

一种新的基于视觉语言模型的零镜头分类框架
电子说
描述
1. 论文信息
标题:Visual Classification via Description from Large Language Models
作者:Zihao Xu, Hao he, Guang-He Lee, Yuyang Wang, Hao Wang
原文链接:http://wanghao.in/paper/ICLR22_GRDA.pdf
代码链接:https://github.com/ZrrSkywalker/PointCLIP
2. 引言
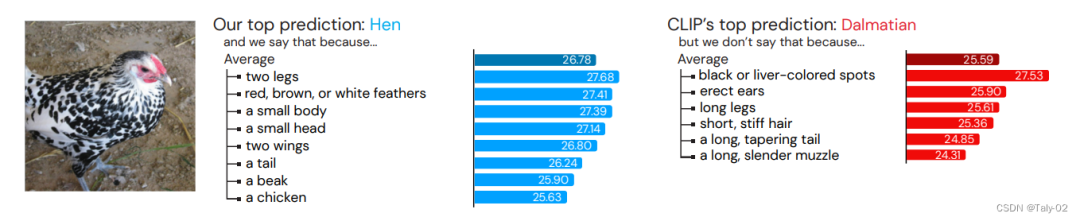
论文首先介绍了一个非常有意思的图:为什么人们把图中的物体分类为母鸡?因为如果我们人类需要证明我们给出的答案是正确的,你可以给它的喙命名,描述它的羽毛,或者讨论我们与母鸡联系在一起的任何其他特征。
人们很容易用文字来描述类别的视觉特征,并利用这些文字描述来辅助感知,用于分类检测等各种感知任务。然而,生成这样的模式的语言描述本身就已经非常具有挑战,很难以完成了,更不用说利用它们进行感知任务,这在机器学习领域还是一个比较大的挑战。
在成对的图像-文本数据的大型语料库上进行训练视觉语言模型(Vison-Language Model),例如CLIP ,最近取得了巨大成功,在图像分类等领域取得了巨大的成就。标准的zero-shot分类的程序设定——计算查询图像和每个类别单词的embeddings之间的相似度,然后选择最高的。这种zero-shot的设定在许多流行的基准测试中显示了令人印象深刻的性能。
与单词相比,这种结构化的描述显然是一个合理的出发点,因为这种基于语义的方法可以依赖于这样一个事实,即在互联网环境种,“母鸡”这个词往往出现在母鸡的图片附近。
其实本文主要的insight是,其实我们可以使用语言作为视觉识别的internal representation,这为计算机视觉任务创建了一个可解释的方案。使用语言使我们能够灵活地与任何单词进行比较,而不是只使用一个类别名称来在多模态信息种进行查询。如果我们知道应该使用什么特性,我们可以让VLM检查这些特性,而不仅仅是依照类名进行查询。
