

基于网络测试与验证
描述
01 背景
数据平面验证技术可以通过验证设备的数据平面来检测网络错误,尽可能减少网络错误带来的代价,这也是减少网络中断的一种重要技术。目前,数据平面验证工具已经做到了在微秒级别上实现数据平面的增量更新的验证。虽然研究人员在实现快速数据平面验证方面取得了重大进展,但是现有的数据平面验证技术无法有效处理大规模网络的更新风暴场景(短时间内发生大量数据平面更新)和长尾更新场景(有些交换机的更新需要很长时间到达)。原因:现有的数据平面技术处理大型数据中心的更新风暴场景往往需要耗费数小时,甚至更长时间;而由于有些数据平面更新需要经过一段延迟时间才能到达,那很可能导致验证者使用不完整不一致的数据平面来验证,进而得到的验证结果也是不正确的。
02 设计
针对上述两种场景或者当两种场景同时存在,作者提出了Flash,它可以针对更新风暴、长尾更新或两者都存在时的场景实现快速、一致的数据平面验证。Flash引入了快速逆模型转换(Fast IMT)以有效地处理更新风暴,引入了早期检测机制以处理长尾更新场景。接下来我们将阐述Flash的工作流程和两种关键技术(Fast IMT、早期检测机制)。
下图是Flash的架构示意图和工作流程图。其中有2个关键组成部分:子空间验证器、CE2D(consistent, efficient early detection)调度器。子空间验证器接收FIB更新,重建数据平面状态,并验证是否违反了属性,可以专门用作大规模网络的数据平面验证。它与CE2D调度器协作来保证早期检测的一致性和正确性。CE2D调度器有两个职责。首先,它负责管理子空间验证器的生命周期,即创建、破坏和重新配置。其次,CE2D调度器负责根据 epoch-verifier映射将FIB更新转发到子空间验证器。
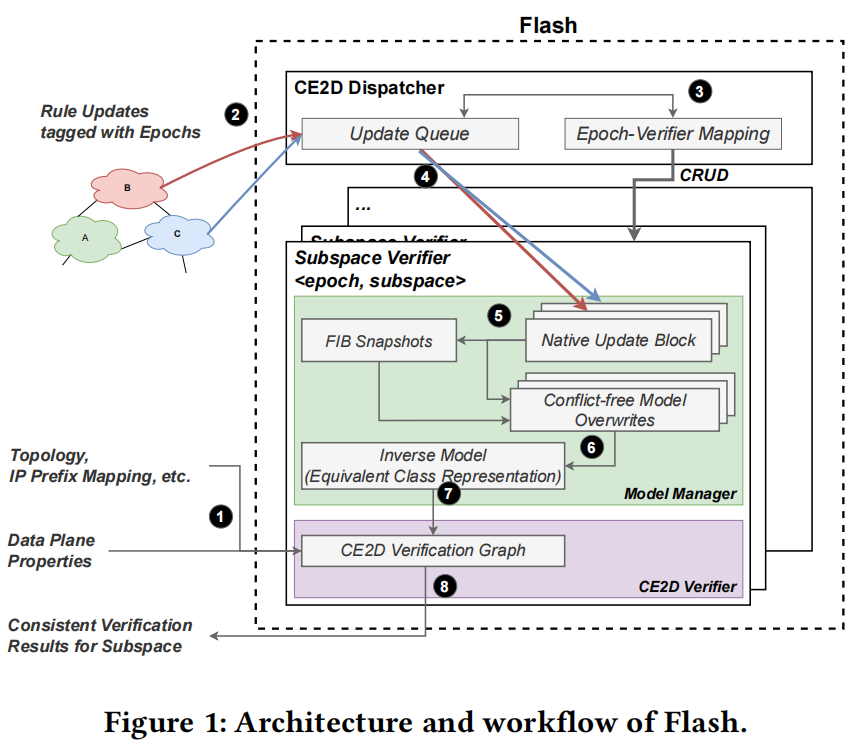
使用Flash系统的典型工作流程如上图所示。
1)输入:基于正则表达式的规范语言来指定验证要求,即要验证的数据平面属性。构建CE2D验证图还需要进行网络拓扑和IP前缀映射等静态配置。
2)在系统启动并运行后,它可以从路由器、代理或网络模拟器接收FIB更新。为了获得一致的早期检测结果,这些FIB更新应该使用epoch标记。
3)在从设备接收到新epoch后,CE2D调度程序找到epoch过时的子空间验证器,停止执行,并重新配置它们以验证最新epoch。
4)更新epoch-verifier映射,并相应地转发FIB更新。
5)每个子空间验证器都维护一个逆模型,即数据平面的等价类表示。当子空间验证器接收到新的FIB更新时,它首先将它们分派到块中,这些块使用Fast IMT覆盖计算最新的FIB快照。
