

什么是数字逻辑设计?我应该使用什么工具?
描述
我在数字逻辑设计方面并没有经验。也就是说,直到最近我才决定尝试设计自己的 CPU,并在 FPGA 上运行!如果你也是一名软件工程师,并对硬件设计有兴趣,那么我希望这一系列关于我所学到的知识的文章能够对你有所帮助,并让你感到有趣。
什么是数字逻辑设计?
数字逻辑设计就是设计一个逻辑电路,对二进制数值进行运算。基本元件是逻辑门:例如,与门一样,有两个输入和一个输出。它的输出为 1 或 iff,两个输入均为 1。
我们所设计的同步电路,一般都是利用触发器来储存状态,使电路运行与共时钟同步。触发器由逻辑门组成。
模拟电路设计包括构成逻辑门的电子元件,例如晶体管和二极管。这种抽象通常是用于直接处理来自模拟传感器的信号的应用,例如无线电接收器。在设计 CPU 时,这种抽象水平是行不通的:现代的 CPU 有几十亿个晶体管!
相反,我们使用的工具可以将数字逻辑设计转化为不同的有用格式:FPGA 的配置(见下文);模拟;晶片布局。
FPGA 是什么,为什么要用 FPGA?
上文中我们指出,不管我们是创建自定义 ASIC 芯片还是配置 FPGA,都可以使用相同的数字逻辑设计工具。现场可编程门阵列(Field-Programmable Gate Array,FPGA)是一种集成集成电路,其中包含了可编程逻辑块阵列。你可以把它想象成一个大型的逻辑门阵列,可以通过多种方式连接起来。
定制一款芯片动辄需要几百万美元,当然,一旦芯片被生产出来,就无法对它进行更改。所以 FPGA 通常用于下列情况:
由于缺乏资金,无法负担制作定制 ASIC 的费用(例如,如果你只是像我这样的黑客,而不是 ARM 或英特尔)。
无法负担制作定制 ASIC 的费用,因为产量太低,不值得一次性支付高昂的费用 (例如,如果你正在使用定制的数据采集硬件生产少量的 MRI 机器)。
需要灵活性。
缺点是什么?那就是 FPGA 的单芯片成本要高得多,并且由于它能够以非常灵活的方式将逻辑块连接在一起,因此速度通常要慢得多。与此相反,定制的设计可以减少晶体管的数量,而无需考虑灵活性。
在我看来,比较 ASIC 的定制设计过程和 FPGA 的设计过程是很有帮助的:
逻辑设计:就像做 FPGA 一样,ASIC 的逻辑设计也是用硬件描述语言来完成的。
验证:FPGA 设计可能会被验证,但是可以期待 ASIC!设计的过程更严格了。毕竟,设计一旦制造出来就不能更改!验证通常包括设计部分的正式验证。
合成:这将创建一个网表,一个逻辑块及其连接的列表。连接被称为网,而块被称为单元。对于 FPGA 和 ASIC 来说,单元是特定于厂商的。
布局布线(Placement and routing,P&R):对于 FPGA 来说,它涉及到将网表中描述的逻辑块映射到 FPGA 中的实际块。由此产生的二进制通常称为比特流。对于 ASIC 来说,这涉及到决定在晶片上何处放置单元,以及如何将它们连接起来。这两种应用通常都要使用自动优化工具。
我需要什么工具? 硬件描述语言:我使用的是 nMigen
你可能听说过 Verilog 或 VHDL:这两种流行的硬件描述语言(hardware description language,HDL)。这里我所说的“流行”,是指广泛使用,而非广受欢迎。
我不会假装对这些工具很了解。我只知道那些比我更聪明的人,有着丰富的逻辑设计经验,却对这些工具恨之入骨。由于 Verilog 和其他类似工具存在的问题,人们尝试着开发出更有用、更友好的替代方法。就是在 Python 中创建一 门领域专用语言的项目。用它自己的话就是:
虽然用 Verilog 和 VHDL 进行硬件设计比输入原理图的速度要快,但是由于一些原因,硬件设计还是很枯燥,而且效率也不高。对目前逻辑设计中占有重要地位的同步电路而言,事件驱动模型引入了不必要的问题,并引入了人工编码。逆直觉的算术规则导致了更陡峭的学习曲线,并为设计上的微小缺陷提供了温床。最后,通过“generate”语句来支持逻辑过程生成(元编程)非常有限,并且限制了代码的通用、重用和组织方式。
针对这些问题,我们开发了 nMigen FHDL,该库取代了事件驱动范例,它采用了组合语句和同步语句的概念,并采用了算术规则,使整型始终像数学整型一样,最重要的是允许 Python 程序构建所设计的逻辑。这一点使硬件设计人员能够充分利用 Python 语言的丰富内容:面向对象编程、函数参数、生成器、操作符重载、库等,构建组织良好、可重用的优雅设计。
假如你和我一样,从未使用过 Verilog,那么这些对你来说不仅仅是抽象的含义。但是听起来确实很有前景,而且我可以证明,在没有 Verilog 障碍的情况下,从逻辑设计开始就非常简单。如果你对 Python 非常熟悉,我将推荐它!
