

一种新的单目视觉里程计深度学习系统
描述
摘要
大家好,今天为大家带来的文章:Deep Patch Visual Odometry 我们提出了一种新的单目视觉里程计深度学习系统(Deep Patch Visual Odometry, DPVO)。DPVO在一个RTX-3090 GPU上仅使用4GB内存,以2 -5倍的实时速度运行时是准确和健壮的。我们在标准基准上进行评估,并在准确性和速度上超越所有之前的工作(经典的或学习过的)。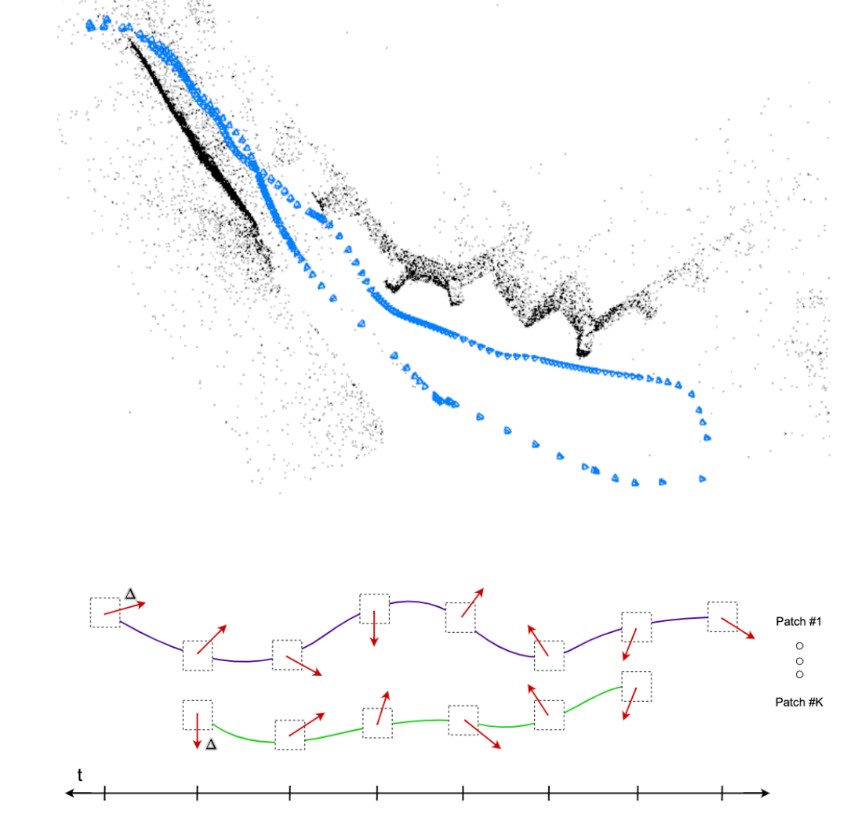
图1 深度斑块视觉里程计(DPVO)。相机姿态和稀疏三维重建(上)是通过迭代修正补丁轨迹随着时间
主要工作与贡献
与之前的深度学习系统相比,我们的方法的新颖之处在于在单一体系结构中紧密集成了三个关键成分:(1)基于补丁关联,(2)循环迭代更新,(3)可微束调整。基于补丁的关联提高了密集流的效率和鲁棒性。循环迭代更新和可区分的bundle调整允许端到端学习可靠的特征匹配。 DPVO准确、高效、实现简单。
在显卡(RTX-3090)上,它只需要4GB内存就能运行2倍实时。我们还提供了一个在EuRoC数据集[2]上以100fps运行的模型,同时仍然优于之前的工作。对于每一帧,运行时间是恒定的,不依赖于相机运动的程度。该系统的实现非常简单,代码量非常少。无需对底层VO实现或逻辑进行任何必要的更改,就可以轻松地交换新的网络架构。我们希望DPVO可以作为未来深度VO和SLAM系统发展的试验台。
算法流程
