

一文详解超级嵌入式系统“性能/时间”工具箱
嵌入式技术
描述
【开篇就白给?】
对大家熟悉的Cortex-M处理起来说,无论是强调极致资源和低功耗的Cortex-M0、还是频率达到上GHz且能与某些应用处理器掰一掰手腕的Cortex-M7,都不会缺席了SysTick的身影。 正因为SysTick是官方钦定的“不可或缺”的“基础设施”,无论是RTOS系统还是裸机应用,几乎所有的嵌入式固件都会用到它。在这一背景下,如果我告诉你,有一个基于C语言的模块,提供以下功能:
精确测量系统性能
精确测量函数执行时间
精确测量中断响应延迟
提供精确到us级的阻塞或非阻塞的延时服务
改善伪随机数的随机数特性
提供系统时间戳
……
使用了SysTick却不会占用SysTick;
或者说提供以上功能的同时,用户的原有的SysTick应用(比如RTOS调度器或是普通的应用延时)丝毫不会受到影响;
再直白点说:以上功能都是白送的,每个Cortex-M处理器都能立即享有,且不受到芯片型号的影响,
你是不是要直呼:“真就白给?”
是的!作为一个在Github上开源的C语言模块,它真就白给!
【请张嘴……啊~】
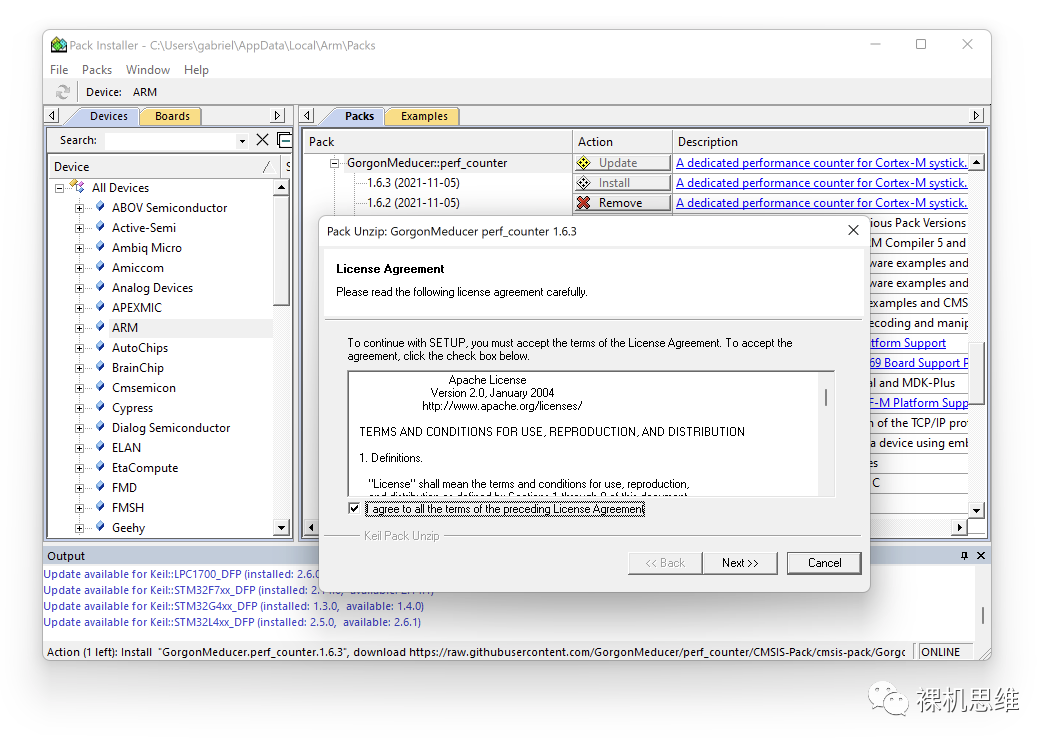
perf_counter版本一路进化,从加入对GCC、IAR的支持、通过Library简化用户部署以来,从版本1.6.1开始更是把模块的部署做到了极致的简化: 这次,你只要从下面的链接“一次性”的下载 CMSIS-Pack,就可以在MDK环境中实现傻瓜式的部署: https://raw.githubusercontent.com/GorgonMeducer/perf_counter/CMSIS-Pack/cmsis-pack/GorgonMeducer.perf_counter.1.9.9.pack 也可以向公众号发送 perf_counter 进行下载。 下载后,双击pack文件进行无脑安装:
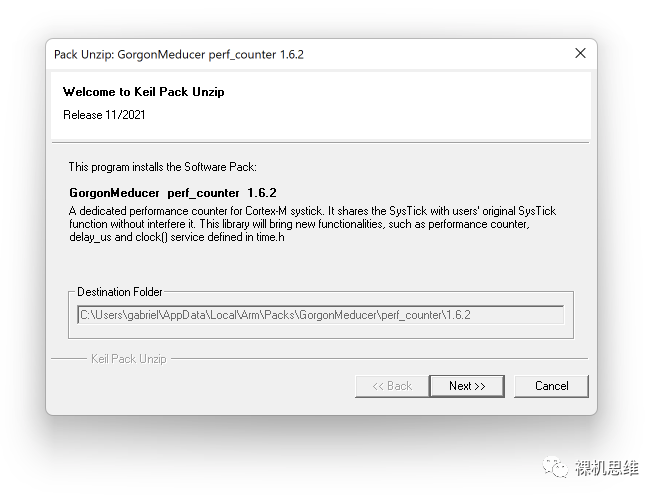
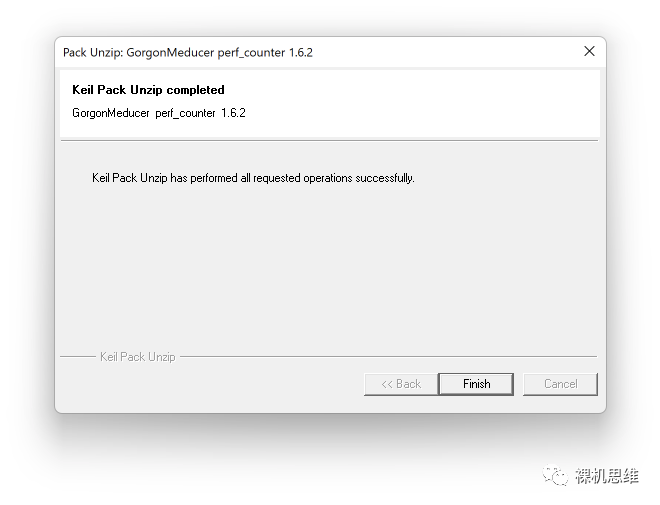
在确认了开原许可Apache 2.0的条款后,一路Next,直到单击Finish,完成整个安装过程:
一般来说,部署会非常顺利,但如果出现了安装错误,比如下面这种:
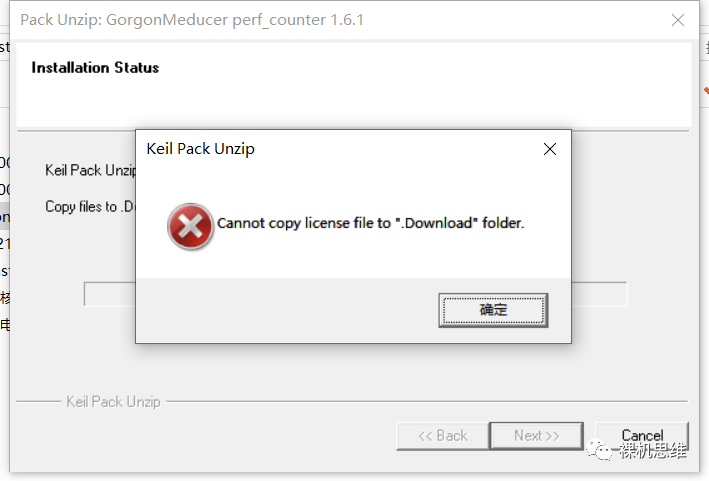
则很可能是您所使用的MDK版本太低导致的——是时候更新下MDK啦。
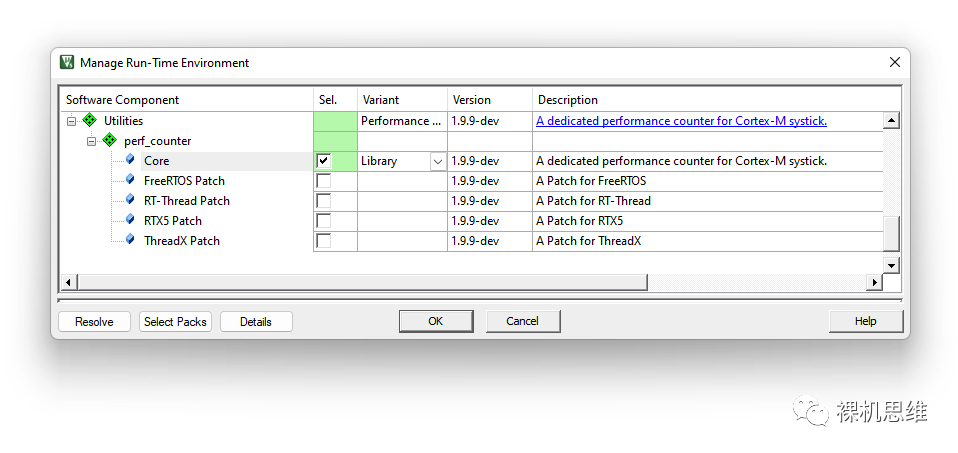
