

Java与云原生的矛盾原因
电子说
描述
0. 前言
前阵子在 B 站刷到了周志明博士的视频,主题是云原生时代下 Java,主要内容是云原生时代下的挑战与 Java 社区的对策。这个视频我在两年前看到过,当时也是印象深刻。现在笔者也是想和大家一起看看相关项目的推进以及一些细节。这篇笔记会大量参考视频中提到的内容,如果读者看过相关视频,可以跳过这篇笔记。
视频分享中提到,Java 与云原生的矛盾大概原因有二:
首当其冲的是 Java 的“一次编写,到处运行”(Write Once, Run Anywhere) 。在当年是非常好的做法,直接开启了许多托管语言的兴盛期。但云原生时代大家会选择以隔离的方式,通过容器实现的不可变基础设施去解决。虽然容器的“一次构建,到处运行”(Build Once, Run Anywhere)和 Java 的“一次编写,到处运行”(Write Once, Run Anywhere)并不是一个 Level 的——容器只能提供环境兼容性和有局限的平台无关性(指系统内核功能以上的 ABI 兼容),但服务端的应用都跑在 Linux 上,所以对于业务来说也无伤大雅。
其二,则是 Java 总体上是面向长时间的“巨塔式”服务端应用而设计的 :
静态类型动态链接的语言结构,利于多人协作开发,让软件触及更大规模;
即时编译器、性能制导优化、垃圾收集子系统等 Java 最具代表性的技术特征,都是为了便于长时间运行的程序能享受到硬件规模发展的红利。
但在,微服务时代是提倡服务围绕业务能力(不同的语言适合不同的业务场景)而非技术来构建应用,不再追求实现上的一致。一个系统由不同语言、不同技术框架所实现的服务来组成是完全合理的。
服务化拆分后,很可能单个微服务不再需要再面对数十、数百 GB 乃至 TB 的内存。有了高可用的服务集群,也无须追求单个服务要 7×24 小时不可间断地运行,它们随时可以中断和更新。不仅如此,微服务对镜像体积、内存消耗、启动速度,以及达到最高性能的时间等方面提出了新的要求。这两年的网红概念 Serverless(以及衍生出来的 Faas) 也进一步增加这些因素的考虑权重。
而这些却正好都是 Java 的弱项:哪怕再小的 Java 程序也要带着厚重的 Rumtime(Vm 和 StandLibrary)——基于 Java 虚拟机的执行机制,使得任何 Java 的程序都会有固定的内存开销与启动时间,而且 Java 生态中广泛采用的依赖注入进一步将启动时间拉长,使得容器的冷启动时间很难缩短。
举两个例子。
软件工业中已经出现过不止一起因 Java 这些弱点而导致失败的案例。如 JRuby 编写的 Logstash,原本是同时承担部署在节点上的收集端(Shipper)和专门转换处理的服务端(Master)的职责,后来因为资源占用的原因,被 Elstaic.co 用 Golang 的 Filebeat 代替了 Shipper 部分的职能。
又如 Scala 语言编写的边车代理 Linkerd,作为服务网格概念的提出者,却最终被 Envoy 所取代,其主要弱点之一也是由于 Java 虚拟机的资源消耗所带来的劣势。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://gitee.com/zhijiantianya/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
1. 变革之火
1.1 Complie Native Code
显然,如果将字节码直接编译成可以脱离 Java 虚拟机的原生代码则可以解决所有问题。
如果真的能够生成脱离 Java 虚拟机运行的原生程序,将意味着启动时间长的问题能够彻底解决,因为此时已经不存在初始化虚拟机和类加载的过程。也意味着程序马上就能达到最佳的性能,因为此时已经不存在即时编译器运行时编译,所有代码都是在编译期编译和优化好的。同理,厚重的 Runtime 也不会出现在镜像中。
Java 并非没有尝试走过这条路。
从 GCJ 到 Excelsior JET 再到 GraalVM 中的 SubstrateVM 模块再到 2020 年中期建立的 Leyden 项目,都在朝着提前编译(Ahead-of-Time Compilation,AOT)生成原生程序这个目标迈进。Java 支持提前编译最大的困难在于它是一门动态链接的语言,它假设程序的代码空间是开放的(Open World),允许在程序的任何时候通过类加载器去加载新的类,作为程序的一部分运行。要进行提前编译,就必须放弃这部分动态性,假设程序的代码空间是封闭的(Closed World),所有要运行的代码都必须在编译期全部可知。