我们的网络是在线训练和评估的。一个接一个地添加新的帧,并在关键帧的局部窗口中进行优化。我们的方法有两个主要模块:patch提取器(3.1)和更新模块(3.2)。补丁提取器从传入帧中提取稀疏的图像补丁集合。更新模块试图通过使用循环神经网络跟踪这些补丁与包调整交替迭代更新。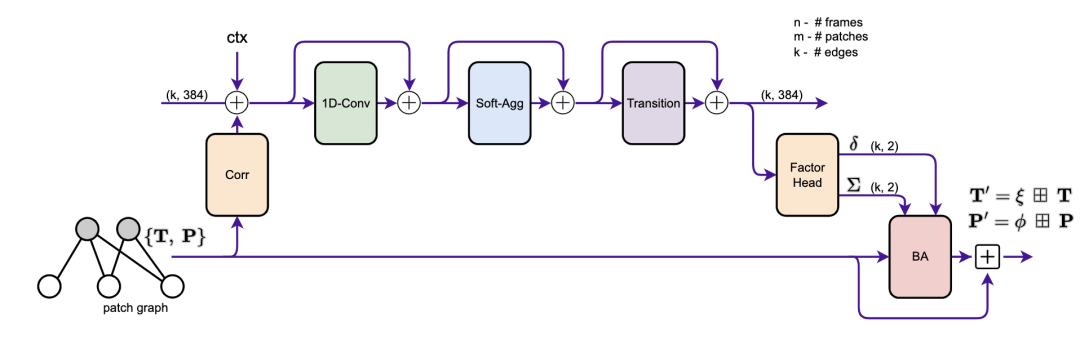
图2 更新操作符的原理图。从补丁图的边缘提取相关特征,并与上下文特征一起注入到隐藏状态中。我们应用了卷积、消息传递和转换块。因子头产生轨迹修正,由束调整层用于更新相机姿势和补丁深度。
2. 方法
我们介绍了DPVO,一种新的基于补丁的深度VO系统,它克服了这些限制。我们方法的核心部分是深度补丁表示(图1)。我们使用神经网络从传入帧中提取补丁集合。然后使用循环神经网络跟踪每个补丁通过时间交替补丁轨迹更新与可微束调整层。我们在合成数据上对整个系统进行端到端训练,但在真实视频上表现出很强的泛化能力。
2.1 特征和补丁提取
我们使用一对残差网络从输入图像中提取特征。一个网络提取匹配特征,另一个网络提取上下文特征。每个网络的第一层是一个跨步2的7 × 7卷积,后面是两个1/2分辨率的剩余块(维64)和两个1/4分辨率的剩余块(维128),这样最终的特征映射是输入分辨率的1/4。匹配网络和上下文网络的结构是相同的,除了匹配网络使用实例规格化,而上下文网络不使用规格化。