6)通过无冲突逆模型覆盖,获得与新的FIB快照相一致的最新逆模型。
7)利用逆模型,CE2D验证器对CE2D验证图进行更新,并应用早期检测算法。
8)如果返回一个确定性结果,验证者将返回子空间的一致的验证结果。
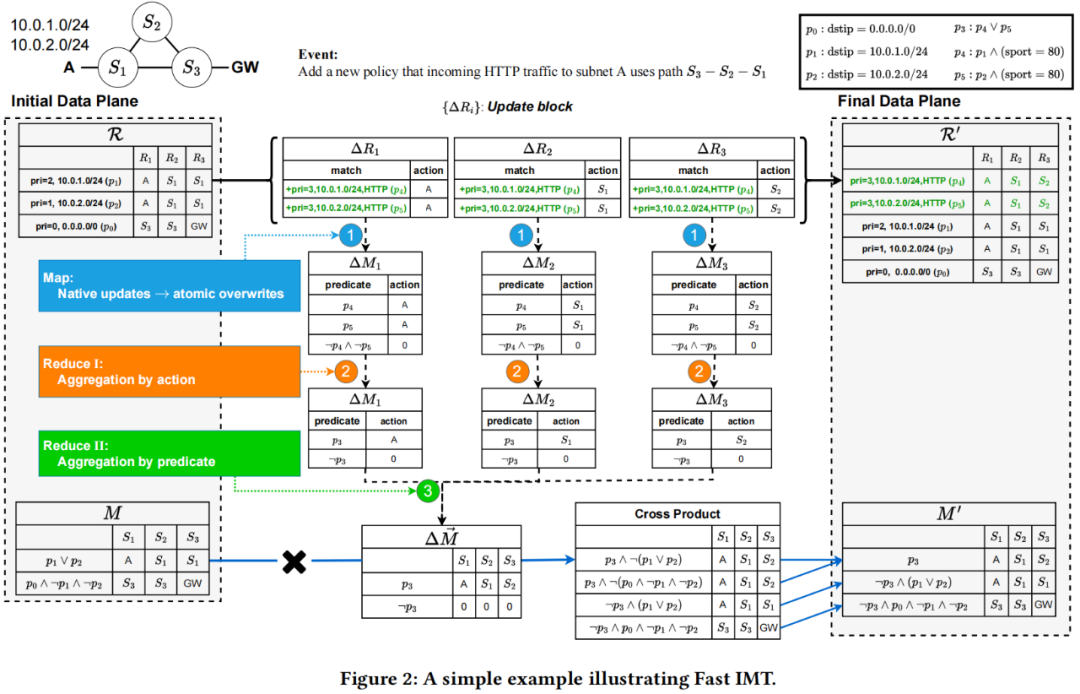
下图为Fast IMT的简单示例。Fast IMT首先使用一种基于合并的高效算法,将大量native更新分解为一组可组合的更新(atomic conflict-free overwrites)。然后,它通过MR2(Map-Reduce-Reduce)算法生成紧凑的conflict-free overwrites,用于更新inverse模型。Map: 在考虑到更高优先级规则后,将每个更新匹配的数据包集替换为将由其处理的确切数据包集;Reduce-Reduce:这些更新先通过它们执行的动作进行聚合,再通过它们匹配的数据包集进行聚合。将MR2(map-reduce-reduce)算法与子空间划分、重叠规则的快速查找和持久动作树等结合,Fast IMT大大降低了计算开销,实现了高可伸缩性。
早期检测机制:Flash使用epoch区分从不同网络状态计算的FIB更新,并对构造给一个epoch中的同步设备的模型应用早期检测机制,同步设备的FIB的计算依据相同的的网络状态。然后利用自动机理论提出新算法以实现有效的早期检测。
03 性能评估
作者在更新风暴或者长尾更新(或者二者同时存在)场景下对Flash进行广泛的评估。其中,利用大规模网络的数据平面,与最先进的顺序验证更新的数据平面验证系统相比,Flash要快9000倍。但在许多情况下,Flash还是比Delta-net要慢。
04 个人观点
优点:
为了在更新风暴下有效地执行验证,Flash引入了快速逆模型变换,亮点在于不将单个数据平面更新逐个合并到数据平面模型中,而是将大量native更新分解为一组可组合的更新。此外,为了在长尾更新下有效地执行验证,Flash引入的早期检测机制能够在无法获取完整的数据平面情况下进行一致、正确的数据平面验证,这是其他数据平面验证工具做不到的。
不足:
1)文中提到的更新风暴和长尾更新情况本质上是由于数据平面验证工具所采用的集中式架构所导致的,Flash仍然采用了这一架构,在这种集中式架构下,验证器会成为性能瓶颈和单一故障点,因此,无论在大型数据中心还是广域网上,拓展性与实用性都会受到限制。相比之下,本团队最近提出的分布式设备自验证框架Coral(已被HotNets‘22接收,长文版本详见https://arxiv.org/abs/2205.07808),通过将算力/内存密集型的验证计算分解为轻量、设备级验证子任务,下放到网络设备上分布式执行,可以实现大规模网络数据平面的网内快速自检。
