

基于FPGA协处理器的算法及总线连接
可编程逻辑
描述
当今的设计工程师受到面积、功率和成本的约束,不能采用GHz级的计算机实现嵌入式设计。在嵌入式系统中,通常是由相对数量较少的算法决定最大的运算需求。使用设计自动化工具可以将这些算法快速转换到硬件协处理器中。然后,协处理器可以有效地连接到处理器,产生“GHz”级的性能。
本文主要研究了代码加速和代码转换到硬件协处理器的方法。我们还分析了通过一个涉及到基于辅助处理器单元(APU)的实际图像显示案例的基准数据均衡决策的过程。该设计使用了在一个平台FPGA中实现的一个嵌入式PowerPC。
协处理器的意义
协处理器是一个处理单元,该处理单元与一个主处理单元一起使用来承担通常由主处理单元执行的运算。通常,协处理器功能在硬件中实现以替代几种软件指令。通过减少多种代码指令为单一指令,以及在硬件中直接实现指令的方式,从而实现代码加速。
最常用的协处理器是浮点单元(FPU),这是与CPU紧密结合的唯一普通协处理器。没有通用的协处理器库,即使是存在这样的库,将依然难以简单地将协处理器与一个CPU(例如Pentium 4)连接。Xilinx Virtex-4 FX FPGA拥有一个或两个PowerPC,每个都有一个APU接口。通过在FPGA中嵌入一个处理器,现在就有机会在单芯片上实现完整的处理系统。
带APU接口的PowerPC使得在FPGA中得以实现一个紧密结合的协处理器。因为频率的需求以及管脚数量的限制,采用外部协处理器不大可行。因此可以创建一个直接连接到PowerPC的专用应用协处理器,大大地提高了软件速度。因为FPGA是可编程的,你可以快速地开发和测试连接到CPU的协处理器解决方案。
协处理器连接模型
协处理器有三种基本的形式:与CPU总线连接的、与I/O连接的和指令流水线连接(Instruction Pipeline Connection)。此外,还存在一些这些形式的混合形式。
1. CPU总线连接
处理器总线连接加速器需要CPU在总线上移动数据以及发送命令。通常,单个数据处理就需要很多的处理器时钟周期。因为总线仲裁以及总线驱动的时钟是处理器时钟的分频,所以会降低数据处理速度。一个与总线连接的加速器可以包含一个存储器存取(DMA)引擎。在增加额外的逻辑情况下,DMA引擎允许协处理器工作在位于连接到总线的存储器上的数据块,独立于CPU。
2. I/O连接
与I/O连接的加速器直接连接到一个专用的I/O端口。通常通过GET或PUT函数提供数据和控制。因为缺少了仲裁、控制复杂度降低以及连接器件较少,因此这些接口的驱动时钟通常比处理器总线更快。这种接口的一个较好的例子如Xilinx Fast Simplex Link(FSL)。FSL是一种简单的FIFO接口,可以连接到Xilinx MicroBlaze软核处理器或Virtex-4 FX PowerPC。与处理器总线接口中的数据移动相比,通过FSL移动的数据具有较低的延时和更高的数据速率。
3. 指令流水线连接
指令流水线连接加速器直接连接到CPU的计算内核。通过与指令流水线连接,CPU不能识别的指令可以由协处理器执行。操作数、结果以及状态直接从数据执行流水线向外传递,或接收。单个运算可以实现两个操作数的处理,同时返回一个结果和状态。
作为一个直接连接的接口,连接道指令流水线的加速器可以用比处理器总线更快的时钟驱动。Xilinx通过APU接口实现这种协处理器连接模型,对于典型的双操作数指令,在数据控制和数据传输上可以缩减10倍的时钟周期。APU控制器还连接到数据缓存控制器,通过它可以执行数据加载/存储操作。因此,APU接口能在每秒内移动数百兆字节,接近DMA速度。
