

如何使用TensorRT框架部署ONNX模型
描述
导读 模型部署作为算法模型落地的最后一步,在人工智能产业化过程中是非常关键的步骤,而目标检测作为计算机视觉三大基础任务之一,众多的业务功能都要在检测的基础之上完成,本文提供了YOLOv5算法从0部署的实战教程,值得各位读者收藏学习。
前言
TensorRT是英伟达官方提供的一个高性能深度学习推理优化库,支持C++和Python两种编程语言API。通常情况下深度学习模型部署都会追求效率,尤其是在嵌入式平台上,所以一般会选择使用C++来做部署。 本文将以YOLOv5为例详细介绍如何使用TensorRT的C++版本API来部署ONNX模型,使用的TensorRT版本为8.4.1.5,如果使用其他版本可能会存在某些函数与本文描述的不一致。另外,使用TensorRT 7会导致YOLOv5的输出结果与期望不一致,请注意。
导出ONNX模型
YOLOv5使用PyTorch框架进行训练,可以使用官方代码仓库中的export.py脚本把PyTorch模型转换为ONNX模型:
python export.py --weights yolov5x.pt --include onnx --imgsz 640 640
准备模型输入数据
如果想用YOLOv5对图像做目标检测,在将图像输入给模型之前还需要做一定的预处理操作,预处理操作应该与模型训练时所做的操作一致。YOLOv5的输入是RGB格式的3通道图像,图像的每个像素需要除以255来做归一化,并且数据要按照CHW的顺序进行排布。所以YOLOv5的预处理大致可以分为两个步骤:
将原始输入图像缩放到模型需要的尺寸,比如640x640。这一步需要注意的是,原始图像是按照等比例进行缩放的,如果缩放后的图像某个维度上比目标值小,那么就需要进行填充。举个例子:假设输入图像尺寸为768x576,模型输入尺寸为640x640,按照等比例缩放的原则缩放后的图像尺寸为640x480,那么在y方向上还需要填充640-480=160(分别在图像的顶部和底部各填充80)。来看一下实现代码:
cv::Mat input_image = cv::imread("dog.jpg"); cv::Mat resize_image; const int model_width = 640; const int model_height = 640; const float ratio = std::min(model_width / (input_image.cols * 1.0f), model_height / (input_image.rows * 1.0f)); // 等比例缩放 const int border_width = input_image.cols * ratio; const int border_height = input_image.rows * ratio; // 计算偏移值 const int x_offset = (model_width - border_width) / 2; const int y_offset = (model_height - border_height) / 2; cv::resize(input_image, resize_image, cv::Size(border_width, border_height)); cv::copyMakeBorder(resize_image, resize_image, y_offset, y_offset, x_offset, x_offset, cv::BORDER_CONSTANT, cv::Scalar(114, 114, 114)); // 转换为RGB格式 cv::cvtColor(resize_image, resize_image, cv::COLOR_BGR2RGB); 图像这样处理后的效果如下图所示,顶部和底部的灰色部分是填充后的效果。
对图像像素做归一化操作,并按照CHW的顺序进行排布。这一步的操作比较简单,直接看代码吧:
input_blob = new float[model_height * model_width * 3]; const int channels = resize_image.channels(); const int width = resize_image.cols; const int height = resize_image.rows; for (int c = 0; c < channels; c++) { for (int h = 0; h < height; h++) { for (int w = 0; w < width; w++) { input_blob[c * width * height + h * width + w] = resize_image.at
ONNX模型部署
1. 模型优化与序列化
要使用TensorRT的C++ API来部署模型,首先需要包含头文件NvInfer.h。