我能想到的唯一缺点是,nMigen 仍然处于开发阶段,特别是文档还不完整。但你可以通过 chat.freenode.net 的 #nmigen 频道找到有用的社区。
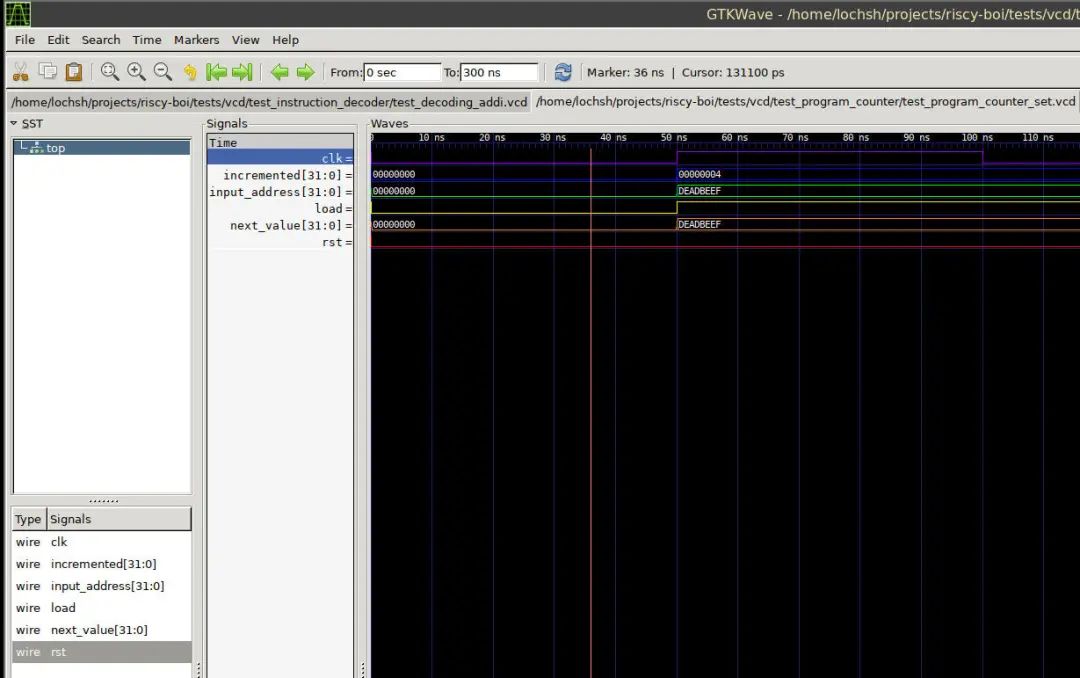
用于检查模拟的波形显示器:我使用的是 GTKWave
nMigen 提供了模拟工具。我将它用于用 pytest 编写的测试。为了帮助调试,我记录了这些测试中的信号,并在波形显示器中观察它们。
FPGA 开发板:我使用的是 myStorm BlackIce II
你不必使用 FPGA 开发板来创建自己的 CPU。在模拟中,你可以做任何事情。对于我来说,工作中使用板子的乐趣就是能闪烁 LED,看着自己的设计运行。
当然,如果你要创建的东西比我的最基本的 CPU 更有用,那么你可能需要一些硬件来运行它,而这并非“可选”选项!
开始使用 nMigen
在 nMigen 系统中,我并没有立刻尝试设计一个 CPU,而是首先制作一个算术逻辑单元(Arithmetic Logic Unit ,ALU)。在我见过的所有 CPU 设计中, ALU 是一个关键部件:它执行算术运算。
为什么要从这里开始呢?我知道我的 CPU 需要一个 ALU;我知道我能做一个简单的 ALU;我知道当开始一个新的项目时,做事情的感觉是一种重要的动力!