这一点不仅仅影响到了类加载器的正常运作。除了无法再动态加载外,反射(通过反射可以调用在编译期不可知的方法)、动态代理、字节码生成库(如 CGLib)等一切会运行时产生新代码的功能都不再可用——如果将这些基础能力直接抽离掉,Hello world 还是能跑起来,大部分的生产力工具都跑不起来,整个 Java 生态中绝大多数上层建筑都会轰然崩塌。
随便列两个 Case:Flink 的 SQL API 会解析 SQL 并生成执行计划。这个时候会通过 JavaCC 动态生成类加载到代码空间中去;Spring 也有类似的情况,当 AOP 通过动态代理的方式去生成相关逻辑时,本质还是在 Runtime 时生成代码并加载进去。
要获得有实用价值的提前编译能力,只有依靠提前编译器、组件类库和开发者三方一起协同才可能办到——可以参考 Quarkus。
Quarkus 和我们上述的方法如出一辙,以 Dependency Inject 为例:所有要运行的代码都必须在编译期全部可知,在编译期就推导出来相关的 Bean,最后交给 GraalVM 来运行。
1.2 Memory Access Efficiency Improvement
Java 即时编译器的优化效果拔群,但是由于 Java “一切皆为对象”的前提假设,导致它在处理一系列不同类型的小对象时,内存访问性能很差。这点是 Java 在游戏、图形处理等领域一直难有建树的重要制约因素,也是 Java 建立 Valhalla 项目的目标初衷。
这里举个例子来说明此问题,如果我想描述空间里面若干条线段的集合,在 Java 中定义的代码会是这样的:
public record Point(float x, float y, float z) {}
public record Line(Point start, Point end) {}
Line[] lines;
面向对象的内存布局中,对象标识符(Object Identity)存在的目的是为了允许在不暴露对象结构的前提下,依然可以引用其属性与行为,这是面向对象编程中多态性的基础。在 Java 中堆内存分配和回收、空值判断、引用比较、同步锁等一系列功能都会涉及到对象标识符,内存访问也是依靠对象标识符来进行链式处理的,譬如上面代码中的“若干条线段的集合”,在堆内存中将构成如下图的引用关系:
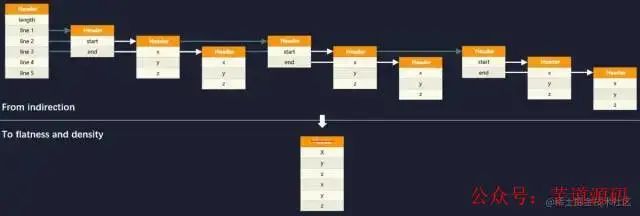
计算机硬件经过 25 年的发展,内存与处理器虽然都在进步,但是内存延迟与处理器执行性能之间的冯诺依曼瓶颈(Von Neumann Bottleneck)不仅没有缩减,反而还在持续加大,“RAM Is the New Disk”已经从嘲讽梗逐渐成为了现实。
一次内存访问(将主内存数据调入处理器 Cache)大约需要耗费数百个时钟周期,而大部分简单指令的执行只需要一个时钟周期而已。因此,在程序执行性能这个问题上,如果编译器能减少一次内存访问,可能比优化掉几十、几百条其他指令都来得更有效果。
额外知识:冯诺依曼瓶颈 不同处理器(现代处理器都集成了内存管理器,以前是在北桥芯片中)的内存延迟大概是 40-80 纳秒(ns,十亿分之一秒),而根据不同的时钟频率,一个时钟周期大概在 0.2-0.4 纳秒之间,如此短暂的时间内,即使真空中传播的光,也仅仅能够行进 10 厘米左右。
数据存储与处理器执行的速度矛盾 是冯诺依曼架构的主要局限性之一,1977 年的图灵奖得主 John Backus 提出了“冯诺依曼瓶颈”这个概念,专门用来描述这种局限性。
Java 编译器的确在努力减少内存访问,从 JDK 6 起,HotSpot 的即时编译器就尝试通过逃逸分析来做标量替换(Scalar Replacement)和栈上分配(Stack Allocations)优化。基本原理是,如果能通过分析得知一个对象不会传递到方法之外,那就不需要真实地在对象中创建完整的对象布局。完全可以绕过对象标识符,将它拆散为基本的原生数据类型来创建,甚至是直接在栈内存中分配空间(HotSpot 并没有这样做),方法执行完毕后随着栈帧一起销毁掉。
不过,逃逸分析是一种过程间优化(Interprocedural Optimization),非常耗时,也很难处理那些理论上有可能但实际不存在的情况。这意味着它是 Runtime 时发生的 。而相同的问题在 C、C++ 中却并不存在,上面场景中,程序员只要将 Point 和 Line 都定义为 struct 即可,C# 中也有 struct,是依靠 .NET 的值类型(Value Type)来实现的。这些语言在编译期就解决了这些问题。
而 Valhalla 的目标就是提供类似的值类型支持,提供一个新的关键字(inline),让用户可以在不需要向方法外部暴露对象、不需要多态性支持、不需要将对象用作同步锁的场合中,将类标识为值类型。此时编译器就能够绕过对象标识符,以平坦的、紧凑的方式去为对象分配内存。