当我们想在任何已有工程中部署perf_counter时,只需要单击MDK工具栏上如下图所示的图标:

打开RTE配置窗口:
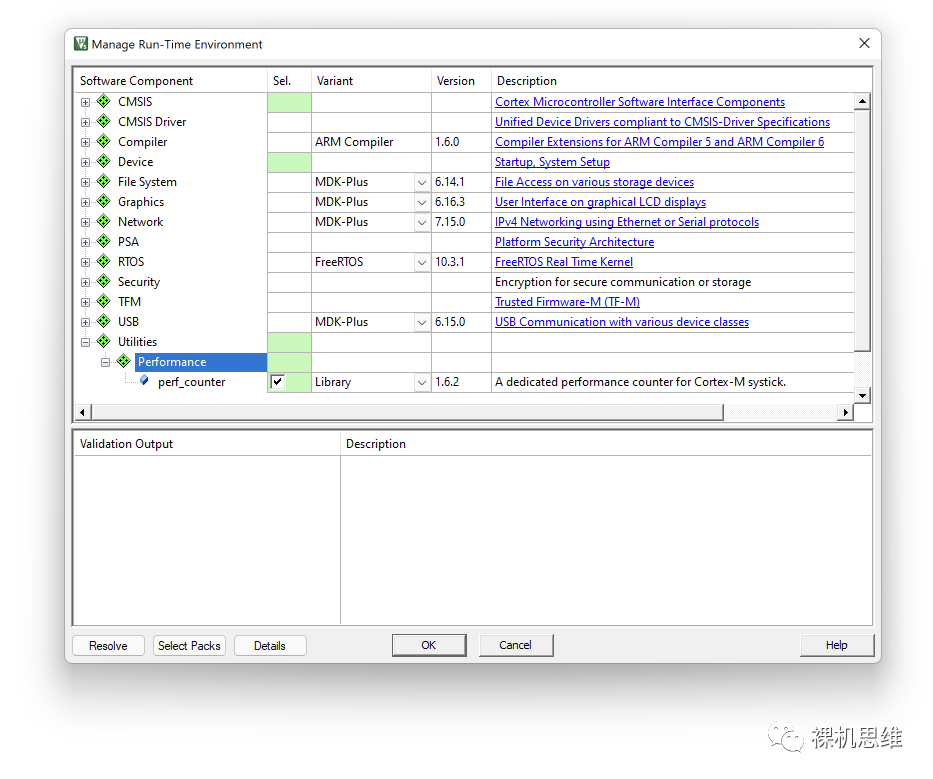
我们会注意到,在列表的末端出现了一个Utilities条目,依次展开后勾选Performance下的perf_counter——默认情况下系统会自动选择以库的形式来实现模块的部署——这也是我吐血推荐的方式,因为它省去了不必要的编译麻烦。
单击OK按钮后,我们会发现Utilities已经被加入到了工程管理器中,而perf_counter.lib也已经成功的部署到了目标工程中:
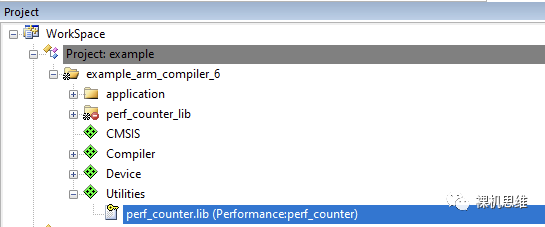
看过我往期文章《【教程】如何用GCC“零汇编”白嫖MDK》的小伙伴一定知道,MDK也可以使用GCC作为编译器。perf_counter也将这种情况考虑在内——当用户实际使用的是GCC时,对应的 libperf_counter_gcc.a(而不是arm compiler 5或arm compielr 6下的perf_counter.lib)会被加入到工程中。
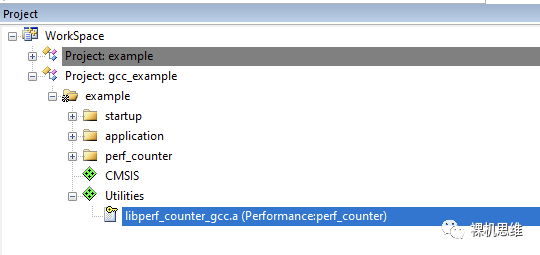
GCC环境下使用perf_counter略微有一些注意事项,由于在文章《【教程】如何用GCC“零汇编”白嫖MDK》的末尾已经有过非常详尽的介绍,这里就不再赘述了。
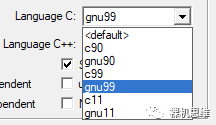
当我们在MDK环境下使用Arm Compiler 6作为编译器时,需要打开对GNU扩展和C99(极其以上)语言标准的支持,具体方法如下图所示:在Language C标准下拉列表中选择带有gnu前缀的选项——如果没有什么特别的顾虑,推荐直接拉满——使用gnu11即可。
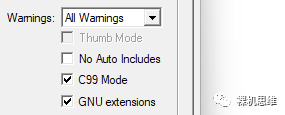
如果你使用的是较老的Arm Compiler 5,则应该同时勾选C99 Mode和GNU extensions两个选项。找不到上述两个选项的小伙伴,应该认真考虑升级你们的MDK版本了。
【一键终结甜咸之争?】
虽然在RTE中,perf_counter推荐并默认使用library的方式来部署,  但考虑到总有小伙伴对黑盒子有莫名的恐惧:
但考虑到总有小伙伴对黑盒子有莫名的恐惧:
“……往往要親眼看着黃酒從罎子裏舀出,看過壺子底裏有水沒有,又親看將壺子放在熱水裏,然後放心……” https://zh.m.wikisource.org/zh/%E5%AD%94%E4%B9%99%E5%B7%B1
