

浅谈LLVM LibFuzzer工具和实践
描述
摘要
我们在代码编辑器 (IDE) 中编写源代码,将源代码保存到文本文件中,然后用对应的编译器读取文件、分析代码,并将其翻译成适合目标平台的格式,比如 X86、X86-64、Nvidia-GPU。不同的目标平台涉及的指令集有所不同,拿 X86 指令集来说,总数上千条,如果将每条组合不同的参数一一去验证,可以想象这个工程量有多么的庞大。除了 CPU 指令,GPU 指令也是如此。面对如此复杂的工作,有没有一种强大且智能的测试方式呢?答案是肯定的,它就是出自 LLVM 编译器框架的 LibFuzzer 工具。
利用 LibFuzzer 可以轻松发现程序常见的致命错误,包括不限于这些 crash:堆/栈/全局越界 (OOM)、内存泄漏、未初始化、互斥作用等,这样可以最大限度地发现人为很难发现的问题,提高产品的安全和稳定性。
本文将介绍什么是 Fuzzer、LibFuzzer,如何编译 LLVM-Fuzzer,以及快速写一个 Hello World 目标函数,帮助大家熟悉并了解以上工具的用法、特性和需要注意的问题,提高代码编译的效率。
1什么是 Fuzzing Testing
在编程和软件开发中,Fuzzing 测试是一种自动化的软件测试技术,其核心思想是将自动或半自动生成的随机数据输入到一个程序中,并检测程序异常,如 Crash,Assertion 失败,以尽可能地发现程序错误,比如内存泄漏。Fuzzing 测试常常用于检测软件或计算机系统的安全漏洞。
通常,Fuzzer 用于测试采用参数化输入的程序。例如,在参数一定的前提下,在一个图片编码过程中,区分有效和无效的编码数据,使代码在不同分支下(比如:if…else if),产生不同的结果。无效输入会导致程序得不到正确处理,从而发现问题。
Fuzzer 可以分为以下几类:生成型、突变型,以及前面两种情况的结合-进化型,今天介绍的是最后一种进化型,即 LLVM 自带 LibFuzzer。
2什么是 LibFuzzer
我们先了解下这个强大的编译器框架 LLVM 是什么?
LLVM 是一套编译器和工具链技术,可用于开发任何编程语言的前端和任何指令集架构的后端。LLVM 是围绕独立于语言的中间表示 (IR) 设计的,它作为一种可移植的高级汇编语言,可以通过多次转换进行优化。
LibFuzzer 与被测库链接,并通过特定的 Fuzzy 入口函数 (LLVMFuzzerTestOneInput),又称目标函数,将 Fuzzy 随机生成的参数提供给库;然后,Fuzzer 跟踪到达的代码区域,并在输入数据的主体上生成不同的参数组合,以最大限度地提高代码覆盖率。LibFuzzer 的代码覆盖率信息由 LLVM 的 SanitizerCoverage 工具提供。
LibFuzzer 有 3 个特性:第一个是in-process(进程内),即 LibFuzzer 在 fuzz 时并不是产生出多个进程来分别处理不同的输入,而是将所有的测试数据放入进程的内存空间中。
这有利于进行高效的数据传输。为了提高这种高输入,还可以结合 Google 序列化结构化数据库 protobuf,如 LLVM 里面的 clang-proto-fuzzer 就是这种类型。
第二个特性是coverage-guided(覆盖率)。Fuzzer 测试是随机的,不清楚覆盖了多少代码,那么就可以用这个特性来统计代码覆盖率。
