

BPF技术知识和实践经验
描述
1 前言
随着容器技术的发展,越来越多业务甚至核心业务开始采用这一轻量级虚拟化方案。作为一项依然处于发展阶段的新技术,容器的安全性在不断提高,也在不断地受到挑战。天翼云云容器引擎于去年 11 月底上线,目前已经在 22 个自研资源池部署上线。天翼云云容器引擎使用 ebpf 技术实现了细粒度容器安全,对主机和容器异常行为进行检测,对有问题的节点和容器进行自动隔离,保证了多租户容器平台容器运行时安全。
BPF 是一项革命性的技术,可在无需编译内核或加载内核模块的情况下,安全地高效地附加到内核的各种事件上,对内核事件进行监控、跟踪和可观测性。BPF 可用于多种用途,如:开发性能分析工具、软件定义网络和安全等。我很荣幸获得今年 openEuler Summit 大会的演讲资格,做 BPF 技术知识和实践经验的分享。本文将作为技术分享,从 BPF 技术由来、架构演变、BPF 跟踪、以及容器安全面对新挑战,如何基于 BPF 技术实现容器运行时安全等方面进行介绍。
2 初出茅庐:BPF 只是一种数据包过滤技术
BPF 全称是「Berkeley Packet Filter」,中文翻译为「伯克利包过滤器」。它源于 1992 年伯克利实验室,Steven McCanne 和 Van Jacobson 写得一篇名为《The BSD Packet Filter: A New Architecture for User-level Packet Capture》的论文。该论文描述是在 BSD 系统上设计了一种新的用户级的数据包过滤架构。在性能上,新的架构比当时基于栈过滤器的 CSPF 快 20 倍,比之前 Unix 的数据包过滤器,例如:SunOS 的 NIT(The Network Interface Tap )快 100 倍。
BPF 在数据包过滤上引入了两大革新来提高性能:
BPF 是基于寄存器的过滤器,可以有效地工作在基于寄存器结构的 CPU 之上。
BPF 使用简单无共享的缓存模型。数据包会先经过 BPF 过滤再拷贝到缓存,缓存不会拷贝所有数据包数据,这样可以最大程度地减少了处理的数据量从而提高性能。
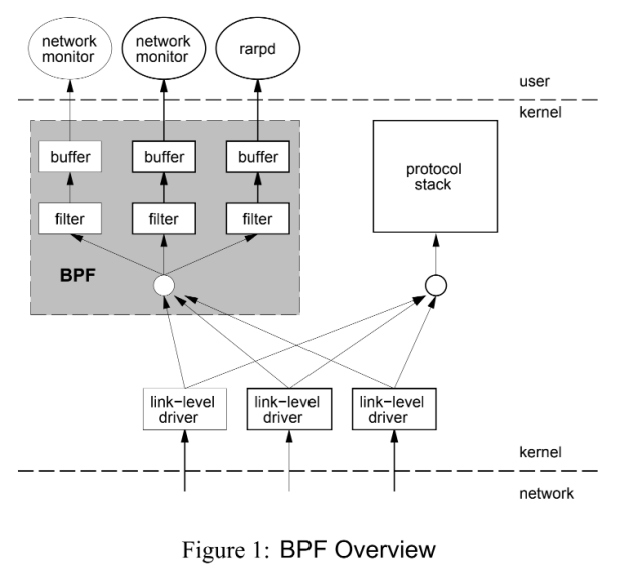
3 Linux 超能力终于到来了:eBPF 架构演变
3.1 eBPF 介绍