因此,perf_counter贴心的提供了以Source源代码来进行部署的方式:

此时,相关的perf_counter.c和systick_wrapper_ual.s会取代原本的库文件加入到编译中:
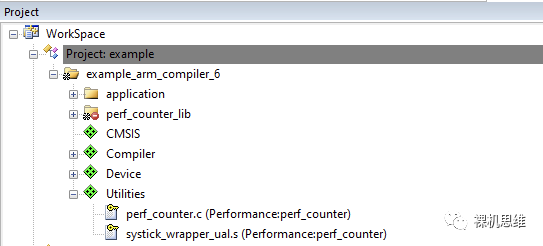
当然,使用Source方式来编译也是有代价的,即perf_counter的源代码对CMSIS有依赖——当你的工程中并未在RTE配置界面中勾选CMSIS-CORE,就会出现类似下图所示的黄色警告信息:“Additional software components required”。
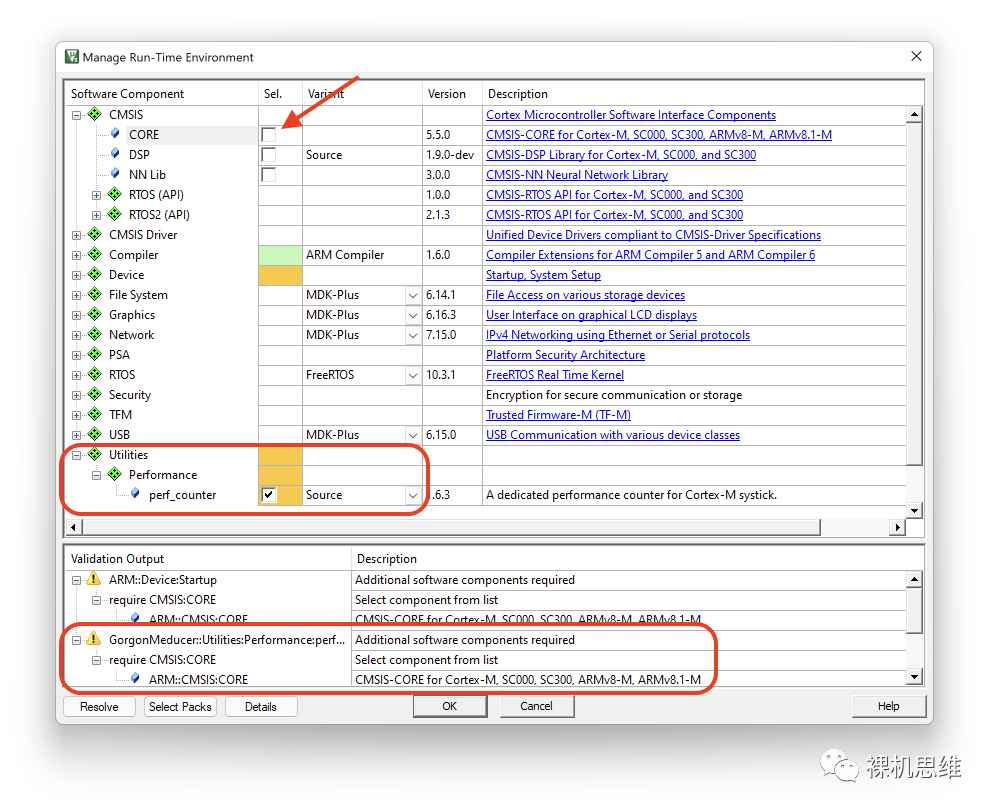
此时,你可以简单的单击Resolve按钮来解决问题——你会发现,所谓的解决方案就是RTE自动把Source模式依赖的CMSIS-CORE帮你勾选上了而已:
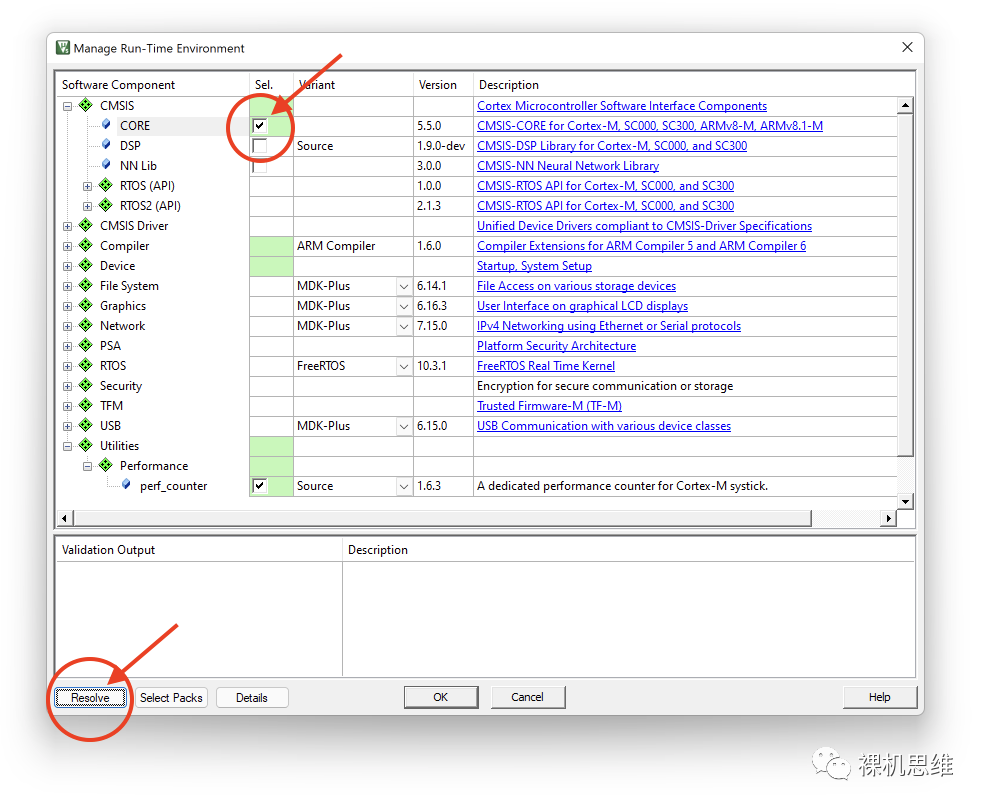
如果你对此并无异议,则问题圆满解决;如果你的系统中存在别的版本的CMSIS(比如很多正点原子、野火、以及CubeMX生成的工程都很可能会携带不经由RTE配置界面来管理的CMSIS),则很有可能出现CMSIS版本冲突——而关于冲突的解决方案,则稍微复杂一些——你可以参考我的文章《CMSIS玩家的“阴间成就”指南》来实现某种取舍……又或者……
还是推荐你继续使用Library模式吧,毕竟它对CMSIS没有任何依赖。
【一键更新的……嵌入式软件模块?】
一旦你安装了perf_counter任何一个版本的pack,都会在MDK的pack-installer中留下痕迹:
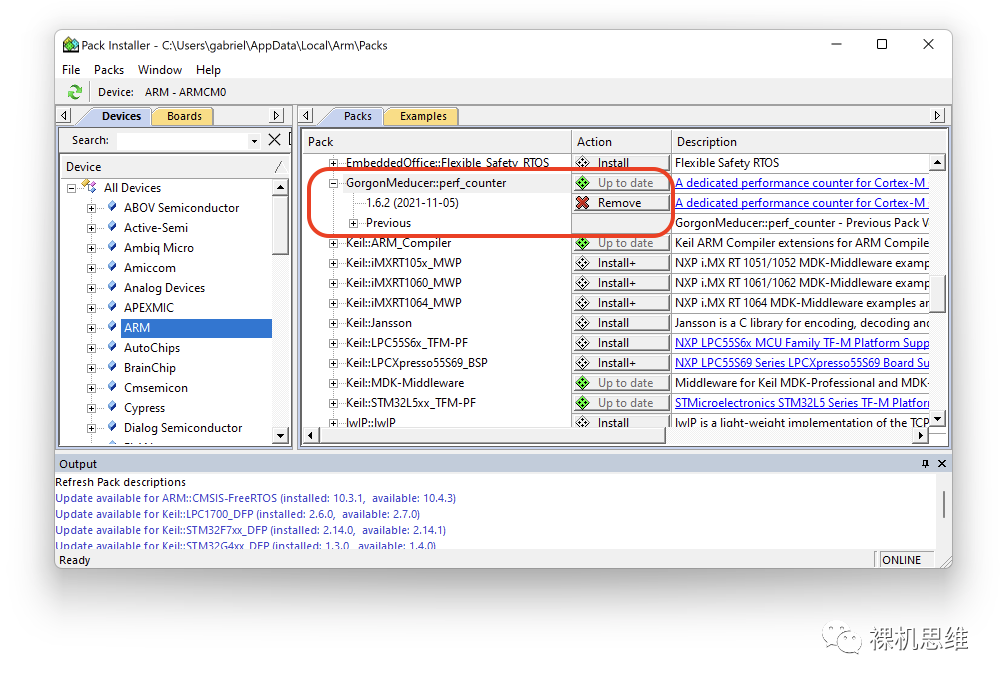
此时,只要通过菜单 Pcak->Check For Update,我们就能实时的查询 perf_counter是否存在最新版本:
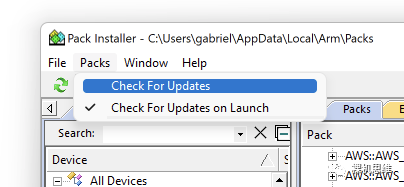
如果Pack-Installer真的从github上发现了更新,就会以黄色Update的图标来告知我们:
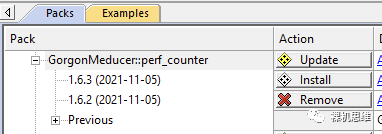
此时,单击Update按钮,即可安装最新版本:
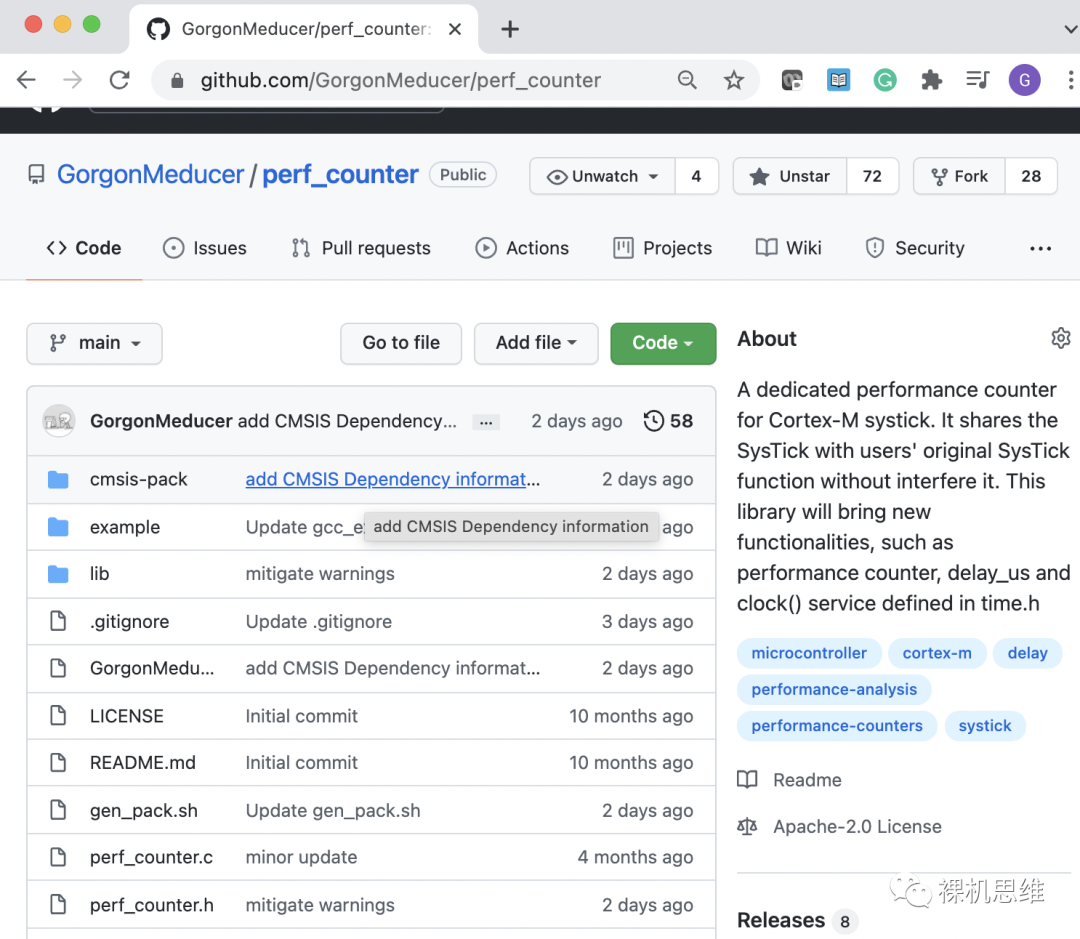
那么,如何才能鼓励博主多多更新、加入更多更好的功能呢?
当然还是要靠有能力科学上网的小伙伴多多Star呀!
