

用于学习对象级、语言感知和语义丰富视觉表征的GLIP模型
描述
简介
问题
Visual recognition 模型通常只能预测一组固定的预先确定的目标类别,这限制了在现实世界的可扩展能力,因为对于新的视觉概念类别和新的任务领域需要新的标注数据。
CLIP可以在大量图像文本对上有效地学习 image-level 的视觉表征,因为大规模匹配的图像文本对包含的视觉概念比任何预定义的概念都更广泛,预训练的CLIP模型语义丰富,可以在 zero-shot 下轻松地迁移到下游的图像分类和文本图像检索任务中。
为了获得对图像的细粒度理解(如目标检测、分割、人体姿态估计、场景理解、动作识别、视觉语言理解),这些任务都非常需要 object-level 的视觉表征。
方案
这篇论文提出了 grounded language-image pretraining (GLIP) 模型,用于学习对象级、语言感知和语义丰富的视觉表征。GLIP将 object detection 和 phrase grounding 结合起来进行预训练。这有两个好处:
GLIP可以同时从 detection 和 grounding 数据中训练学习,以改进两种任务,训练一个优秀的 grounding 模型;
GLIP可以通过 self-training 的方式生成 grounding boxes(即伪标签)来利用大量的图像文本对数据,使学习到的视觉表征具有丰富的语义。
实验上,作者对27M grounding data 进行预训练(包括3M人工注释和24M网络爬取的图像文本对)。训练学习到的视觉表征在各种目标级别的识别任务中都具有较强的zero/few shot迁移能力。
当直接在COCO和LVIS上评估(预训练期间没有训练COCO中的图像)时,GLIP分别达到 49.8 AP和 26.9 AP;
当在COCO上进行微调后,在val上达到 60.8 AP,在test-dev上达到 61.5 AP,超过了之前的SoTA模型。
主要贡献
「1、Unifying detection and grounding by reformulating object detection as phrase grounding」
改变了检测模型的输入:不仅输入图像,还输入 text prompt(包含检测任务的所有候选类别)。例如,COCO目标检测任务的 text prompt 是由80个COCO对象类别名组成的文本字符串,如图2(左)所示。通过将 object classification logits 替换为 word-region alignment 分数(例如视觉region和文本token的点积),任何 object detection 模型都可以转换为 grounding 模型,如图2(右)所示。与仅在最后点积操作融合视觉和语言的CLIP不同,GLIP利用跨模态融合操作,具有了深度的跨模态融合的能力。
「2、Scaling up visual concepts with massive image-text data」