#include "NvInfer.h" TensorRT所有的编程接口都被放在命名空间nvinfer1中,并且都以字母I为前缀,比如ILogger、IBuilder等。使用TensorRT部署模型首先需要创建一个IBuilder对象,创建之前还要先实例化ILogger接口:
class MyLogger : public nvinfer1::ILogger { public: explicit MyLogger(nvinfer1::Severity severity = nvinfer1::kWARNING) : severity_(severity) {} void log(nvinfer1::Severity severity, const char *msg) noexcept override { if (severity <= severity_) { std::cerr << msg << std::endl; } } nvinfer1::Severity severity_; }; 上面的代码默认会捕获级别大于等于WARNING的日志信息并在终端输出。实例化ILogger接口后,就可以创建IBuilder对象:
MyLogger logger; nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(logger); 创建IBuilder对象后,优化一个模型的第一步是要构建模型的网络结构。
const uint32_t explicit_batch = 1U << static_cast
const std::string onnx_model = "yolov5m.onnx"; nvonnxparser::IParser *parser = nvonnxparser::createParser(*network, logger); parser->parseFromFile(model_path.c_str(), static_cast
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig(); config->setMemoryPoolLimit(nvinfer1::kWORKSPACE, 1U << 25); if (builder->platformHasFastFp16()) { config->setFlag(nvinfer1::kFP16); } 设置IBuilderConfig属性后,就可以启动优化引擎对模型进行优化了,这个过程需要一定的时间,在嵌入式平台上可能会比较久一点。经过TensorRT优化后的序列化模型被保存到IHostMemory对象中,我们可以将其保存到磁盘中,下次使用时直接加载这个经过优化的模型即可,这样就可以省去漫长的等待模型优化的过程。我一般习惯把序列化模型保存到一个后缀为.engine的文件中。
nvinfer1::IHostMemory *serialized_model = builder->buildSerializedNetwork(*network, *config); // 将模型序列化到engine文件中 std::stringstream engine_file_stream; engine_file_stream.seekg(0, engine_file_stream.beg); engine_file_stream.write(static_cast
delete config; delete parser; delete network; delete builder; IHostMemory对象用完后也可以通过delete进行释放。
2. 模型反序列化
通过上一步得到优化后的序列化模型后,如果要用模型进行推理,那么还需要创建一个IRuntime接口的实例,然后通过其模型反序列化接口去创建一个ICudaEngine对象:
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(logger); nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine( serialized_model->data(), serialized_model->size()); delete serialized_model; delete runtime; 如果是直接从磁盘中加载.engine文件也是差不多的步骤,首先从.engine文件中把模型加载到内存中,然后再通过IRuntime接口对模型进行反序列化即可。
const std::string engine_file_path = "yolov5m.engine"; std::stringstream engine_file_stream; engine_file_stream.seekg(0, engine_file_stream.beg); std::ifstream ifs(engine_file_path); engine_file_stream << ifs.rdbuf(); ifs.close(); engine_file_stream.seekg(0, std::end); const int model_size = engine_file_stream.tellg(); engine_file_stream.seekg(0, std::beg); void *model_mem = malloc(model_size); engine_file_stream.read(static_cast