2)在更新风暴场景下,Flash使用的批处理技术与最近的研究DNA(NSDI 2022)非常相似,其核心创新并没有在文中体现出来。
3) Flash对数据平面验证标称的最多9000倍的加速效果,有非常大的一部分来自于Libra(NSDI 2014)提出的报文空间分区,去除这一部分之后,Flash的加速效果并不高。
4)Flash是否能实现packet transformer等功能以及是否仍然具备高性能和低开销,这是不可知的。
5)个人认为早期检测机制只适用于少数长尾更新场景。
6)性能上,在许多情况下,Flash还是比Delta-net慢。
7)Fast IMT把一组native updates进行分解后map与2次reduce,个人认为这个过程在某些场景下会很耗时,而且最终reduce效果不佳。
01 背景
网络验证通常需要在不同故障模型(确定性和/或概率性)下分析不同空间(报头空间、故障空间或产品流量空间)的属性。现有的验证器可以高效地处理报头或故障空间,但不能两者兼顾;或者同样高效地处理确定性和概率性的链路故障场景验证,但仍不能兼顾。也就是说,目前没有一个单一的验证器可以同时支持不同的空间覆盖度和不确定性故障模型的分析。于是本文提出了一种基于符号执行的路由计算SRE(Symbolic Router Execution),一种支持各种分析场景的通用可扩展的验证引擎。SRE可以符号化地模拟网络模型从而发现报文故障等价类(PFECs),每个PFEC都表示一种在特定故障场景下的具有相同转发行为的报头空间。此外,SRE在符号执行期间支持各种优化,同时保持对故障种类的不可知性,因此它可以扩展到其他种类的包空间。通过二元决策树BDD对报头空间和故障场景进行编码,各类网络验证就可以简化为BDD上的图算法执行(例如,最短路径)。
02 设计
SRE Workflow:SRE通过对链路状态以及报头空间进行符号化计算得到不确定报头空间在不确定链路故障情况下的转发表。如下图, 每一条转发表项都包含了相应的前缀和链路状态信息(即满足约束的目的IP和链路状态条件下才会匹配该表项)。计算这样的转发表包含两个步骤:一是对故障状态做符号执行计算控制平面,即计算不同目的网段在不同的链路故障情况下的转发表(类似Hoyan);二是对IP做符号化执行计算数据面,根据符号化的转发表和配置的ACL计算具有相同转发行为的报文集合(类似AP)。至此就可以得到PFECs,最后把所有的PFECs合并成BDD,则可以将属性验证转化成图算法求解。