2013 年 BPF 技术沉默了 20 年之后,Alexei Starovoitov 提出了对 BPF 进行重大改写。2013 年 9 月 Alexei 发布了补丁,名为「extended BPF」。eBPF 实现的最初目标是针对现代硬件进行优化。eBPF 增加了寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,函数参数可以交换更多的信息,编写更复杂的程序。eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行速度提高了 4 倍。
当时 BPF 程序仍然限于内核空间使用,只有少数用户空间程序可以编写内核的 BPF 过滤器,例如:tcpdump 和 seccomp 。2014 年 3 月, 经过 Alexei Starovoitov 和 Daniel Borkmann 的进一步开发, Daniel 将 eBPF 提交到 Linux 内核中。2014 年 6 月 BPF JIT 组件提交到 Linux 3.15 中。2014 年 12 月 系统调用 bpf 提交到 Linux 3.18 中。随后,Linux 4.x 加入了 BPF 对 kprobes、uprobe、tracepoints 和 perf_evnets 支持。至此,eBPF 完成了架构演变,eBPF 扩展到用户空间成为了 BPF 技术的转折点。正如 Alexei 在提交补丁的注释中写到:“这个补丁展示了 eBPF 的潜力”。当前 eBPF 不再局限于网络栈,成为内核顶级的子系统。
后来,Alexei 将 eBPF 改为 BPF。原来的 BPF 就被称为 cBPF「classic BPF」。现在 cBPF 已经基本废弃,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
下面是 cBPF 和 eBPF 的对比:
| 纬度 | cBPF | eBPF |
|---|---|---|
| 内核版本 | Linux 2.1.75(1997 年) | Linux 3.18(2014 年)[4.x for kprobe/uprobe/tracepoint/perf-event](注:虽然 eBPF 在 Linux 3.18 版本以后引入,并不代表只能在内核 3.18+ 版本上运行,低版本的内核升级到最新也可以使用 eBPF 能力,只是可能部分功能受限。) |
| 寄存器数目 | 2 个:A, X | 10 个:R0–R9, 另外 R10 是一个只读的帧指针* R0 - eBPF 中内核函数的返回值和退出值* R1 - R5 - eBF 程序在内核中的参数值* R6 - R9 - 内核函数将保存的被调用者 callee 保存的寄存器* R10 -一个只读的堆栈帧指针 |
| 寄存器宽度 | 32 位 | 64 位 |
| 存储 | 16 个内存位: M[0–15] | 512 字节堆栈,无限制大小的 “map” 存储 |
