

SmartNIC、DPU和IPU的定义和分类
电子说
描述
关于SmartNIC、DPU、IPU的定义和分类,在上一篇发布了STH的NIC分类框架之后,觉得这个分类有很大的问题。每家的功能集合不同,即使同一个功能,定义也不完全相同。并且,具体的实现形态还有不同:有FPGA的实现、NP的实现以及芯片的实现。如果把把这些具体的因素都考虑进去以后,整个定义和分类逻辑会非常混乱。
本文透过现象看本质:忽略具体的实现形态,只考虑实现的功能;并且,我们把具体功能抽象化,避免不同厂家具体产品功能集的不同以及功能定义的差异导致的划分困难和混淆。基于上述两个原则,站在软硬件融合的视角,给出了SmartNIC、DPU和IPU的定义。
1 软硬件融合基础
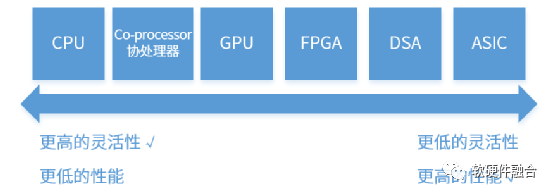
按照单位计算(指令)的复杂度,处理器平台大致分为CPU、协处理器、GPU、FPGA、DSA和ASIC。从左往右,单位计算越来越复杂,灵活性越来越低。
随着软件新技术不断涌现以及技术的迭代越来越快,但硬件规模越来越大但更新换代却越来越慢。芯片开发高投入高风险等,严重制约着软件的进一步发展空间。
软硬件融合,强调要在更系统的层次理解软件和硬件,以及两者之间的关系和相互作用。在架构上指的是CPU+协处理器+GPU+FPGA+DSA+ASIC的超异构混合架构。目标是让硬件更加灵活、弹性、可扩展,弥补硬件和软件之间的鸿沟,并且能够兼顾软件灵活性和硬件高性能,实现既要又要。
2 DPU/IPU的本质
2.1 名称解释
SmartNIC,智能网卡;
DPU,Data Processing Unit,数据处理器;
IPU,Infrastructure Processing Unit,基础设施处理器;
eIPU,elastic IPU,弹性的基础设施处理器。
2.2 CPU性能瓶颈,必须卸载和加速
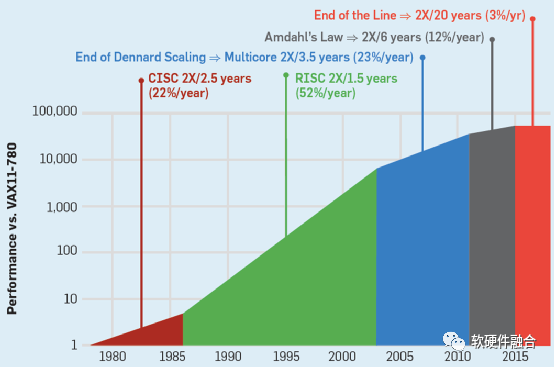
上世纪80-90年代,每18个月,CPU性能提升一倍,这就是著名的摩尔定律。如今,CPU性能提升每年只有3%,要想性能翻倍,需要20年。CPU的性能提升已经达到瓶颈。
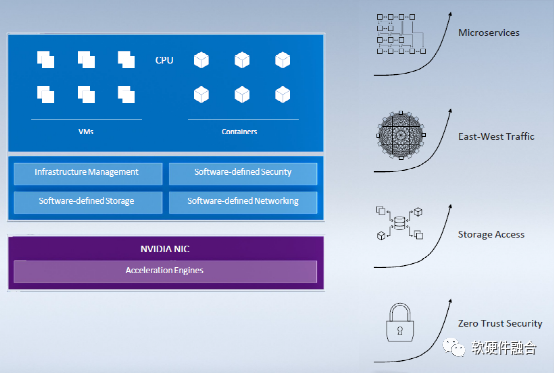
因此,随着网络、存储等IO的处理带宽增加,各种相关的IO处理对CPU的消耗呈现完全增长的局面。这样,底层基础设施Workload所占的CPU资源越来越多,留给用户应用的CPU资源越来越少。
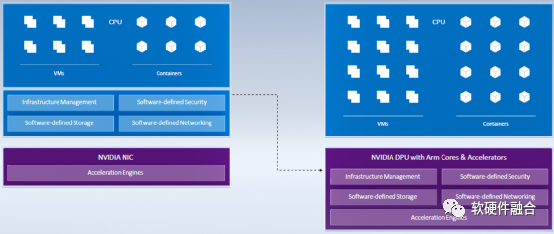
这样,把基础设施层的所有任务都从Host CPU转移到DPU或IPU中,把CPU完整的交给业务应用,达到了业务和管理分离。
业务和管理分离是云运营商最看中的价值,其优势体现在:
CPU资源完全交付;
更高可扩展性,灵活主机配置;
传统客户方便上云(虚拟化嵌套);
主机侧安全访问;
物理机的性能 + 虚拟机的可扩展性及高可用;
统一公有云和私有云运维。
2.3 卸载和加速的区别
卸载不一定加速,加速不一定卸载。