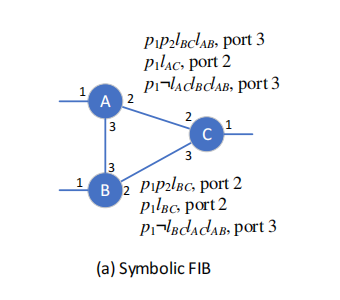
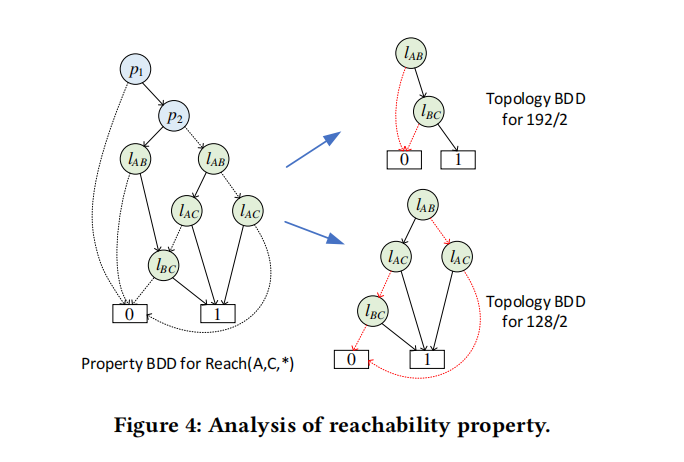
SRE的属性验证:SRE将所有满足/不满足属性的PFECs转换成BDD树来验证,每一条到达验证节点的BDD路径都表示了一种在相同链路状态条件下的具有相同转发行为的包空间集合,如图上所示。然后利用图算法可以实现故障场景分析、满足可能性分析以及差分分析。
03 个人观点
SRE利用程序分析中的符号执行技术实现了一种通用的针对网络故障场景分析方法。在验证中引入了不确定性,使得流量分析结果更精确(但不能实现一些交叉流量分析),同时验证的时间开销也增长了,但由于只需符号化部分变量,所以开销相较Minesweeper这类纯SMT的验证器耗时仍然较少。这篇文章通过符号化技术结合了数据面验证和控制面验证的优点,达到了较好的平衡。
01 背景
数据平面特定领域编程语言P4在应用场景下经常伴随一些错误。这些错误可以进一步细分为代码逻辑错误、编译器错误和ASIC错误。调查显示40%的错误与编译器或ASIC有关(non-code bugs)。目前的p4验证工具(如:Aquila、p4pktgen等)倾向于验证代码相关错误,而对于非代码错误研究较少。
同时,生产级的应用场景会带来规模上的挑战:例如复杂的控制流图、多流水线、多交换机的情况。在一些网关的生产级程序中,代码数量达到了o(10^14),可能的路径数达到了o(10^197)。面对如此复杂的程序应该如何进行遍历,以达到100%的路径覆盖率同样也成为很大的挑战。
02 设计
Meissa采用的核心方法是Code Summary。Code Summary是领域特定的,利用了控制流图中每个流水线都是单起点单终点的特性。总体上来讲可以分为流水线内的冗余消除和流水线间的公共前置条件过滤。
1)流水线内的冗余消除(intra-pipeline redundancy elimination):使用DFS搜索遍历流水线内部的路径,选择其中的合法路径,同时在过程中收集路径的语义。这种做法的效果在于1.将一个流水线中本来不合法的路径删除以免被其他流水线重复计算;2.可以缩短合法路径的长度。
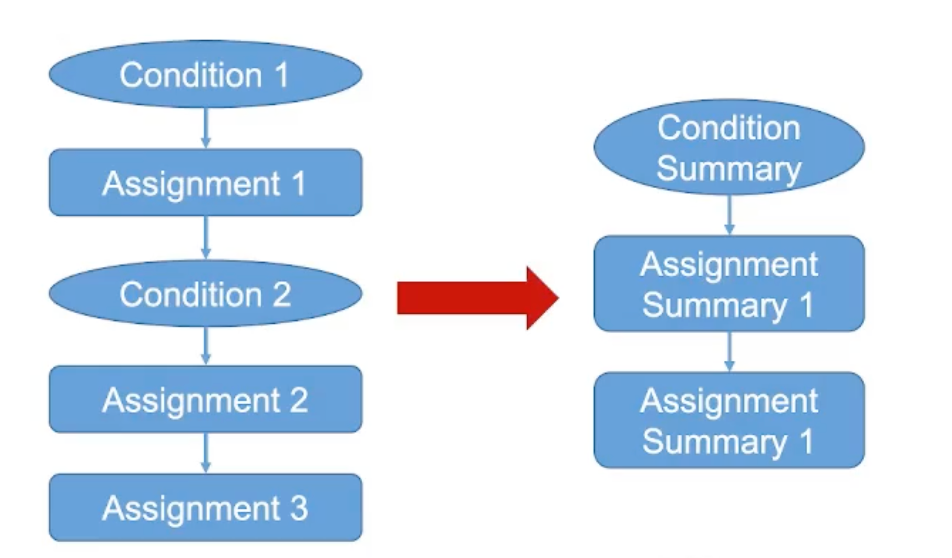
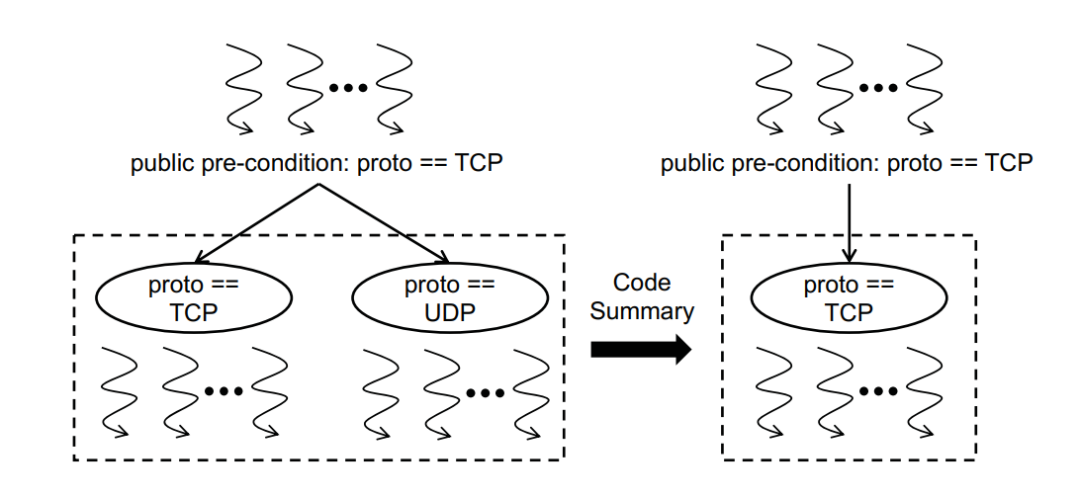
2)流水线间的公共前置条件过滤(inter-pipeline public pre-condition filtering):公共前置条件是指从整个控制流图开始到这个流水线入口处所有可行的合法路径中共同包含的一些条件。对于下图中的情况,由于前置流水线将所有协议统一为TCP,在本流水线中就不需要考虑UDP协议的情况。