https://github.com/GorgonMeducer/perf_counter.git
【库的初始化和注意事项】
关于头文件
在任何需要使用perf_counter的C语言源文件中,我们需要首先加入对头文件的引用:
#include "perf_counter.h"
需要注意的是,通过RTE方式部署的perf_counter并不会在工程管理器中引入 perf_counter.h 以供用户查看。想要查看perf_counter.h查找可用API的小伙伴,可以“简单的”在上述代码行上单击右键,从弹出菜单中选择“Open document 'perf_counter'” 来实现对头文件的访问。
关于库的初始化
一般来说,用户会在某一个地方,比如 main() 函数内完成对CPU工作频率的配置,我们应该在完成这一工作之后确保全局变量 SystemCoreClock 被正确的更新——保存当前CPU的工作频率,比如:
extern uint32_t SystemCoreClock;
void main(void)
{
SystemCoreClockUpdate(); //! 更新CPU工作频率
SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz
...
}
一般来说,你的芯片工程如果本身都是基于较新的CMSIS框架而创建的,你的启动文件中已经为你定义好了全局变量 SystemCoreClock——当然,凡事都有例外,如果你在编译的时候报告找不到变量 SystemCoreClock 或者说“Undefined symbol __SystemCoreClock” 之类的,你自己定义一下就好了,比如:
uint32_t SystemCoreClock;
void main(void)
{
SystemCoreClockUpdate(); //! 更新CPU工作频率
SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz
...
}
在这以后,我们需要对 perf_counter 库进行初始化。这里分两种情况:
1、用户自己的应用里完全没有使用SysTick。此时,在编译时,我们多半会看到类似如下的错误提示:

Error: L6218E: Undefined symbol $Super$$SysTick_Handler (referred from systick_wrapper_ual.o).
对于这种情况,我们需要在任意的C文件中添加一个SysTick中断处理程序:
#include "perf_counter.h"
...
