

对话系统中的中文自然语言理解(NLU)(3.1)学术界中的方法(联合训练)
描述
对话系统中的中文自然语言理解(NLU)(3.1)学术界中的方法(联合训练)
3 学术界中的方法 (Academic Methods)
在这一节中,我们会详细的介绍2个任务:意图分类 和 槽位填充。除此之外,我们还会对以往的一些工作进行回顾。来看一看这些工作是如何完成这两个任务的。你会发现,其中有一些工作便会用到在上一节中提到的中文特色的特征。
In this section, we will cover the 2 tasks in detail: Intent Classification and Slot Filling. In addition to this, we will also review some of the previous work for these two tasks. You will notice that some of these studies used the Chinese-specific features mentioned in the previous article.
需要注意的是,这一系列文章中不包含端到端的工作(比如,将说的话作为喂给一个语言模型,然后模型吐出来意图分类或者槽位填充的结果,或者两者同时吐出来)。
It should be noted that this series of articles does not include end-to-end methods (e.g. feeding utterances to a language model and generating the answers, intent classification results, slot filling, or both).
2个任务 (2 Tasks)
意图分类任务(Intent Classification Task) 和文本分类比较类似,对说出的话进行分类。类别需要提前预先设置好,比如:播放新闻、播放音乐、调高音量等。Similar to Text Classification, the utterances are categorised. The categories need to be pre-defined in advance, e.g. Play News, Play Music, Turn Up Volume, etc.
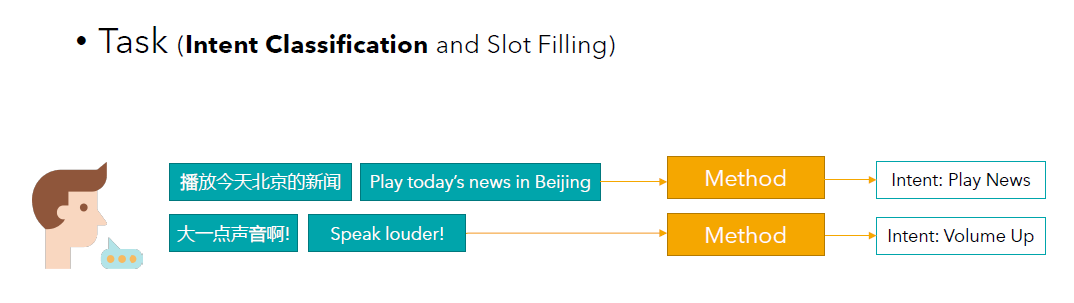
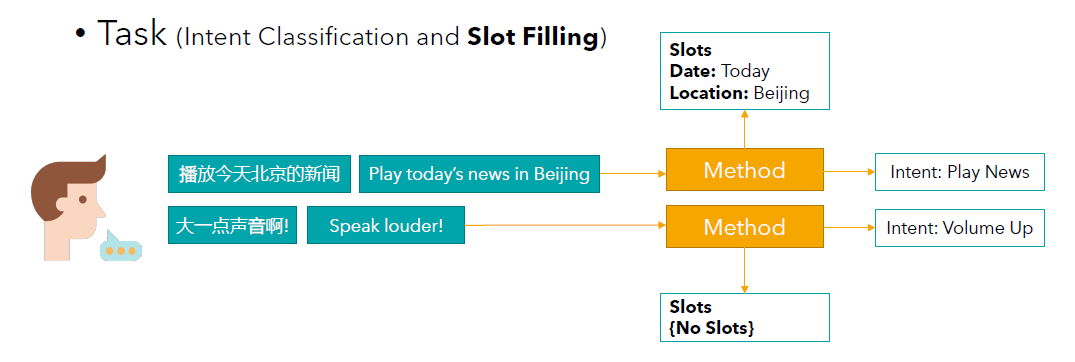
槽位填充任务(Slot Filling Task) 当模型听懂人类的意图之后,为了执行任务,模型便需要进一步了解细节。比如当意图是播放新闻时,模型想进一步知道哪里的以及哪一天发生的新闻。这里的日期和地点便是槽位,而它们对应的信息便是槽位填充的内容。Once the model understands the intent, in order to perform the task, the model needs to obtain further details. For example, when the intention is to Play News, the model has to know Where and on Which Day. In the example in the figure, the Date and Location are the slots, and the information they correspond to is what the slots are filled with.
