

一种新颖的标签驱动去噪框架(LDF)
描述
01
研究动机
方面类别检测(简称ACD)是细粒度情感分析的一个重要子任务,旨在从一组预定义的方面类别中检测出评论句子中提到的方面类别。例如,给定句子”虽然房间很贵,但是服务很好.”,ACD 的任务是从句子中识别出两个方面类别,即”服务”和”价格”。显然,ACD 属于多标签分类问题。
最近,随着深度学习的发展,研究者们提出了大量用于 ACD 任务的神经网络模型[1, 2, 3]。所有这些模型的性能在很大程度上依赖于足够的标记数据。但是,ACD 任务中方面类别的注释非常昂贵。有限的标记数据严重限制了神经网络模型的有效性。为了缓解这个问题,Hu等人[4]参考了小样本学习 (FSL) 的思路[5, 6,7 ,8],将 ACD任务形式化为小样本学习问题 (FS-ACD),即使用少量的监督数据来判评论句子所属的方面类别。
表1: 3-way 2-shot 元任务的示例
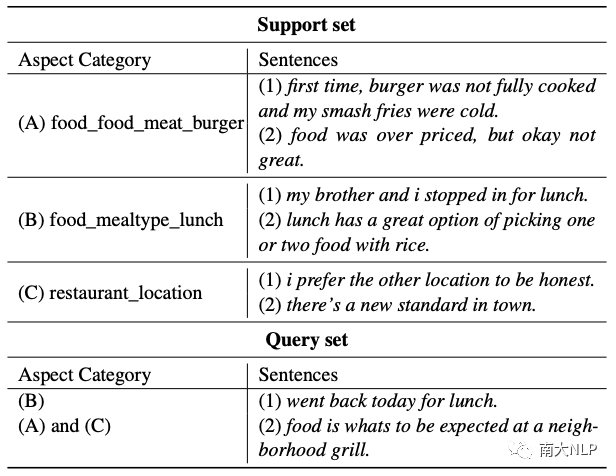
FS-ACD 遵循元学习范式[9],构建了一个 N-way K-shot 的元任务集合。表1显示了一个 3-way 2-shot 的元任务,它由一个支持集和一个查询集组成。支持集随机采样三个类(即方面类别),每个类随机选择两个句子(即实例)。元任务旨在借助少量标记的支持集来推断查询集中句子所属的方面类别。
通过在训练阶段对不同的元任务进行采样,FS-ACD 可以在少样本场景中学习到很好的泛化能力,并且在测试阶段表现良好。为了执行 FS-ACD 任务,Hu等人[4]提出了一个基于注意力的原型网络Proto-AWATT。它首先利用注意力机制从支持集中的方面类别对应的句子中提取关键字,然后将它们聚合为证据为每个方面类别生成一个原型。
然后,查询集利用原型生成相应的查询表示。最后,通过测量每个原型表示与相应查询表示之间的距离来进行类别预测。
尽管取得了很好的效果,但是我们发现噪声仍然是 FS-ACD 任务的关键问题。原因来自两个方面:一方面,由于缺乏足够的监督数据,以前的模型很容易捕捉到与当前方面类别无关的噪声词,这在很大程度上影响了生成原型的质量。如图1所示,以方面类别 food_food_meat_burger的原型为例。
我们根据Proto-AWATT 的注意力权重突出显示其前 10 个单词。由于缺乏足够的监督数据,我们观察到模型倾向于关注那些常见但嘈杂的单词,例如“a”、“the”、“my”。这些嘈杂的词无法为每个方面生成具有代表性的原型,从而导致性能打折。另一方面,语义上接近的方面类别通常会产生相似的原型,这些语义接近的原型互为噪音,极大地混淆了分类器。
据统计,数据集中近 25% 的方面类别对具有相似的语义,例如表 1 中的 food_food_meat_burger 和 food_mealtype_lunch。显然,这些语义相近的方面类别生成的原型会相互干扰并严重混淆 FS-ACD的检测结果。
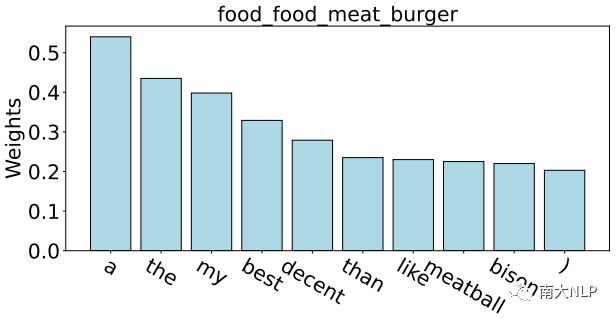
图1:根据 Proto-AWATT 的注意力权重可视化方面类别 food_food_meat_burger 原型的前 10 个单词
