

内存计算架构的原理及无晶体管CIM架构的器件物理特性
电子说
描述
为了推进人工智能,宾夕法尼亚大学的研究人员最近开发了一种新的内存计算 (CIM) 架构,用于数据密集型计算。CIM 在大数据应用方面具有诸多优势,UPenn 集团在生产小型、强大的 CIM 电路方面迈出了第一步。
在本文中,我们将深入研究 CIM 的原理和支持研究人员无晶体管 CIM 架构的器件物理特性。
为什么要在内存中计算?
传统上,计算主要依赖于基于冯诺依曼架构的互连设备。在此架构的简化版本中,存在三个计算构建块:内存、输入/输出 (I/O) 接口和中央处理单元 (CPU)。
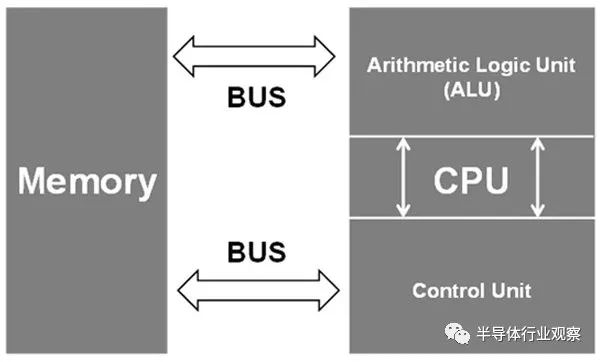
每个构建块都可以根据 CPU 给出的指令与其他构建块交互。然而,随着 CPU 速度的提高,内存访问速度会大大降低整个系统的性能。这在需要大量数据的人工智能等数据密集型用例中更为复杂。此外,如果内存未与处理器位于同一位置,则基本光速限制会进一步降低性能。
所有这些问题都可以通过 CIM 系统来解决。在 CIM 系统中,内存块和处理器之间的距离大大缩短,内存传输速度可能会更高,从而可以更快地计算。
氮化钪铝(Aluminum Scandium Nitride):内置高效内存
UPenn 的 CIM 系统利用氮化钪铝(AlScN) 的独特材料特性来生产小型高效的内存块。AlScN 是一种铁电材料,这意味着它可能会响应外部电场而变得电极化。通过改变施加的电场超过某个阈值,铁电二极管 (FeD) 可以被编程为低电阻或高电阻状态(分别为 LRS 或 HRS)。

