

基于MVSNet的神经辐射场进行三维重建渲染
人工智能
描述
摘要
大家好,今天为大家带来的文章是 MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo 我们提出了MVSNeRF,一种新型的神经渲染方法,可以有效地重建用于视图合成的神经辐射场。与之前考虑在密集拍摄的图像上进行每个场景优化的神经辐射场的工作不同,我们提出了一个通用的深度神经网络,它可以通过快速的网络推理,仅从三个附近的输入视图中重建辐射场。我们的方法利用平面掠过成本体积(广泛用于多视图立体声)进行几何感知的场景推理,并将其与基于物理的体积渲染结合起来进行神经辐射场重建。
我们在DTU数据集中的真实物体上训练我们的网络,并在三个不同的数据集上测试它,以评估其有效性和通用性。我们的方法可以跨场景通用(甚至是室内场景,与我们的物体训练场景完全不同),并且只用三张输入图像就能产生真实的视图合成结果,大大超过了同时进行的可通用的辐射场重建工作。此外,如果捕捉到密集的图像,我们估计的辐射场表示可以很容易地进行微调;这成就了快速的按场景重建,具有更高的渲染质量,而且优化时间大大少于NeRF。
主要工作与贡献

- 提出了基于MVSNet的神经辐射场进行三维重建渲染。 - 在速度和质量上有了很大的提升。
算法流程
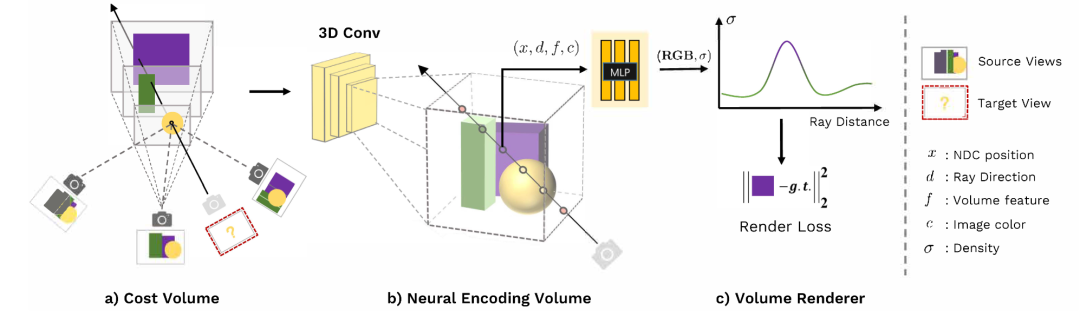
我们现在介绍我们的MVSNeRF。与NeRF通过每个场景的 "网络记忆 "来重建辐射场不同,我们的MVSNeRF学习一个通用网络来重建辐射场。给定真实场景的M个输入拍摄图像Ii(i=1,...,M)及其已知的相机参数Φi,我们提出了一个新颖的网络,可以将辐射场重建为一个神经编码体,并使用它在任意场景位置回归体的渲染属性(密度和与视图有关的辐射度),以进行视图合成。一般来说,我们的整个网络可以被看作是辐射度场的函数,表示为:
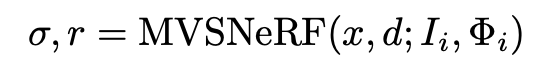
我们的框架首先通过将二维图像特征扭曲到一个平面扫描上构建一个成本体积(a)。然后我们应用三维CNN来重建一个具有每体素神经特征的神经编码体(b)。我们使用MLP在任意位置使用从编码体积内插的特征对体积密度和RGB辐射度进行回归。这些体积特性被微分光线行进法用于最终渲染(c)。
Cost Volume重建
求解Cost Volume的过程和双目立体矫正类似,首先提取图像特征,然后计算成本量P。成本量P是由D扫面上的扭曲特征图构建的。我们利用基于方差的度量来计算成本,这在MVSNet中已经被广泛用于几何重建。具体来说,对于P中以(u, v, z)为中心的每个体素,其成本特征向量的计算方法是:
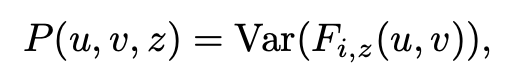
2.辐射场重建
我们建议使用深度神经网络来有效地将构建的成本量转换为重建的辐射场,以实现现实的视图合成。我们利用一个三维CNN B,从原始二维图像特征成本的成本卷P中重建一个神经编码卷S;S由编码局部场景几何和外观的每体素特征组成。一个MLP解码器A被用来从这个编码体积中回归体积渲染属性。
神经编码量。
以前的MVS通常直接从成本体积中预测深度概率,而成本体积只表达场景的几何。我们的目标是实现高质量的渲染,这就需要从成本体积中推断出更多的外观感知信息。因此,我们训练一个深度三维CNN B,将建立的图像特征成本体积转化为一个新的C通道神经特征体积S,其中特征空间是由网络本身学习和发现的,用于以下体积属性回归。这个过程用以下方式表示。
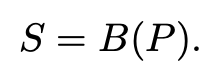
三维CNN B是一个具有下采样和上采样卷积层和跳过连接的三维UNET,它可以有效地推断和传播场景外观信息,导致一个有意义的场景编码体积S。注意,这个编码体积是以无监督的方式预测的,并在端到端训练中推断出体积渲染。我们的网络可以学习在每体素的神经特征中编码有意义的场景几何和外观;这些特征后来被连续插值并转化为体积密度和视图依赖的辐射度。由于二维特征提取的下采样,场景编码体积的分辨率相对较低;仅从这些信息中回归高频外观是具有挑战性的。因此,在接下来的体积回归阶段,我们还加入了原始图像像素数据,尽管我们后来表明,这种高频也可以通过快速的按场景微调优化在增强的体积中得到恢复。 3.端到端的体素渲染 端到端训练。这种光线行进渲染是完全可分的;因此它允许我们的框架在新的视点使用三个输入视图从头到尾回归最终的像素颜色。我们使用L2渲染损失对我们的整个框架进行监督,并使用基础像素颜色。
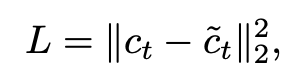
由于基于物理的体积渲染和端到端训练,渲染监督可以通过每个网络组件传播场景外观和对应信息,并将其正则化,以便为最终的视图合成提供意义。与之前主要关注每个场景训练的NeRF不同,我们在DTU数据集的不同场景中训练整个网络。我们的MVSNeRF得益于成本体积处理中的几何感知场景推理,可以有效地学习一个通用函数,该函数可以在新的测试场景上将辐射场重建为神经编码体积,从而实现高质量的视图合成。
4.优化神经编码量。
当跨场景训练时,我们的MVSNeRF已经可以学习一个强大的通用函数,只用三张输入图像就可以重构跨场景的辐射场。然而,由于有限的输入和不同场景和数据集之间的高度多样性,使用这样一个通用的解决方案在不同场景上取得完美的结果是非常具有挑战性的。另一方面,NeRF通过对密集的输入图像进行每个场景的优化,避免了这一难以概括的问题;这导致了逼真的结果,但成本极高。相比之下,我们建议对我们的神经编码量进行微调--我们的网络可以从很少的图像中立即重建,以便在捕获密集的图像时实现快速的按场景优化。
添加颜色。
如前所述,我们的神经编码量在发送到MLP解码器时与像素颜色相结合。保留这种微调的设计仍然有效,但会导致重建总是依赖于三个输入。取而代之的是,我们通过将体素中心的每一视角的颜色作为额外的通道附加到编码量中来实现独立的神经重建;这些颜色作为特征也可以在每个场景的优化中进行训练。这种简单的附加最初在渲染中引入了模糊性,但在微调过程中很快就能解决。
优化。
在添加了颜色之后,MLP的神经编码量是一个体面的初始辐射场,已经可以合成合理的图像。我们建议在有密集图像的情况下,与MLP解码器一起进一步微调体素特征,以进行快速的按场景优化。请注意,我们只优化编码量和MLP,而不是我们的整个网络。这赋予了神经优化更多的灵活性,以便在优化时独立调整每个体素的局部神经特征;这比试图优化跨体素的共享卷积操作更容易。
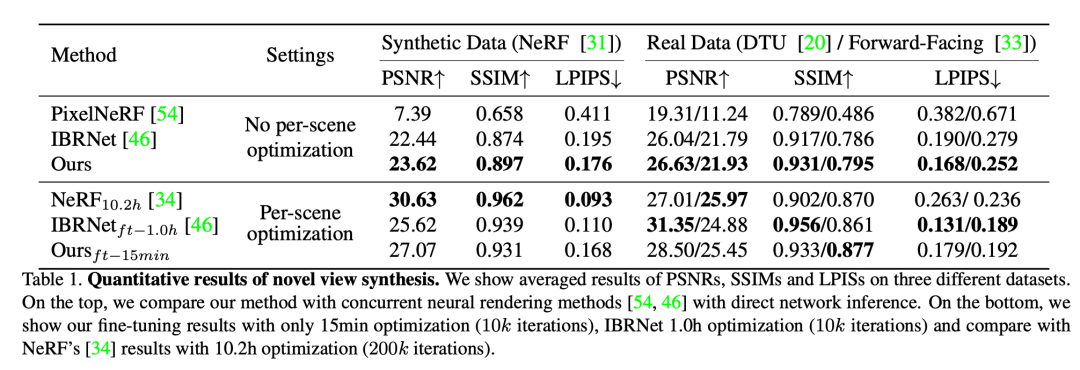
实验结果


