

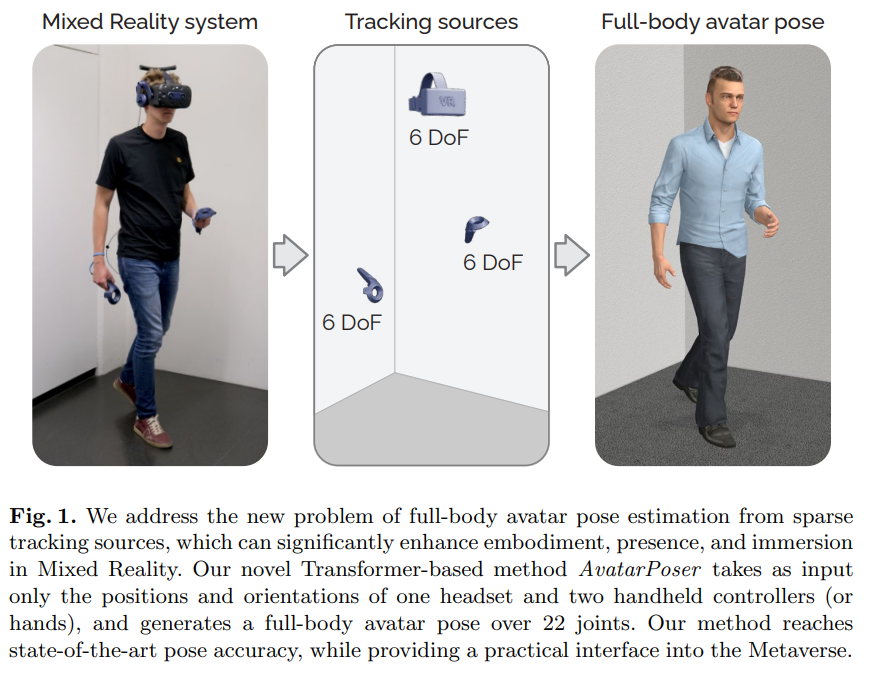
可全身位姿估计与追踪的VR方案
vr|ar|虚拟现实
描述
来自苏黎世联邦理工学院和 Meta 虚拟现实实验室的研究者联合提出了一个用稀疏运动传感设备进行全身位姿估计与追踪的方案。
近日,Meta Connect 大会上「有腿」的虚拟世界人物形象引起机器学习和VR社区的高度关注。人们意识到,在构建元宇宙的美好愿景中,虚拟形象的生动逼真是非常重要的。

Meta Connect 大会上扎克伯格展示了自己的虚拟形象。
以前,虚拟人物形象通常只有上半身,这严重破坏了用户的沉浸感,降低了整体的使用体验。

为了解决这个问题,来自苏黎世联邦理工学院 (ETH Zurich) 和 Meta 虚拟现实实验室 (Reality Labs at Meta) 的学者联手提出了 AvatarPoser,一个用稀疏运动传感设备进行全身位姿估计与追踪的方案。该工作被计算机视觉顶会 ECCV 2022 接收,论文和代码均已开源。

论文链接:https://arxiv.org/abs/2207.13784
代码链接:https://github.com/eth-siplab/AvatarPoser
研究背景
当前的混合现实头戴式显示器和手持控制器可以追踪用户在现实世界中的头部和手的位置和姿势,以便用户在增强现实和虚拟现实场景中进行交互。虽然这足以支持用户提供输入信息,但是通常只将用户的虚拟形象局限于上半身。因此,当前 VR 系统只能提供浮动的虚拟形象,其局限性在协作环境中尤为明显。为了使用稀疏输入源估计全身姿势,先前的工作在腰或腿脚位置加入了额外的追踪器和传感器,但这增加了设备的复杂性并限制了实际应用的便携性。
AvatarPoser 是第一个基于深度学习来通过用户头部和手部的运动输入来预测世界坐标中的全身姿态的方法。该研究用 Transformer 编码器从输入信号中提取深度特征,并将人体的全局运动与局部关节运动解耦,以引导整体的姿态估计。此外,作者还将 Transformer 和逆运动学结合,来优化手臂关节的位置,以匹配手的真实位置。在作者的实验评估中,AvatarPoser 在大型动作捕捉数据集 AMASS 的评估中取得了最佳结果。该方法的极快的推理速度也支持实时操作,提供了一个实用的接口来支持元界应用的整体的虚拟人表示和控制。