要找一只母鸡,要找它的喙、羽毛以及其他的特征。通过基于这些特性的判断,我们可以获得视觉信息种的额外线索,鼓励查看我们想要使用的特性。在这个过程中,我们可以清楚地了解模型使用什么来做出决策,显然这是有助于。然而,手工编写这些特性可能代价高昂,而且不能扩展到大量的类。我们可以通过向另一个模型请求帮助来解决这个问题。
大型语言模型(large language model),如GPT-3 ,显示了对各种主题的显著的世界知识。它们可以被认为是隐性知识库,以一种可以用自然语言轻松查询的方式喧闹地浓缩了互联网的集体知识。因为人们经常写东西看起来像什么,这包括视觉描述符的知识。
因此,我们可以简单地问一个LLM,通过LLM来查询物体的特征。与从大型语言模型获得的类描述符相比,我们提供了一种用视觉语言模型替代当前零目标分类范式的方法。这不需要额外的训练,也不需要推理期间的大量计算开销。通过构造,这提供了某种程度的内在可解释性;我们可以知道一张图片被标记为老虎,因为模型看到的是老虎的条纹,而不是因为它有一个尾巴而把他分类成老虎。
3. 方法
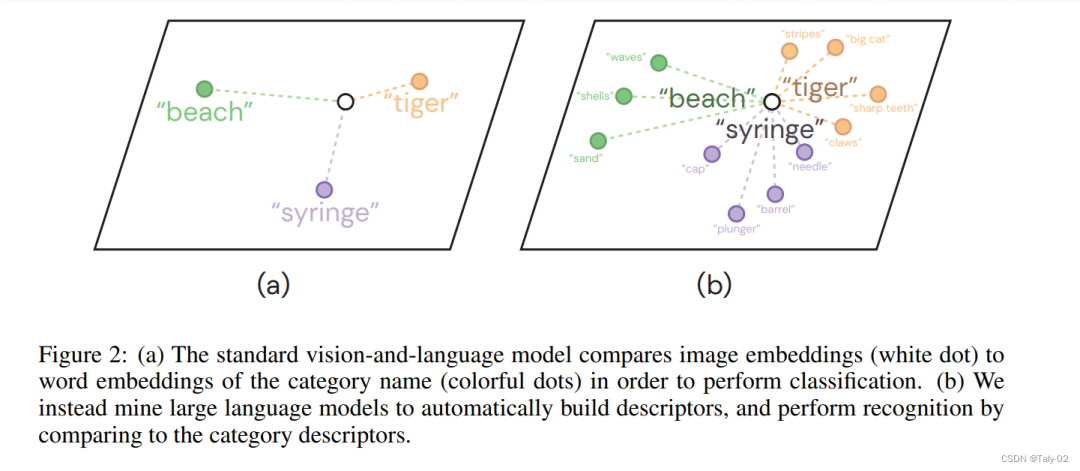
首先来描述下本文定义识别范式和经典的语言识别模型的区别,如上图,论文提出的方法首先对模型类别的特征进行分解:
where is the set of descriptors for the category and is the log probability that descriptor pertains to the image . Our approach will represent the descriptors also through a natural language sentence.
