

探索3D检测需要做哪些适配
描述
1. 前言
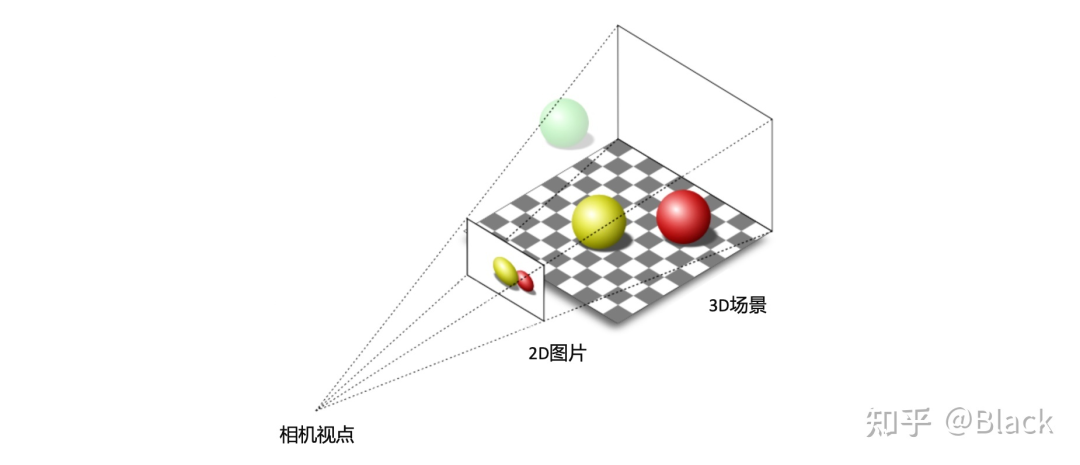
做为被动传感器的相机,其感光元件仅接收物体表面反射的环境光,3D场景经投影变换呈现在2D像平面上,成像过程深度信息丢失了。而当我们仅有图片时,想要估计物体在真实3D场景中所处的位置,这将是一个欠约束的问题。
2. 几何求解
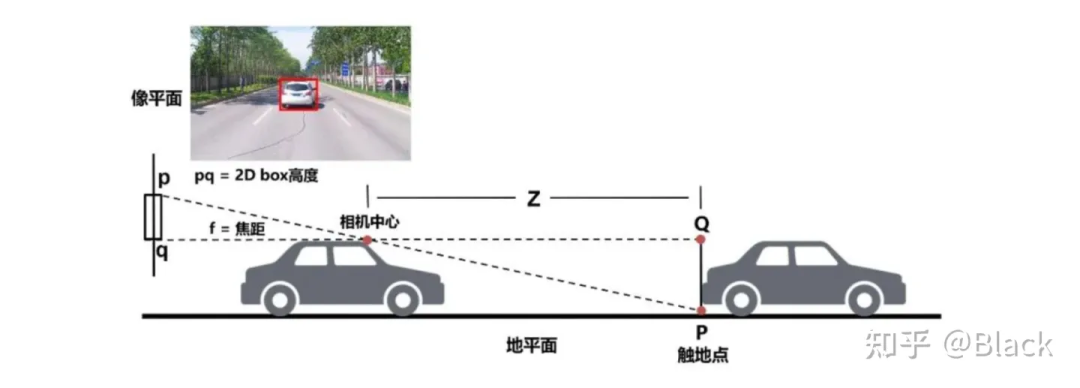
分类、2D目标检测等图像任务已经在工业界得到广泛应用,可以认为是已经解决了的问题,并且数据价格低廉。但2D目标框无法满足自动驾驶、机器人等对障碍物有定位需求的领域。传统算法利用2D检测框的底部中心点,基于平面假设,求解近似三角形来获得目标离自车的距离。这类方法简单轻量,数据驱动的部分仅限于2D目标检测部分,但对地面有较强的假设,面对车辆颠簸敏感(俯仰角变化),且对2D检测框的完整性有较强的依赖。
3. 单目3D目标检测
随着标注方法的升级,目标的表示由原来的2D框对角点表示 进化成了3D坐标系下bounding box的表示 ,不同纬度表示了3D框的位置、尺寸、以及地面上的偏航角。有了数据,原本用于2D检测的深度神经网络,也可以依靠监督学习用于3D目标框检测。
这样的3D数据业界目前主要有两种获取方式,一种是车辆除了配备了相机,同时安装了LiDAR这样的3D传感器,经扫描,目标轮廓以点云的形式被记录下来,标注员主要看点云来标注。另一种是像特斯拉这样仅配备相机的车辆,收集的只有图像数据,依靠多种交叉验证的离线算法,辅以人工来生成3D标注数据。
焦距适中的相机,FOV是有限的,想要检测车身 目标,就要部署多个相机,每个相机负责一定FOV范围内的感知。最终将各相机的检测结果通过相机到车身的外参,转换到统一的车辆坐标系下。
但在有共视时,会产生冗余检测,即有多个摄像头对同一目标做了预测,现有方法,如FCOS3D,会在统一的坐标系下对所有检测结果做一遍NMS,有重合的目标框仅留下一个分类指标得分最高的。