相关工作
文章和此前的相关工作 Final IK, LoBSTr (Eurographics 2021), CoolMoves (IMWUT 2021), VAE-HMD (ICCV 2021)进行了比较。Final IK 是基于物理模型的标准商业解决方案。然而,它只能给出中性的下半身位置,因此产生了看起来不真实的运动预测。LoBSTr 使用 GRU 模型根据头部、手部和腰部的跟踪信号预测下半身,并通过 IK 求解器计算上半身姿势。
但是,这种方法需要额外的腰部跟踪器。CoolMoves 是第一个只使用来自头戴式设备和手控制器的输入来估计全身姿势的方法。然而,所提出的基于 KNN 的方法只能在小数据中插值估计姿势,且需要运动类型已知。VAE-HMD 是最近提出的一种基于 VAE 的方法,可以从稀疏输入中生成合理且多样化的身体姿势。然而,该方法所使用的信息都是相对于与腰部位置的,这相当于使用了腰部的位置作为第四个输入。因此,用稀疏传感设备追踪虚拟人全身的方法主要存在三个局限性:
(1) 大多数通用商用程序使用逆向运动学(IK)来估计全身姿势。这通常会产生看似静态且不自然的人体运动,尤其是对于远离运动链中已知关节位置的那些关节。
(2) 尽管目标是仅使用来自头部和手部的输入,但现有的基于深度学习的方法隐含地使用了腰部姿势的信息。然而,大多数便携式混合现实系统无法进行腰部跟踪,这增加了全身估计的难度。
(3) 即使使用腰部追踪设备,先前方法估计的下半身动画也会经常包含抖动和滑动伪影。这些往往是由腰部跟踪器的无意运动引起的,该跟踪器连接在腹部,因此与实际腰部关节的移动方式不同。
方法介绍
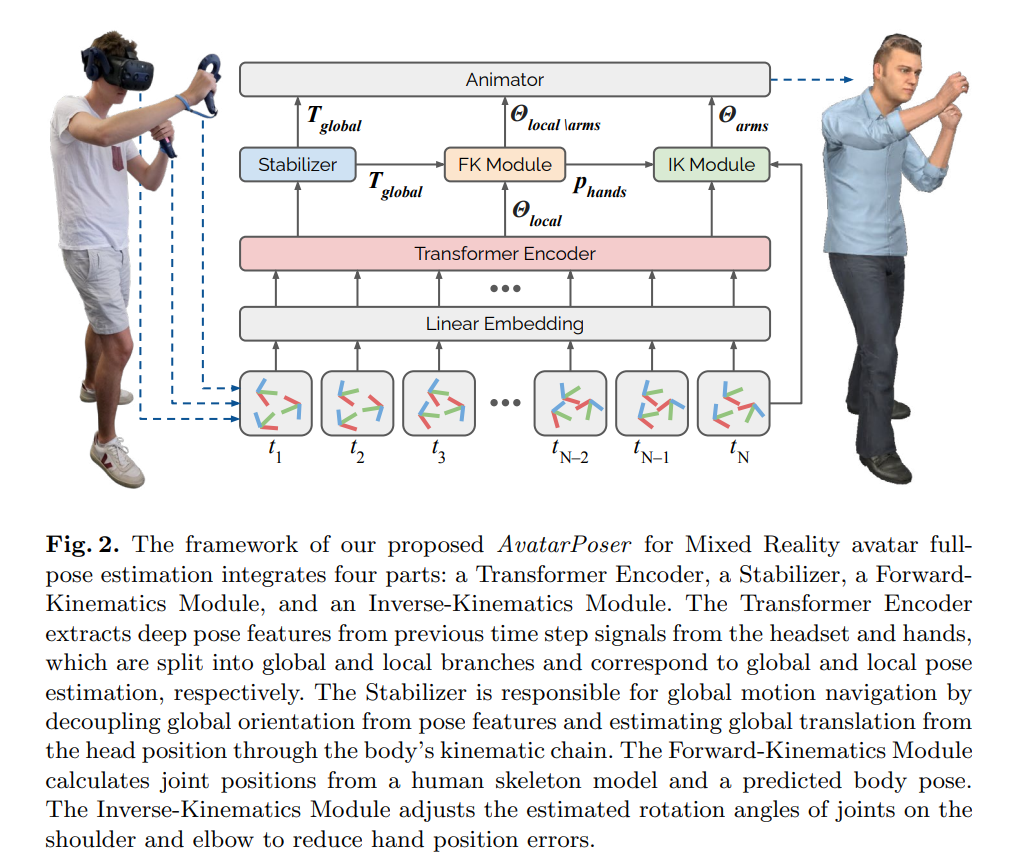
AvatarPoser 的整体框架如图 2 所示。这是一个时间序列的网络结构,它将来自稀疏跟踪器的前 N - 1 帧和当前第 N 帧的 6D 信号作为输入,并预测人体的全局方向以及每个关节相对于其父节点的局部相对旋转。具体来说,AvatarPoser 由四个组件组成:Transformer 编码器、稳定器、正向运动学 (FK) 模块和逆向运动学 (IK) 模块。作者设计的网络使得每个组件都可以解决特定的任务。