一个Workload在CPU运行,则定义为软件运行。一个任务在协处理器、GPU、FPGA、DSA或ASIC运行,则定义为硬件加速运行。
在CPU和DPU/IPU的场景下,卸载指的是把一个Workload从上面的CPU卸载到DPU/IPU。根据卸载的完整与否,卸载可以分为:
部分卸载,只卸载数据面,控制面依然在Host CPU;
完全卸载,数据面和控制面都卸载,控制面运行在DPU/IPU内部的嵌入式CPU。
根据数据面卸载到的处理引擎不同,可以将卸载分为:
软件卸载,即将Workload从Host CPU卸载到DPU/IPU内部的嵌入式CPU;
硬件加速卸载,即将Workload的数据面完全由DPU/IPU内部的其他类型(协处理器、GPU、FPGA、DSA、ASIC)硬件加速引擎来处理。
加速和卸载最大的区别在于,加速一般是一个系统内的协作,基于CPU+xPU的架构,把系统内可加速部分拆分到xPU去运行。而卸载更多强调的是两个系统间的协作,把一个系统卸载到另一个运行实体,然后通过特定的接口交互。
2.4 DPU/IPU的核心功能和扩展功能
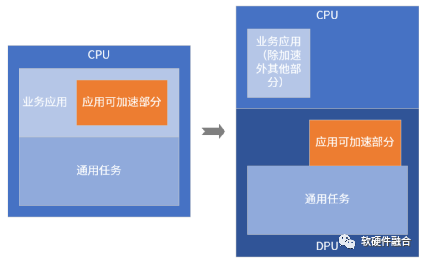
DPU/IPU所做的事情,简单来说,分为两类:
第一类是处于应用之下的各种通用任务的卸载&加速,这类工作属于DPU的“本职”工作。因此,DPU/IPU的核心功能是通用任务的卸载和加速。
另一类,是业务应用的加速。这一类工作通常是独立GPU和AI等加速器要做的工作。但是,在一些轻量的场景,独立的加速器有些浪费。在DPU内部集成业务加速引擎,可以有效降低数据交互的代价,使得整个计算更加高效。因此,DPU/IPU的扩展功能是业务应用的弹性加速。
2.5 卸载是一个过程:系统从软件向硬件逐步沉淀
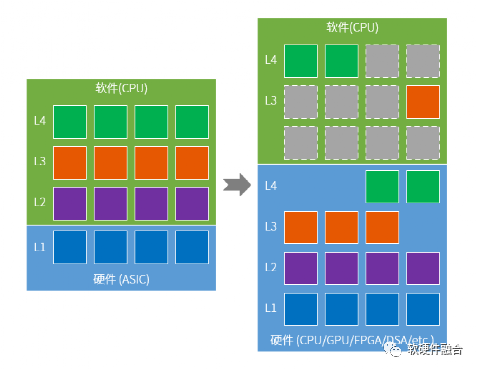
CPU已经达到性能瓶颈,随着整个系统的算力需求依然不断的上升。这样,系统中的工作任务势必不断的从CPU软件卸载到DPU/IPU中的 “硬件”进行加速。
但,从系统从软件卸载到硬件,不是一个一蹴而就的事情,而是一个长期的过程。因此,我们需要有一个很好的平台框架来支持任务持续不断的卸载到硬件来加速。
3 BasicNIC - SmartNIC - DPU - IPU - eIPU
3.1 综述
SmartNIC/DPU/IPU有各种不同形态的实现,比如基于Network Processor的实现、基于FPGA+CPU的实现,或者基于单芯片SOC的实现。如果要考虑各种不同形态的实现载体,也要考虑具体的功能分类,那势必对SmartNIC/DPU/IPU的划分会五花八门,这样反而会混淆对整件事情的认知。
软硬件融合对SmartNIC/DPU/IPU的定义:
透过现象看本质,忽略具体的实现形态,只考虑实现的功能;
把功能抽象化,避免不同厂家具体产品功能集的不同以及功能定义的差异导致的划分困难和混淆。
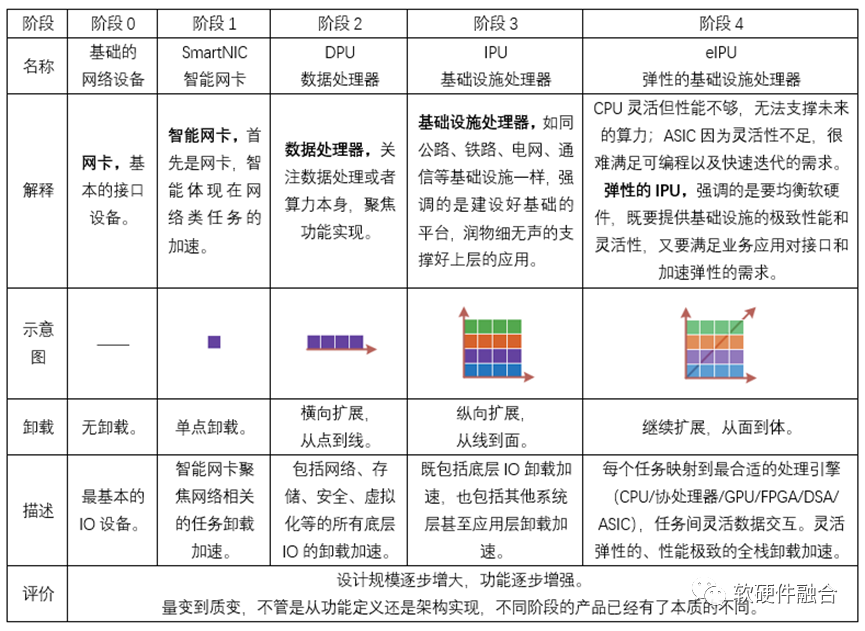