解决任务的方法(Methods)
目前比较流行的方法有两类。There are roughly two types of popular approaches.
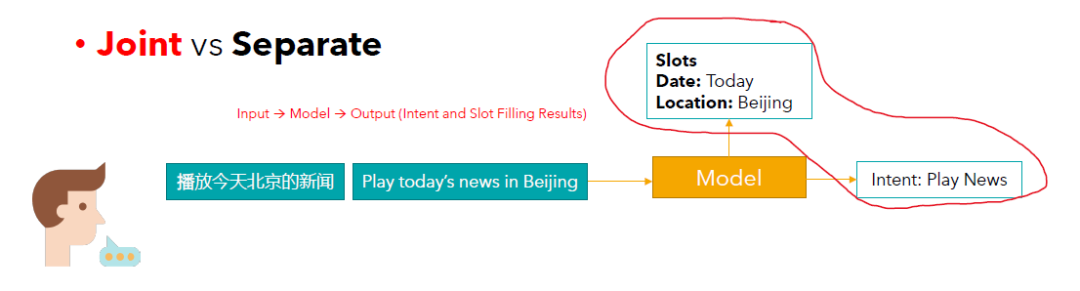
联合训练:为这两个任务设计一个共享的模型主体,而在输出预测结果的时候会进行特别的设计。一般的做法是,这两个任务分别有自己对应的输出层。
Joint training: A shared model body is designed for the two tasks, while the output prediction layers are specifically designed.
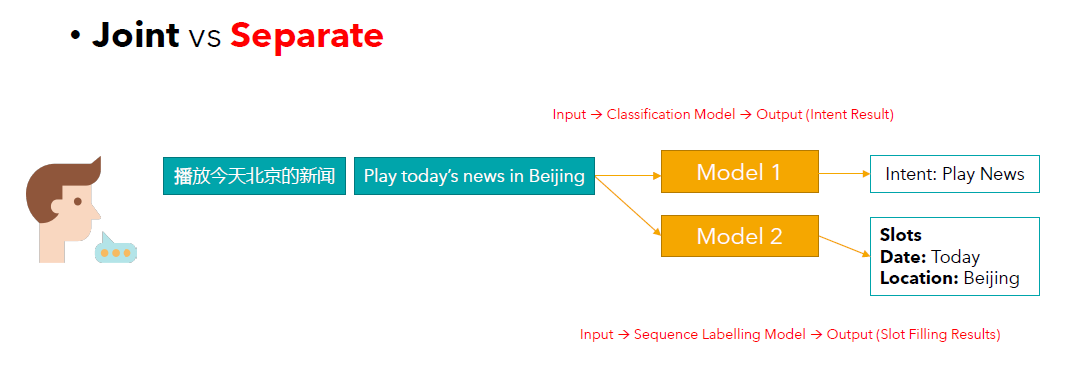
单独训练:把这两个任务当作互相没有关联的任务。也就是说针对每一个任务会单独设计一个方法。
Separate training: The two tasks are considered they are unrelated to each other. This means that a separate method will be designed for each task.