Transformer 编码器: 由于 Transformer 在效率、可扩展性和长距离建模能力方面具有优势,本文的方法建立在其基础上,从时间序列数据中提取有用的信息,用自注意力 (self-attention) 机制来清楚地捕获数据中的全局远程依赖关系。具体来说,给定输入信号,首先应用线性嵌入将特征丰富到 256 维。接下来,Transformer 编码器从头显和手部的先前时间步长中提取深度姿势特征,这些特征分别由用于全局运动预测的稳定器和用于局部姿势估计的 2 层多层感知器 (MLP) 共享。Transformer 中的 head 的数量设置为 8,自注意力层的数量设置为 3。
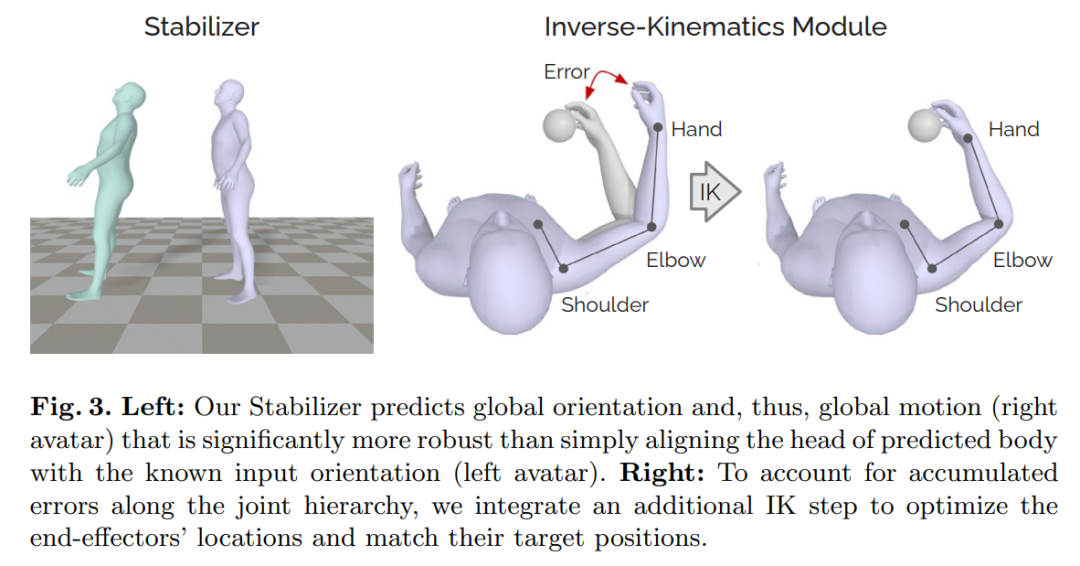
稳定器 Stabilizer: 稳定器是一个 2 层多层感知机,它接受来自 Transformer 编码器生成的 256 维姿势特征作为输入,负责输出人体的全局运动方向(也是腰部的旋转方向)。因此,稳定器通过将全局方向与姿势特征解耦并通过身体运动链从头部位置获得全局平移来负责全局运动导航。尽管通过运动链从给定的头部姿势计算全局方向也是一种只管的解决方案,但用户的头部旋转通常独立于其他关节的运动, 因此这种方法会导致估计的整体方向对头部的旋转很敏感。比如考虑一下用户站着不动,只转动头部的场景,全局方向很可能会有很大的误差,这往往会导致生成的虚拟人浮动在空中,如图 3 的左边图所示。
正向运动学 (FK) 模块:正向运动学 (FK) 模块将预测的局部旋转作为输入,计算给定人体骨骼模型的所有关节位置。虽然基于旋转的方法无需重新投影到骨架约束以避免骨骼拉伸和无效配置即可提供稳健的结果,但它们容易沿着运动链累积位置误差。在没有 FK 模块的情况下训练网络只能最小化关节旋转角度,但不会在优化过程中考虑实际产生的关节位置。
逆向运动学模块:基于旋转的姿态估计的一个主要问题是末端执行器的预测可能会偏离它们的实际位置——即使末端执行器用作已知输入,例如 VR 场景中的手。这是因为对于末端执行器,误差会沿着运动链累积。然而,准确估计末端执行器的位置在混合现实中尤为重要,因为手通常用于提供用户的输入信息,即使是位置上的小误差也会严重干扰与虚拟界面元素的交互。为了解决这个问题,本文采用了一个单独的 IK 模块,该算法根据已知的手部位置调整手臂肢体位置。具体来说,在网络产生输出后,IK 模块会调整肩部和肘部关节的估计旋转角度,以减少手部位置的误差,如图 3 的右图所示。