__attribute__((used)) //!< 避免下面的处理程序被编译器优化掉
void SysTick_Handler(void)
{
}
然后我们在 main() 函数里初始化 perf_counter 服务:
#include... void main(void) { SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz init_cycle_counter(false); ... }
需要特别注意的是:由于用户并没有自己初始化 SysTick,因此我们需要将这一情况告知 perf_counter 库——由它来完成对 SysTick 的初始化——这里传递 false 给函数 init_cycle_counter() 就是这个功能。如果由perf_counter 库自己来初始化SysTick,它会为了自己功能更可靠将 SysTick的溢出值(LOAD寄存器)设置为最大值(0x00FFFFFF)。
2、用户自己的应用里使用了SysTick,拥有自己的初始化过程。对于这种情况,我们需要确保一件事情:即,SysTick的CTRL寄存器的 BIT2(SysTick_CTRL_CLKSOURCE_Msk)是否被置位了——如果其值是1,说明SysTick使用了跟CPU一样的工作频率,那么SysTick的测量结果就是CPU的周期数;如果其值是0,说明SysTick使用了来自于别处的时钟源,这个时钟源具体频率是多少就只能看芯片手册了(比如STM32就喜欢将系统频率做 1/8 分频后提供给SysTick作为时钟源),此时SysTick测量出来的结果就不是CPU的周期数。
在确保了 CTRL 寄存器的 BIT2 被正确置位,并且SysTick中断被使能(置位 BIT1,SysTick_CTRL_TICKINT_Msk )后,我们可以简单的通过 init_cycle_counter() 函数告诉perf_counter模块:SysTick 被用户占用了——这里传递 true 就实现这一功能。
#include... void main(void) { SystemCoreClock = 72000000ul //! 假设更新后的系统频率是 72MHz init_cycle_counter(true); ... }
关于Library的匹配问题
perf_counter.lib 库在编译的时候,开启了 Short enums/wchar(分别对应命令行的 -fshort-enums -fshort-wchar)。这么做其实没什么特别的原因,但如果你的工程使用了不同的配置,例如:
下图的工程配置中,没有勾选 "Short enums/wchar"
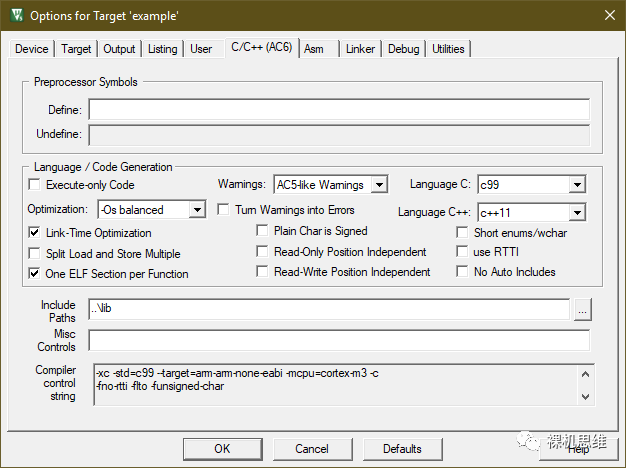
你一定会看到这样的编译错误:

.Outexample.axf: Error: L6242E: Cannot link object perf_counter.o as its attributes are incompatible with the image attributes.
... wchart-16 clashes with wchart-32. ... packed-enum clashes with enum_is_int.
既然知道了原因,解决方法就很简单,要么在工程配置中勾选上这一选项;要么使用源代码编译的模式。
【时间类服务】
微秒级阻塞延时
perf_counter提供了一个us级阻塞延时函数 delay_us(),它的函数原型如下:
extern void delay_us(int32_t iUs);
实际上,由于函数调用的开销,delay_us在时间判断上会存在一个“不积累”的误差——根据优化等级的不同,其具体CPU周期数存在差异,如果我们以Library方式进行部署时,这一误差大约在+/-25个CPU周期左右——这一信息实际上告诉我们:
在使用Library的情况下,当你的CPU频率超过50MHz时,delay_us() 可以提供最小<1us的延时误差;
当你的系统频率不满足上述条件时,以系统频率 12MHz为参考,则可以认为delay_us误差为不积累的 +/- 2us。
具体评估方法,请参考我往期的文章《【实时性迷思】CPU究竟跑的有多快?》,这里就不做赘述。
全局系统时间
perf_counter提供了API函数get_system_ticks(),用于方便用户获取自 SysTick启动以来系统已经经历过的总周期数,其函数原型如下:
__attribute__((nothrow)) extern int64_t get_system_ticks(void);
可以看到,其返回值是一个 64位的有符号整数,即便抛开符号位,也基本可以确信:无论芯片频率如何,在人类灭绝之前,不会发生溢出问题。
此外,从版本v1.9.9开始,我们还可以从 perf_counter 中找到另外两个有用的函数:get_system_us() 和 get_system_ms()。 比如,这里的 get_system_ms() 可以告诉我们从SysTick启动以来(一般大约可以等效为从系统复位开始)已经过去了多少毫秒。是不是特别方便?
非阻塞式多重延时
在状态机中,非阻塞式的延时往往是必不可少的功能,包括但不限于:
机构控制的延时;
电路的时序控制;
通信协议的超时处理;
下图就是一个支持多实例的非阻塞延时的状态机,即便你没有看过我的状态机系列文章,对应的逻辑应该也算是浅显易懂。
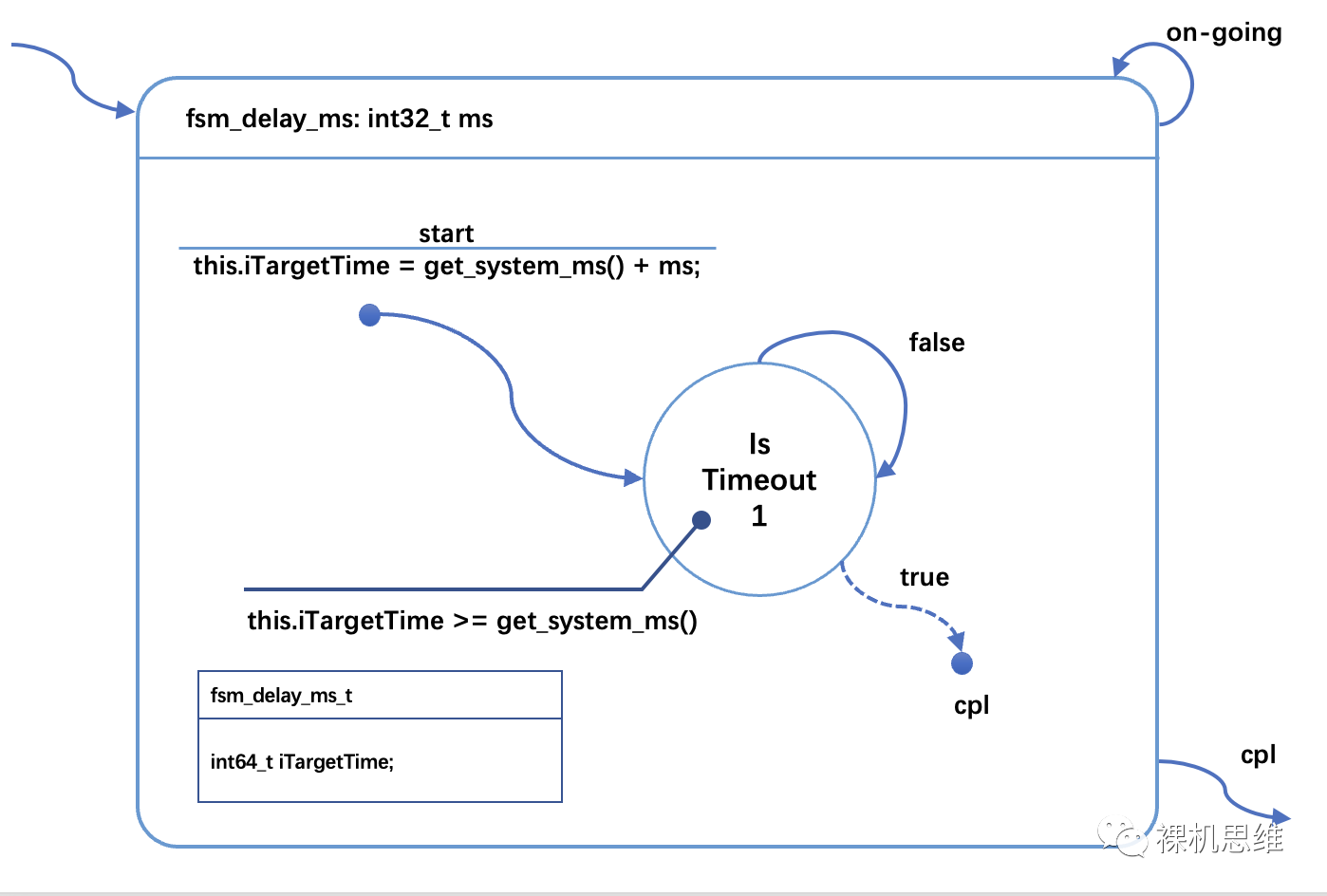
这里的核心思想是:
在延时的开始时刻,通过 get_system_ms() 来获取当前的系统时间戳;