第三个特性就是Evolutionary(进化型), LibFuzzer 不仅可以生成数据,还可以对目前的数据进行突变,如前面讲到的,结合了生成和突变两种形式。
不过这些特性也在一定程度上约束了 LibFuzzer 在某些场景的使用,比如在内存上完成生成、突变作为输入,速度非常快,但需要避免目标函数太大、太复杂,以及不能出现 exit() 函数。
在使用 Fuzzer 进行测试的时候,在编译目标函数时,需要指定 -fsanitize 类型,包括 AddressSanitizer (ASAN),UndefinedBehaviorSanitizer (UBSAN), 以及 MemorySanitizer (MSAN)。
3环境准备
为了能够让更多的程序员使用这个强大的工具,LibFuzzer 是独立的,并不依赖于 LLVM 框架,使用时只需下载对应的库和头文件即可,在 ubuntu , centos 以及 windows 系统中,都可以快速获取到,关键字搜索:llvm-toolset。
不要被 LLVM 编译器这种庞然大物吓到,其实它与其他的编译构建原理类似,下面就以 LLVM 内置的 Fuzzer 为例来进行详细介绍。
首先是克隆 LLVM 的源代码,然后编译 LLVM 和 compile-rt,命令如下。
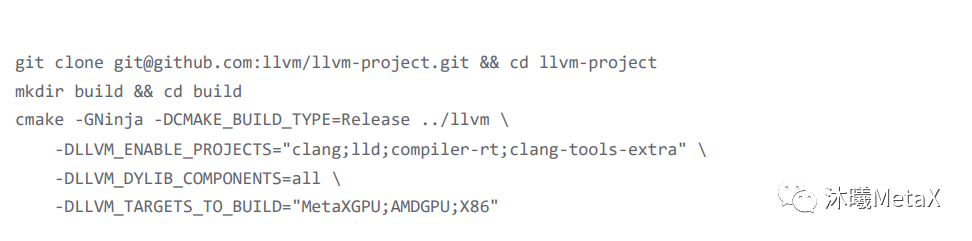
这里推荐编译类型为 Release,因为 debug 的编译实在太慢,通常前者 10 分钟内可以完成,后者大概需要 2 个小时。
如果要用 LLVM 自带的 LLVM-Fuzzer 工具,可以手动编译自带的 Fuzzer 工具,参考下面的命令,编译好之后,在 bin 目录可以找到有 clang-fuzzer、llvm-as-fuzzer、llvm-isel-fuzzer、llvm-mc-fuzzer 等 Fuzzer (模糊测试器),能够用于测试 LLVM 前后端的功能,包括汇编、反汇编、指令选择、优化等等。

值得注意的是需要指定 -DMAKE_C_COMPILER 为上一步编译 LLVM 的 clang 文件,而且是不同的 build 目录。就地取材,用LLVM 工程自带的 compiler-rt/test/fuzzer/CompressedTest.cpp来编译完成之后,来将程序运行一下。
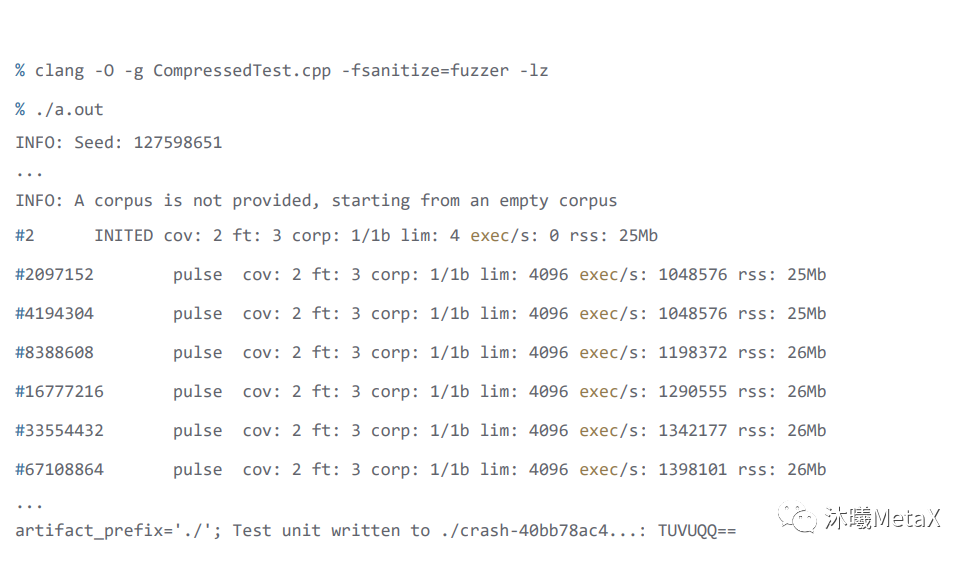
以上程序运行之后的日志信息里,可以看到如下信息,分别代表的意义为:
Seed 即 ./a.out -seed=xxx 可以指定的随机 seed
INFO 第一行提示没有指定 corpus,corpus 是一个提高 fuzzer 效率的方法
#2 后面的 INITED 代表初始化、开始执行, pulse 代表在运行,但没有新的产生,执行了 2 的 n 次方后会显示 pulse,有新的输入产生会显示 new 等等
cov: 2 代表覆盖率是 2, 执行当前输入所覆盖的代码块的总数
ft: 3 feature 泛指代码覆盖率:边缘覆盖率、边缘技术、配置文件等
corp: 1/1b 当前内存中测试输入 corpus 库中的条目数及其大小(以字节为单位)
lim: 4 exec/s 当前对语料库中新条目长度的限制。随时间增加,直到达到设置的最大长度 (-max_len),目前长度是 4
rss: 25MB 当前内存消耗,当前是25MB
./crash-xxx 是用来复现问题的 binary 文件
是不是很方便?最后一个crash 文件用于复现问题,这样我们就可以有针对性的对程序进行动态调试,利用造成 crash 的输入重现出漏洞的细节。