我们用一个四乘四步滤波器对匹配特征进行平均池化,构建了一个两级特征金字塔。我们为每一帧存储匹配的特征。此外,我们还从匹配和上下文特征映射中提取补丁。在随机抽取斑块质心的基础上,采用双线性插值方法进行特征提取。 与DROID-SLAM不同的是,我们从未显式地构建相关卷。相反,我们同时存储帧和补丁特征映射,这样相关特征就可以实时计算
2.2 更新操作
更新操作符的目的是更新姿势和补丁。这是通过修改patch轨迹来实现的,如图1所示。我们在图2中提供了操作符的概览示意图,并详细介绍了下面的各个组件。图中的每个“+”操作都是一个残留连接,然后是层归一化。更新操作符作用于补丁图,补丁图中的每条边都用一个隐藏状态(维度为384)进行扩充。当添加一条新边时,隐藏状态初始化为0。
2.2.1 关联操作
对于补丁图中的每条边(i, j),我们计算相关特征。我们首先使用Eqn. 2对帧j中的patch i进行重投影:xij = ωij(T, P)。给定patch特征g∈Rp×p×D,帧特征f∈RH×W ×D,对于patch i中的每个像素(u, v),我们计算其与帧j中像素(u, v)重投影为中心的像素网格的相关性,使用内积: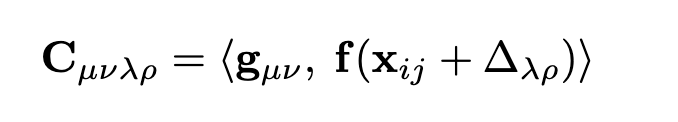
2.2.2 可微的束调整
图2中的这一层在补丁图上全局运行,并输出深度和相机姿势的更新。预测因子(δ, Σ)用于定义优化目标 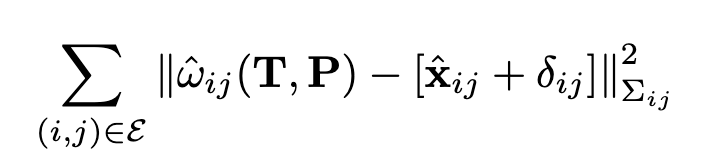
2.2 训练与监督