I/O连接加速器或指令流水线连接加速器可以与总线连接加速器结合起来。在增加额外的逻辑条件下,可以创建一个加速器,这个加速器运行在一个位于总线连接存储器上的数据块上,通过一个快速、低延时的接口接收命令并返回状态。
在本文中介绍的C-HDL工具组可以实现总线连接和I/O连接加速器,它还能实现连接到PowerPC的APU接口的加速器。尽管APU连接是基于指令流水线的,C-HDL工具组实现了一种I/O流水线接口,该接口具有I/O连接加速器的典型性能。
FPGA/PowerPC/APU接口
FPGA允许硬件设计工程师利用单芯片上的处理器、解码逻辑、外设和协处理器实现一个完整的计算系统。FPGA可以包含数千到数十万的逻辑单元,可以从这些逻辑单元实现一个处理器,如Xilinx PicoBlaze或MicroBlaze处理器,或者可以是一个或者更多的硬逻辑单元(如Virtex-4 FX PowerPC)。大量的逻辑单元使你可以实现数据处理单元,这些单元与处理器系统一起工作,由处理器对其进行控制或监控。
FPGA作为一种可重复编程的单元,允许你在设计过程中进行编程并对其进行测试。如果你发现了一个设计缺陷,你可以立即对其进行重新编程设计。FPGA还允许你实现硬件运算功能,而这在以前的实现成本是很高的。CPU流水线与FPGA逻辑之间紧密结合,这样就可以创建高性能软件加速器。
图1的模块框图显示了PowerPC、集成的APU控制器以及一个与之相连的协处理器。来自高速缓存或存储器中的指令可以立即出现在CPU解码器和APU控制器上,如果CPU能识别指令,则运行这些指令。否则,APU控制器或用户创建的协处理器可以对指令做出应答并执行指令。一个或者两个操作数被传递到协处理器,并返回一个结果或状态。APU接口还支持用一个指令发送一个数据单元。数据单元的大小范围从一个字节到4个32位的字。
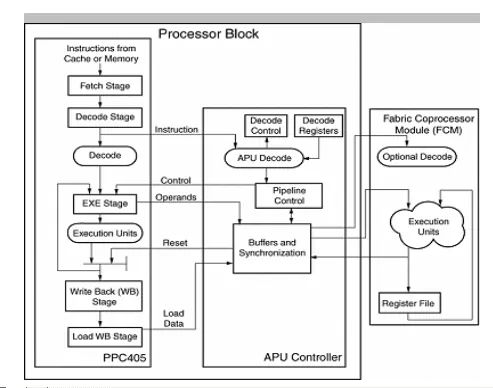
图1:PowerPC、集成的APU控制器和协处理器
通过一个结构协处理器总线(FCB),可以将一个或多个协处理器连接到APU接口。连接到总线的协处理器范围包括现存的内核(例如FPU)到用户创建的协处理器。一个协处理器可以连接到FCB用于控制和状态运算,并连接到一个处理器总线,实现直接存储器数据块访问以及DMA数据传递。一种简化的连接方案,例如FSL,也可以在FCB和协处理器之间使用,在牺牲一定性能的条件下实现FIFO数据和控制通信。
为展示指令流水线连接加速器的性能优势,我们采用一个处理器总线连接FPU首先实现了一个设计,然后采用APU/FCB连接的FPU实现设计。表1总结了两种实现方式下有限脉冲响应(FIR)滤波器的性能。如表1中所反映的一样,连接到一个指令流水线的FPU使软件浮点运算速度增加30倍,而APU接口相比于总线连接FPU来说改善了近4倍。

表1:未加速与加速的浮点性能
C代码转换到HDL
采用C到HDL的转换工具将C代码转换到HDL加速器是一种创建硬件协处理器的高效方法。图2所示以及下面详述的步骤总结了C到HDL转换的过程:
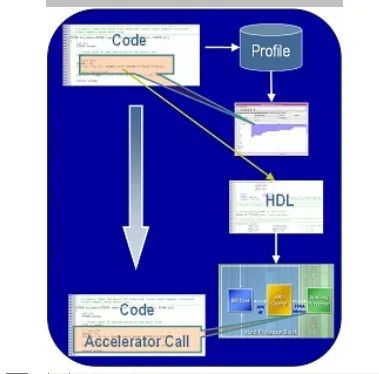
图2:C-HDL设计流程
使用标准C工具实现应用程序或算法。开发一种软件测试向量(test bench)用于基线性能和正确性(主机或台式电脑仿真)测试。使用一种编译器(例如gprof)来开始确定关键的函数。