对于整体框架而言,用户需要输入P4代码、对于表项的设置值以及测试意图。之后通过拓扑排序确定Code Summary的顺序。在对于每一个流水线进行冗余消除和公共前置条件过滤后得到彻底化简的CFG。通过对CFG的DFS搜索可以得到全部的测试样例,将测试样例跑在真实的交换机上即可获得compiler path 以及 ASIC path以定位非代码逻辑错误。
03 性能评估
实验显示Code Summary 能够在1.2–5.0x的范围内加速Meissa的性能,通过Code Summary能够减少SMT solver 1.8–14.9x 的调用频率,同时对于不同的P4程序减少了10^60–10^390x的需遍历路径数量。
04 个人观点
本文的创新点主要在于:
1)对p4复杂的控制流图进行了高效的剪枝操作,通过流水线内的冗余消除和流水线间的公共前置条件过滤,极大地简化了控制流图。与此同时还保持了高精确性(100\%的路径覆盖)。
2)考虑到了p4错误验证中的非代码错误(来自编译器或ASIC),通过将简化CFG的搜索结果和实际交换机测试结果进行对比以定位此类错误,很好地弥补了有关领域研究中的不足。
这篇文章提出了SwitchV,一种自动化的SDN交换机验证工具,主要由谷歌团队实现,合作者来自于布朗大学和哈佛大学等高校,其中包括哈佛大学的俞敏岚教授。
01 背景
随着对计算机网络的可靠性、灵活性以及效率等需求的不断增加,促使制造商和运营商加速设计与实施新的特性的功能。但是,在增加新的功能的同时,需要根据非规范文档进行手工编写大量的测试以保证可靠性,限制了新功能的开发效率。因此,本文旨在实现一种工具,帮助在保证可靠性的同时,能够实现新功能的快速开发。
02 设计
为实现该目标,文章提出了SwitchV,整体思想是使用P4语言建模交换机行为,然后基于P4程序使用测试技术完成控制平面和数据平面的验证,可以分为3个步骤实现:
1) 使用P4编程语言建模交换机行为:P4编程语言原本是用来控制网络设备的数据平面转发行为的,但作者发现P4的语言特性非常适合表达交换机行为,而且可以进一步使用符号执行技术。此外,P4程序可以直接作为网络交换机的文档,相比于非规范文档更加适合功能创新。由于P4语言缺少约束的定义,作者扩展实现了P4-constraints,可以用于建模Isolated或Integrity方面的约束。
2)控制平面验证:提出了一个模糊测试工具(Fuzzer)用于检查交换机是否会正确接收或拒绝控制平面请求。Fuzzer首先根据P4程序生成许多有效(valid)或无效(invalid)的控制平面更新请求,然后发送这些更新请求,并观察交换机是否会正确处理。其中,有效和无效是相对于P4程序中的约束而言,且文中提出了一些优化方法用于处理状态爆炸问题。