如何得到这些先验的特征分配呢?当然不是去根据手工标注,我们可以去问GPT-3。当类别D(c)的字典包含许多与观察到的图像x高度匹配的描述符时,该模型s(c, x)将输出一个高分。图2说明了这种分类方法。我们使用加法,以便在图像中可以缺少一些描述符,并通过类的描述符数量进行规范化,以允许不同的类拥有不同数量的描述符。由于描述符是相加的,并且用自然语言表示,因此模型是自然可解释的。要理解为什么模型预测c类,我们可以简单地阅读哪些描述符得分高。

问题的模式,如上所示。而获取的答案也非常有意思:

可以发现,利用GPT-3来预测的效果还是非常不错的。描述符通常包括颜色、形状、物体部件、数量和关系,但也可以用自然语言表达任何东西,这些特征灵活性区分了它们,使每个类别的描述符丰富而微妙。
虽然语言模型的训练集中没有图像,但它们可以在没有视觉输入的情况下成功地模仿视觉描述。用于训练语言模型的语料库包含有视觉知识的人所写的描述。这些描述,在规模上聚合,为视觉识别提供了强有力的基础。
下一步就是GROUNDING DESCRIPTORS, 也就是说利用“{category_name} which (is/has/etc) {descriptor}”这种prompt的方式,来使得CLIP的描述更加细粒度,使得模型的text embedding具有更强的泛化能力。可以发现,这个方法等于只是重新设计了一种获取prompt的方式。
4. 实验
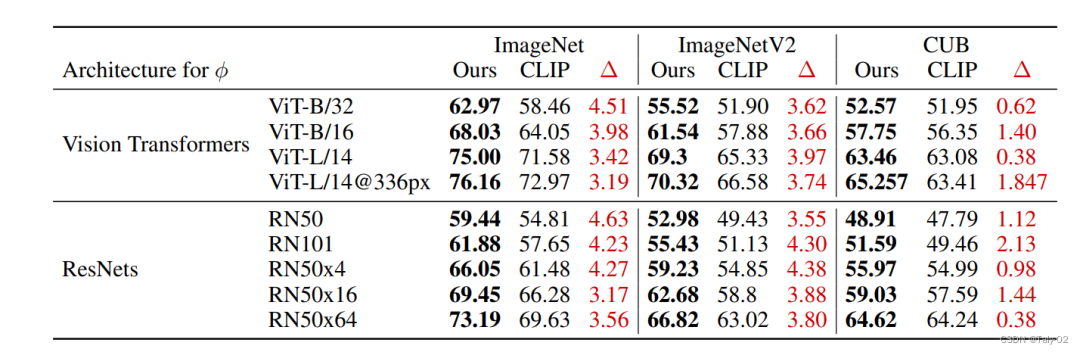
论文评估提出的方法在执行图像分类的能力,同时也为其决策提供解释。虽然大多数可解释性方法都在基准性能上做出了妥协,但在表1中演示了我们的方法在此基础上进行了改进。
与将图像与类名的embedding进行比较的CLIP相比,论文提出的方法在imagenet1上平均提高了3%以上的性能。ImageNetV2分布移位基准的改进表明,这些改进不是由于对ImageNet分布的过拟合。最后,我们演示了对鸟类细粒度分类的CUB基准的约1-2%的改进,表明该技术在通用识别环境之外具有前景。我们假设,由于GPT-3不能产生特定于鸟类分类的生态位描述符,所以在CUB上的收益减少了。