为了解决上述问题,我们为 FS-ACD 任务提出了一种新颖的标签驱动去噪框架(LDF)。具体来说,对于第一个问题,方面类别的标签文本包含丰富的语义描述方面的概念和范围,例如方面类别restaurant_location的标签文本“restaurant“和”location”,它们可以帮助注意力机制更好地捕捉与标签相关的单词。
因此,我们提出了一种标签引导的注意力策略来过滤噪声词并引导 LDF 产生更好的方面原型。鉴于第二个问题,我们提出了一种有效的标签加权对比损失,它将支持集的类间关系合并到对比学习函数中,从而扩大了相似原型之间的距离。
02
贡献
1、据我们所知,我们是第一个利用方面类别的标签信息来解决FS-ACD任务中噪声问题的工作;
2、我们提出了一种新颖的标签驱动去噪框架(LDF),它包含一个标签引导的注意力策略来过滤嘈杂的单词并为每个方面生成一个有代表性的原型,以及一个标签加权的对比损失来避免为语义接近的方面类别生成相似的原型;
3、LDF 框架具有良好的兼容性,可以很容易地扩展到现有模型。在这项工作中,我们将其应用于两个最新的 FS-ACD 模型,Proto-HATT[8] 和 Proto-AWATT[4]。三个基准数据集的实验结果证明了我们框架的优越性。
03
背景
在这项工作中,我们基于 Proto-AWATT[4] 和 Proto-HATT[8] 模型抽象了一个通用的架构,它们都实现了令人满意的性能,因此被选为我们工作的基础。
给定一个包含 l 个单词的实例,我们首先通过查找嵌入表将其映射到单词序列中。然后,我们使用卷积神经网络 (CNN) 将单词序列编码为上下文表示。接下来,注意力层为实例中的每个单词分配一个权重。最终实例表示由下式给出:
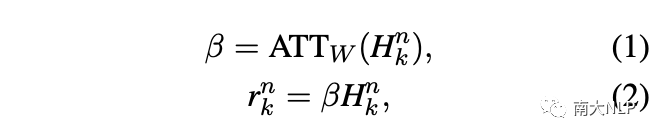
之后,我们聚合类 n 的所有实例表示来生成原型表示:
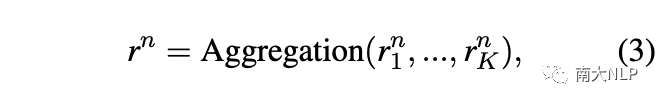
在处理了支持集中的所有类之后,我们得到了 N 个原型表示。类似地,对于查询实例,我们首先利用注意力机制生成 N 个原型特定的查询表示。之后,我们计算每个原型与对应的原型特定查询表示之间的欧几里得距离 (ED)。最后,我们对负欧几里得距离进行归一化以获得原型的排名,并使用阈值来选择方面类别:
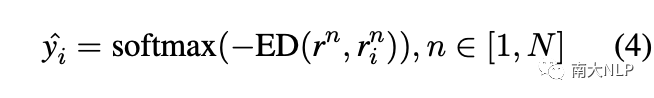
最终的训练目标是均方误差 (MSE) 损失:
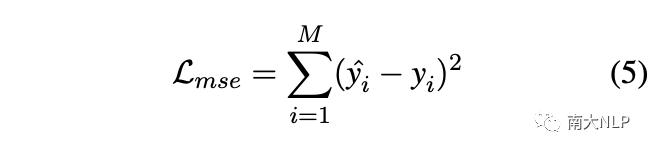
04
解决方案
图 2 展示了 LDF 的整体架构,其中包含两个组件:标签引导的注意力策略和标签加权的对比损失。在标签信息的帮助下,前者可以更好地关注与方面类别相关的单词,从而为每个方面生成更准确的原型,后者利用支持集的类间关系避免生成相似的原型。
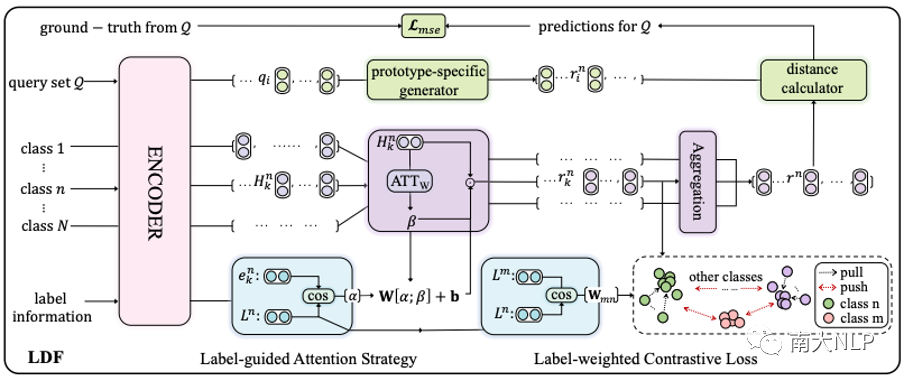
图2:标签驱动去噪框架(LDF)的整体架构
3.1 标签引导的注意力策略