因为我们这篇文章主要介绍针对中文的方法。这里我们简单提一下处理中文和英文方法之间的关系。如下面的图说的那样,处理这两种语言的方法是有重叠部分的。也就是说,有的方法既适用于中文,也适用于英文。需要注意的是,也有一些针对某一种语言的方法,而这些方法是没有办法直接的运用到另一个语种上的。
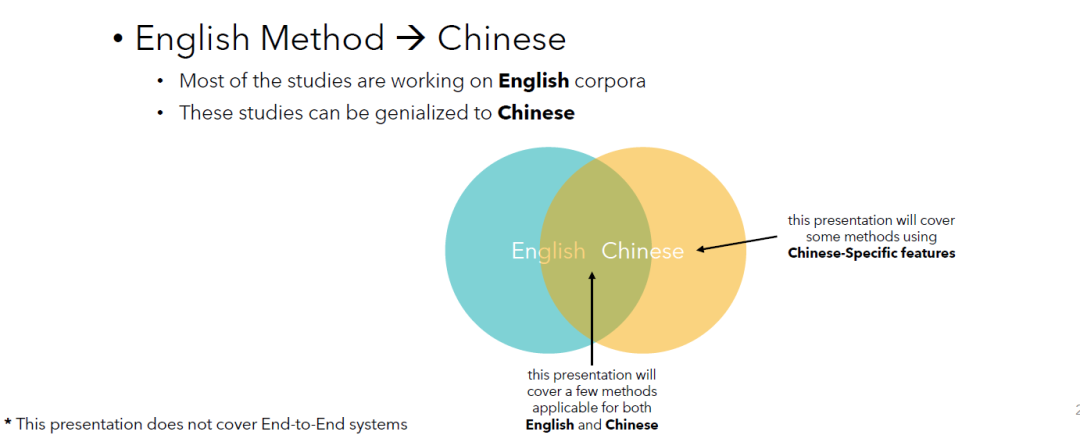
Because our article focuses on methods for the Chinese language. Here we briefly mention the relationship between the methods for dealing with Chinese and English. As the picture illustrates, there is an overlap between the methods for dealing with the two languages. That is, there are methods that work for Chinese as well as English. It is important to note that there are also methods for one language that cannot be directly applied to another language.
3.1 联合训练(Joint Training)
BERT for Joint Intent Classification and Slot Filling, 2019, DAMO Academy, Alibaba

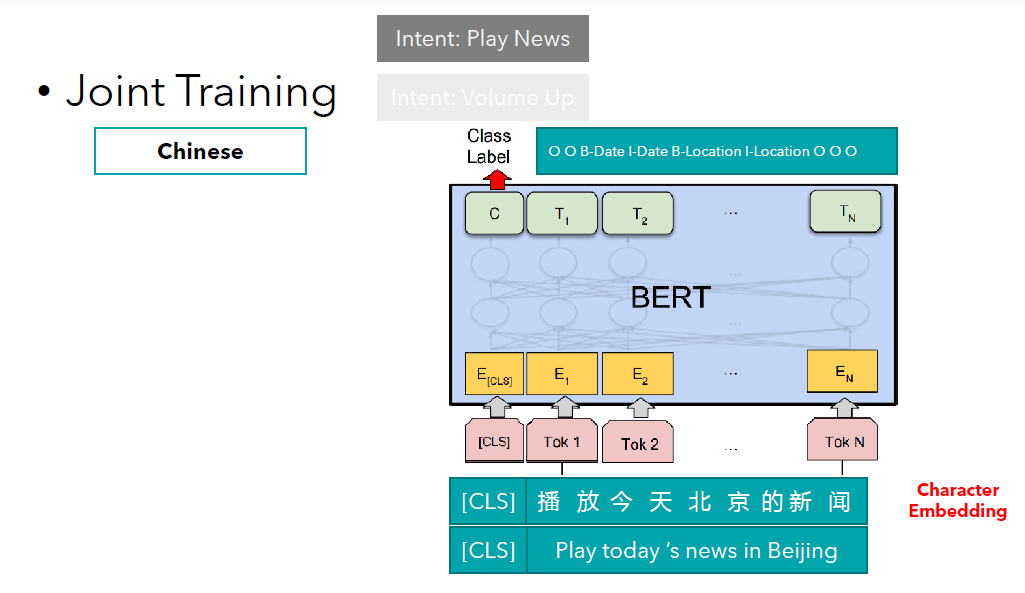
我们从这篇论文说起。在上图中,我们展示了如何处理英文文本。它的框架在目前是比较流行的。Let's start with this paper. The figure shows how the model works with English text. Its framework is relatively popular at the moment.