实验
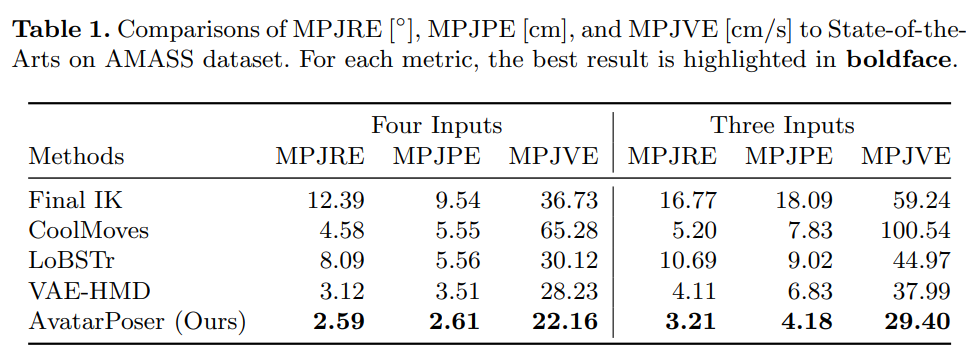
作者评估了三个和四个输入的不同方法。评估指标是平均每个关节旋转误差 (MPJRE)、位置误差(MPJPE) 和速度误差(MPJVE)。实验表明,AvatarPoser 在两种设置中都实现了 SOTA 的性能。
表 1 报告了四个和三个输入的所考虑指标(MPJRE、MPJPE 和 MPJVE)的数值结果。可以看出,AvatarPoser 在所有三个指标上都取得了最佳结果,并且显著优于所有其他方法, VAE-HMD 在 MPJPE 上取得了第二好的性能,紧随其后的是 CoolMoves。Final IK 在 MPJPE 和 MPJRE 上给出了最差的结果,因为它为了优化末端执行器的位置和姿势,没有考虑到其他身体关节的位置和平滑度。因此,使用 Final IK 进行上身姿态估计的 LoBSTr 的性能也很低。作者表示这显示了用数据驱动方法从现有动作捕捉数据集中学习人体运动的价值。但是,这并不意味着传统的优化方法没有用,作者的消融研究中展示了逆向运动学与深度学习相结合如何提高手部位置的准确性。
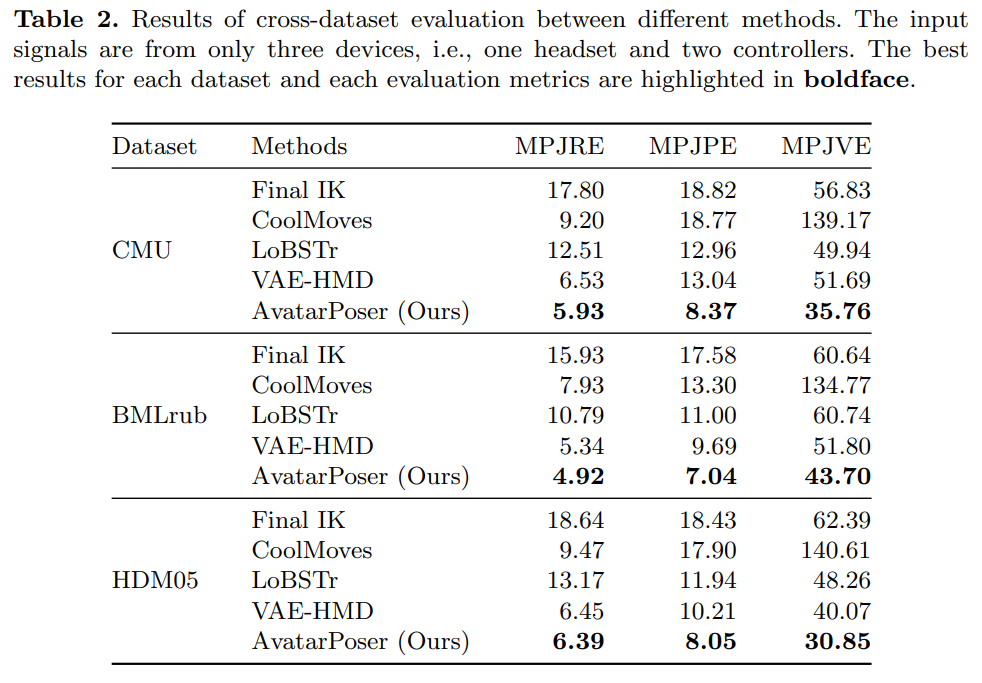
为了进一步评估提出的方法的泛化能力,作者在不同方法之间进行了跨数据集评估。为此,作者在两个子集上进行训练,在另一个子集进行测试。表 2 显示了在 CMU、BMLrub 和 HDM05 数据集上测试的不同方法的实验结果。AvatarPoser 再次在所有三个数据集中的所有评估指标上都取得了最好的结果。
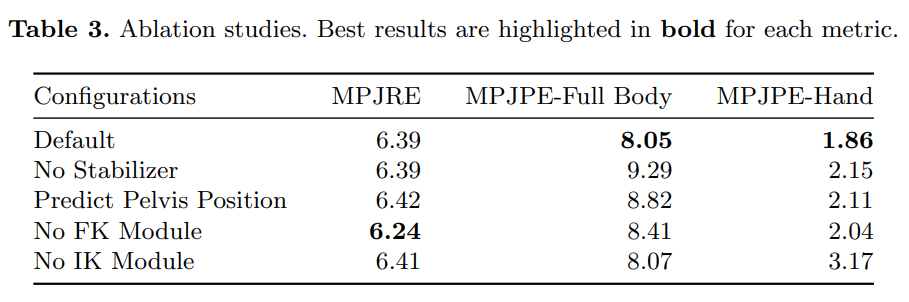
作者还对不同子模块进行消融研究,并在表 3 中提供结果。实验是在与表 2 中的 HDM05 相同的测试集上进行的。评价指标为 MPJRE [◦]和 MPJPE [cm] 。除了全身关节的位置误差外,作者还计算了手部位置的平均误差,以体现 IK 模块如何帮助改善手的位置。