由于缺乏足够的监督数据,公式1中的注意力权重通常会关注一些与当前类别无关的噪声词,导致原型变得不具有代表性。直觉上来说,每个类的标签文本都包含丰富的语义,可以为捕获方面类别相关的单词提供指导。因此,我们利用标签信息来解决上述问题并提出标签引导的注意力策略。
具体来说,我们首先计算标签文本与实例中每个单词的语义相似度来定位每个类的关键词:
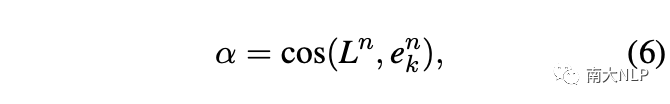
在标签信息的约束下,相似度权重倾向于关注与标签文本高度相关的少量单词,这样可能会忽略其它有信息量的词。因此,我们将其作为注意力权重的补充,以生成更全面、更准确的注意力权重:
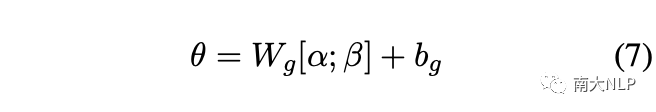
然后,为了重新获得注意力分布,注意力权重被重新归一化为:
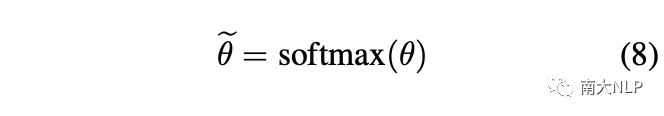
最后,我们将方程1中的注意力权重替换为方程8中新的注意力权重,从而获得支持集中每个类的代表性原型。
3.2 标签加权的对比损失
如前所述,语义上接近的方面类别通常会在支持集中生成相似的原型,它们互为噪声并严重混淆分类器。
直观地说,一种可行且自然的方法是利用有监督对比学习,它可以将不同类别的原型推开如下:
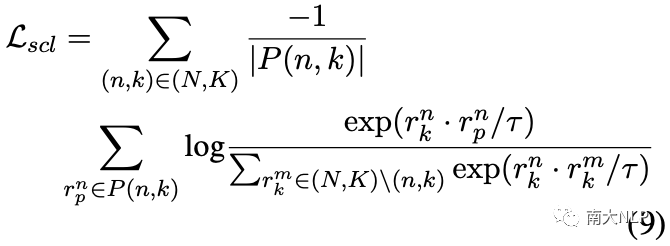
然而,有监督对比学习并不能很好地解决我们的问题,因为它在负集中平等地对待不同的原型,而我们的目标是鼓励越相似的原型相距越远。
例如,“food_food_meat_burger”在语义上比“room_bed”更接近“food_mealtype_lunch”。因此,“food_food_meat_burger”在负集中应该比“room_bed”更远离“food_mealtype_lunch”。
为了实现这一目标,我们再次利用标签信息并提出将类间关系合并到有监督的对比学习中,以自适应地区分负集中的相似原型:
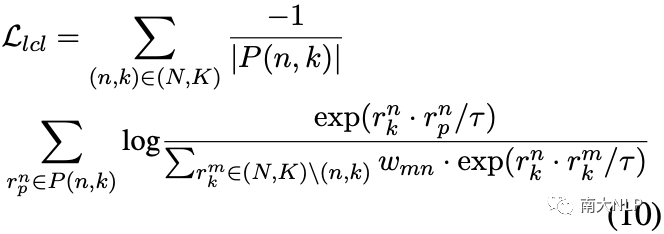
其中 wmn 表示负集中不同方面类别之间的 cos 相似度,计算如下:
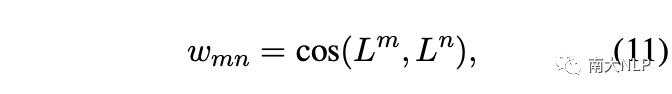
在标签加权的对比损失模块中,最终的损失函数为:
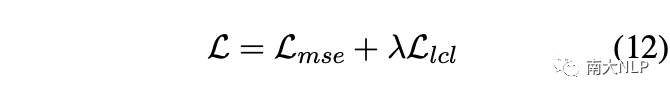
05
实验
5.1 实验设置
我们在三个公开的数据集FewAsp(single)、FewAsp(multi) 和 FewAsp上进行了实验,它们共享相同的 100 个方面类别,其中 64 个方面用于训练,16 个方面用于验证,20 个方面用于测试。我们使用 Macro-F1 和 AUC 分数作为评估指标,并且 5-way 设置和 10-way 设置中的阈值分别设置为0.3和0.2。
为了验证 LDF 框架的优越性,我们选择了两个性能最好的主流模型作为我们工作的基础,即Proto-HATT[8] 和Proto-AWATT[4]。换句话说,我们将 LDF 集成到Proto-HATT 和Proto-AWATT中,得到最终模型LDF-HATT和LDF-AWATT。
