediction at each frame
"Engine",
"Breathing",
"Vehicle",
"Vehicle",
"Vehicle",
"Vehicle",
"Frying (food)",
"Breathing",
"Rattle",
"Engine"
]
}
并且...所有音频文件都已正确存储到 USB 上:
未来的改进
未来,我们设想进行以下更改以改进 Agouti:
- 支持通过 LoRaWan 发送分析的音频标签和传感器数据,因此可以立即刷新数据和警告(我们确实有准备好通过 Lora 将传感器数据发送到 Helium 的代码,但连接存在问题,可能与 Lora 覆盖有关)
- 太阳能电池板可实现更长时间的连续运行
- 使移植的 ML 模型更准确,并且能够识别更多的音频类
- 使用更好的麦克风并以更高的速率采样
学分
感谢我来自 Team Enigma 的其他 3 位队友,他们参与了这个项目的开发:
Dylan Kainth主要用于处理硬件的 Wio 方面,建议使用 Pi 以及许多其他事情
Alex Yi主要用于帮助人工智能,研究不同的算法,并提出不同的音频增强
Mark Zeng设计了机箱并对 Edge Impulse 进行了一些研究
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