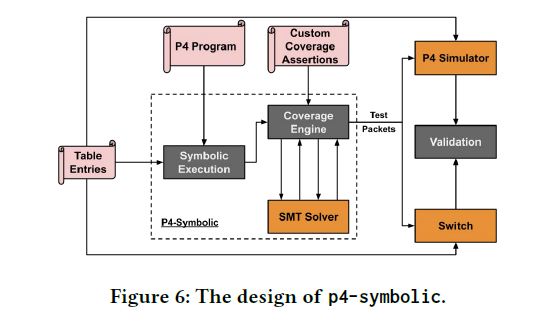
3)数据平面验证:提出了P4-SYMBOLIC,通过比对P4模拟器和真实交换机的转发行为,完成数据平面验证。P4-SYMBOLIC运行流程如图所示,测试人员首先输入P4程序、表条目以及最小覆盖范围,然后基于P4程序使用符号执行技术分析控制流,如果符号执行结果满足覆盖约束,则生成测试数据包发送到模拟器和真实交换机,通过比对转发行为完成验证。
03 性能评估
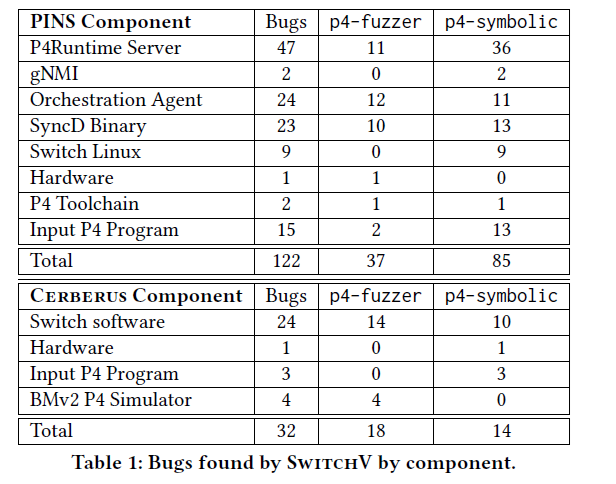
SwitchV已经在谷歌的实际网络中部署运行,实验结果表明SwitchV可以发现出多种类型的错误(如图所示),且许多错误不能被传统的测试技术发现。性能方面,在生产网络中,整个测试过程可以以秒级速度完成,且最慢的是SMT求解过程。
04 个人观点
本篇文章创新性地使用了P4语言建模交换机行为,相比以往采用的英文文档描述方法,P4语言更加规范易读而且利于未来的迭代开发。在其基础之上,SwitchV使用自动化测试技术(fuzz,符号执行)对交换机的控制平面与数据平面进行验证,以保证交换机行为的正确性,相比以往采用的手工测试套件,具有更高的可靠性和效率。不过,SwitchV也存在一定的局限性,例如需要人工将交换机行为抽象成P4程序;只支持部分P4语言特性;测试技术无法完全保证正确性等。
01 背景
在实际物理测试平台中,整个系统中端到端时延的测量对网络系统的评估具有有重大意义,但往往很难取得。现存的模拟软件(ns-2, ns-3, OMNet+等)由于不支持所有的组件,或不支持某些技术细节,同样也很难实现端到端测量。本文旨在提出一种模块化的模拟测试工具,灵活的将各种组件(内存、处理器、多种设备、网络)专属的模拟器组合在一起,搭建了能够实现端到端测量的测试平台。
02 设计
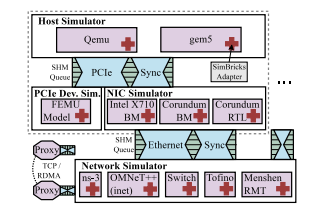
不同于重新构建一个模拟器的思路,simBricks 选择将现存的一些模拟器整合为一个支持不同操作系统、驱动和具体应用的全系统模拟器。
主要面临以下困难:1) 不同模拟器之间没有相互调用接口。2) 模块间实现同步困难 。3) 需要将不兼容的模块进行整合。
simBricks根据实际物理设备的边界(PCIe and Ethernet links)来定义接口,每个模块都由独立、并行的进程运行,通过共享内存队列进行交流。simBricks设计了一个针对模拟器之间拓扑关系和时延,用来进行时钟同步的协议。同时为了实现可扩展性,simBricks引入了代理来基于TCP 或 RDMA传输消息。