5.2 主实验
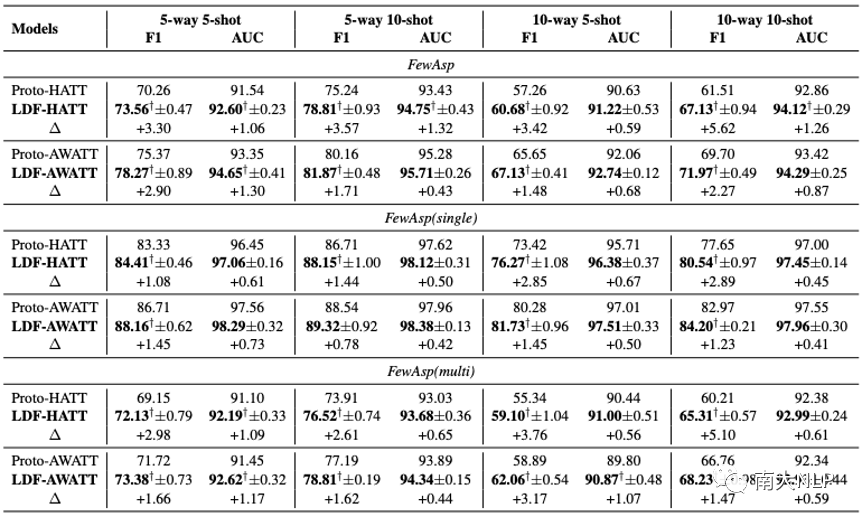
从表2可以看出,LDF-HATT 和LDF-AWATT 在三个数据集上的性能始终优于其基础模型。值得一提的是LDF-HATT 在 Macro-F1 和 AUC 分数上最多获得了 5.62% 和 1.32% 的提升。相比之下, LDF-AWATT 最多比Proto-AWATT 高 3.17% 和 1.30%。这些结果表明我们的框架具有良好的兼容性。
事实上,LDF-AWATT 的 Macro-F1 在大多数情况下提高了大约 2%,而LDF-HATT 的Macro-F1 平均提高了大约 3% 。这与我们的预期一致,因为原始Proto-AWATT 具有更强大的性能。 LDF-HATT 和LDF-AWATT 在FewAsp(multi) 数据集上比在FewAsp(single) 数据集上表现更好。
一个可能的原因是FewAsp(multi) 数据集中的每个类包含更多的实例,这使得LDF-HATT 和LDF-AWATT 在多标签分类中可以生成更准确的原型。
表2:主实验结果
5.3 消融实验
在不失一般性的情况下,我们选择 LDF-AWATT 模型进行消融实验,以研究 LDF 中单个模块对模型整体效果的影响。标签引导的注意力策略简称LAS,标签加权的对比损失简称LCL,有监督的对比学习简称SCL。根据表 3 报告的结果,我们可以观察到以下几点:
表3:消融实验结果

1、与基础模型Proto-AWATT相比, Proto-AWATT+LAS在三个数据集上取得了具有竞争力的性能,这验证了利用标签信息为每个类生成具有代表性原型的合理性;
2、将 LCL 集成到 Proto-AWATT+LAS后,LDF-AWATT 实现了 state-of-the-art 的性能,这表明 LCL 有利于区分相似的原型;
3、LAS 比 LCL 更有效。一个可能的原因是注意力机制是生成原型的核心因素。因此,它对我们的框架贡献更大;
4、Proto-AWATT+SCL 在FewAsp 数据集上的性能略好于Proto-AWATT,但它们的结果远低于 Proto-AWATT+LCL,这些结果进一步凸显了LCL的有效性;
5、将类间关系集成到 Proto-AWATT+SCL后, Proto-AWATT+LCL取得了更好的性能,这表明类间关系在区分相似原型方面起着至关重要的作用;
06
案例分析
为了更好地理解我们框架的优势,我们从FewAsp 数据集中选择一些样本进行案例研究。具体来说,我们随机抽取 5 个类,然后为这5个类抽取 50 次 5-way 5-shot 元任务。最后对于每个类,我们得到 50 个原型向量。
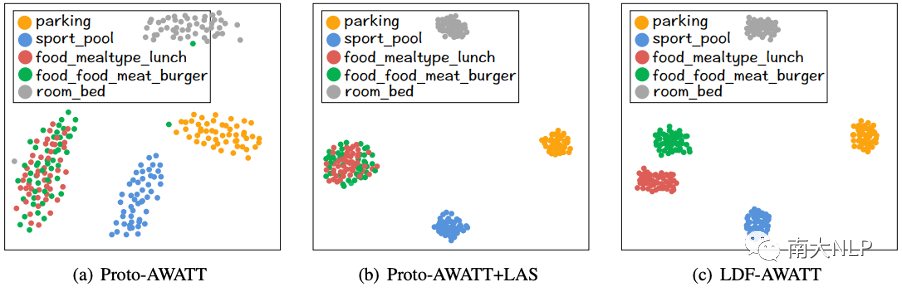
图4:可视化Proto-AWATT、Proto-AWATT+LAS 和 LDF-AWATT 原型表示
6.1 Proto-AWATT vs. Proto-AWATT+LAS