DPVO是使用PyTorch实现的。我们用TartanAir数据集训练我们的网络。在每个训练序列上,我们使用地面真值姿态和深度来预计算所有帧对之间的光流大小。在训练过程中,我们对帧对帧光流大小在16px到72px之间的轨迹进行采样。这确保了训练实例通常是困难的,但不是不可能的。 我们对姿态和光流(即轨迹更新)进行监督,监督更新操作符的每个中间输出,并在每次更新之前从梯度带中分离姿态和补丁。
2.2.2 pose监督
我们使用Umeyama对齐算法[30]缩放预测轨迹以匹配地面真相。然后对每一对姿态(i, j)进行误差监督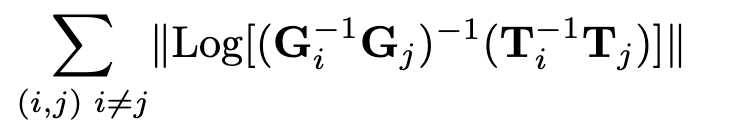
2.2.3 Flow监督
此外,我们还监测了每个补丁和帧之间的诱导光流和地真光流之间的距离,从每个补丁被提取的帧的两个时间戳。每个补丁诱导一个p×p流场。我们取所有p × p误差中的最小值。
2.2.4训练
我们训练长度为15的序列。前8帧用于初始化,后7帧每次添加一帧。我们在训练期间展开更新操作符的18次迭代。对于前1k的训练步骤,我们用地面真相固定姿势,只要求网络估计补丁的深度。然后,该网络被要求估计姿势和深度。 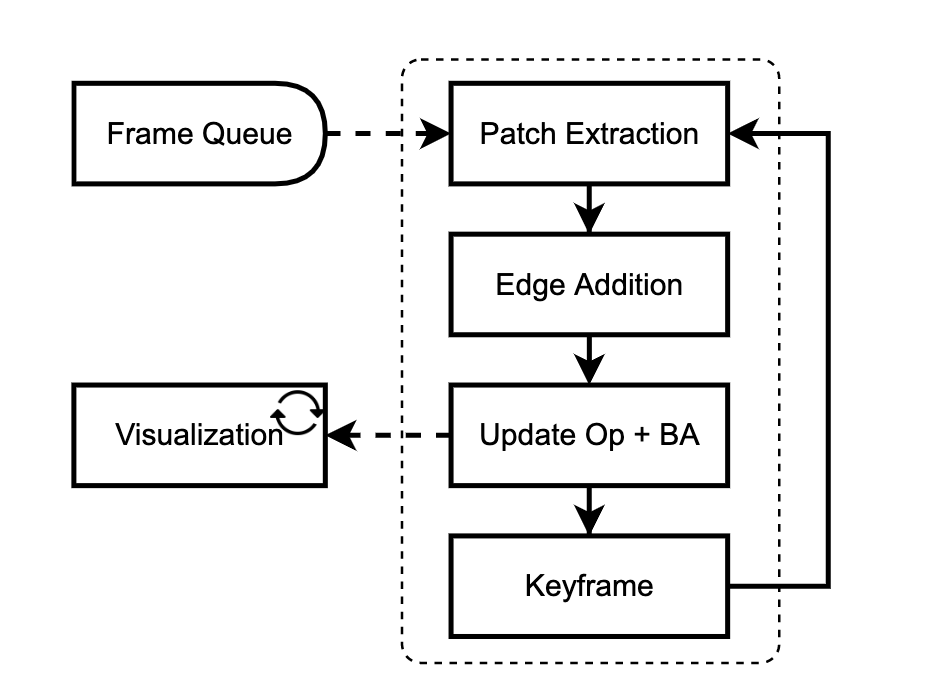
图3 VO系统概述。
2.3 VO System
在本节中,我们将介绍将我们的网络变成一个完整的可视化里程表系统所必需的几个关键实现细节。系统的逻辑主要用Python实现,瓶颈操作如包调整和可视化用c++和CUDA实现。与其他VO系统相比,DPVO非常简单,需要最少的设计选择
初始化:我们使用8帧进行初始化。我们添加新的补丁和帧,直到累积了8帧,然后运行更新操作符的12次迭代。需要一些相机运动进行初始化;因此,我们只在前一帧中积累平均流量大小至少为8像素的帧。