编辑:黄飞
-
使用DLP LightCrafter4500投影结构光进行三维重建遇到的疑问求解2025-03-03 619
-
怎样去设计一种基于RGB-D相机的三维重建无序抓取系统?2021-07-02 2135
-
如何去开发一款基于RGB-D相机与机械臂的三维重建无序抓取系统2021-09-08 2266
-
MC三维重建算法的二义性消除研究2010-01-22 963
-
基于FPGA的医学图像三维重建系统设计与实现2011-03-15 1354
-
透明物体的三维重建研究综述2021-04-21 1299
-
NVIDIA Omniverse平台助力三维重建服务协同发展2022-10-13 2639
-
深度学习背景下的图像三维重建技术进展综述2023-01-09 4370
-
如何使用纯格雷码进行三维重建?2023-01-13 2416
-
NerfingMVS:引导优化神经辐射场实现室内多视角三维重建2023-02-13 4732
-
从多视角图像做三维场景重建 (CVPR'22 Oral)2023-02-20 4427
-
三维重建:从入门到入土2023-03-03 2466
-
如何实现整个三维重建过程2023-09-01 2925
-
基于光学成像的物体三维重建技术研究2023-09-15 2078
-
航天宏图全栈式3DGS实景三维重建系统解决方案2025-06-27 2345
全部0条评论

快来发表一下你的评论吧 !