| 限制的内核调用 | 非常有限,仅限于 JIT 特定 | 有限,通过 bpf_call 指令调用 |
| 目标事件 | 数据包、 seccomp-BPF | 数据包、内核函数、用户函数、跟踪点 PMCs 等 |
接下来,让我们来看看演变后的 BPF 架构。
3.2 eBPF 架构演变
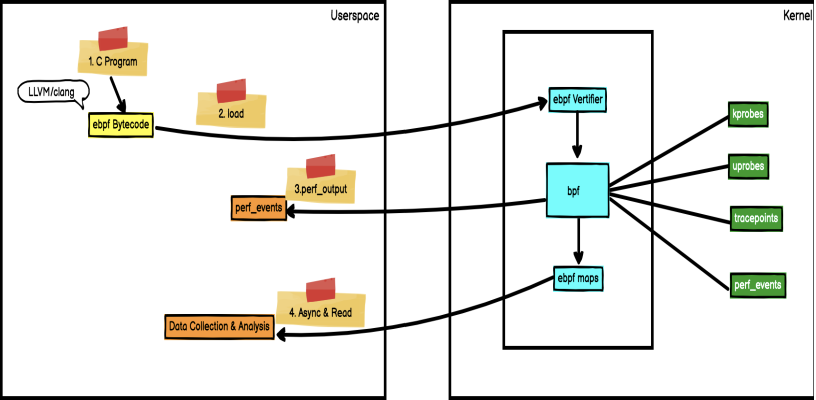
BPF 是一个通用执行引擎,能够高效地安全地执行基于系统事件的特定代码。BPF 内部由字节码指令,存储对象和帮助函数组成。从某种意义上看,BPF 和 Java 虚拟机功能类似。对于 Java 开发人员而言,可以使用 javac 将高级编程语言编译成机器代码,Java 虚拟机是运行该机器代码的专用程序。相应地,BPF 开发人员可以使用编译器 LLVM 将 C 代码编译成 BPF 字节码,字节码指令在内核执行前必须通过 BPF 验证器进行验证,同时使用内核中的 BPF JIT 模块,将字节码指令直接转成内核可执行的本地指令。编译后的程序附加到内核的各种事件上,以便在 Linux 内核中运行该 BPF 程序。下图是 BPF 架构图:
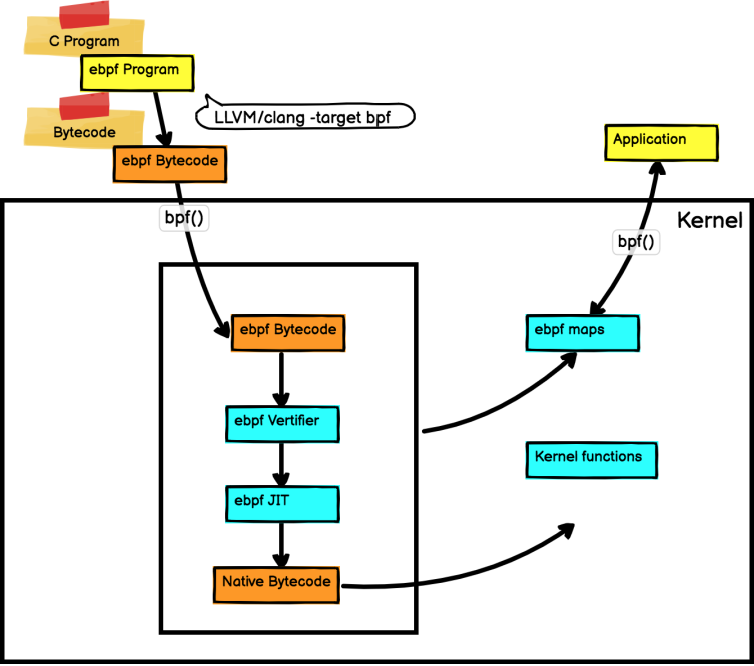
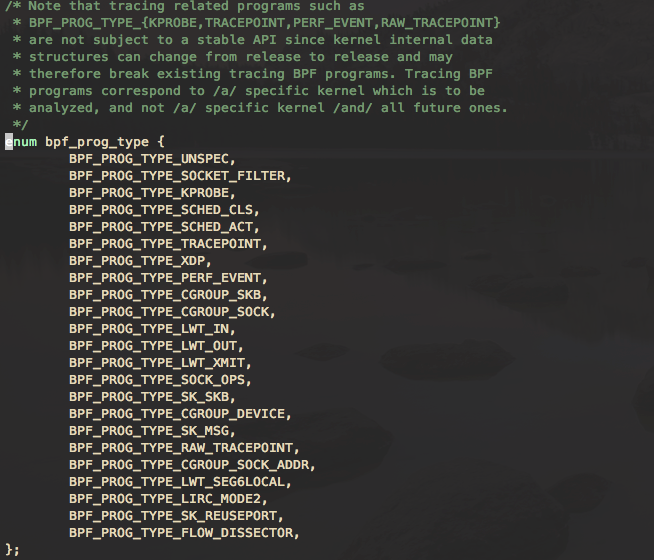
BPF 使内核具有可编程性。BPF 程序是运行在各种内核事件上的小型程序。这与 JavaScript 程序有一些相似之处:JavaScript 是允许在浏览器事件,例如:鼠标单击上运行的微型 Web 程序。BPF 是允许内核在系统和应用程序事件,例如:磁盘 I/O 上运行的微型程序。内核运行 BPF 程序之前,需要知道程序附加的执行点。程序执行点是由 BPF 程序类型确定。通过查看/kernel-src/sample/bpf/bpf_load.c 可以查看 BPF 程序类型。下面是定义在 bpf 头文件中的 bpf 程序类型:
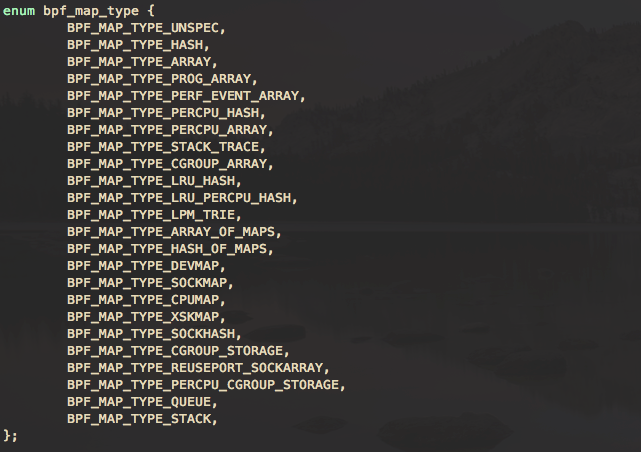
BPF 映射提供了内核和用户空间双向数据共享,允许用户从内核和用户空间读取和写入数据。BPF 映射的数据结构类型可以从简单数组、哈希映射到自定义类型映射。下面是定义在 bpf 头文件中的 bpf 映射类型:
3.3.BPF 与传统 Linux 内核模块的对比
BPF 看上去更像内核模块,所以总是会拿来与 Linux 内核模块方式进行对比,但 BPF 与内核模块不同。BPF 在安全性、入门门槛上及高性能上比内核模块都有优势。