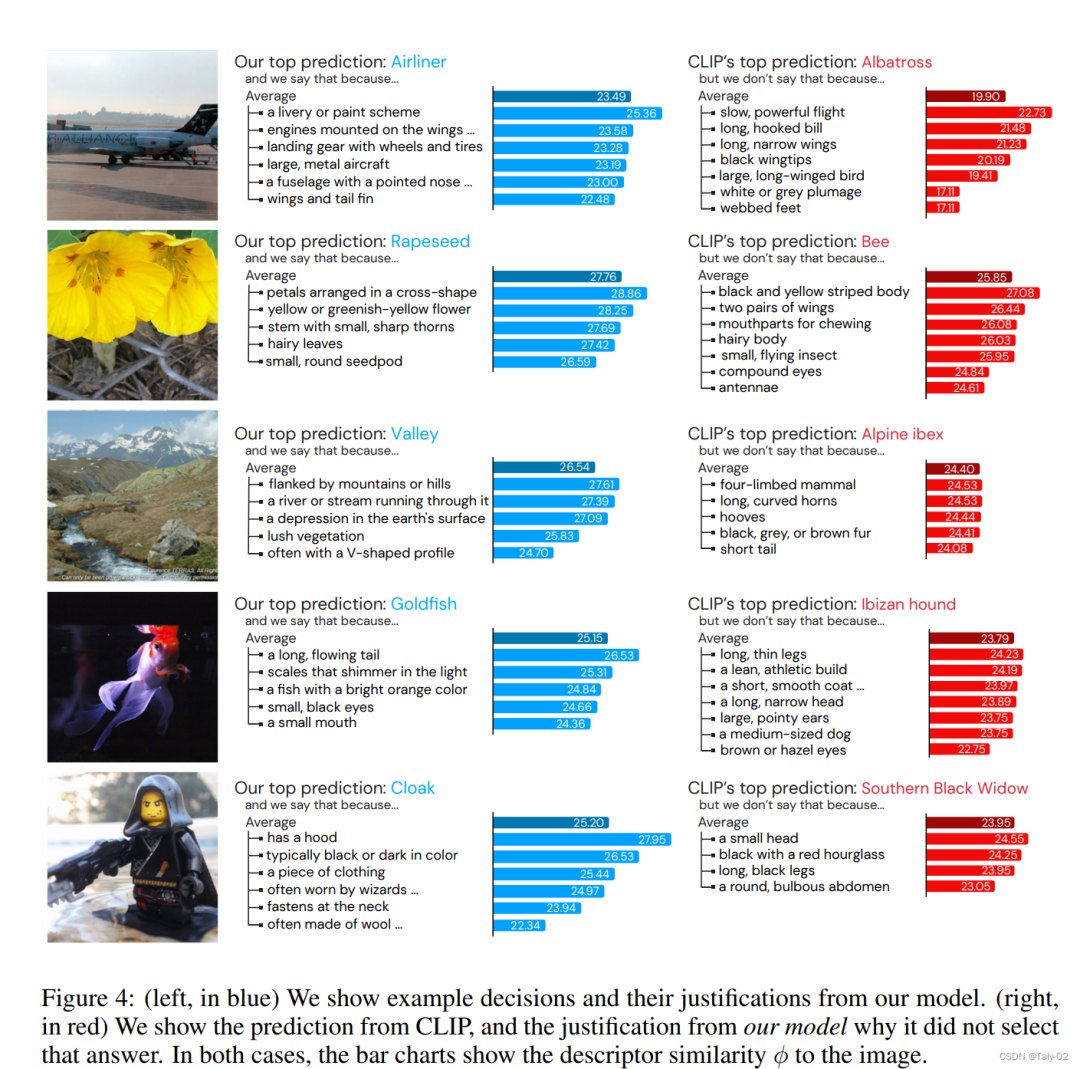
可以看到可视化还是提供了比较充分的对于类别特征的解释的。
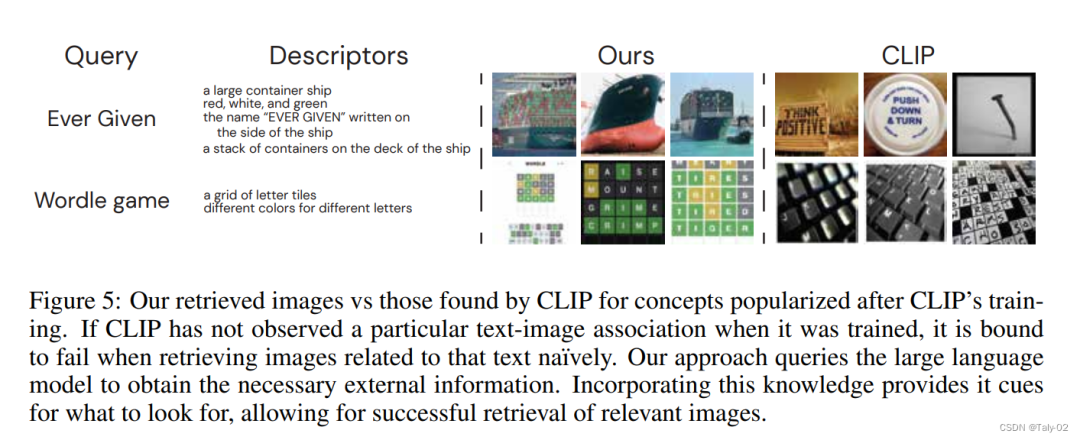
论文也提供了基于描述符的检索信息,可以发现也会有非常显著的性能改进。
5. 结论
论文提出了一种新的基于视觉语言模型的零镜头分类框架。作者利用大型语言模型中关于视觉类别的语言知识,为每个类别生成文本描述符,将图像与这些描述符进行比较,而不是直接估计图像与类别名称的相似性。使用GPT-3和CLIP,作者显示了非常promising的结果。
审核编辑:刘清
-
如何利用Transformers了解视觉语言模型2023-03-03 1866
-
一种成分取证的理论分析模式的分类框架2017-03-20 716
-
一种新的动态微观语言竞争社会仿真模型2017-11-23 1201
-
一种改进的视觉词袋方法2017-12-28 946
-
一种新的目标分类特征深度学习模型2018-03-20 1285
-
一种基于框架特征的共指消解方法2021-03-19 1576
-
一种基于BERT模型的社交电商文本分类算法2021-04-13 1396
-
一种问题框架与模型驱动技术现结合的方法2021-04-23 882
-
OpenCV中支持的非分类与检测视觉模型2022-08-19 2368
-
介绍一种新的全景视觉里程计框架PVO2023-05-09 3186
-
大语言模型中的语言与知识:一种神秘的分离现象2024-02-20 1453
-
基于视觉语言模型的导航框架VLMnav2024-11-22 1998
-
大语言模型开发框架是什么2024-12-06 1356
-
一文详解视觉语言模型2025-02-12 4247
-
VLM(视觉语言模型)详细解析2025-03-17 10396
全部0条评论

快来发表一下你的评论吧 !