我的设计看起来像这样:
"""Arithmetic Logic Unit"""import enum import nmigen as nm class ALUOp(enum.IntEnum): """Operations for the ALU""" ADD = 0 SUB = 1 class ALU(nm.Elaboratable): """ Arithmetic Logic Unit * op (in): the opcode * a (in): the first operand * b (in): the second operand * o (out): the output """ def __init__(self, width): """ Initialiser Args: width (int): data width """ self.op = nm.Signal() self.a = nm.Signal(width) self.b = nm.Signal(width) self.o = nm.Signal(width) def elaborate(self, _): m = nm.Module() with m.Switch(self.op): with m.Case(ALUOp.ADD): m.d.comb += self.o.eq(self.a + self.b) with m.Case(ALUOp.SUB): m.d.comb += self.o.eq(self.a - self.b) return m
正如你所看到的,我们已经创建了大量的 nMigen Signal 实例,以很好地表示定义 ALU 接口的信号!但这个复杂的方法是什么呢?这个 elaborate 方法又是什么呢?我的理解是,“elaboration”是合成网表的第一步的名称(见上文)。在上面的 nMigen 代码中,我们的想法是,已经创建了一些可阐述的结构(通过继承 nm.Elaboratable),也就是用来描述想要合成的数字逻辑的东西。这个 elaborate 方法描述了数字逻辑。它必须返回一个 nMigen 模块。
下面让我们进一步了解一下 elaborate 的方法的内容。Switch 将创造某种形式的合成设计决策逻辑。但什么是 m.d.comb 呢?nMigen 提出了同步(m.d.sync)和组合(m.d.comb)控制域的概念。:
控制域是指在相同条件下改变其值的一组命名信号。
所有的设计都有一个预定义的组合域,其中包含所有的信号,当用来计算这些信号的任何值发生变化时,这些信号也随之发生变化。名称 comb 是为组合域保留的。
一种设计还可以有任意数量的用户定义的同步域,也称为时钟域,其中包含的信号在域的时钟信号出现特定边缘时会发生变化,或者,对于具有异步复位功能的域,域的复位信号会发生变化。大多数模块只使用一个同步域。
在组合域和同步域中,信号的赋值的行为各不相同。总的来说,同步域中的信号包含了设计的状态,而组合域中的信号并不能形成反馈回路或维持状态。
下面以移位寄存器为例,说明要设计的逻辑。假定移位寄存器有 8 位,每个时钟周期,该位值都会有一个移位(最左边的值来自输入信号)。这必然是同步的:不能通过简单地将位连接在一起来创建这个功能,而在 nMigen 中,将位分配到组合域中将代表此功能。