如图4(a) 和图4(b) 所示,我们可以看到Proto-AWATT+LAS 学习到的每个类的原型表示显然比Proto-AWATT 更集中。这些观察表明Proto-AWATT+LAS确实可以为每个类生成更准确的原型。
6.2 Proto-AWATT+LAS vs. LDF-AWATT
如图4(b) 和 图4(c) 所示,将 LCL 集成到Proto-AWATT+LAS后,LDF-AWATT 学习到的 food_mealtype_lunch 和food_food_meat_burger 的原型表示比 Proto-AWATT+LAS 更分离。 这表明LCL确实可以区分相似的原型。
07
错误分析
为了分析我们框架的局限性,我们通过LDF-AWATT 从FewAsp 数据集中随机抽取 100 个错误案例,并将它们大致分为两类。表4显示了每个类别的比例和一些代表性示例。主要类别是”Complex”,主要包括需要深入理解的示例。
如示例(1)所示,与 restaurant_location 相关的单词片段“Chandler Downtown Serrano”在训练集中出现的次数不超过 5 次,这些表达的低频率使得我们的模型难以捕捉到它们的模式,因此给出正确的预测确实具有挑战性。
第二类是”No obvious clues”,主要包括信息不足的例子。如示例(2)所示,句子很短,无法提供足够的信息来预测真实标签。
表4:LDF-AWATT模型的错误样例

08
总结
在本文中,我们提出了一种新颖的标签驱动去噪框架(LDF)来缓解 FS-ACD 任务的噪声问题。具体来说,我们设计了两个合理的方法:标签引导的注意力策略和标签加权的对比损失,旨在为每个类生成更好的原型并区分相似的原型。大量实验的结果表明,我们的框架 LDF 与其他最先进的方法相比实现了更好的性能。
论文链接:
https://arxiv.org/pdf/2210.04220.pdf
代码链接:
https://github.com/1429904852/LDF
审核编辑:刘清
-
H.264解码器中一种新颖的去块效应滤波器设计,不看肯定后悔2021-04-12 967
-
请问怎样去设计一种电子标签天线?2021-05-25 2035
-
如何去实现一种ThreadX内核框架的设计呢2021-11-29 2121
-
一种新的小波视频去噪方法2009-07-16 783
-
一种改进的轮廓小波变换及其图像去噪应用2009-10-23 687
-
基于一种新阈值函数的小波医学图像去噪2010-01-15 953
-
一种新颖的功率因数校正芯片的研究2009-07-06 1394
-
一种新颖的ZVZCSPWM全桥变换器2009-07-11 1328
-
一种新颖的精密陀螺电源2009-07-27 1257
-
一种基于压缩感知的改进全变分图像去噪方法2017-01-07 1579
-
一种基于小波框架的非局部曲面去躁方法2017-11-01 928
-
一种基于小波去噪的DFT信道估计改进算法2017-11-25 1005
-
一种全变分耦合图像去噪2018-02-12 1278
全部0条评论

快来发表一下你的评论吧 !