我们认为,从基础的网络设备,发展到后面的eIPU,是一个设计规模逐步增大,功能逐步增强的过程。具体如下表所示。
注意:需要强调的是,这里的每个阶段的名称和其他各个厂家命名的SmartNIC、DPU、IPU的概念并不一一对应。
3.2 基础状态,标准NIC,无卸载
最开始的状态,严格来说,应该是IO设备,而不仅仅是网络设备。至少还有一个需要考虑的高速IO设备:存储控制器。
但考虑到,我们讨论的这个处理设备,一端是要支持PCIe接口,另一端需要支持高速网络接口,跟网络NIC非常接近。因此,我们可以当做是在标准NIC上的扩展,不断的叠加新的功能,包括叠加存储控制器以及其他存储相关功能。
标准NIC,不支持Workload的卸载,主要是接口卡的功能,内部完成TCP/IP层以下PHY/MAC层的工作。几乎所有现代NIC都有一些非常基本的卸载,例如CRC校验和大包的拆包/封包。案例如Intel经典网卡82599系列,这里不做详细介绍。
3.3 第一阶段,SmartNIC,卸载单点的网络
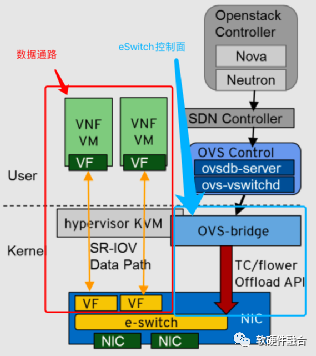
SmartNIC最经典案例是NVIDIA Networking的CX5系列。CX5支持ASAP2加速,可以把网络相关Workload卸载到eSwitch,即Fast path跑在硬件中,只有Slow path及控制面需要送到Host CPU。
在CX5中不具有独立的CPU运行OS和软件,因此所有的相关软件部分依然运行在Host CPU。
3.4 第二阶段,DPU,卸载IO底层处理,横向扩展成线
云计算数据中心的每一台服务器和交换机都运行独立的堆栈,然后这些分布式的堆栈使得整个数据中心组成了一个完全池化的超级仓储计算机。每台服务器运行的复杂的、分层的系统,CPU性能瓶颈已经不堪重负。并且,数据中心的规模都日益庞大,一些主流的云运营商动辄百万台以上的服务器规模。
量变引起质变,这些趋势促使了一个效果:运行在每台服务器的底层Workload变的越来越趋同,例如,虚拟网络、分布式存储、安全加解密、虚拟化和容器等任务几乎存在于每台服务器中。DPU/IPU最核心的功能,就是要进行这些规模庞大的、性能敏感的通用任务的加速,这样才能产生显著的性能的提升和成本的优化。
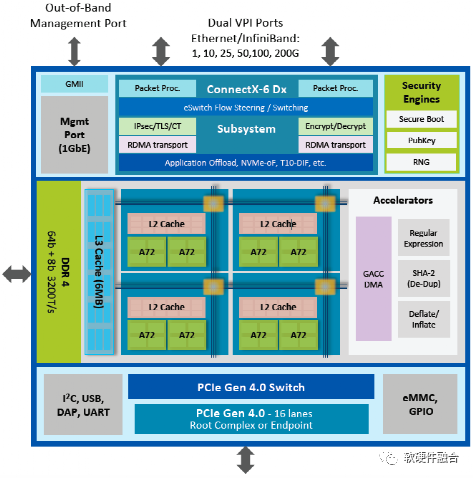
NVIDIA BlueField-2是一个高度集成的DPU,集成ConnectX-6 DX网络适配器与ARM处理器核阵列。BlueField-2 DPU:
通过ASAP2的网络加速方案以及完整的数据面及控制面卸载,可以高效、高性能的支持虚拟化、裸金属、边缘计算场景的快速部署;
通过SNAP机制为存储提供完整的端到端解决方案;
集成了各种安全加速,可以为数据中心提供隔离、安全性和加解密加速功能;
集成的ARM Core可以运行基础设施层的虚拟化、管理监控等功能。
除了NVIDIA Bluefield DPU之外,其他可以划归到DPU分类的产品有:
NITRO系统。Nitro系统用于为AWS EC2实例类型提供网络硬件卸载、EBS存储硬件卸载、NVMe本地存储、远程直接内存访问(RDMA)、裸金属实例的硬件保护/固件验证以及控制EC2实例所需的所有业务逻辑等。
Fungible DPU。Fungible DPU采用通用多线程处理器,结合标准以太网和PCIe接口。其他硬件组件包括高性能的片上Fabric、定制的内存系统、一套完整的灵活数据加速器、可编程网络硬件流水线、可编程PCIe硬件流水线。
Pensando DPU。包括网络功能(交换和路由、L3 ECMP, L4负载均衡、Overlay网络VXLAN等、IP-NAT等)、安全功能(微分段、DoS保护、IPsec终止、TLS/DTLS终止等)以及存储功能(NVMe over TCP/RoCEv2、压缩/解压、加密/解密、SHA3重复数据删除、CRC64/32校验和等)。
Intel IPU。IPU使用专用协议加速器加速基础设施功能,包括存储虚拟化、网络虚拟化和安全性。允许灵活的工作负载放置来提高数据中心利用率。
Marvell DPU。Marvell OCTEON 10集成ARM Neoverse N2内核、1Tb的交换机,支持内联加密,基于VPP的硬件加速器可将数据包处理速度提高多达5倍,基于机器学习的硬件加速引擎比软件处理性能提升100倍。
3.5 第三阶段,IPU,卸载更多层次的工作任务,纵向扩展从线成面
IPU阶段,最显著的特点是把业务加速也集成进来,这是DPU/IPU的一个长期的目标。但业务加速跟底层的通用任务加速相比,具有一些新的挑战:
一方面,业务应用五花八门,远比底层任务要数量众多。具体到每台服务器要运行什么任务,是完全未知的;
另一方面,业务系统和算法通常处于一个快速迭代持续更新的状态,这样,势必要求硬件加速引擎也能够快速编程和快速更新。
基于上述挑战,业务加速需要的是一个足够弹性的、可快速编程的,并且具有显著加速效果的加速平台。因为研发、运维和性能/成本等多方面考虑,这个平台还需要规模足够庞大,并且硬件完全一致性。
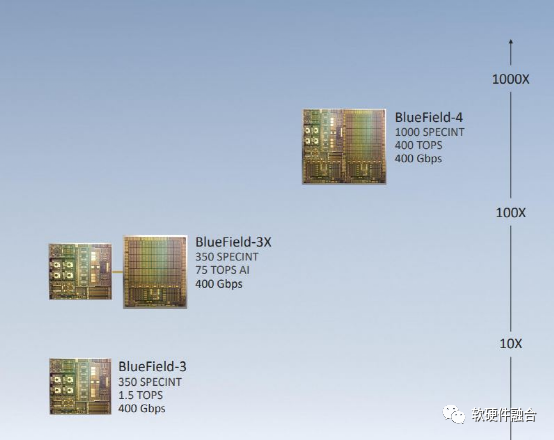
严格来说,目前还没有符合IPU阶段的产品面市。但有一些这方面的趋势:
添加AI加速。NVIDIA在即将发布的Bluefield-3X板卡集成独立DPU和独立AI两颗芯片,而Bluefield-4则是单芯片集成DPU+AI加速器。而Marvell先NVIDIA一步,率先发布了集成AI推理加速引擎的OCTEON 10 DPU。
添加FPGA弹性加速。Intel IPU和Xilinx SmartNIC当前都是FPGA+CPU的架构的,理论上可以通过FPGA编程的方式快速实现。但“用户要的是牛奶,而不是奶牛”,不是简单的把一个完整的FPGA交给用户就OK。而是要像FaaS那样,把基础的环境准备好,用户只是开发主机的加速内核和相应的控制面驱动而已。
3.6 第四阶段,eIPU,任务引擎软硬件均衡,扩展从面成体
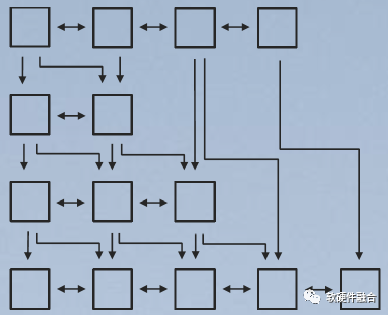