冗余问题得到缓解,但要命的是被截断的目标往往在任一个相机里都只出现了一部分,多数情况是每个相机下的检测质量都堪忧。原因是多相机的图片在深度神经网络是以 的形式传递的,传统网络中会有纬度 的特征间交互,也会有纬度 的空间交互,但唯独没有不同图片间batch纬度的交互。简单来说就是下图中左边图片在检测黑色客车时,是无法用到右边图片的信息的。

4. 统一多视角相机的3D目标检测
4.1 看到哪算哪
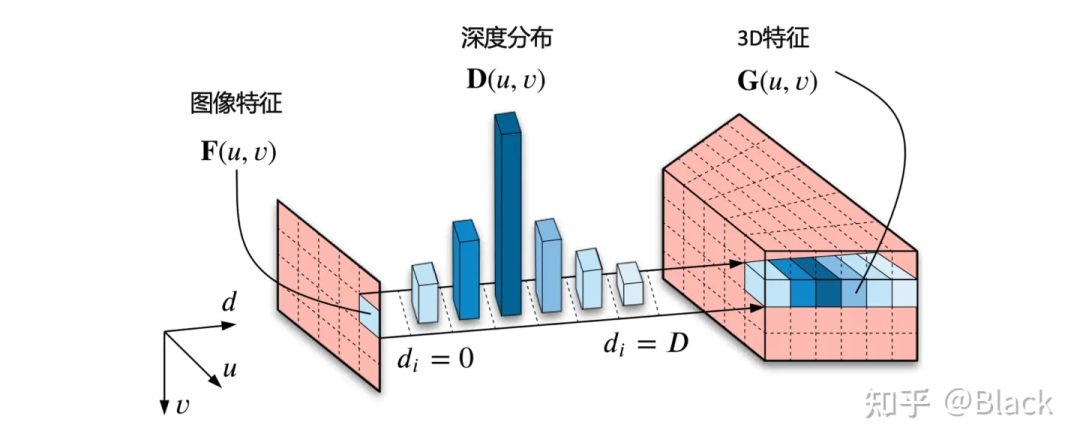
自下而上的方法,手头的信息看到哪算哪。下图来自CaDNN这篇文章,很好的描述了这一类方法,包括Lift、BEVDet、BEVDepth。这类方法预测每个像素的深度/深度分布,有的方法隐式的预测,有的方法利用LiDAR点云当监督信号(推理时没有LiDAR),虽然只用在训练阶段,但不太能算在纯视觉的方法里比较精度,工程使用的时候可能涉及部署车辆和数据采集车辆割裂的尴尬。总之,有了深度就可以由相机内外参计算此像素在3D空间中的位置,然后把图像特征塞入对应位置。可以理解为由图片生成3D“点云”,多视角相机形成的“点云”拼在一起,有了“点云”就可以利用现有的点云3D目标检测器了(如PointPillars, CenterPoint)。
4.2 先决定看哪
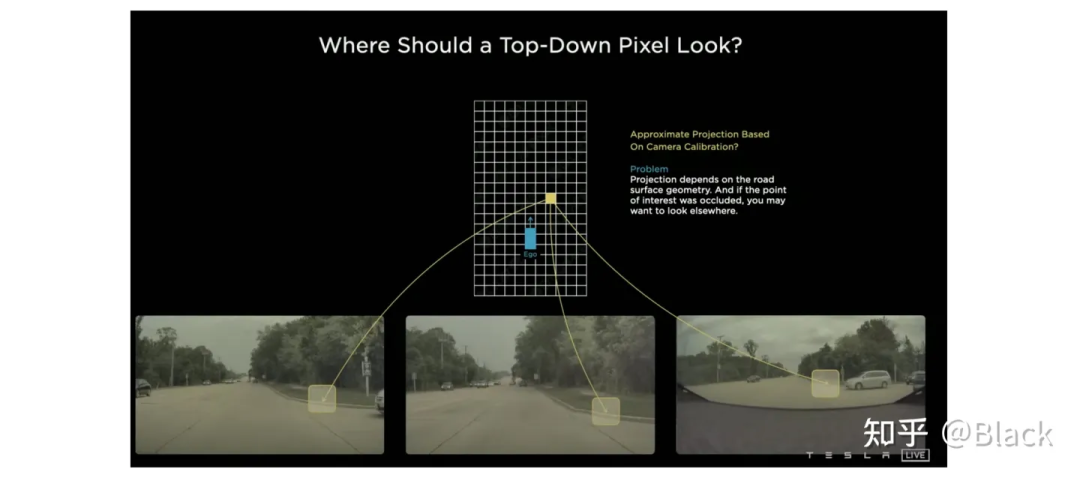
自上而下的方法,先确定关注的地方(但可能手头不宽裕,不配关注这个地方... 比如想关注自车后方,可后方视野完全被一辆大车遮挡了的情况)。关于这类的方法,下图碰瓷一下特斯拉,简单来说就是先确定空间中要关注的位置(图中网格代表的车身周围的地方),由这些位置去各个图像中“搜集”特征,然后做判断。根据“搜集”方式的不同衍生出了下面几种方法。
4.2.1 关键点采样
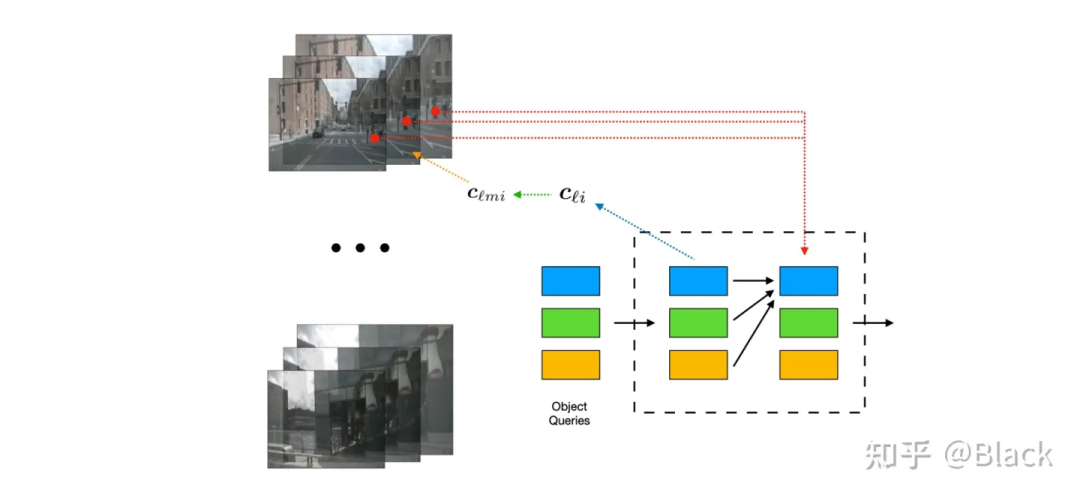