我将在这个系列博客的下一部分详细讨论我的 CPU 设计。现在的情况是,我试图在每个周期中只停用一个指令,而不使用流水线——这很不寻常,但是我希望这样做可以简化 CPU 的各个方面。其结果是,大多数逻辑是组合的,而非同步的,因为我几乎没有在时钟周期之间维持这种状态。现在,我的寄存器文件设计有问题,为了解决这个问题,我可能需要重新考虑我的“无流水线”想法。
编写测试
对于 Python 测试,我喜欢使用 pytest,当然你也可以使用任何能吸引你的框架。以下是我在上面测试的 ALU 代码:
"""ALU tests""" import nmigen.sim import pytest from riscy_boi import alu @pytest.mark.parametrize( "op, a, b, o", [ (alu.ALUOp.ADD, 1, 1, 2), (alu.ALUOp.ADD, 1, 2, 3), (alu.ALUOp.ADD, 2, 1, 3), (alu.ALUOp.ADD, 258, 203, 461), (alu.ALUOp.ADD, 5, 0, 5), (alu.ALUOp.ADD, 0, 5, 5), (alu.ALUOp.ADD, 2**32 - 1, 1, 0), (alu.ALUOp.SUB, 1, 1, 0), (alu.ALUOp.SUB, 4942, 0, 4942), (alu.ALUOp.SUB, 1, 2, 2**32 - 1)]) def test_alu(comb_sim, op, a, b, o): alu_inst = alu.ALU(32) def testbench(): yield alu_inst.op.eq(op) yield alu_inst.a.eq(a) yield alu_inst.b.eq(b) yield nmigen.sim.Settle() assert (yield alu_inst.o) == o comb_sim(alu_inst, testbench)
以及我的 conftest.py:
"""Test configuration"""
import os
import shutil
import nmigen.sim
import pytest
VCD_TOP_DIR = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
"tests",
"vcd")
def vcd_path(node):
directory = os.path.join(VCD_TOP_DIR, node.fspath.basename.split(".")[0])
os.makedirs(directory, exist_ok=True)
return os.path.join(directory, node.name + ".vcd")
@pytest.fixture(scope="session", autouse=True)
def clear_vcd_directory():
shutil.rmtree(VCD_TOP_DIR, ignore_errors=True)