计算目标时刻的系统时间戳并保存在状态机类中(保存在 iTargetTime里);
在随后的状态中以非阻塞的方式轮询 get_system_ms() 以检查约定的时间是否已经到来。
下面的状态图展示了如何在执行某些动作(或者子状态机)的同时,进行超时判断:
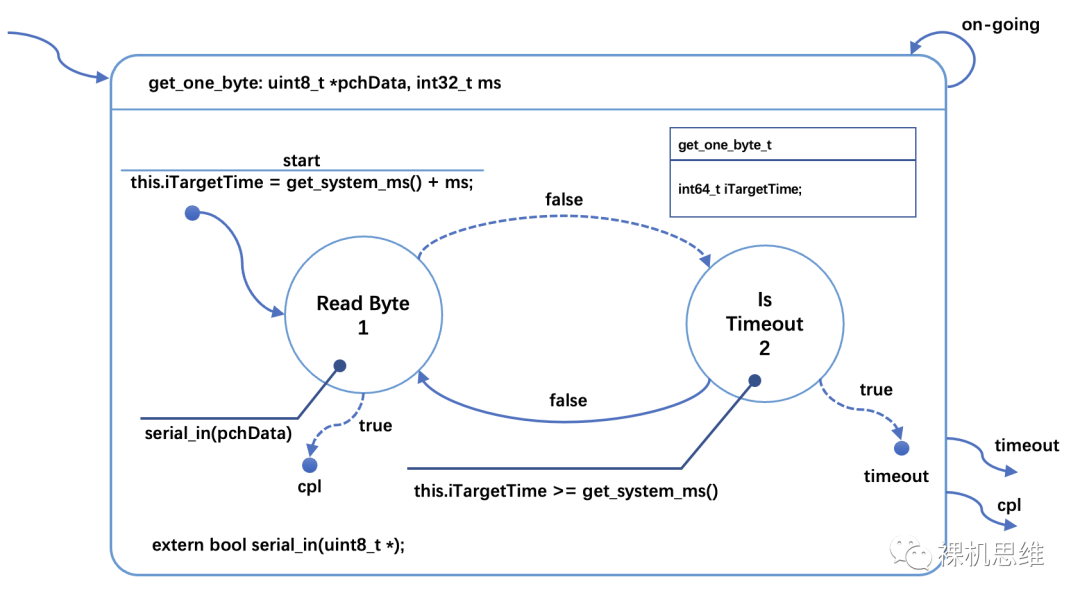
这里值得注意的细节是:
在延时的开始时刻,通过 get_system_ms() 来获取当前的系统时间戳;
计算目标时刻的系统时间戳并保存在状态机类中(保存在 iTargetTime里);
在读取字符失败时,通过对比当前的系统时间戳来判断是否超时。
具体状态图的解读和翻译方式,还不熟悉的小伙伴可以单击这里来阅读状态机系列文章,这里就不再赘述。
随机数发生
几乎所有的C语言教程都在介绍过随机数的发生,比如:
#include由于rand()实际上是一个伪随机数发生器,因此为了达到理想的效果,无一例外的,所有教材都推荐使用时间作为随机数的种子。借助 get_system_ticks() 的帮助,我们的伪随机发生函数几乎可以肯定的是距离真正的随机数发生器更近了一步:#include int main (void) { int i, n; time_t t; n = 5; /* Intializes random number generator */ srand((unsigned) time(&t)); /* Print 5 random numbers from 0 to 49 */ for( i = 0 ; i < n ; i++ ) { printf("%d ", rand() % 50); } return(0); }
#include "perf_counter.h" #includesrand((unsigned)get_system_ticks());
【嵌入式C语言扩展】
perf_counter除了提供一些与系统性能测量和时间有关的服务歪,还额外对嵌入C语言做了一定的扩展,有兴趣的小伙伴不妨试一试。
全局中断屏蔽 __IRQ_SAFE
perf_counter 提供了一个关键字 __IRQ_SAFE,它可以在执行紧随其后一条语句、或是紧随其后的花括号内的代码片断时,暂时性的关闭全局中断响应,并在完成对应操作后恢复原样。
//! 执行 紧随其后的printf语句时,暂时性的屏蔽全局中断
__IRQ_SAFE printf("hellow world!");
//! 执行花括号内的代码时,暂时性的屏蔽全局中断
__IRQ_SAFE {
...
}
//! 想提前结束时,可以用continue;
__IRQ_SAFE {
...
if (某些条件) {
//! 我们需要提前结束
continue;
}
//! 条件性跳过的操作
...
}
__IRQ_SAFE在使用时,有以下注意事项:
它只能用于函数内部,不可以用来修饰函数或者变量;
它支持嵌套
编译器类型检测
有些小伙伴在进行软件开发时,可能会因为这样或者那样的原因,需要能够稳定可靠的检测出当前所使用的编译器,比如 Arm Compiler 5、Arm Compiler 6、GCC等等。
perf_counter 提供了一系列统一格式的宏,有效的解决了上述问题。它们是:
__IS_COMPILER_ARM_COMPILER_5__ __IS_COMPILER_ARM_COMPILER_6__ __IS_COMPILER_GCC__ __IS_COMPILER_LLVM__ __IS_COMPILER_IAR__
这些宏仅会在检测到对应编译器时被定义。一个典型的用法如下:
#if defined(__IS_COMPILER_IAR__)
__attribute__((constructor))
#else
__attribute__((constructor(255)))
#endif
void __perf_counter_init(void)
{
init_cycle_counter(true);
}
这里,__attribute__((constructor)) 的作用在于告诉编译器“请在执行main函数前执行被它修饰的函数”。这是一个GCC扩展,为大部分编译器广泛接受和支持,但由于IAR的在语法上并不支持存在多个函数时排队用的序号,因此需要与其它编译器区别处理。
预编译胶水宏
很多场景下,我们需要在预编译时刻对多个“文本片断”进行“粘合”,以生成新的名称,比如宏、枚举、变量名、函数名等等。 一般来说,我们都见过类似如下的做法:
#define TPASTE(a,b) a##b
但这里其实存在一些问题,这类问题在我的文章《【为宏正名】本应写入教科书的“世界设定”》中有详细讲解,这里就不再赘述。单纯从功能上来讲,TPASTE只能完成2个名称的“粘合”,如果是多个呢?如果要粘合的名称数量不去定呢?perf_counter就提供了这样一个解决方案 CONNECT(),并具有以下优势:
黏合的数量可以是变化的
最大支持黏合9个片断
比如,我们想生成一个安全的临时名称,则可以试着将代码所在行号__LINE__、下划线以及用户指定的后缀黏合在一起:
#define SAFE_NAME(__NAME) CONNECT(__,__LINE__,_,__NAME)
比如,下面的代码:
#define measure_time(...)
({
int64_t SAFE_NAME(StartTime) = get_system_ticks();
__VA_ARGS__;
get_system_ticks() - SAFE_NAME(StartTime);
})
int32_t iCycleUsed =
measure_time(
printf("Hello world!