给定 grounding 模型(teacher),可以自动生成大量图像-文本对数据的 grounding boxes 来扩充GLIP预训练数据,其中 noun phrases 由NLP解析器检测,图3为两个 boxes 的示例,teacher模型可以定位到困难的概念,如注射器、疫苗、美丽的加勒比海绿松石,甚至抽象的单词(视图)。在这种语义丰富的数据上训练可以生成语义丰富的student模型。
「3、Transfer learning with GLIP: one model for all」
GLIP可以有效的迁移到各种任务中,而只需要很少甚至不需要额外的人工标注。此外,当特定于任务的标注数据可用时,也不必微调整个模型,只需微调特定于任务的 prompt embedding,同时冻结模型参数。
相关工作
标准的 object detection 模型只能推理固定的对象类别,如COCO,而这种人工标注的数据扩展成本很高。GLIP将 object detection 定义为 phrase grounding,可以推广到任何目标检测任务。
CLIP和ALIGN在大规模图像-文本对上进行跨模态对比学习,可以直接进行开放类别的图像分类。GLIP继承了这一研究领域的语义丰富和语言感知的特性,实现了SoTA对象检测性能,并显著提高了对下游检测任务的可迁移能力。
方法
Grounded Language Image Pre-training
在概念上,object detection 与 phrase grounding 具有很大的相似性,它们都寻求对对象进行本地化(即学习到并能检测这种对象的类别),并将其与语义概念对齐。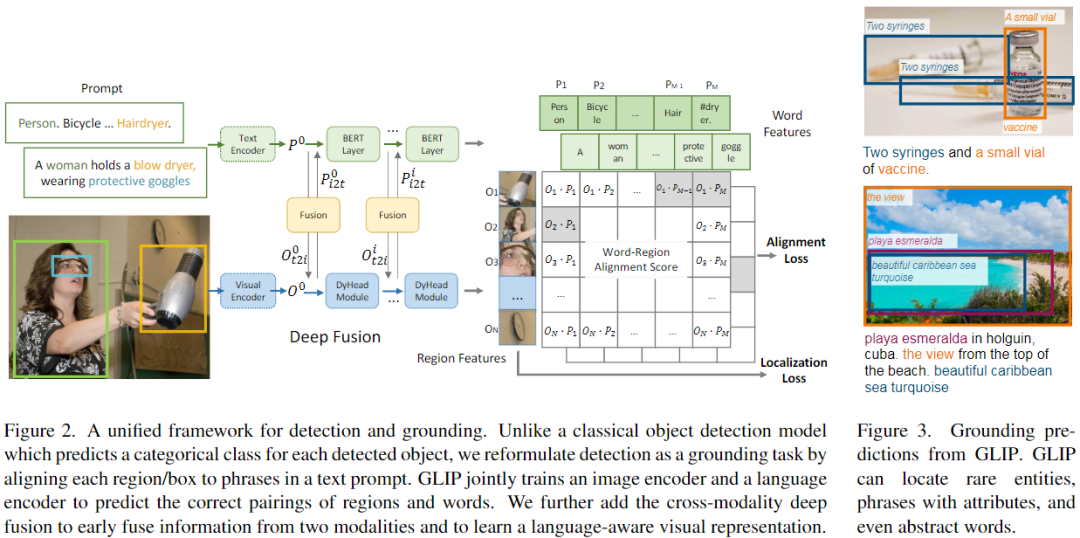
a、Unified Formulation
「Background: object detection」
标准的检测模型将一张图像输入 visual encoder(CNN或Transformer),提取 region/box 特征(图2底部),每个 region/box 特征输入两个 prediction heads,即分类器(分类损失)和回归器(定位损失)。在两阶段检测器中,还有一个分离的RPN层用以区分前景、背景和改善anchors,因为RPN层没有用到目标类别的语义信息,我们将其损失合并到定位损失。
「Object detection as phrase grounding」
作者不是将每个 region/box 分类为c类,而是将检测任务重新定义为一个 grounding 任务,通过将每个 region 与文本 prompt(Prompt = "Detect: person, bicycle, car, ... , toothbrush") 中的c个phrases 进行 grounding/aligning(图2)。在 grounding 模型中,计算图像区域和prompt中的word之间的对齐分数:
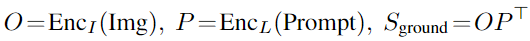
其中 为图像编码器, 为文本编码器,通过 和上一小节提到的分类损失、定位损失,共三个损失端到端进行训练。到这里,会有一个问题,如图2中间所示,子词的数量 是要大于文本 prompt 的 phrases 数量 的,这是因为:
有一些phrase包含多个word,例如‘traffic light’;
一些单词会切分为多个子词,例如‘toothbrush’会切分为‘tooth#’和‘#brush’;