确定是否浮点到定点转换适当。使用库或宏来辅助这种转换,使用一个基线测试向量来分析性能和准确性。使用编译器来重新评估关键函数。
使用C到HDL转换工具(如Impulse C),在每个关键功能上重复,以实现:将算法分割成并行的进程;创建硬件/软件进程接口(流、共享存储器、信号);对关键的代码段(例如内部代码循环)进行自动优化和并行化;使用桌面电脑仿真、周期准确的C仿真以及实际的在系统测试对得到的并行算法进行测试和验证。
使用C到HDL转换工具将关键的代码段转换到HDL协处理器。
将协处理器连接到APU接口用于最终的测试。
Impulse:C到HDL转换工具
如图3所示的Impulse C通过结合使用C兼容库函数与Impulse CoDeveloper C代码到硬件的编译器,使嵌入式系统设计工程师能创建高度并行的、FPGA加速的应用。Impulse C通过使用定义完好的数据通信、消息传递和同步处理机制,简化了硬件/软件混合应用设计。Impulse C提供了C代码(例如循环流水线处理、展开和运算符调度)的自动优化以及交互式工具,允许你对每个周期的硬件行为进行分析。
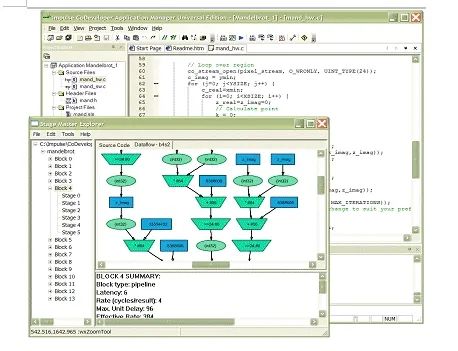
图3. Impulse C
Impulse C设计用于面向数据流的应用,但是它也具有足够的灵活性来支持其他的编程模型,包括使用共享存储器。这一点很重要,因为基于FPGA不同的应用具有不同的性能和数据要求。在一些应用中,通过块存储器读和写在嵌入式处理器和FPGA之间转移数据是有意义的;在其它的情况下,流传数通信信道可能提供更高的性能。可以快速建模、编译和评估可选的算法的能力对于实现某个应用最佳的结果来说,非常重要。
到目前为止,Impulse C库包含以新数据类型和预定义的函数调用形式的最少C语言扩展。使用Impulse C函数调用,你可以定义多个并行程序段(调用进程),并使用流、信号和其他机制描述它们的互连。Impulse C编译器将这些C语言进程转换并优化成:可以综合到FPGA的较低级HDL,或可以通过广泛存在的C交叉编译器编译到支持的微处理器上标准C(带相关的库调用)。
完整的CoDeveloper开发环境包括与标准C编译器和调试器(包括微软公司的Visual Studio和GCC/GDB)兼容的台式电脑仿真库。使用这些库,Impulse C程序设计工程师能编译和执行他们用于算法验证和调试目的的应用程序。C程序设计工程师还能检验并行进程,分析数据移动,并利用CoDeveloper Application Monitor解决进程到进程的通信问题。
在编译时,Impulse C应用的输出是一组硬件和软件源文件,用于输入到FPGA综合工具。这些文件包括:
用于描述编译硬件进程的自动产生的HDL文件;
用于描述连接硬件进程到系统总线所需的流、信号和存储器组件的自动产生的HDL文件;
自动产生的软件组件(包括运行时间库)用于建立任何硬件/软件流连接的软件端;
附加文件,包括脚本文件,用于输入产生的应用程序到目标FPGA布局布线环境。这种编译进程的结果是一个完整的应用,包括需要的硬件/软件接口,用于在基于FPGA的编程平台上实现。
设计实例
图4所示的Mandelbrot图是一种经典的不规则几何图形,该图形广泛用在科学和工程学界用于仿真无序事件,例如天气。不规则图形也用于产生纹理和在视频显示应用上成像。Mandelbrot图像描述为自相似性。放大图形的局部,可以获得类似于整个图形的另外一个图形。
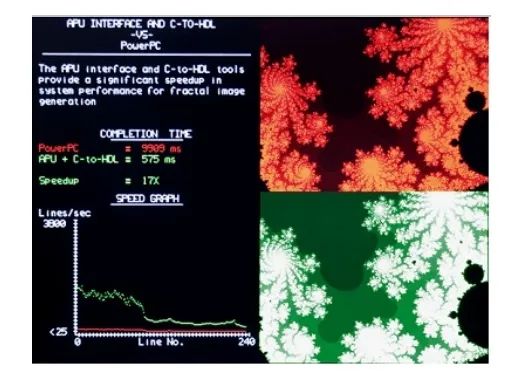
图4:Mandelbrot图