3. 模型推理
ICudaEngine对象中存放着经过TensorRT优化后的模型,不过如果要用模型进行推理则还需要通过createExecutionContext()函数去创建一个IExecutionContext对象来管理推理的过程:
nvinfer1::IExecutionContext *context = engine->createExecutionContext(); 现在让我们先来看一下使用TensorRT框架进行模型推理的完整流程:

对输入图像数据做与模型训练时一样的预处理操作。
把模型的输入数据从CPU拷贝到GPU中。
调用模型推理接口进行推理。
把模型的输出数据从GPU拷贝到CPU中。
对模型的输出结果进行解析,进行必要的后处理后得到最终的结果。
由于模型的推理是在GPU上进行的,所以会存在搬运输入、输出数据的操作,因此有必要在GPU上创建内存区域用于存放输入、输出数据。模型输入、输出的尺寸可以通过ICudaEngine对象的接口来获取,根据这些信息我们可以先为模型分配输入、输出缓存区。
void *buffers[2]; // 获取模型输入尺寸并分配GPU内存 nvinfer1::Dims input_dim = engine->getBindingDimensions(0); int input_size = 1; for (int j = 0; j < input_dim.nbDims; ++j) { input_size *= input_dim.d[j]; } cudaMalloc(&buffers[0], input_size * sizeof(float)); // 获取模型输出尺寸并分配GPU内存 nvinfer1::Dims output_dim = engine->getBindingDimensions(1); int output_size = 1; for (int j = 0; j < output_dim.nbDims; ++j) { output_size *= output_dim.d[j]; } cudaMalloc(&buffers[1], output_size * sizeof(float)); // 给模型输出数据分配相应的CPU内存 float *output_buffer = new float[output_size](); 到这一步,如果你的输入数据已经准备好了,那么就可以调用TensorRT的接口进行推理了。通常情况下,我们会调用IExecutionContext对象的enqueueV2()函数进行异步地推理操作,该函数的第二个参数为CUDA流对象,第三个参数为CUDA事件对象,这个事件表示该执行流中输入数据已经使用完,可以挪作他用了。如果对CUDA的流和事件不了解,可以参考我之前写的这篇文章。
cudaStream_t stream; cudaStreamCreate(&stream); // 拷贝输入数据 cudaMemcpyAsync(buffers[0], input_blob,input_size * sizeof(float), cudaMemcpyHostToDevice, stream); // 执行推理 context->enqueueV2(buffers, stream, nullptr); // 拷贝输出数据 cudaMemcpyAsync(output_buffer, buffers[1],output_size * sizeof(float), cudaMemcpyDeviceToHost, stream); cudaStreamSynchronize(stream); 模型推理成功后,其输出数据被拷贝到output_buffer中,接下来我们只需按照YOLOv5的输出数据排布规则去解析即可。
4. 小结
在介绍如何解析YOLOv5输出数据之前,我们先来总结一下用TensorRT框架部署ONNX模型的基本流程。  如上图所示,主要步骤如下:
如上图所示,主要步骤如下:
实例化Logger;
创建Builder;
创建Network;
使用Parser解析ONNX模型,构建Network;
设置Config参数;
优化网络,序列化模型;
反序列化模型;
拷贝模型输入数据(HostToDevice),执行模型推理;
拷贝模型输出数据(DeviceToHost),解析结果。
解析模型输出结果