4提高 Fuzz 效率
从以上 CompressedTest 例子,可以看到一个简单的 Fuzzer 目标函数执行之后的一些打印信息。同时在执行时 LibFuzzer 还内置了一些可选参数供程序员使用,比如最大长度默认是100,如果某个 bug 输入的参数长度是 101 才能触发,那这个 bug 用长度 100 的输入永远都跑不出来。
因此可见,我们设置一些常见的可选参数也能够提高效率,并找到真正的问题所在。如下这些参数是比较常见的。
max_len 生成输入的最大长度
len_control 首先尝试生成较小的输入,越小就代表执行的速度就越快,然后随着时间的推移尝试生成较大的输入
除了这些常见的可选参数之外,还有两个非常重要的能够提高效率的参数:dict 和 corpus。
Dict 字典
相信「字典」对我们来说并不陌生,小学的时候基本人手一本「新华字典」。字典是从一种或多种特定语言的词典中列出的词汇,通常按字母顺序排列。
对于 Fuzzer 的字典,就是从一个目标函数中列举出所有输入特性相关的词汇。比如对应编译器的 MC(machine code),字典就包括但不限于:指令集、寄存器、const 常量、寄存器宽度等等。再举个程序员熟悉的例子,常见的编程语言,包含有条件、跳转、逻辑处理等等,对应的字典包括但不限于:if、else、for、defined、template、include、pragma、!=、+= 等等,这样相对比较好理解。

Fuzzer 字典的好处是提供一组我们希望在输入中找到的常用词或值来作为输入,帮助 Fuzzer更快地扩大其覆盖范围。使用也非常简单,用 -dict 参数即可:./a.out -dict=dict.txt。
程序员可以根据被测函数的特性手动生成一个字典,除此之外,每次程序跑完之后 LibFuzzer 会提供一个建议的字典,只要更新到对应的字典文件里即可。
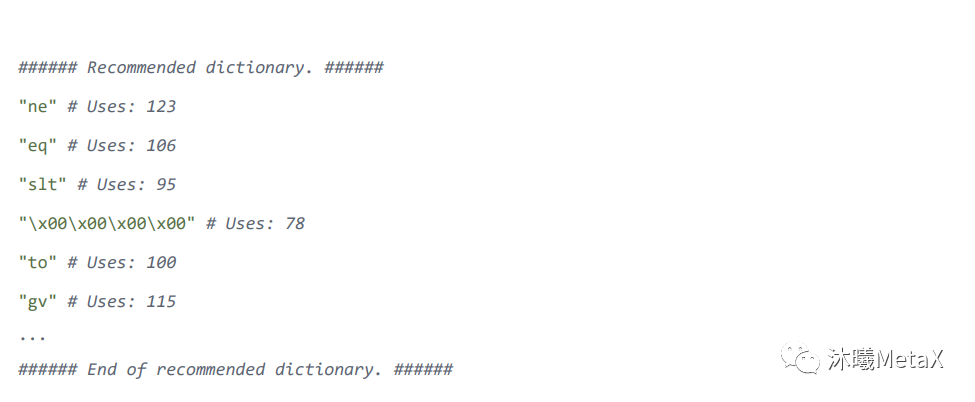
Corpus 语料库
Corpus 语料库,可以想象为一个函数的参数及各种参数的组合,即 Fuzzer 的测试用例。
在未使用语料库的情况下就得到了 crash,实属意外收获。如果我们在使用字典的情况下仍然暂时未得到 crash,就可以去寻找一些有效的输入语料库。因为 LibFuzzer 是进化型的 fuzz,结合了产生和突变两个方面。
如果我们可以提供一些好的语料库,虽然它本身无法造成程序 crash,但 LibFuzzer 会在此基础上进行变异,有可能变异出更好的输入参数,从而增大程序 crash 的概率。具体的变异策略需阅读 LibFuzzer 源码或网上搜索相关的文章。
在多种情况下,提供语料库可以将代码覆盖率提高一个数量级。
在学习 Fuzzer 时,以下资料会对大家有所帮助,可以参考 Google Oss-Fuzz 开源仓库。语料库不能适用所有的场景,但特别适用于严格定义的文件格式和数据传输协议,比如:
对于文件格式解析器,添加测试套件中的有效文件
对于协议解析器,将测试套件中的有效原始流添加到单独的文件中
对于图形库,添加各种小的 PNG/JPG/GIF 文件
执行时,只需要在目标函数后面跟一个目录即可,./a.out corpus,这里的 corpus 目录就是用来存放corpus 集的。随着运行时间而增长变多。