一些token为added token或special token,不属于要识别的类别;
在token词表中会添加一个[NoObj] token。
因此,如果一个phrase是正匹配某个visual region,便将所有子词正匹配,而将所有的added token负匹配所有的visual region,这样将原始的分类损失扩展为。
「Equivalence between detection and grounding」
通过上述方法,将任意detection 模型转化为grounding模型,且理论上训练和推理都是等价的。由于语言编码器的自由形式的输入,预训练的phrase grounding模型可以直接应用于任何目标检测任务。
b、Language-Aware Deep Fusion
在公式3中,图像和文本由单独的编码器编码,只在最后融合以计算对齐分数,这种模型为晚期融合模型,而在视觉语言任务中,视觉和语言特征的深度融合是必要的。
因此,作者在图像和语言编码器之间引入了深度融合,融合最后几个编码层中的图像和文本信息,如图2(中)所示。具体来说,当使用DyHead作为图像编码器,BERT作为文本编码器时,深度融合编码器为:
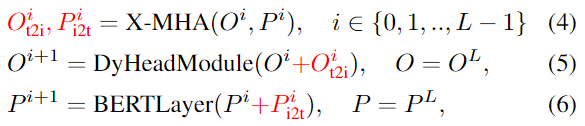
跨模态交互由跨模态多头注意力(X-MHA)(4)实现,然后是单模态融合,并在(5)和(6)中更新。在没有添加上下文向量(视觉模态和语言模态)的情况下,模型即为后期融合模型。
在跨模态多头注意力(XMHA)(4)中,每个head通过关注另一个模态来计算一个模态的上下文向量:
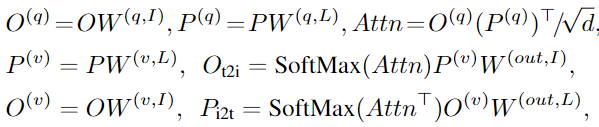
深度融合(4)-(6)有两个好处:
提高了 phrase grounding 性能;
使学习到的视觉表征是语言感知的。
因此模型的预测是以文本prompt为条件的。
c、Pre-training with Scalable Semantic-Rich Data
GLIP模型可以在检测和更重要的grounding数据上进行训练,作者表明,grounding数据可以提供丰富的语义,以促进本地化,可以以self-training的方式扩展。
Grounding 数据涵盖了更多的视觉概念词汇,因此作者扩展了词汇表,几乎涵盖了 grounded captions 中出现的任何概念,例如,Flickr30K包含44,518个惟一的phrase,而VG Caption包含110,689个惟一phrase。
实验
GLIP variants
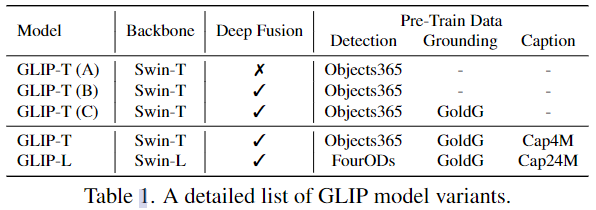
经过预训练,GLIP可以轻松地应用于 grounding 和 detection 任务,在三个基准上显示了强大的域迁移性能:
COCO,包含80个类别;
LVIS包含1000个类别;
Flickr30K用以 phrase grounding任务。
作者训练了5个GLIP变种模型(表1)用以消融,其中GoldG是指0.8M人类标注的grounding数据,包括Flickr30K, VG Caption和GQA,并且已经从数据集中删除了COCO图像,Cap4M和Cap24M是指网络收集的图文对。