YOLOv5有3个检测头,如果模型输入尺寸为640x640,那么这3个检测头分别在80x80、40x40和20x20的特征图上做检测。让我们先用Netron工具来看一下YOLOv5 ONNX模型的结构,可以看到,YOLOv5的后处理操作已经被包含在模型中了(如下图红色框内所示),3个检测头分支的结果最终被组合成一个张量作为输出。 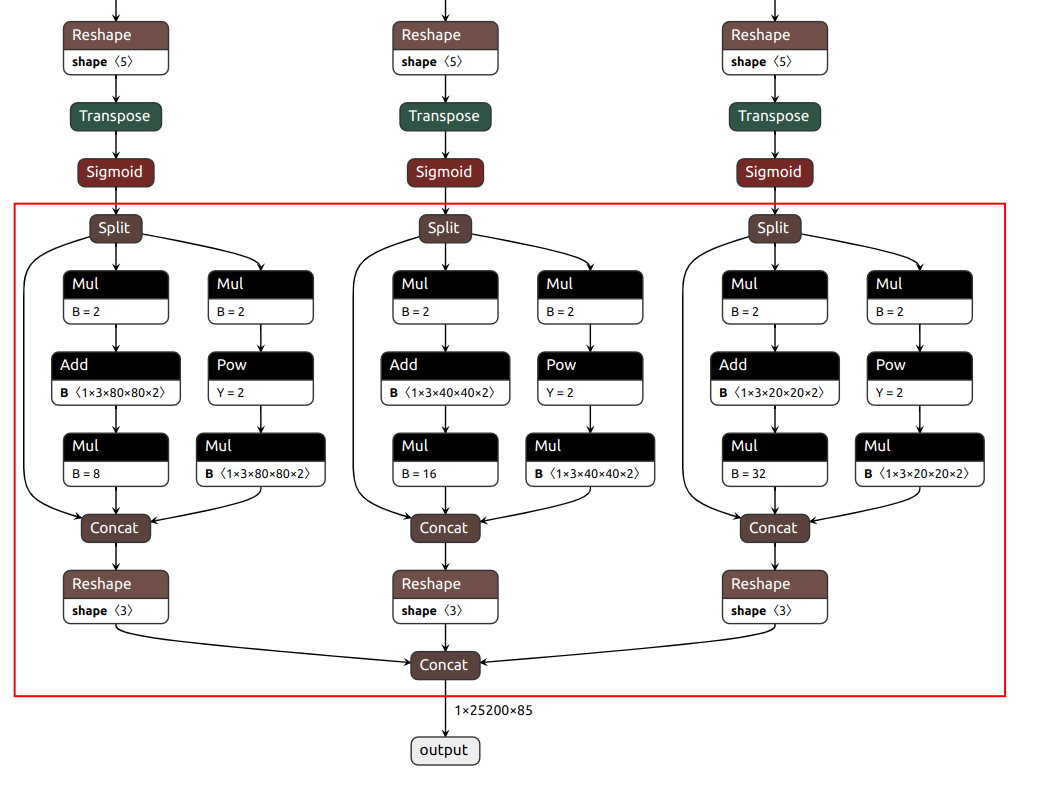 yolov5m YOLOv5的3个检测头一共有(80x80+40x40+20x20)x3=25200个输出单元格,每个单元格输出x,y,w,h,objectness这5项再加80个类别的置信度总共85项内容。经过后处理操作后,目标的坐标值已经被恢复到以640x640为参考的尺寸,如果需要恢复到原始图像尺寸,只需要除以预处理时的缩放因子即可。这里有个问题需要注意:由于在做预处理的时候图像做了填充,原始图像并不是被缩放成640x640而是640x480,使得输入给模型的图像的顶部被填充了一块高度为80的区域,所以在恢复到原始尺寸之前,需要把目标的y坐标减去偏移量80。
yolov5m YOLOv5的3个检测头一共有(80x80+40x40+20x20)x3=25200个输出单元格,每个单元格输出x,y,w,h,objectness这5项再加80个类别的置信度总共85项内容。经过后处理操作后,目标的坐标值已经被恢复到以640x640为参考的尺寸,如果需要恢复到原始图像尺寸,只需要除以预处理时的缩放因子即可。这里有个问题需要注意:由于在做预处理的时候图像做了填充,原始图像并不是被缩放成640x640而是640x480,使得输入给模型的图像的顶部被填充了一块高度为80的区域,所以在恢复到原始尺寸之前,需要把目标的y坐标减去偏移量80。 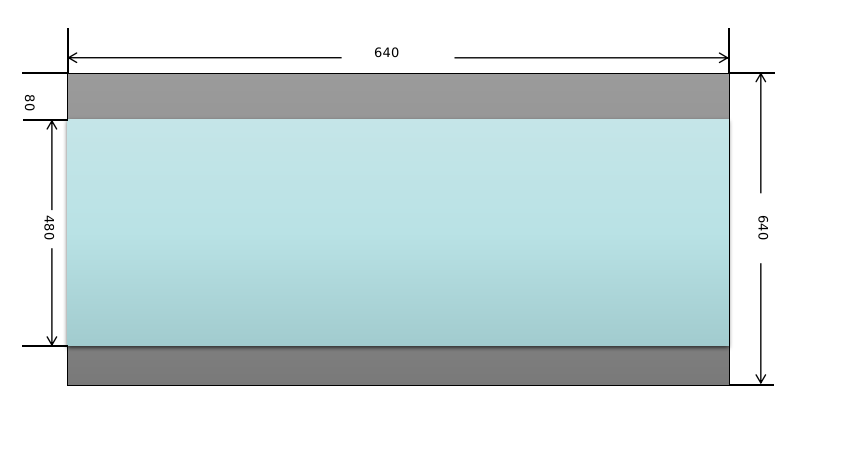 详细的解析代码如下:
详细的解析代码如下:
float *ptr = output_buffer; for (int i = 0; i < 25200; ++i) { const float objectness = ptr[4]; if (objectness >= 0.45f) { const int label = std::max_element(ptr + 5, ptr + 85) - (ptr + 5); const float confidence = ptr[5 + label] * objectness; if (confidence >= 0.25f) { const float bx = ptr[0]; const float by = ptr[1]; const float bw = ptr[2]; const float bh = ptr[3]; Object obj; // 这里要减掉偏移值 obj.box.x = (bx - bw * 0.5f - x_offset) / ratio; obj.box.y = (by - bh * 0.5f - y_offset) / ratio; obj.box.width = bw / ratio; obj.box.height = bh / ratio; obj.label = label; obj.confidence = confidence; objs->push_back(std::move(obj)); } } ptr += 85; } // i loop 对解析出的目标做非极大值抑制(NMS)操作后,检测结果如下图所示:

总结
本文以YOLOv5为例通过大量的代码一步步讲解如何使用TensorRT框架部署ONNX模型,主要目的是希望读者能够通过本文学习到TensorRT模型部署的基本流程,比如如何准备输入数据、如何调用API用模型做推理、如何解析模型的输出结果。如何部署YOLOv5模型并不是本文的重点,重点是要掌握使用TensorRT部署ONNX模型的基本方法,这样才会有举一反三的效果。
-
深度探索ONNX模型部署 精选资料分享2021-07-20 872
-
ONNX的相关资料分享2021-11-05 1104
-
如何使用Paddle2ONNX模型转换工具将飞桨模型转换为ONNX模型?2021-12-29 3579
-
EIQ onnx模型转换为tf-lite失败怎么解决?2023-03-31 1021
-
Facebook推出ONNX,旨在为不同编程框架的神经网络创建共享模型2017-12-28 4914
-
嵌入式Linux平台部署AI神经网络模型Inference的方案2021-11-02 856
-
基于TensorRT完成NanoDet模型部署2022-01-25 644
-
使用Bottlerocket和Amazon EC2部署AI模型2022-04-08 1757
-
基于NVIDIA Triton的AI模型高效部署实践2022-06-28 3241
-
Pytorch转化ONNX过程代码实操2023-01-02 1403
-
ONNX格式模型部署兼容性框架介绍2023-06-19 6724
-
三种主流模型部署框架YOLOv8推理演示2023-08-06 4213
-
用STM32Cube.AI部署ONNX模型实操示例:风扇堵塞检测2023-09-28 3764
-
基于Pytorch训练并部署ONNX模型在TDA4应用笔记2024-09-11 576
-
NVIDIA TensorRT LLM 1.0推理框架正式上线2025-10-21 1635
全部0条评论

快来发表一下你的评论吧 !