传统 Linux 内核模块开发,内核开发工程师通过直接修改内核代码,每次功能的更新都需要重新编译打包内核代码。内核工程师可以开发即时加载的内核模块,在运行时加载到 Linux 内核中,从而实现扩展内核功能的目的。然而每次内核版本的官方更新,可能会引起内核 API 的变化,因此你编写的内核模块可能会随着每一个内核版本的发布而不可用,这样就必须得为每次的内核版本更新调整你的模块代码,并且,错误的代码会造成内核直接崩溃。
BPF 具有强安全性。BPF 程序不需要重新编译内核,并且 BPF 验证器会保证每个程序能够安全运行,确保内核本身不会崩溃。BPF 虚拟机会使用 BPF JIT 编译器将 BPF 字节码生成本地机器字节码,从而能获得本地编译后的程序运行速度。
下面是 BPF 与 Linux 内核模块的对比:
| 维度 | Linux 内核模块 | BPF |
|---|---|---|
| kprobes、tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
4 BPF 实践中的第一公民:BPF 跟踪
BPF 跟踪是 Linux 可观测性的新方法。在 BPF 技术的众多应用场景中,BPF 跟踪是应用最广泛的。2013 年 12 月 Alexei 已将 eBPF 用于跟踪。BPF 跟踪支持的各种内核事件包括:kprobes、uprobes、tracepoint 、USDT 和 perf_events:
kprobes:实现内核动态跟踪。kprobes 可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中的函数。
tracepoints:内核静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
USDT:为用户空间的应用程序提供了静态跟踪点。
perf_events:定时采样和 PMC。
5 容器安全
5.1 容器生态链带来新挑战
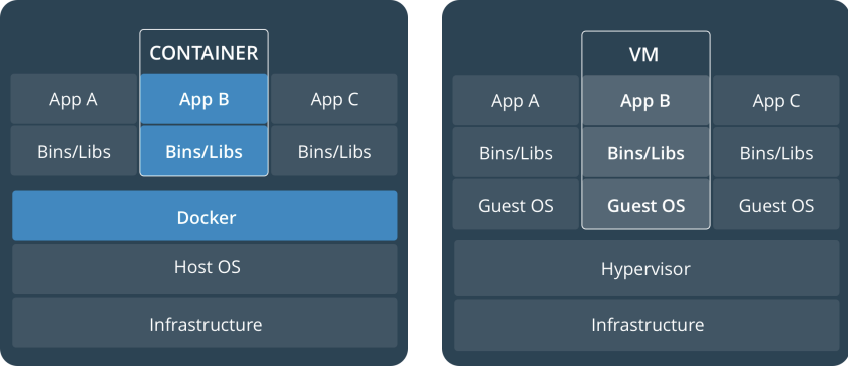
虚拟机(VM)是一个物理硬件层抽象,用于将一台服务器变成多台服务器。管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此占用大量空间。VM 启动也较慢。
容器是一种应用层抽象,用于将代码和依赖资源打包在一起。多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行。与虚拟机相比,容器占用的空间比较少(容器镜像大小通常只有几十兆),瞬间就能完成启动。
容器技术面临的新挑战:
容器共享宿主机内核,隔离性相对较弱!