同时可以精简合并corpus,./a.out -merge=1 corpus_min corpus, 这样,corpus_min 和 corpus 将会存放到新的 corpus 精简后的输入样例。
为提高效率,程序员可以从可选参数的组合、字典以及 corpus这三方面入手,即可以保证目标函数的稳定性。除了以上手段外,还有一个重点也是难点,就是如何写好一个目标函数。
5Hello World Fuzzer
下面就从几个简单的 Hello world 入手,熟悉下 LibFuzzer 如何写一个目标函数。
创建一个文 fuzz_target.cc, 内容如下,不要使用 main 等作为函数名,因为 Libfuzzer 自带了main 函数。
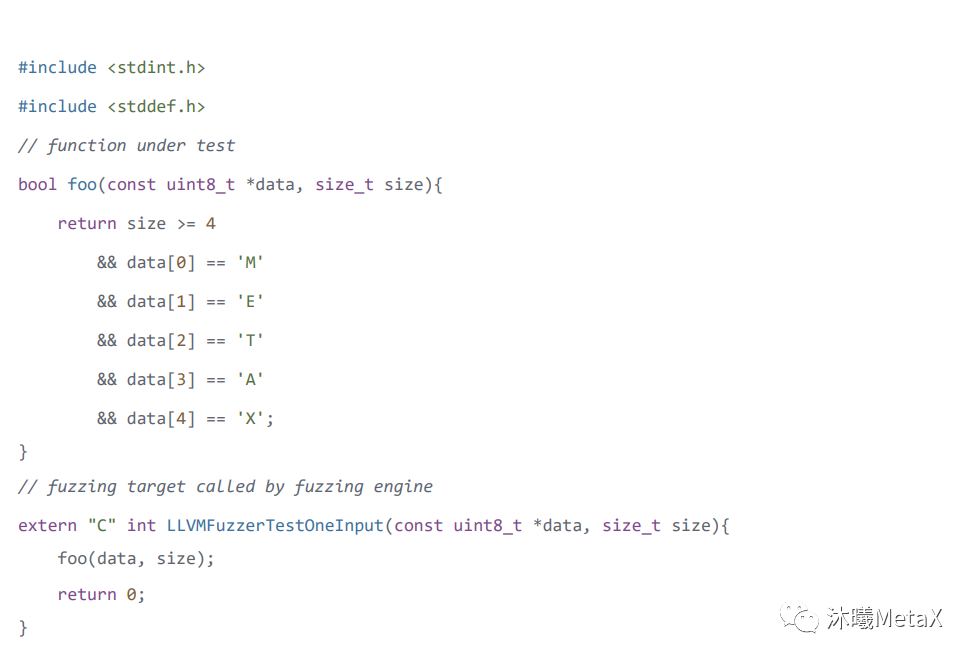
需要注意的是LLVMFuzzerTestOneInput函数是要实现的接口函数,包含两个参数 Data (LibFuzzer 的测试样本数据)及 size (样本数据的大小)。
分析问题:当foo函数被调用的时候,条件 size>=4,但是 data[4], index 取到 4,相当于 size 应该是 5,就会触发超出边界的异常。
编译这个文件,命令clang++ -g -O1 -fsanitize=fuzzer,address fuzz_target.cc -o fuzzer_target,这里的 clang 是用 LLVM 编译出来的。
如果是直接安装的 clang,就需要添加 LibFuzzer的库函数:clang++ -g -O1 -fsanitize=fuzzer,address libFuzzer/Fuzzer/libFuzzer.a fuzz_target.cc -o fuzzer_target,否则可能会报错。
参数的含义:
g 可选参数,保留调试符号
O1 指定优化等级为 1,对应的还有 O0 (optimize 0,1,2),以及 OS (optimize size)使用后 binary 大小会变小
fsanitize 指定 sanitize, 类型有几种:fuzzer, address, 和memory(单独使用,检查内存),undefined(未定义)
编译这一步骤整体过程就是通过 clang 的 -fsanitize=fuzzer 选项启用 LibFuzzer,这个选项在编译和链接过程中生效,实现了条件判断语句和分支执行的记录,通过生成不同的测试样例获得代码的覆盖率情况,最终实现所谓的 fuzz-testing。
注意:编译的选项会影响 Fuzzer 的效率,比如是否保存指针。遇到问题可以在网上搜索,或问下身边的大佬。另外,关注「沐曦MetaX」也会有意想不到的收获。
clang 编译的时候,参数-fno-omit-frame-pointer对于不需要栈指针的函数就不在寄存器中保存指针,因此可以忽略存储和检索地址的代码,同时对众多函数提供一个额外的寄存器。在 AMD64 平台上此选项默认打开,但是在 x86 平台上则默认关闭,建议编译的时候做显式设置。
gline-tables-only 表示使用采样分析器, 在应用程序执行时,抽样探查器用于收集运行时信息(如硬件计数器)。一般情况下,这个参数非常有效,并且不会引起大量的运行时开销。分析器收集的示例数据可用于编译期间确定代码中执行最多的区域是什么,在编译器使用分析信息之前,代码需要在分析器下执行,这对提高 Fuzzing 效率很重要。