此外,作者还给出了方法对比的视频,有移动,锻炼,投掷 3 个示例,黄颜色代表误差,可以说 AvatarPoser 的结果是一骑绝尘,非常丝滑了!
AvatarPoser 也可以在流行的 VR 系统上很好地工作,尽管训练时只使用了合成的动作捕捉数据。作者在 VIVE Pro 头显和两个控制器上进行测试,如视频所示,AvatarPoser 对各种运动类型(如步行、坐着、站立、跑步、跳跃和蹲下)都具有稳定优秀的性能。
总结
这篇论文展示了全新的基于 Transformer 的方法 AvatarPoser,仅通过混合现实头显和手持控制器的运动信号来估计真实的人体姿态。AvatarPoser 通过将全局运动信息与学习的姿势特征解耦并使用它来引导姿态估计,在没有腰部信号的情况下获得了稳健的估计结果。此外,通过将基于学习的方法与传统的基于模型的优化相结合,该方法在全身风格的真实感和准确的手控之间保持平衡。AvatarPoser 在 AMASS 数据集上的大量实验表明其不仅取得了 SOTA 的性能,更为实际的 VR/AR 应用提供了一个实用的解决方案。
编辑:黄飞
-
Meta用头显实现全身动作追踪!没有腿部信息,也可准确估计姿态2023-07-19 1700
-
常见位姿估计算法的比较:三角测量、PNP、ICP2023-06-07 1005
-
如何去使用深度学习的model SLAM位姿估计的自训练方法2023-03-29 1456
-
仅需580元!自制VR全身追踪器 第二期 slimevr 全中文教程 高精度全身追踪 owotrack-2露露Mikuru 2022-02-21
-
VR/AR头盔中可预测追踪技术的原理分析2020-04-06 1774
-
浅析VR/AR头盔的可预测追踪技术2020-01-24 1124
-
Driver4VR+微软Kinect,实现最低成本的全身追踪2018-11-30 814
-
Holosuit套装结合AR和VR实现全身动作追踪,感受科技如此强大2018-08-07 1730
-
AR/VR全身追踪,HoloSuit套装到底有啥独特之处2018-08-01 3977
-
VR光学跟踪方案之“Lighthouse”追踪系统技术2017-10-09 1642
-
基于MIMUGPS的动中通航姿估计姚若晨2017-03-17 699
全部0条评论

快来发表一下你的评论吧 !