Mandelbrot图形是硬件/软件协同设计的理想选择,因为它具有单个运算密集的函数。通过将关键的函数转移到硬件实现将大大地增加整个系统的速度,使这个关键函数更快。Mandelbrot应用还能清楚地区分硬件和软件进程,使用C-HDL工具很容易实现。
本文使用CoDeveloper工具组作为C-HDL工具组用于该设计实例,而且只修改了软件Mandelbrot C程序以使其与C-HDL工具兼容。其中的改变包括:将软件项目分割成不同的进程(顺序执行的独立单元);函数接口转换(硬件到软件)到流;增加编译器指令来对产生的硬件进行优化。我们随后使用CoDeveloper工具组来创建Pcore协处理器,将该协处理器输入到Xilinx Platform Studio(XPS)。利用XPS,我们将PC连接到PowerPC APU控制器接口,并测试系统。
Xilinx公司的应用说明资料XAPP901中提供了该设计的全面描述和设计文件,并提供下载。同时,用户指南UG096提供一种实现设计实例的逐步设计指导。
我们对Mandelbrot图像纹理问题、图像滤波应用和三倍DES加密的性能改善进行了测量。性能改善显示了从11倍到34倍的加速,在表2中做出了总结。

表2:通过协处理器加速器的算法加速性能对比
本文小结
受功率、尺寸和成本的约束,你可能需要做出一个并非理想的处理器选择,通常所选择处理器性能比期望的性能低。当软件代码不能运行足够快时,协处理器代码加速器成为一种很有吸引力的解决方案。你可以在HDL中手动设计加速器或使用C-HDL工具自动将C代码转换成HDL。
使用Impulse C这样的C-HDL工具能使加速器运行更快且更简单。Virtex-4 FX FPGA具有两个嵌入式PowerPC,能实现处理器指令流水线到软件加速器之间紧密的连接。如上所述,关键的软件程序增加速度10倍到30倍,使300MHz的PowerPC提供等于或高于高性能GHz级处理器的性能。上面的实例每个只需要几天的时间来产生,显示了采用C-HDL流程的快速设计、实现和测试。
编辑:黄飞
-
FPGA协处理的优势有哪些?如何去使用FPGA协处理?2023-10-21 3118
-
MD5信息摘要算法实现二(基于蜂鸟E203协处理器)2025-10-30 284
-
FPGA协处理器的优势2011-09-29 6293
-
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现2015-02-02 3743
-
采用FPGA的协处理器来简化ASIC仿真2019-07-23 1583
-
如何利用串行RapidIO实现FPGA协处理器?2019-08-07 2916
-
让FPGA协处理器实现代码加速的方法有哪些?2019-09-03 2184
-
为什么FPGA协处理器可以实现算法加速?2021-04-13 2731
-
请问FPGA协处理器有哪些优势?2021-05-08 1847
-
FPGA协处理技术介绍及进展2010-04-26 1221
-
基于FPGA平台的嵌入式PowerPC协处理器实现算法加速设计2018-07-22 1790
-
MIC协处理器的OLAP外键连接算法2017-12-30 1315
-
手机上的协处理器有什么作用_苹果协处理器是干什么的2018-04-24 23544
-
采用FPGA协处理器实现算法加速教程2021-09-28 5248
-
基于FPGA协处理器的算法及总线连接2023-08-22 1856
全部0条评论

快来发表一下你的评论吧 !