除了作为存储单元的可操作性之外,AlScN 还可用于创建没有晶体管的三元内容可寻址存储 (TCAM) 单元。TCAM 单元对于大数据应用程序极为重要,因为使用冯诺依曼架构搜索数据可能非常耗时。使用 LRS 和 HRS 状态的组合,研究人员实现了一个有效的三态并联,所有这些都没有使用晶体管。
使用无晶体管 CIM 阵列的神经网络
为了展示 AlScN 执行 CIM 操作的能力,UPenn 小组开发了一个使用 FeD 阵列的卷积神经网络 (CNN)。该阵列通过对输入电压产生的输出电流求和来有效地完成矩阵乘法。权重矩阵(即输出电流和输入电压之间的关系)可以通过修改cell的电导率来调整到离散水平。这种调谐是通过偏置 AlScN 薄膜以表现出所需的电导来实现的。
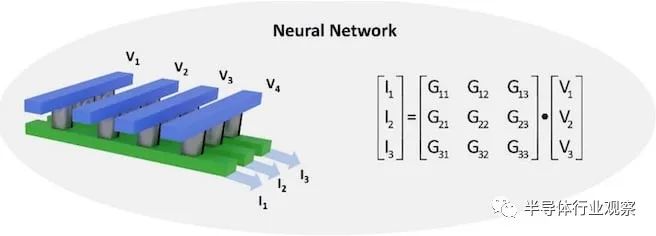
AlScN CNN 仅使用 4 位电导率分辨率就成功地从MNIST 数据集中识别出手写数字,与 32 位浮点软件相比,降级约为 2%。此外,没有晶体管使架构简单且可扩展,使其成为未来需要高性能矩阵代数的人工智能应用的优秀计算技术。
打破冯诺依曼瓶颈
在其存在的大部分时间里,人工智能计算主要是一个软件领域。然而,随着问题变得更加数据密集,冯诺依曼瓶颈对系统有效计算的能力产生了更深的影响,使得非常规架构变得更有价值。
基于 AlScN FeD 的模拟 CIM 系统消除了训练和评估神经网络延迟的主要原因,使它们更容易在现场部署。与现有硅硬件集成的 AlScN 设备的多功能性可能会为将 AI 集成到更多领域提供开创性的方法。
原文:重新思考人工智能时代的计算机芯片
人工智能对传统计算架构提出了重大挑战。在标准模型中,内存存储和计算发生在机器的不同部分,数据必须从其存储区域移动到 CPU 或 GPU 进行处理。
这种设计的问题是移动需要时间,太多时间。你可以拥有市场上最强大的处理单元,但它的性能将受到限制,因为它会等待数据,这个问题被称为“内存墙”或“瓶颈”。
当计算性能优于内存传输时,延迟是不可避免的。在处理机器学习和人工智能应用程序所必需的大量数据时,这些延迟成为严重的问题。
随着人工智能软件的不断发展,传感器密集型物联网的兴起产生了越来越大的数据集,研究人员已将注意力集中在硬件重新设计上,以在速度、敏捷性和能源使用方面提供所需的改进。
宾夕法尼亚大学工程与应用科学学院的一组研究人员与桑迪亚国家实验室和布鲁克海文国家实验室的科学家合作,推出了一种非常适合人工智能的计算架构。
该项目由电气与系统工程 (ESE) 系助理教授Deep Jariwala 、ESE副教授Troy Olsson和博士刘希文共同领导。作为 Jarawala设备研究和工程实验室的候选人,该研究小组依靠一种称为内存计算 (CIM) 的方法。
在 CIM 架构中,处理和存储发生在同一个地方,从而消除了传输时间并最大限度地减少了能源消耗。该团队的新 CIM 设计是最近发表在Nano Letters上的一项研究的主题,以完全无晶体管而著称。这种设计独特地适应了大数据应用程序改变计算性质的方式。
“即使在内存计算架构中使用,晶体管也会影响数据的访问时间,”Jariwala 说。“它们需要在芯片的整个电路中进行大量布线,因此使用的时间、空间和能量超出了我们对人工智能应用的期望。我们无晶体管设计的美妙之处在于它简单、小巧、快速,并且只需要很少的能量。”
该架构的进步不仅体现在电路级设计。这种新的计算架构建立在该团队早期在材料科学方面的工作之上,该工作专注于一种称为钪合金氮化铝 (AlScN) 的半导体。AlScN 允许铁电开关,其物理特性比替代的非易失性存储元件更快、更节能。
“这种材料的一个关键属性是它可以在足够低的温度下沉积以与硅制造厂兼容,”Olsson 说。“大多数铁电材料需要更高的温度。AlScN 的特殊性能意味着我们展示的存储设备可以在垂直异质集成堆栈中的硅层顶部。想想一个可容纳一百辆汽车的多层停车场和分布在一个地块上的一百个独立停车位之间的区别。哪个在空间方面更有效?像我们这样高度微型化的芯片中的信息和设备也是如此。这种效率对于需要资源限制的应用程序(例如移动或可穿戴设备)和对能源极其密集的应用程序(例如数据中心)同样重要。”
2021 年,该团队确立了 AlScN作为内存计算强国的可行性。它在小型化、低成本、资源效率、易于制造和商业可行性方面的能力在研究和工业界都取得了重大进展。
在最近首次推出无晶体管设计的研究中,该团队观察到他们的 CIM 铁二极管的执行速度可能比传统计算架构快 100 倍。
该领域的其他研究已成功使用内存计算架构来提高 AI 应用程序的性能。然而,这些解决方案受到限制,无法克服性能和灵活性之间的矛盾权衡。使用忆阻器交叉阵列的计算架构,一种模仿人脑结构以支持神经网络操作的高级性能的设计,也展示了令人钦佩的速度。
然而,使用多层算法来解释数据和识别模式的神经网络操作只是功能性 AI 所需的几个关键数据任务类别之一。该设计的适应性不足以为任何其他 AI 数据操作提供足够的性能。
Penn 团队的铁二极管设计提供了其他内存计算架构所没有的突破性灵活性。它实现了卓越的准确性,在构成有效 AI 应用程序基础的三种基本数据操作中表现同样出色。它支持片上存储,或容纳深度学习所需的海量数据的能力,并行搜索,一种允许精确数据过滤和分析的功能,以及矩阵乘法加速,神经网络计算的核心过程。
“假设,”Jariwala 说,“你有一个 AI 应用程序,它需要大内存来存储以及进行模式识别和搜索的能力。想想自动驾驶汽车或自主机器人,它们需要快速准确地响应动态、不可预测的环境。使用传统架构,您需要为每个功能使用不同的芯片区域,并且您会很快耗尽可用性和空间。我们的铁二极管设计允许您通过简单地更改施加电压的方式对其进行编程,从而在一个地方完成所有工作。”
可以适应多种数据操作的 CIM 芯片的回报是显而易见的:当团队通过他们的芯片运行机器学习任务的模拟时,它的执行精度与在传统 CPU 上运行的基于 AI 的软件相当。
“这项研究非常重要,因为它证明我们可以依靠内存技术来开发集成多个人工智能数据应用程序的芯片,从而真正挑战传统计算技术,”该研究的第一作者刘说。
该团队的设计方法是考虑到人工智能既不是硬件也不是软件,而是两者之间必不可少的协作。
“重要的是要意识到,目前完成的所有人工智能计算都是在几十年前设计的硅硬件架构上启用软件的,”Jariwala 说。“这就是为什么人工智能作为一个领域一直由计算机和软件工程师主导。从根本上重新设计人工智能硬件将成为半导体和微电子领域的下一个重大变革。我们现在的方向是软硬件协同设计。”
“我们设计的硬件可以让软件更好地工作,”Liu 补充道,“通过这种新架构,我们确保技术不仅快速而且准确。”
审核编辑:郭婷
-
晶体管的结构特性2013-08-17 3914
-
功率晶体管(GTR)的特性2018-01-15 6060
-
直接驱动GaN晶体管的优点2020-10-27 1783
-
绝缘门/双极性晶体管介绍与特性2022-04-29 9793
-
什么是晶体管 晶体管的分类及主要参数2023-02-03 2663
-
什么是达林顿晶体管?2023-02-16 2155
-
什么是鳍式场效应晶体管?鳍式场效应晶体管有哪些优缺点?2023-02-24 14838
-
晶体管特性图示仪,晶体管特性图示仪是什么意思2010-03-05 3852
-
一种新的内存计算 (CIM) 架构原理分析2022-10-13 3976
-
实现无晶体管CIM架构的器件物理特性2022-10-24 1980
-
一种无晶体管的内存计算架构的原理和器件物理特性2022-11-03 1294
-
为什么晶体管有高低频的特性?2023-09-20 2086
-
什么是晶体管?晶体管的种类及其特性2023-09-27 14778
-
晶体管计算机的主要物理元件为2024-02-02 2163
-
晶体管架构的演变过程2025-07-08 2761
全部0条评论

快来发表一下你的评论吧 !