");
);
假设measure_time所在的行号为123,则实际对应的代码为:
int32_t iCycleUsed =
({
int64_t __123_StartTime = get_system_ticks();
__VA_ARGS__;
get_system_ticks() - __123_StartTime;
});
该代码的作用是测量 measure_time()的圆括号内的代码块所用时间,并作为表达式的值返回。这里用到了GCC的一个被称为“Statements and Declarations in Expressions”的语法扩展,感兴趣的小伙伴可以参考下面的链接:
https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs
数组元素枚举器
C语言中,我们时常要使用for语句来实现对数据元素的访问,比如,下面的代码:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];
int16_t get_average_voltage(void)
{
int32_t nTotal = 0;
for (int32_t n = 0; n < ADC_BUFFER_SIZE; n++) {
n += s_iADCBuffer[n];
}
return nTotal / ADC_BUFFER_SIZE;
}
在这个简单的例子中,for循环的作用就是枚举数组 s_iADCBuffer 中的每一个元素。很多高级语言(甚至是Linux内核代码),都引入了专门的 foreach 关键字来实现这样的数据枚举功能,perf_counter也不能免俗,其语法为:
foreach (<数组元素的类型>,<数组名称>) {
...
}
借助 foreach 的帮助,上述代码可以被简化为:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];
int16_t get_average_voltage(void)
{
int32_t nTotal = 0;
foreach (volatile int16_t, s_iADCBuffer) {
nTotal += *_;
}
return nTotal / ADC_BUFFER_SIZE;
}
注意,这里"_"是一个指向枚举过程中当前元素的指针,简单说,它等效于前面代码中的 "(s_iADCBuffer+n)",由于是指针,因此在使用是需要用 “*_”来获取元素的内容。使用"_"来指代循环体内的当前元素,借鉴于脚本语言perl。如果你非常讨厌这种用法,觉得不知所云,那么也可以使用下面的方法:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE];
int16_t get_average_voltage(void)
{
int32_t nTotal = 0;
foreach (volatile int16_t, s_iADCBuffer, piItem) {
nTotal += *piItem;
}
return nTotal / ADC_BUFFER_SIZE;
}
注意到:foreach在原有2个参数的基础上引入了第三个参数 piItem,这里的用法实际为:
foreach (<数组元素的类型>,<数组名称>,<枚举元素名称>) {
...
}
换句话说,用户可以通过第三个参数指定枚举元素的变量名称了,是不是一下就清晰了很多?
【如何测量代码片断占用了多少CPU资源】
支持嵌套的 __cycleof__()
很多时候,我们会关心某一段代码或者函数究竟用了多少CPU周期,比如,我们写了一个算法,你很担心“这个算法究竟使用了多少CPU资源”,为了解决这个问题,我们需要用到如下的公式: CPU资源占用(百分比) = (函数运行所需的时间) (算法运行间隔的最小值) 100% 对于【函数运行所需的时间】和【算法运行间隔的最小值】来说,虽然它们都是时间单位,但考虑到CPU的频率是给定的(不变的),因此,这里的时间单位在乘以CPU的工作频率后都可以被换算为CPU的周期数。举例来说,假如【算法运行间隔的最小值】是 20ms、CPU的频率是72MHz,那么对应的周期数就是 72000000 * (20ms / 1000ms) = 1440000 个周期。看来上述公式中唯一需要我们实际测量的就是【函数运行所需的周期数】了。
perf_counter 提供了一个非常简单的运算符:__cycleof__()。假设我们要测量的代码片断如下:
my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); ...则我们可以轻松的通过__cycleof__()运算来测量结果:
...
__cycleof__("my algorithm") {
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
...
如果你的系统支持 printf(),则可以看到类似如下的输出结果:

带入上述公式: 525139 / 14400000 * 100% ≈ 36.5% 就计算出这个算法占用了大约 36.5% 的CPU资源,值得说明的是,从原理上看,这一方式对裸机和RTOS同样有效哦。
有的小伙伴很快会说,我的系统并不允许我调用printf,那我还可以使用 __cycleof__() 么?当然了!就继续以上述代码为例子:
int32_t nCycleUsed = 0;
...
__cycleof__("my algorithm", {
nCycleUsed = _;
}) {
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
...
这里的代码所实现的功能是:
测量了用户函数 my_algorithm_step_xxx() 所使用的周期数:
测量的结果被转存到了一个叫做 nCycleUsed 的变量中;
__cycleof__() 将不会调用 printf() 进行任何内容输出。
我相信很多小伙伴会揉了揉眼睛、仔细看了又看,然后回过头来满头问号: 这是C语言? 这是什么语法? 不要怀疑,这就是C语言,只不过使用了一点GCC的语法扩展(感兴趣的小伙伴可以复制这里的连接 https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs),考虑到本文只介绍 perf_counter 如何使用,而对其如何实现的并不关心,我们不妨略过GCC扩展语法的部分,专门来看看上述代码的使用细节:
首先,为了方便大家观察,我们先忽略圆括号内的部分:
__cycleof__(...) {
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
...
可以发现,这里跟此前并没有什么不同:花括号包围的部分就是我们要测量的代码片断;
接下来,我们专门来看__cycleof__() 圆括号中的部分:
int32_t nCycleUsed = 0;
__cycleof__("my algorithm", {
nCycleUsed = _;
})
{
...
}
...
容易发现,如果以“,” 为分隔符,那么实际传递给 __cycleof__() 的是两个部分: 1、标注测量名称的字符串
"my algorithm"2、一段用花括号括起来的代码片断:
{nCycleUsed = _;}
其中,nCycleUsed 是一个事先已经初始化好的变量。 这里,对于表示测量名称的字符串"my algorithm",在这一用法下在最终的编译结果里并不会占用任何RAM或者是ROM,但作为语法结构是必须的。 对于花括号所囊括的代码片段来说,实际上在这个花括号里,你几乎可以为所欲为:
你可以写任意数量的代码
你可以调用函数
你可以定义变量(当然这里定义变量肯定就是局部变量了)
但我们一般要做的事情其实是通过__cycleof__() 所定义的一个局部变量"_"来获取测量结果——这也是下面代码的本意:
nCycleUsed = _;需要说明的是,这个局部变量"_"生命周期仅限于这个花括号中,因此不会影响 __cycleof__() 整个结构之外的部分——或者说,下述代码是没有意义的:
int32_t nCycleUsed = 0;
...
__cycleof__("my algorithm", {
nCycleUsed = _;
}) {
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
printf("Cycle Used %d", _);
编译器会毫不客气的告诉你 "_" 是一个未定义的变量,反之如果你这么做:
int32_t nCycleUsed = 0;
...
__cycleof__("my algorithm", {
nCycleUsed = _;
printf("Cycle Used %d", _);
}) {
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
则会看到你心怡的输出结果:
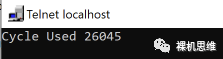
系统时间戳 get_system_ticks()
如果你对上述例子的等效形式(展开形式)感到非常好奇,其实大可不必,上述代码在“逻辑上等效”于如下的形式:
int32_t nCycleUsed = 0;
do {
int64_t _ = get_system_ticks();
{
my_algorithm_step_a();
my_algorithm_step_b();
...
my_algorithm_step_c();
}
_ = get_system_ticks() - _;
//! 我们添加的代码
nCycleUsed = _;
printf("Cycle Used %d", _);
} while(0);
是不是突然就没有那么神秘了?通过“逻辑等效”的形式展开,我们很容易发现一些有趣的内容:
起核心作用的是一个叫做 get_system_ticks() 的函数。实际上它返回的是从复位后 SysTick被使能至今所经历的 CPU 周期数——由于它是int64_t 的类型,因此不用担心超过 SysTick 24位计数器的量程,也不用担心人类历史范围内会发生溢出的可能。 知道这一点后,聪明的小伙伴就可以自己整活儿了。
由于 "_" 是一个局部变量,因此可以判断 __cycleof__() 是支持嵌套的。
需要特别说明的是,get_system_tick() 函数自己也是有CPU时钟开销的,所以如果要获得较为精确的结果,推荐通过下面的方法来获取校准值:
static int64_t s_lPerfCalib;
void calib_perf_counter(void) {
int64_t lTemp = get_system_tick();
s_lPerfCalib = get_system_tick() - lTemp;
}
int64_t get_perf_counter_calib(void)
{
return s_lPerfCalib;
}
具体如何使用,这里就不再赘述了。
连续计时模式
为了方便某些特殊场合的测试需求,perf_counter还通过start_cycle_counter() 和 stop_cycle_counter() 的组合提供了类似体育老师所使用秒表的连续计时功能,即:起跑后可以分别记录每一个学生所用的时间。具体表现为
int32_t nCycles = 0; start_cycle_counter(); //!< 开始总计时 ... nCycles = stop_cycle_counter(); //!< 第一次获取从开始以来的时间 ... nCycles = stop_cycle_counter(); //!< 第二次获取从开始以来的时间 ... nCycles = stop_cycle_counter(); //!< 第三次获取从开始以来的时间 ...