扩展:当添加一个新框架时,我们提取特征和补丁。新框架的姿态初始化使用恒速运动模型。补丁的深度初始化为从前3帧中提取的所有补丁的中值深度。
优化:在添加边缘之后,我们运行更新操作符的一次迭代,然后是两次包调整迭代。除了最后10个关键帧,我们修复了所有的姿势。所有补丁的逆深度都是自由参数。一旦补丁落在优化窗口之外,将从优化中删除。
关键帧:最近的3帧总是被作为关键帧。在每次更新之后,我们计算关键帧t−5和t−3之间的光流大小。如果小于64px,我们删除t−4处的关键帧。当一个关键帧被移除时,我们在它的邻居之间存储相对的姿态,这样完整的姿态轨迹可以被恢复以进行评估
可视化:使用单独的可视化线程交互式地可视化重构。我们的可视化工具是使用穿山甲库实现的。它直接从PyTorch张量中读取,避免了所有不必要的内存拷贝从CPU到GPU。这意味着可视化工具的开销非常小——仅仅使整个系统的速度降低了大约10%。
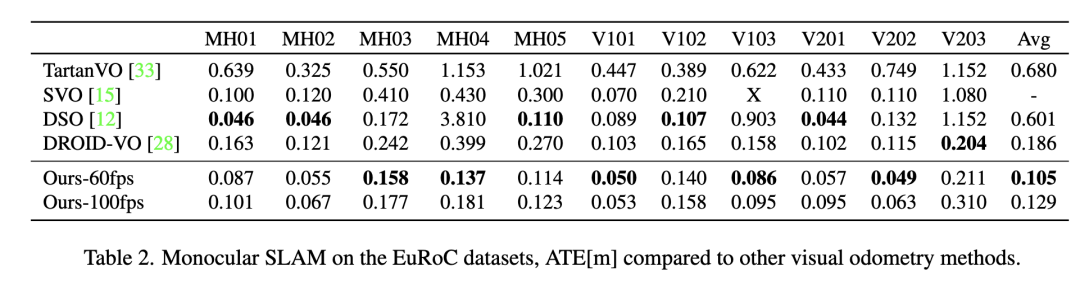
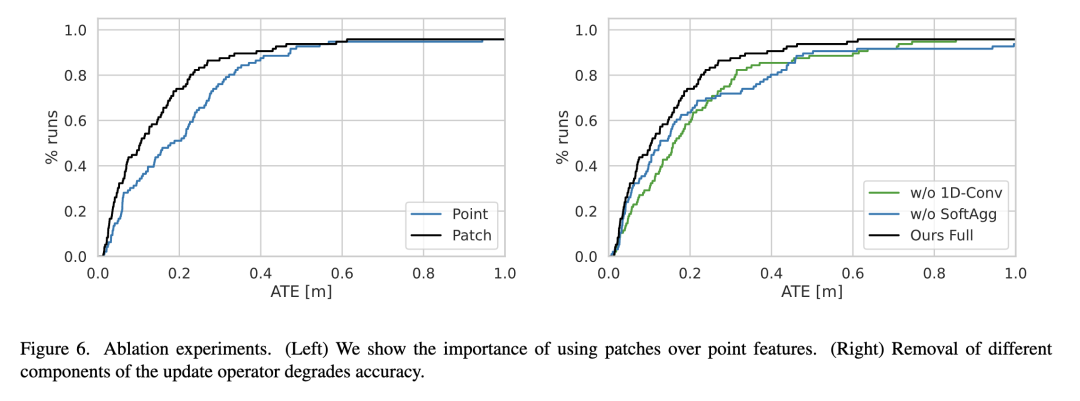
实验结果


图4 示例重建:TartanAir(左)和ETH3D(右)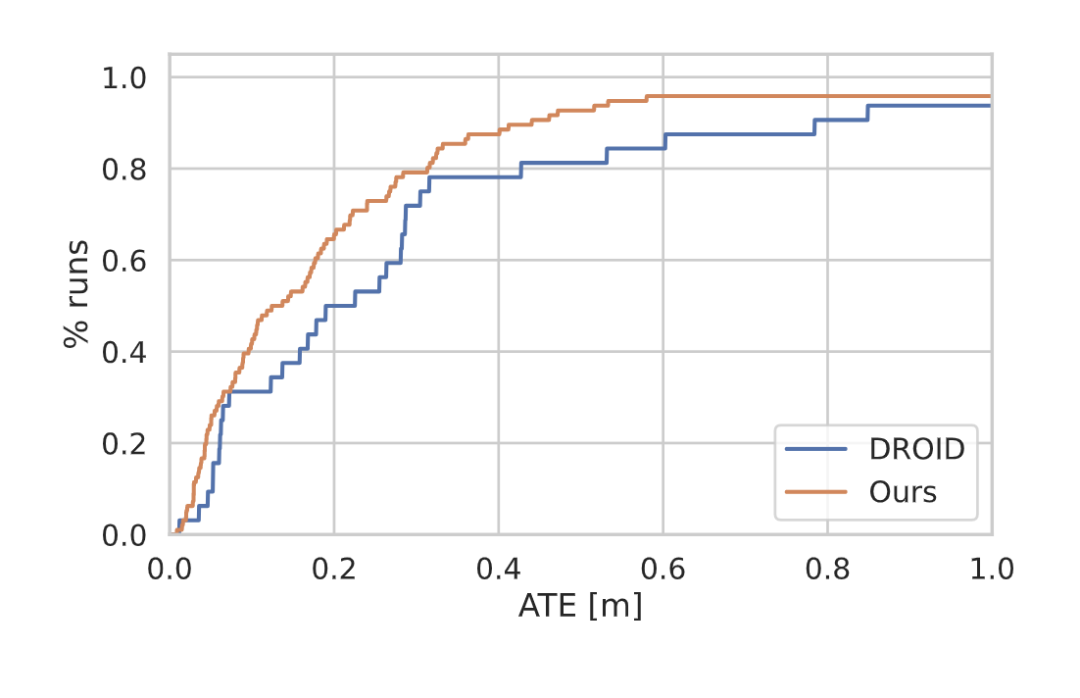
图5 TartanAir[34]验证分离的结果。我们的方法的AUC为0.80,而DROID-SLAM的AUC为0.71,运行速度是DROID-SLAM的4倍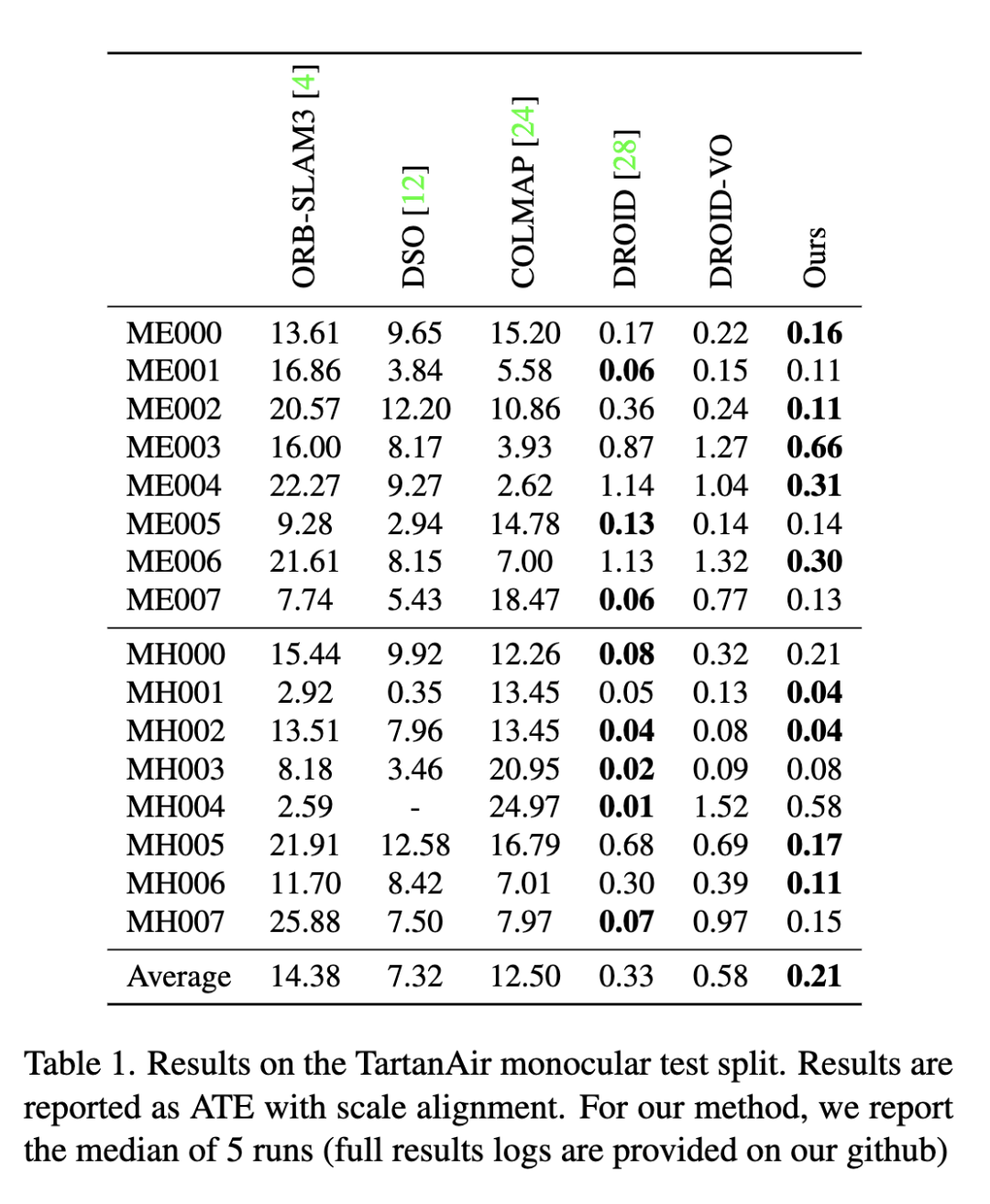