@pytest.fixture
def comb_sim(request):
def run(fragment, process):
sim = nmigen.sim.Simulator(fragment)
sim.add_process(process)
with sim.write_vcd(vcd_path(request.node)):
sim.run_until(100e-6)
return run
@pytest.fixture
def sync_sim(request):
def run(fragment, process):
sim = nmigen.sim.Simulator(fragment)
sim.add_sync_process(process)
sim.add_clock(1 / 10e6)
with sim.write_vcd(vcd_path(request.node)):
sim.run()
return run
每次测试都会生成一个 vcd 文件,我可以通过 GTKWave 等波形显示器来查看,以便调试。你会注意到,组合模拟固定运行的时间段是任意小的,而同步模拟功能运行的时间段是确定的时钟周期数。
一个信号产生于一个测试函数,它将从模拟器请求它的当前值。对于组合逻辑,我们生成 nnmigen.sim.Settle() ,要求完成模拟。
对于同步逻辑,还可以开始新的时钟周期,而不需要参数。
设计一个 CPU
在熟悉了 nMigen 之后,我开始尝试绘制一个框图来显示我的 CPU。在本系列博客的下一部分中,我将对这个问题进行更详细的讨论,但我将简单地说,我先绘制出一个指令所需要的逻辑,然后绘制出另一个指令的逻辑,然后找到如何将它们结合起来的方法。这里有第一个混乱的草图:
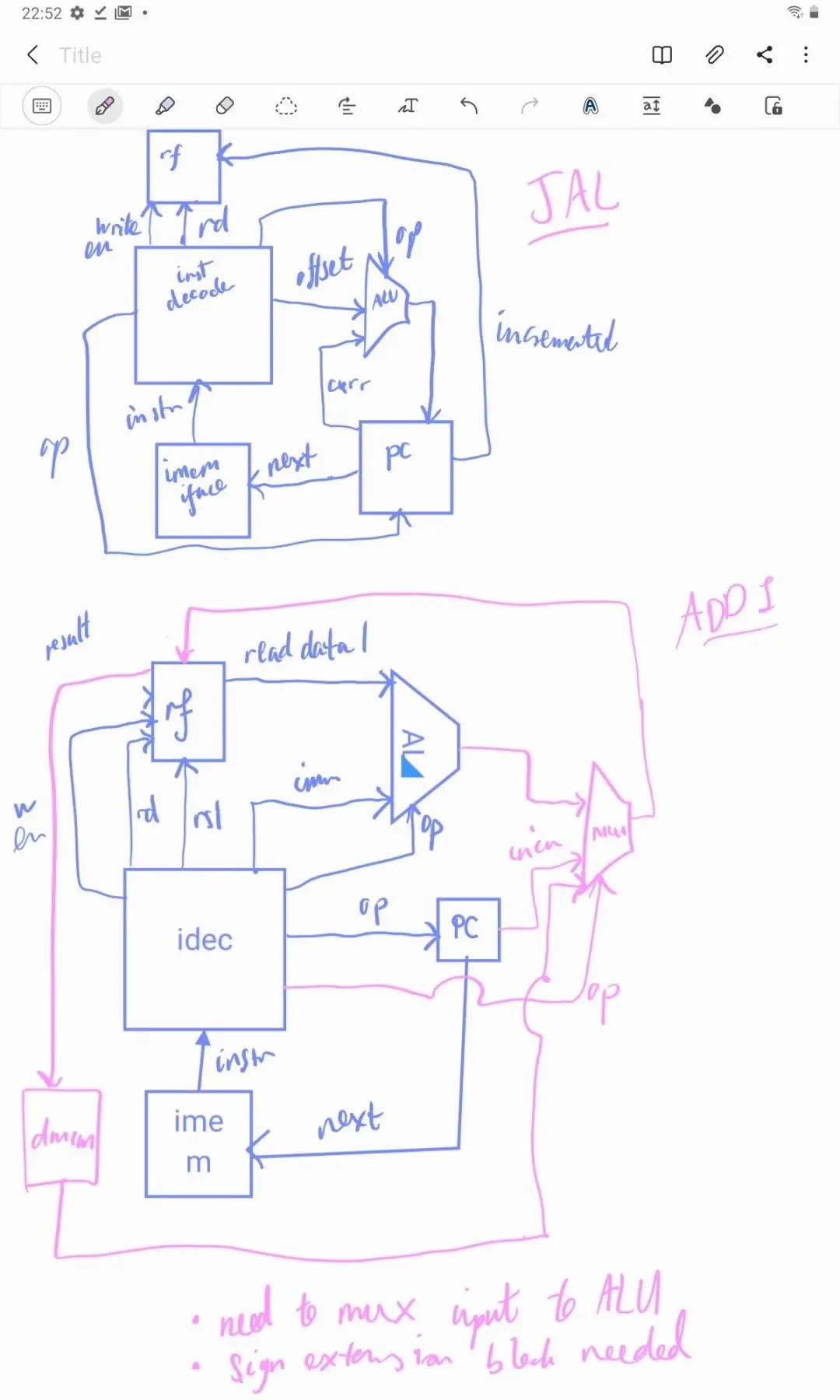
在弄清楚不同元件的接口要求是什么时,这个框图步骤非常有价值,但是在开始使用 nMigen 和在这个过程中学习数字逻辑设计之前,我不想这么做。修改后的框图如下所示:
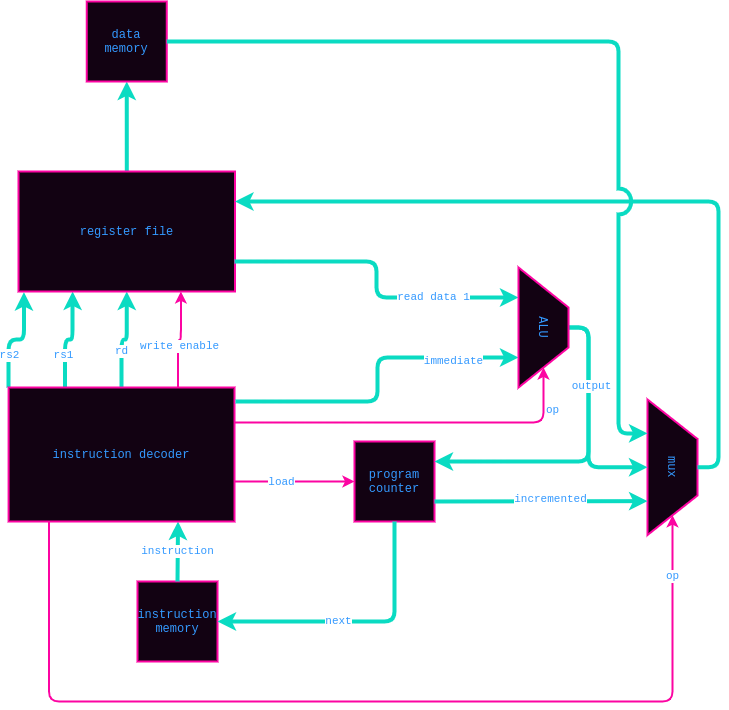
审核编辑:刘清
-
数字电路与逻辑设计2024-03-11 780
-
什么是数字逻辑设计2022-11-01 3043
-
《数字电路与逻辑设计》李晓辉版课后答案详解2021-12-27 5676
-
逻辑设计是什么意思2021-11-10 1456
-
数字电路与逻辑设计电路的分析和方法2021-08-06 1718
-
数字电路与逻辑设计实验报告模板2020-06-05 1870
-
《数字电路与逻辑设计》答案2012-06-25 872
-
组合逻辑设计实例_国外2011-12-16 1153
-
ASIC与大型逻辑设计实习教程2010-06-19 719
-
逻辑设计和校验工具v3.3版本下载2009-10-29 7473
-
组合逻辑设计原则--Combinational logic design principles-数字电路 (数字设计原理2009-09-26 7107
-
中规模集成时序逻辑设计2009-09-01 716
全部0条评论

快来发表一下你的评论吧 !