值得强调的是虽然 start_cycle_counter() 和 stop_cycle_counter() 有 start 和 stop 的字样,但这只有逻辑上的意义而并不会真正的干扰 SysTick 的功能(也就是不会开启或者关闭 SysTick)。这也是这个库敢于声称自己不会影响用户已有的 SysTick 功能的原因。
【对RTOS的支持】
虽然 perf_counter 本身可以直接在大部分RTOS环境下直接使用,但在额外插件的加持下,perf_counter 还可以提供额外的功能,比如:
刨去任务调度的干扰,测量线程内指定代码所用的时间周期数。(详情请参考文章《实时性迷思(5)——实战RTOS多任务性能分析》)
对跨越多个线程的算法进行精确的性能测量(详情请参考文章《实时性迷(6)——如何进行跨任务性能分析》)
要获得上述功能,在MDK环境下只需要勾选对应补丁即可(一些具体注意事项请参考文章《实时性迷思(5)——实战RTOS多任务性能分析》),非常方便。
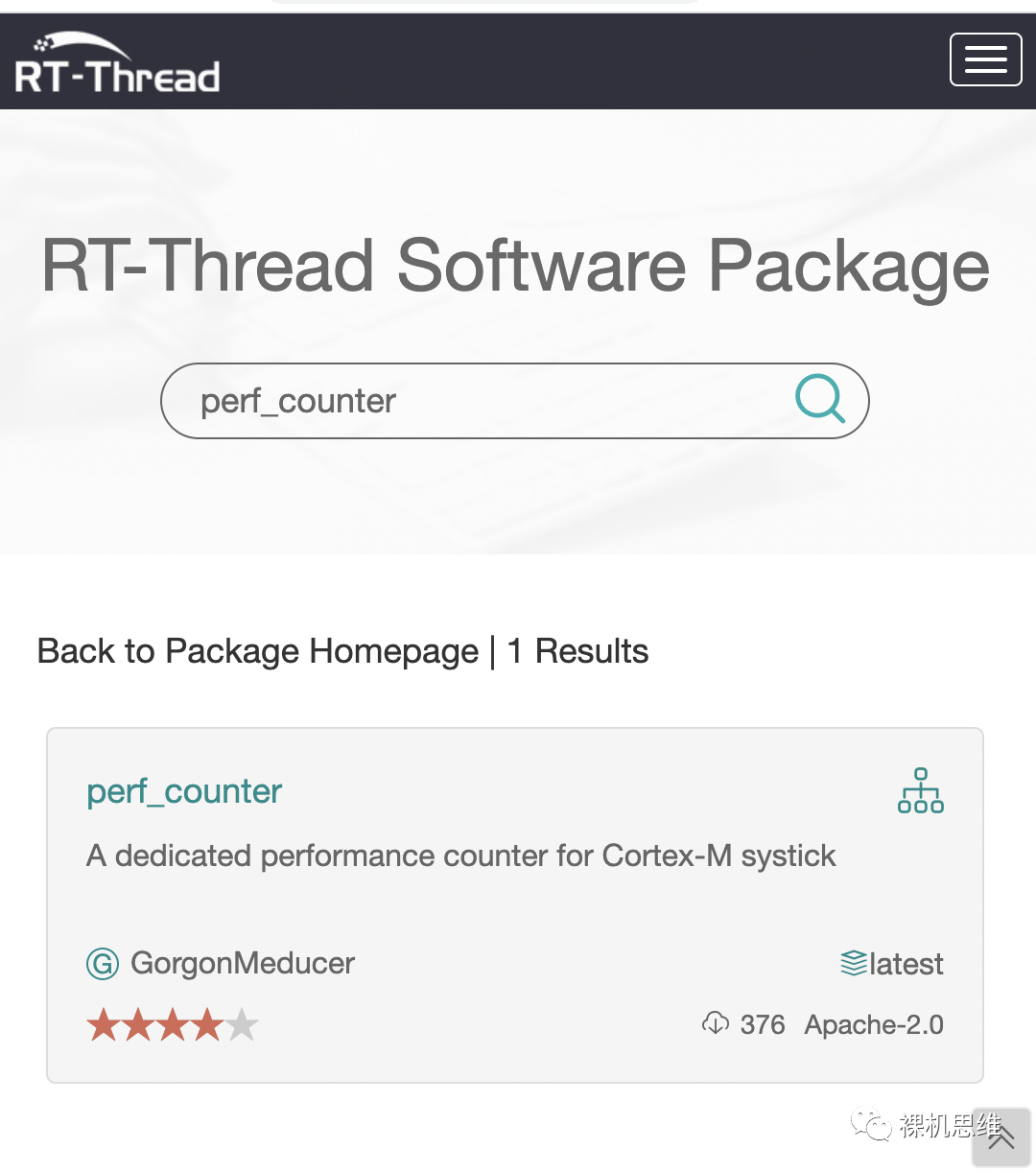
如果你是RT-Thread的用户,还可以通过官方的包管理器直接获取最新的版本:
【说在后面的话】
perf_counter 最初诞生于我的日常工作——当我发现我需要重复的在不同工程间复制性能测试相关的代码时,制作一个模块来节省我的时间就成了偷懒的最好理由。 中文互联网上,在嵌入式项目中对系统性能进行测量其实并不是什么热门话题,在日常应用开发中,相比定量分析,大家可能更喜欢一拍脑袋的纯凭感觉来评价系统的性能。我在文章《【实时性迷思】CPU究竟跑的有多快?》已经对此做了吐槽。相比之下,如何实现 us 级别的延时则更为流行一些。看到不少人用DWT之类限定于某几个处理器的不推荐用户使用的调试类外设作为延时,看到手中明明有更好的、且通用的方案,我实在不敢独享——这也成了perf_counter成为github上一个开源项目的契机。 相比最初那简陋的代码,到现在最新的 v1.9.9版,我很难抑制内心的那种自我感动。感谢大家的支持——是你们的Star支撑着我一路对项目的持续更新。谢谢!
编辑:黄飞
-
PSINS工具箱入门与详解2022-10-31 1679
-
超级嵌入式系统“性能/时间”工具箱资料介绍【上】2022-09-26 3113
-
恩智浦原型嵌入式设计:电池管理系统应用2022-09-22 834
-
基于Simulink的STM32工具箱外设一键式代码该如何去生成呢2021-11-18 1511
-
Simulink中STM32工具箱一览2021-08-17 1382
-
嵌入式详解2021-07-30 1428
-
普查工具箱有哪些以及植保仪器工具箱系列的汇总2021-01-06 2090
-
***工具箱下载5.8最新版2019-04-19 2866
-
ARM嵌入式Linux系统开发详解2018-09-14 5359
-
matlab模糊控制工具箱的使用2016-05-04 848
-
矮人DOS工具箱52016-04-29 927
-
手机超级工具箱2010-05-15 372558
-
MATLAB语言工具箱-ToolBox实用指南2009-11-25 58147
-
matlab的其他工具箱及SIMULINK2009-09-03 824
全部0条评论

快来发表一下你的评论吧 !