a、Zero-Shot and Supervised Transfer on COCO
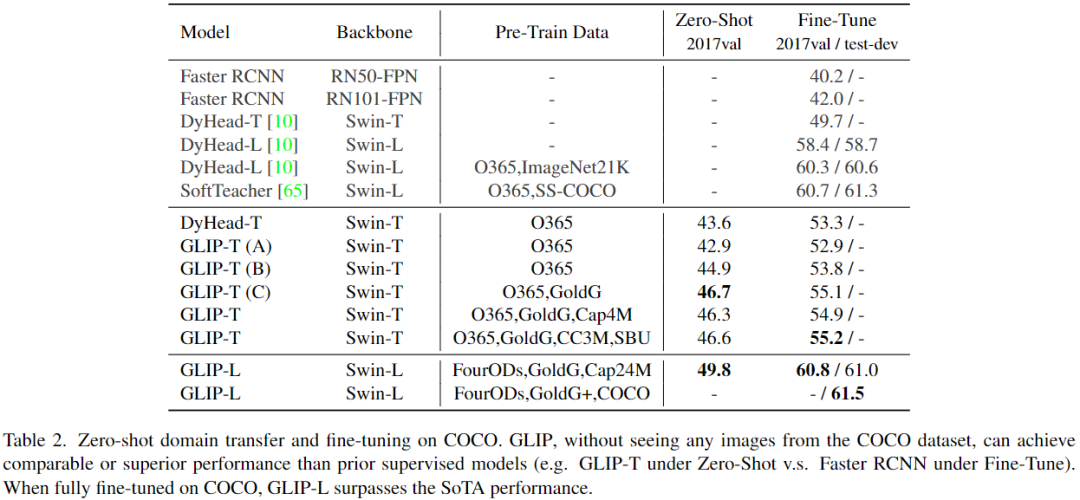
表2可以看到,GLIP模型实现了强大的zero-shot和有监督(即Fine-Tune)性能。GLIP-T(C)达到46.7 AP,超过了Faster RCNN,GLIP-L达到49.8 AP,超过DyHead-T。
在有监督下,GLIP-T比标准DyHead提高5.5 AP (55.2 vs 49.7)。通过swin-large作为主干,GLIP-L超越了COCO上当前的SoTA,在2017val上达到了60.8 AP,在test-dev上达到了61.5 AP。
b、Zero-Shot Transfer on LVIS
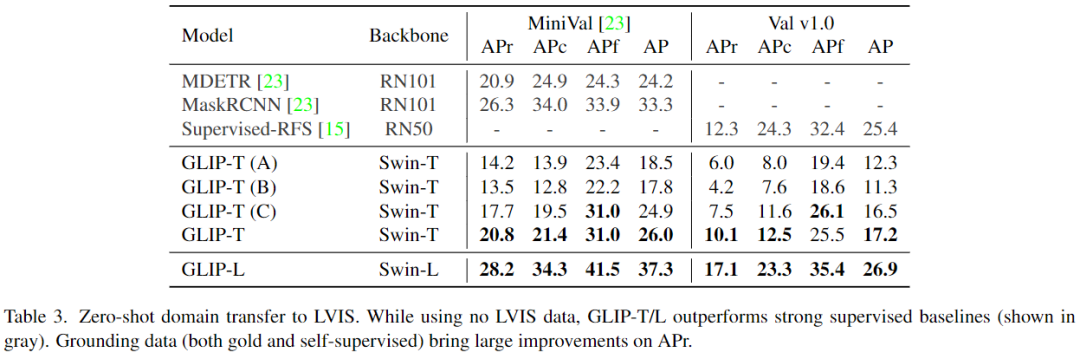
表3可以看到,GLIP在所有类别上都展示了强大的zero-shot性能。
c、Phrase Grounding on Flickr30K Entities
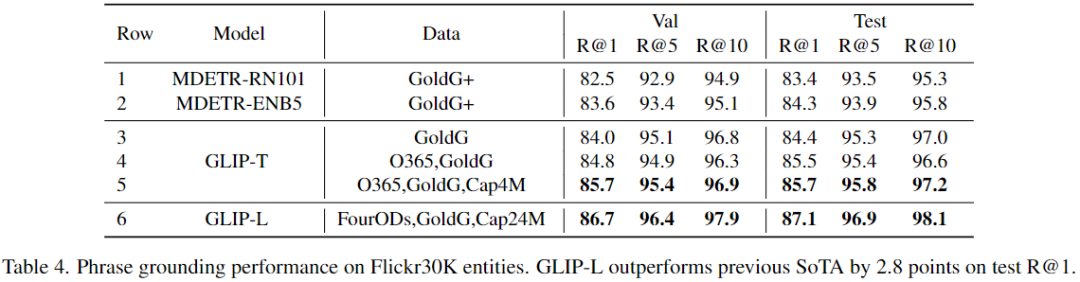
带有GoldG(第3行)的GLIP-T实现了与带有GoldG+的MDETR相似的性能,这是因为引入了Swin Transformer、DyHead模块和深度融合模块。扩展训练数据的(GLIP-L)可以达到87.1 Recall@1,比之前的SoTA高出2.8点。
总结
GLIP将 object detection 和 phrase grounding 任务统一起来,以学习对象级的、语言感知的和语义丰富的视觉表征。在预训练之后,GLIP在完善的基准测试和13个下游任务的zero-shot和fine-tune设置方面显示了有竞争力的结果。
审核编辑:刘清
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 890
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
【《大语言模型应用指南》阅读体验】+ 基础知识学习2024-08-02 3403
-
人工智能多模态与视觉大模型开发实战 - 2026必会2026-04-15 413
-
基于网络本体语言OWL表示模型语义的相似性计算方法2017-12-17 1238
-
语义表征的无监督对比学习:一个新理论框架2019-04-04 3614
-
视觉信号辅助的自然语言文法学习2021-01-05 3190
-
如何通过多模态对比学习增强句子特征学习2022-09-21 2357
-
普通视觉Transformer(ViT)用于语义分割的能力2022-10-31 6646
-
如何利用Transformers了解视觉语言模型2023-03-03 1813
-
大型语言模型能否捕捉到它们所处理和生成的文本中的语义信息2023-05-25 1539
-
视觉深度学习迁移学习训练框架Torchvision介绍2023-09-22 2265
-
图像分割与语义分割中的CNN模型综述2024-07-09 3482
-
利用VLM和MLLMs实现SLAM语义增强2024-12-05 2837
全部0条评论

快来发表一下你的评论吧 !