Valhalla 目前还处于 Preview 阶段。可以在这里看到推进的情况。希望能在下个 LTS 版本正式用上它吧。
1.3 Coroutine
Java 语言抽象出来隐藏了各种操作系统线程差异性的统一线程接口,这曾经是它区别于其他编程语言的一大优势。不过,这也是曾经。
Java 目前主流的线程模型是直接映射到操作系统内核上的 1:1 模型,这对于计算密集型任务这很合适,既不用自己去做调度,也利于一条线程跑满整个处理器核心。但对于 I/O 密集型任务,譬如访问磁盘、访问数据库占主要时间的任务,这种模型就显得成本高昂,主要在于内存消耗和上下文切换上。
举个例子。64 位 Linux 上 HotSpot 的线程栈容量默认是 1MB,线程的内核元数据(Kernel Metadata)还要额外消耗 2-16KB 内存,所以单个虚拟机的最大线程数量一般只会设置到 200 至 400 条,当程序员把数以百万计的请求往线程池里面灌时,系统即便能处理得过来,其中的切换损耗也相当可观。
Loom 项目的目标是让 Java 支持额外 的 N:M 线程模型,而不是像当年从绿色线程过渡到内核线程那样的直接替换,也不是像 Solaris 平台的 HotSpot 虚拟机那样通过参数让用户二选其一。
Loom 要做的是一种有栈协程(Stackful Coroutine),多条虚拟线程可以映射到同一条物理线程之中,在用户空间中自行调度,每条虚拟线程的栈容量也可由用户自行决定。
此外,还有两个重点:
尽量兼容所有原接口。这意味着原来所有的线程接口都可以当作协程使用。但我觉得挺难的——假如里面的代码调到 Native 方法,这个 Stack 就和这个线程绑定了,毕竟 Coroutine 是个用户态的东西。
支持结构化并发:简单来说就是异步的代码写起来像同步的代码,这点 GO 做的很好。毕竟嵌套的回调函数着实让人痛苦。
上述的内容如果拆开来细说,基本就是:
协程的调度;
协程的同步、互斥与通讯;
协程的系统调用包装,尤其是网络 IO 请求的包装;
协程堆栈的自适应。
小知识:每个协程,都有一个自己专享的协程栈。这种需要一个辅助的栈来运行协程的机制,叫做 Stackful Coroutine;而在主栈上运行协程的机制,叫做 Stackless Coroutine。
Stackless Coroutine意味着:
运行时:活动记录放在主线程的栈上
暂停时:堆中保留活动记录
可以调用其他函数
只能在顶层暂停运行,不可以在子函数/子协程里暂停
而Stackfull Coroutine意味着:
运行时:单独的运行栈
可以在调用栈的任何一级暂停
生命周期可以超过它的创建者
可以从一线程上跑到另一个线程上
因此,一个完备的协程库基本顶得上一个操作系统里的进程部分了。只是它在用户态,进程在内核态。
这个项目可以在这里看到。目测 JDK 19 就可以尝尝鲜了。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
2. 小结
目前在云原生领域,Java 可能未必是好的选择——在这个领域最让人难以忍受的就是其庞大的 Runtime 以及较长的 Startup 时间,在以前这是 Java 优点的来源,但到了云原生时代,则成了 Java 显而易见弱点。因此 Java 想在云原生时代继续保持前几十年的趋势,解决这个问题迫在眉睫。从这个点来看,我很看好 Quarkus。
Valhalla 带来的优化很多场景都可以用上,一些长时间运行应用也可以获得更多的性能收益。
而协程针对的是 IO 密集型场景,本身也可以通过 NIO、AIO 方式来避免线程的大量消耗。因此 Loom 在笔者看来更像是锦上添花的事。
-
从 Java 到 Go:面向对象的巨人与云原生的轻骑兵2025-04-25 811
-
云原生AI服务怎么样2025-01-23 1266
-
云原生LLMOps平台作用2025-01-06 1043
-
什么是云原生MLOps平台2024-12-12 1210
-
云原生和非云原生哪个好?六大区别详细对比2024-09-13 1384
-
只需 6 步,你就可以搭建一个云原生操作系统原型2022-09-15 11198
-
华为云中什么是云原生服务中心2022-07-27 1417
-
解读腾讯云原生 鹅厂云原生的“新路”与“历承”2020-12-28 4230
-
如何更好地构建云原生应用生态,推动业界更好地落地云原生2020-12-24 3356
-
引领云原生2.0时代,赋能新云原生企业2020-12-11 2527
-
华为云正式提出云原生2.0的概念2020-12-07 4587
-
云原生应用中的“云”指的是什么?2020-11-27 3368
-
进击的 Java ,云原生时代的蜕变2019-09-17 3405
全部0条评论

快来发表一下你的评论吧 !