审核编辑:刘清
-
#硬声创作季 CVPR2022 oral 基于事件辅助的直接稀疏单目视觉里程计Mr_haohao 2022-10-12
-
如何去提高汽车里程计电路的抗干扰能力?2021-05-19 1690
-
如何理解SLAM用到的传感器轮式里程计IMU、雷达、相机的工作原理与使用场景?精选资料分享2021-07-27 3836
-
基于全景视觉与里程计的移动机器人自定位方法2011-06-28 965
-
视觉里程计的研究和论文资料说明免费下载2018-12-03 771
-
视觉里程计的详细介绍和算法过程2019-08-08 28385
-
视觉语义里程计的详细资料说明2020-10-28 1382
-
计算机视觉方向简介之视觉惯性里程计2021-04-07 4342
-
基于单个全景相机的视觉里程计2022-12-14 1672
-
介绍一种基于编码器合成里程计的方案2023-04-19 4116
-
介绍一种新的全景视觉里程计框架PVO2023-05-09 3100
-
基于相机和激光雷达的视觉里程计和建图系统2023-05-15 1503
-
在城市地区使用低等级IMU的单目视觉惯性车轮里程计2023-06-06 2706
-
用于任意排列多相机的通用视觉里程计系统2024-12-13 1649
-
一种新型激光雷达惯性视觉里程计系统介绍2025-04-28 1422
全部0条评论

快来发表一下你的评论吧 !