03 性能评估
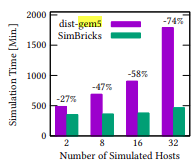
simBricks的模拟实验在以下环境中进行:two 22-core Intel Xeon Gold 6152 processors at 2.10 GHz with 187 GB of memory, hyper-threading disabled, and 100 Gbps Mellanox ConnectX-5 NICs. 模拟中每台主机有单核8G内存,运行 Ubuntu 18.04 with kernel 5.4.46。实验显示simBricks相比于gem5模拟器性能上有较大提升。同时还通过ns-3 默认参数的 network link和SimBricks Ethernet adapter在传输报文的log-level对比,表明simBricks的以太网和PCIe接口能够精确地实现模拟器之间的同步。
04 个人观点
全系统的端到端通信时延测量对于用户体验评估、系统性能瓶颈定位具有实用价值。本文提出的SimBricks是一款高性能、高可扩展性的端到端模拟器,能够精确的同步不同的模拟器组件。SimBricks的主要设计思路在于将现有的模拟器整合到一起,其处理时钟同步以及模块间通信的设计具有相当的工作量。
-
攻击逃逸测试:深度验证网络安全设备的真实防护能力2025-11-17 941
-
RDMA设计50: 如何验证网络嗅探功能?2026-03-31 648
-
网络分析仪可以轻松的应用于设计验证和产线测试2019-07-02 1513
-
片上网络核心芯片的验证2011-01-15 505
-
IC测试技术--设计验证2016-12-14 902
-
是德科技携手诺基亚验证即时测试网络中的5G覆盖2018-11-08 3957
-
福禄克网络宣布扩展LinkIQ™智能链路线缆 + 网络测试仪的网络连接测试功能2022-04-06 3105
-
如何验证Linux系统中网络端口通不通2023-05-12 3640
-
基于UVM验证环境开发测试流程2023-06-09 1913
-
2月22日直播预告|探索TSN时间敏感网络:AVB应用的测试与验证2023-02-16 1617
-
ic验证是封装与测试么?2023-08-24 2040
-
fpga验证和测试的区别2024-03-15 2793
-
5201数据网络测试仪2024-08-20 1245
全部0条评论

快来发表一下你的评论吧 !