在eIPU阶段,把每个Workload均细致的权衡,把它映射到最合适的处理引擎,CPU、ASIC、DSA或者GPU、FPGA。并且,处理引擎间能够实现完全灵活的任务间数据交互,包括对外部提供的接口,就如同软件的IPC/RPC/Restful等交互接口一样灵活。
eIPU是众多Workload的集合体:
在内部,每个Workload均运行在最合适的处理器引擎,可以达到最极致的性能;
在内部,Workload之间的数据交互足够高性能足够灵活;
对外部,提供类似软件的服务API接口。
微服务无处不在,把eIPU融入到微服务体系中去。eIPU既是微服务供其他微服务调用,同时,eIPU也可以调用其他微服务。
4 总结,DPU/IPU成功的关键,平衡好性能和灵活性

DPU/IPU本质上是在做硬件加速。站在硬件加速的角度,数据中心的整个计算架构跟手机端完全没法比。如上图所示,是高通在2014年发布的骁龙810处理器SOC的布局图。手机端一直都是CPU+各种加速器的混合计算架构。
在手机端已经非常成熟的架构,在数据中心端为何如此姗姗来迟?原因在于,数据中心中业务应用的Workload,具有非常大的不确定性,因此需要提供足够通用和灵活的计算平台:
最开始,性能不是问题,CPU是最优的选择;
随着人工智能兴起后,对算力的需求越来越高。这才有了GPU平台的兴起;
即使对算力如此渴求,DSA类加速的AI处理器依然没有形成大规模落地,支撑AI训练和推理的还主要是GPU平台。
这说明一个道理:在数据中心领域(或者说高速迭代的复杂场景),如果不能提供灵活性(或者说易用性、可编程性),提供再多的性能都是“无本之木”。
反过来,如果想提供尽可能好的灵活性,最极端的做法依然是采用CPU。但这个设计要么性能不够,要么代价太高。
基于平衡灵活性和性能的考虑,最优的设计应该是:在满足一定的成本约束条件下,在提供一定灵活可编程能力的情况下,提供最极致的性能。
审核编辑:刘清
-
Napatech IPU解决方案助力优化数据中心存储工作负载2024-05-29 1621
-
什么是DPU?2023-11-03 1774
-
IPU和CXL如何提高数据中心的电源效率?2023-04-17 2319
-
基于FPGA的SmartNIC技术及其在数据中心的应用2022-08-02 2702
-
关于SmartNIC和DPU之间的疑惑2022-07-07 1625
-
从SmartNIC走向DPU,专用加速器的崛起2022-06-25 6073
-
芯启源首次公开"SmartNIC第四代架构"如何赋能DPU蓝海2022-05-05 4860
-
如何构建基于DPU的SmartNIC2022-04-19 2378
-
专⽤数据处理器 (DPU) 技术⽩⽪书2022-03-14 7166
-
Fungible和英伟达在DPU赛道上的进展2022-03-08 3628
-
DPU赛道火热,初创公司赢面更大?2022-03-04 4834
-
关于DPU的那些事2021-10-13 4227
-
PCIe的SmartNIC如何改变方案加速规则2021-01-07 1945
全部0条评论

快来发表一下你的评论吧 !