有 root 权限的用户可以访问所有容器资源!某容器提权后可能影响全局!
容器在主机网络之上构建了一层 Overlay 网络,使容器间的互访避开了传统网络安全的防护!
容器的弹性伸缩性,使有些容器只是短暂运行,短暂运行的容器行为异常不容易被发现!
容器和容器编排给系统增加了新的元素,带来新的风险!
5.2 容器安全事故:容器逃逸
在容器安全问题中,容器逃逸是最为严重,它直接影响到了承载容器的底层基础设施的保密性、完整性和可用性。下面的情况会导致容器逃逸:
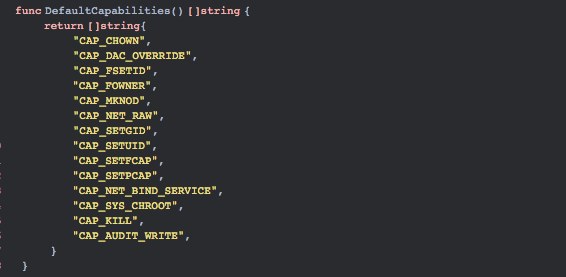
❏ 危险配置导致容器逃逸。在这些年的迭代中,容器社区一直在努力将「纵深防御」、「最小权限」等理念和原则落地。例如,Docker 已经将容器运行时的 Capabilities 黑名单机制改为如今的默认禁止所有 Capabilities,再以白名单方式赋予容器运行所需的最小权限。如果容器启动,配置危险能力,或特权模式容器,或容器以 root 用户权限运行都会导致容器逃逸。下面是容器运行时默认的最小权限。
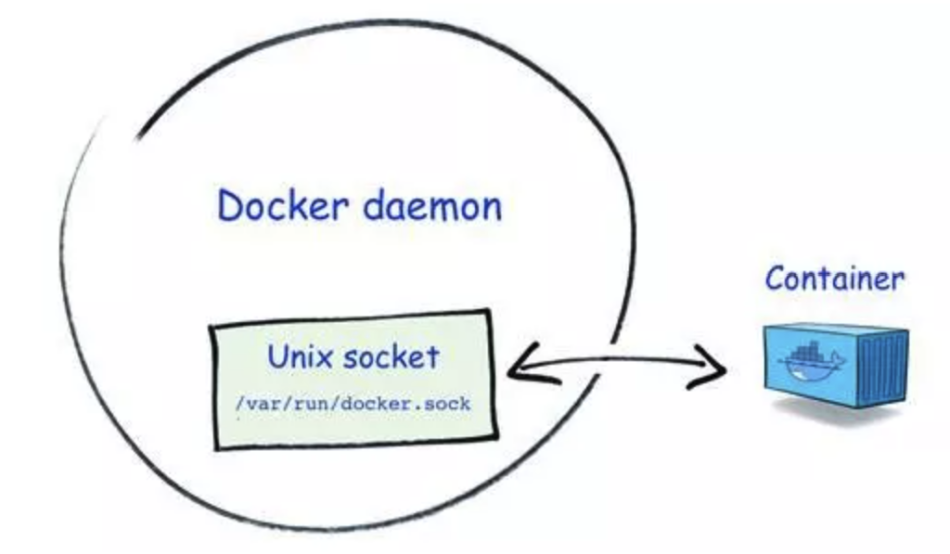
❏ 危险挂载导致容器逃逸。Docker Socket 是 Docker 守护进程监听的 Unix 域套接字,用来与守护进程通信——查询信息或下发命令。如果在攻击者可控的容器内挂载了该套接字文件(/var/run/docker.sock),容器逃逸就相当容易了,除非有进一步的权限限制。
下面通过一个小实验来展示这种逃逸可能性:
1.准备 dockertest 镜像,该镜像是基于 ubuntu 镜像安装 docker,通过 docker commit 生成
2.创建一个容器并挂载/var/run/docker.sock
[root@bpftest ~]#docker run -itd --name with_docker_sock -v /var/run/docker.sock:/var/run/docker.sock dockertest
3.接着使用该客户端通过 Docker Socket 与 Docker 守护进程通信,发送命令创建并运行一个新的容器,将宿主机的根目录挂载到新创建的容器内部;
[root@bpftest ~]#docker exec -it/bin/bash [root@bpftest ~]#docker ps [root@bpftest ~]#docker run -it -v /:/host dockertest /bin/bash
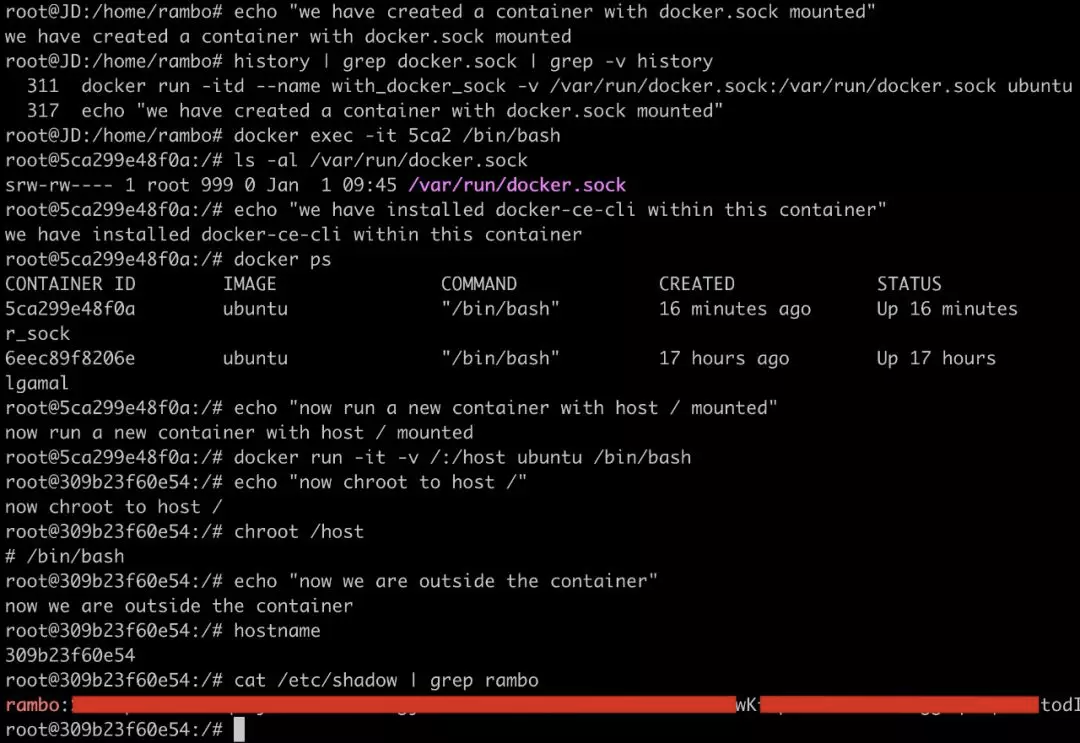
❏ 相关程序漏洞导致容器逃逸,例如:runc 漏洞 CVE-2019-5736 导致容器逃逸。
❏ 内核漏洞导致容器逃逸,例如:Copy_on_Write 脏牛漏洞,向 vDSO 内写入 shellcode 并劫持正常函数的调用过程,导致容器逃逸。
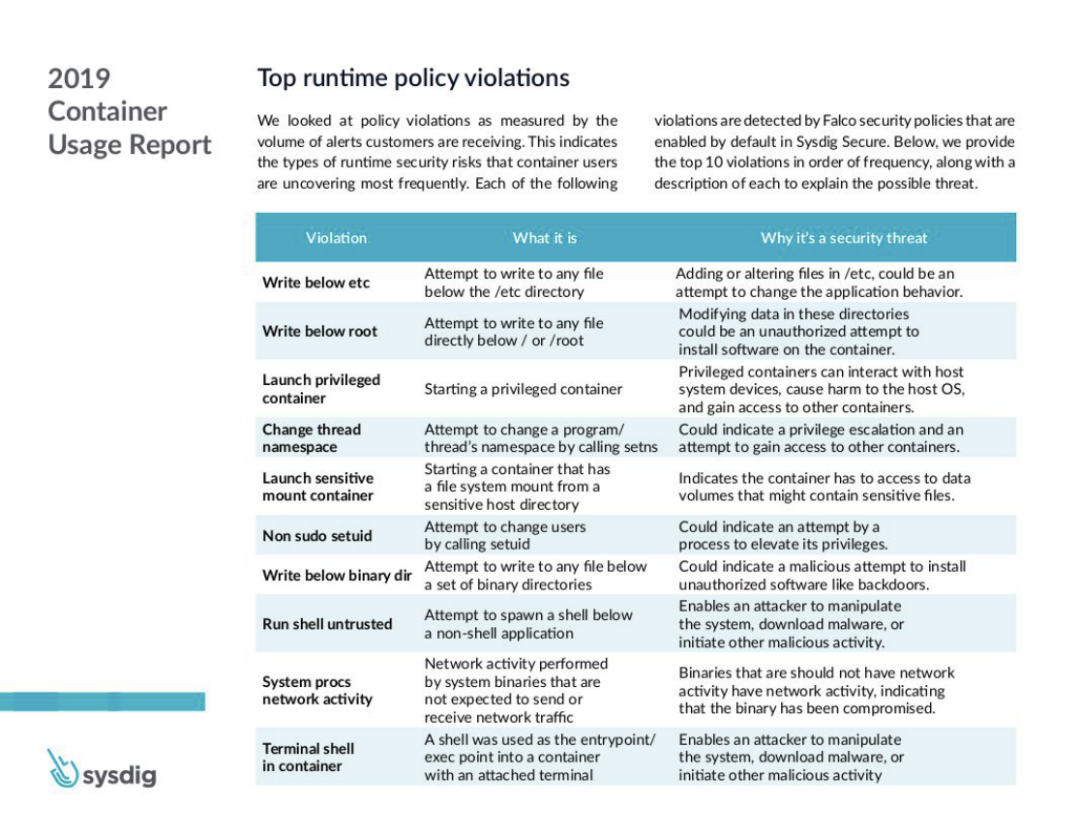
下面是 2019 年排名最高的容器安全事故列表:
6 容器安全主控引擎
6.1 主机和容器异常活动的检测
确保容器运行时安全的关键点:
❏ 降低容器的攻击面,每个容器以最小权限运行,包括容器挂载的文件系统、网络控制、运行命令等。
❏ 确保每个用户对不同的容器拥有合适的权限。
❏ 使用安全容器控制容器之间的访问。当前,Linux 的 Docker 容器技术隔离技术采用 Namespace 和 Cgroups 无法阻止提权攻击或打破沙箱的攻击。
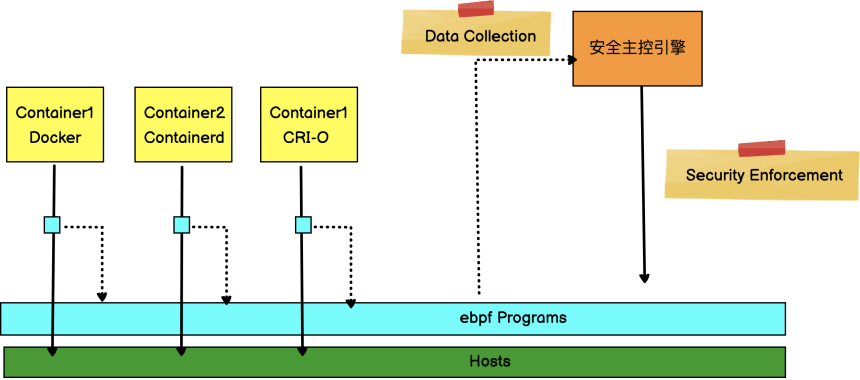
❏ 使用 ebpf 跟踪技术自动生成容器访问控制权限。包括:容器对文件的可疑访问,容器对系统的可疑调用,容器之间的可疑互访,检测容器的异常进程,对可疑行为进行取证。例如:
❏ 检测容器运行时是否创建其他进程。
❏ 检测容器运行时是否存在文件系统读取和写入的异常行为,例如在运行的容器中安装了新软件包或者更新配置。
❏ 检测容器运行时是否打开了新的监听端口或者建立意外连接的异常网络活动。
❏ 检测容器中用户操作及可疑的 shell 脚本的执行。
6.2 隔离有问题的容器和节点
如果检测到有问题的容器或节点,可以将节点设置为维护状态,或使用网络策略隔离有问题的容器,或将 deployment 的副本数设置为 0,删除有问题的容器。同时,使用 sidecar WAF,进行虚拟补丁等进行容器应用安全防范。
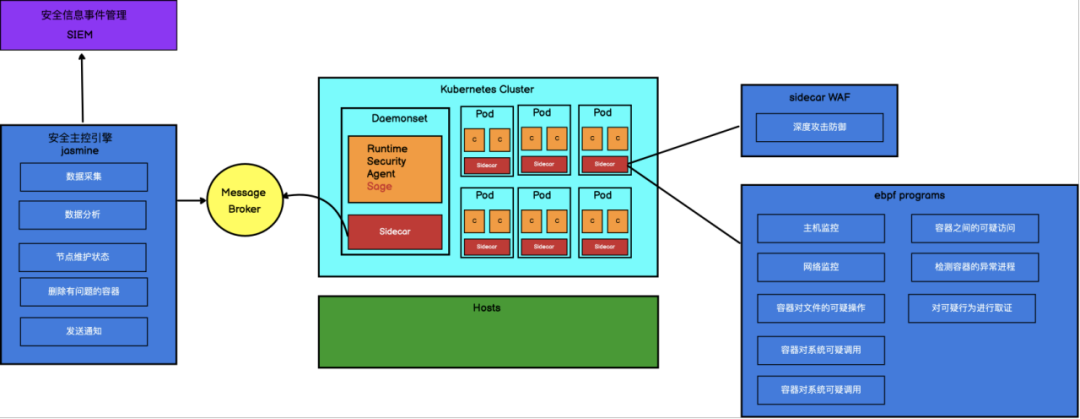
6.3 大型公有云容器平台安全主控引擎
下面是天翼云云容器引擎产品为了保证容器运行时安全实现的安全主控引擎:
❏ Pod 通过 sidecar 注入 WAF 组件对容器进行深度攻击防御。