下图来自DETR3D,其作为将DETR框架用于3D目标的先锋工作,由一群可学习的3D空间中离散的位置(包含于object queries),根据相机内外参转换投影到图片上,来索引图像特征,每个3D位置仅对应一个像素坐标(会提取不同尺度特征图的特征)。
4.2.2 局部注意力
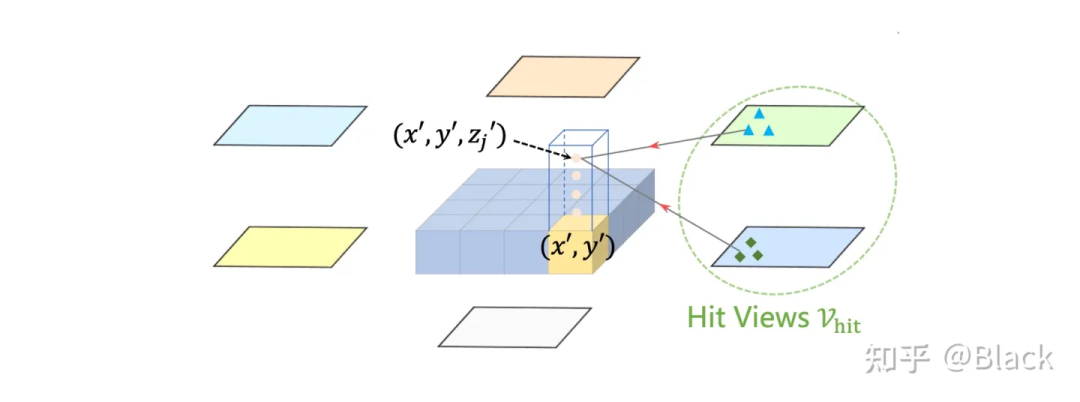
下图来自BEVFormer,该方法预先生成稠密的空间位置(含不同的高度,且不随训练更新),每个位置投影到各图片后,会和投影位置局部的数个像素块发生交互来提取特征(基于deformable detr),相比于DETR3D,每个3D点可以提取到了更多的特征。最终提取的3D稠密特征图在高度纬度会被压扁,形成一张BEV视角下稠密的2D特征图,后续基于此特征图做目标检测。BEVFormer相比DETR3D在精度上有提升(结构上也多了额外的BEV decoders),在BEV视角下,目标尺度被统一了,不会出现图像视角下目标近大远小的问题。一张稠密的BEV特征图还可以做车道线检测/道路分割等任务,缺点是计算量大,显存占用大。
4.2.3 全局注意力
典型方法如PETR,该方法强调保持2D目标检测器DETR的框架,探索3D检测需要做哪些适配。PETR同样利用稀疏的3D点(来自object queries)来“搜索”图像特征,但不像DETR3D或BEVFormer把3D点投影回图片,而是基于标准的attention模块,每个3D点会和来自全部图片的所有像素交互。相似度(attention matrix)计算遵循 ,其中 来自object queries,里面包含的信息和3D bounding box的信息强相关(暂不讨论query也包含的表观信息),而 来自图像(可以理解为和RGB信息强相关,原生DETR中还会加入像素位置编码),这两个向量计算相似度缺乏可解释性(直接训练也不怎么work)。可以理解为下图描述的场景,很难说一个3D框和哪个像素相似。

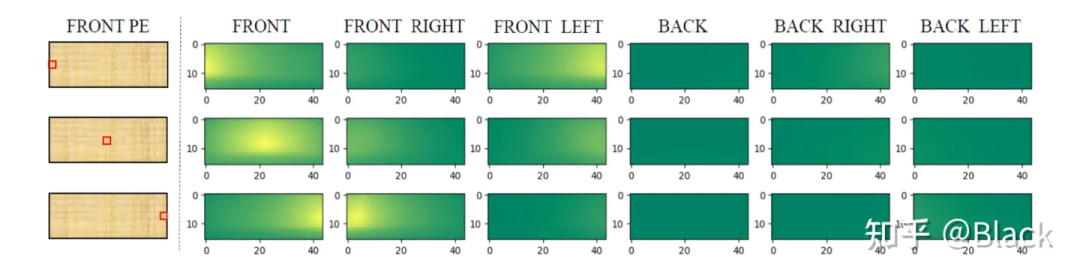