输入包含两部分:特殊token [CLS] 和 tokens;输出也包含两部分:这句话的意图分类结果(上图中为Play News) 以及 每个token对应的序列标注的标签(today对应Date, Beijing对应Location).
Input consists of two parts: special token [CLS] and tokens; Output also consists of two parts: the result of the intention classification (Play News in the picture above) and the label of the sequence corresponding to each token (Today corresponds to Date, Beijing to Location).
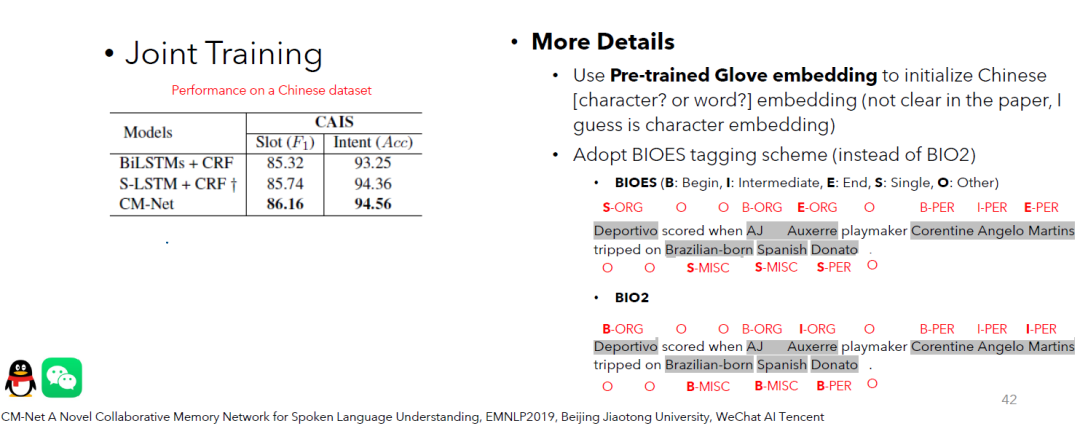
从右上角图中可以看出,在两个公开的数据集上,可以获得不错的效果。那么,如果我们想把它运用到中文上,但同时又不改变模型的结构,应该如何做呢? As you can see from the top right table, good results can be obtained on the two publicly available datasets. What should we do if we plan to apply this model to Chinese, and at the same time not change the structure of the model?
一种简单粗暴的方法是,将每个字作为一个单独的token为输入,并且每个字都会有一个embedding向量。A simple approach would be to consider each Chinese character as an individual token as input, and each character would have an embedding vector.
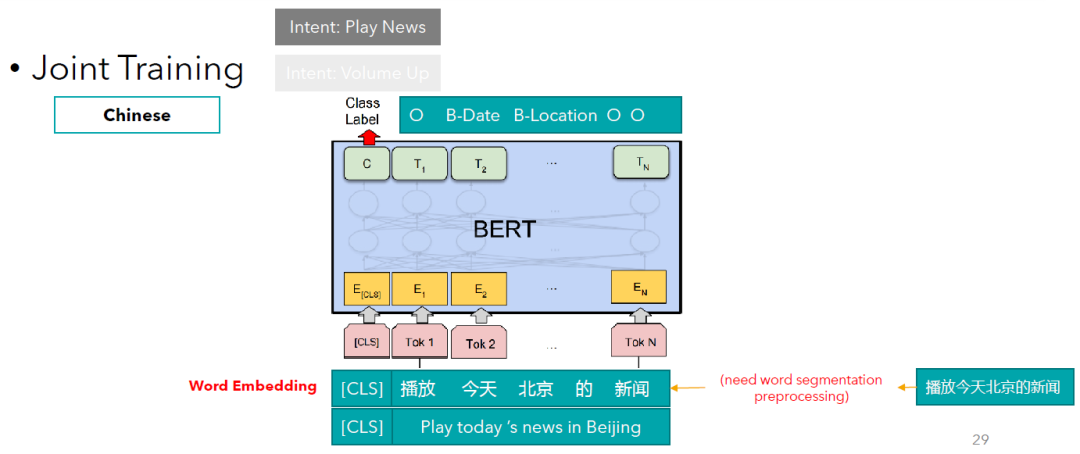
另一种方法是,先将这段文本进行中文分词,然后以词向量的形式输入。Alternatively, we can apply word segmentation to this text (i.e., split text into Chinese words) and then consider word vectors as the inputs.