❏ 容器安全代理 Sage 组件以 Daemonset 形式部署在各个节点上,用来收集容器和主机异常行为,并通过自己的 sidecar 推送到消息队列中。
❏ 安全主控引擎组件 jasmine 从消息队列中拉取事件,对数据进行分析,对有故障的容器和主机进行隔离。并将事件推送给 SIEM 安全信息事件管理平台进行管理。
-
dos技术知识的经典资料2008-06-17 5239
-
有谁能多介绍些AD的实践经验吗?2013-04-03 2135
-
实践经验还是理论学习2014-03-10 2241
-
请问有关于STM32普通IO口模拟操作SMBus通信的相关实践经验吗?2018-10-22 4962
-
工业吸尘吸水机谷歌优化推广,12年实践经验2020-10-28 3724
-
LED技术知识2009-12-04 437
-
LCOS技术知识集锦2009-05-09 2816
-
音箱技术知识2015-11-03 953
-
标准接口的基础技术知识2017-01-24 887
-
不同行业客户如何利用物联网平台的实践经验案例分析2017-12-01 5986
-
OpenHarmony Tech Day技术日 创新教育教学实践经验分享2022-04-25 1641
-
使用Koordinator支持异构资源管理和任务调度场景的实践经验2023-08-15 2455
-
OFDM技术知识点2023-11-18 844
-
中科曙光凭借技术优势以及实践经验获颁“核心参编单位”证书2024-03-25 1952
-
天合储能在系统安全设计与防爆防控方面的实践经验2025-10-29 838
全部0条评论

快来发表一下你的评论吧 !