PETR对矩阵下手,为每个像素编码了3D位置相关的信息,使得相似度得以计算。实现上简单来说是相机光心到像素的射线上每隔一段距离采样一个点的 ,并转换到query坐标系下。相比之下,DETR3D和BEVFormer都遵循了deformable detr的方式,由query预测权重来加权“搜集”来的特征,规避掉了点积相似度的计算,PETR是正面硬刚这个问题了属于是。下图是PETR单位置编码相似度效果图(达到了跨相机相似的效果),只是这个相似度是“虚假”的,跟真实场景没关系,也不会变化。很快,PETRv2中加上了图像特征,效果也有提升。不过全局注意力算力消耗巨大,PETR只用了单尺度特征图,一般显卡还需利用混合精度、checkpoint等降显存的方法才能训练起来。
-
3D检测系统可检测PCB板针脚高度2016-01-05 5613
-
为何PCB设计需要3D功能?2017-11-01 3917
-
哪些适配器需要做CCC认证?2019-04-10 3092
-
高精度3D扫描如何实现?2019-08-06 7395
-
基于ToF的3D活体检测算法研究2021-01-06 3299
-
解读裸眼3D技术2012-02-28 7647
-
3D模型2015-11-04 1906
-
3D技术的应用探索3D机器视觉库2016-03-22 1158
-
探索如何打开我国3D打印的应用之路2016-09-07 1143
-
3DSYS公布了Figure4 3D打印机的材料参数2020-04-26 3323
-
矩子科技的3D检测业务水平如何?2020-10-09 3559
-
3D视觉相机板材瑕疵检测(窄)说明2022-04-22 2912
-
为什么要选择3D机器视觉检测2022-12-26 1720
-
电柜3D布局需要满足哪些条件?2023-10-19 1096
-
如何搞定自动驾驶3D目标检测!2024-01-05 1287
全部0条评论

快来发表一下你的评论吧 !