常用的编译命令就是这样:clang++ -g -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link test.cc libFuzzer/Fuzzer/libFuzzer.a -o test
第一个目标函数里面被调用的 foo 函数是硬编码,有没有一种好的方法直接生成输入数据呢?YES,上代码。

用 FuzzedDataProvider 这样一个 helper,组合生成我们需要的数据,上面两段代码分别获取 value, amount,可以达到相同的效果。
事实上笔者接触 LibFuzzer 并不久,但在编写 Fuzzer 过程中,也发现了一些小技巧,比如可以用LLVMFuzzerCustomMutator来对现有的数据进行突变,然后输入到目标函数。此外,还可以用 LLVMFuzzerCustomCrossOver来自定义数据的交叉组合,从而在相同时间内达到更高的代码覆盖率。
6总结
通过本文我们可以了解 Fuzzer、LibFuzzer 工具、如何编译 LLVM-Fuzzer,以及写一个 Fuzzer 目标函数。利用 LibFuzzer 的功能可以自动发现一些未知的问题,写好了工具,还需要用起来,至于如何管理 corpus、crash bug,集成到项目中,也需要掌握和了解。LibFuzzer 是最常见的 Fuzzing 工具之一,它是独立的、不依赖 LLVM,提供的接口和 helper 非常强大,在运行的过程中,还需要用 dict、corpus 来提高 Fuzzing 的效率。corpus 语料库在 Fuzzy 过程中不断演变,我们可以找到代码中很难人被为发现的问题。随着运行时间的增加,要不断优化合并我们的 corpus,用较小的输入达到同样的覆盖率。
最后,Fuzzer 有开源、半开源、商业等不同类型,如面向安全的 Google-honggfuzz、面向 HTTP 的 Fuzz-Monkey,在工作中需选择适合项目的类型。归根结底 LibFuzzer 只是一个工具,但解决问题还要靠程序员自己。
审核编辑:汤梓红
-
性能突破 | SpacemiT-X60 在 LLVM 编译器上实现 16% 显著提升2025-11-21 9484
-
【CPKCOR-RA8D1】AI人脸检测(安装对应版本的FSP及LLVM)2025-10-31 648
-
使用LLVM-embedded-toolchain-for-Arm-17.0.1开发STM322023-10-23 3969
-
什么是LLVM?LLVM的优势和特点有哪些?2023-06-11 13046
-
LLVM clang 公开 -std=c++232023-05-27 3016
-
LLVM国际开源软件社区发布正式支持LoongArch架构的版本2023-03-21 2796
-
LLVM源码浅析-12023-03-02 3721
-
OLLVM和LLVM功能介绍2022-09-19 10424
-
llvm-mctoll将二进制文件转换为LLVM IR2022-06-22 1113
-
LLVM编译器编译过程2019-04-28 2244
-
智变未来-浅谈人工智能技术应用与实践2019-04-01 1227
-
四个不同的系统上进行LLVM/Clang 6.0 和 5.0 的编译器Benchmark测试2018-03-29 8687
-
在Swift中使用LLVM的四个要点2017-10-13 891
-
FPGA设计工具浅谈2009-10-10 722
全部0条评论

快来发表一下你的评论吧 !