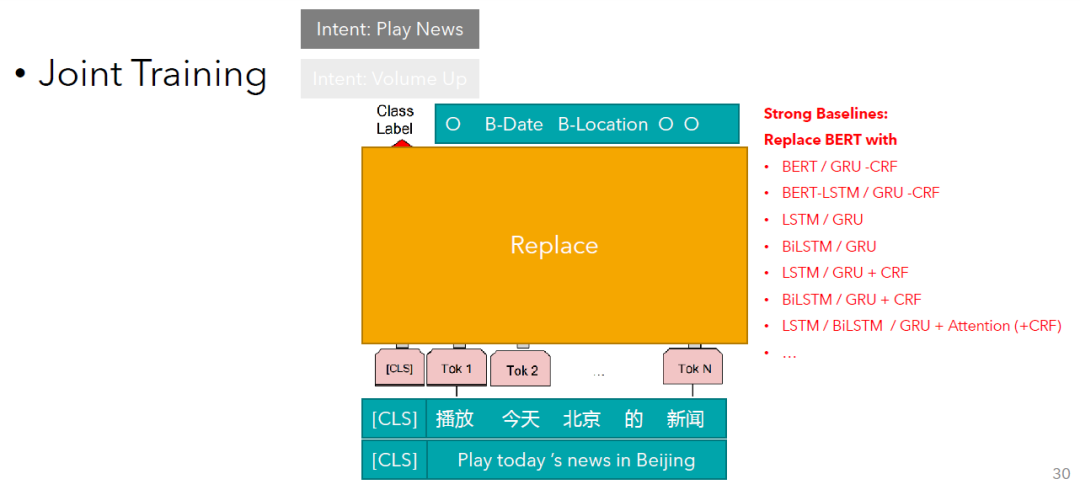
有同学要问了,这里为什么一定要使用BERT模型呢?如果说我的业务场景或者任务需要更加轻量级的模型,但是又需要还可以的效果,又该怎么办呢?You may ask, what if my business scenario or task requires a more lightweight model with acceptable performance? Bert is somehow too heavy for me.
中间是不一定必须使用BERT模型的。中间即使是换成其他的模型,再加上任务没有那么的难,也同样会达到还可以的效果。In this case, it is not necessary to use the BERT model. Even if you replace it with another model, it will still achieve decent performance if the task is not difficult.
如果你是NLP新手的话,对于如何使用CRF层还不是很了解,可以参考我之前写的另一系列文章:CRF Layer on the Top of BiLSTM (https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/)。当然,也可以阅读其他小伙伴的优秀的学习笔记。相信最终你一定会搞懂它的工作原理。If you are new to NLP, and you don't know much about the CRF layer, you can refer to another series of articles I wrote before: CRF Layer on the Top of BiLSTM. Of course, you can also read the excellent articles of other authors. I am sure you will eventually figure out how it works.
A joint model of intent determination and slot filling for spoken language understanding, IJCAI 2016, Peking University
这一篇文章展示的结构为:输入向量→双向GRU结构→CRF层用来做序列标注(即槽位填充)& 最后一个token对应的输出用来做意图分类。The structure shown in this paper is: input vector → bidirectional GRU → CRF layer used for sequence labelling (i.e. slot filling) & the output corresponding to the last token is used to predict the intent.
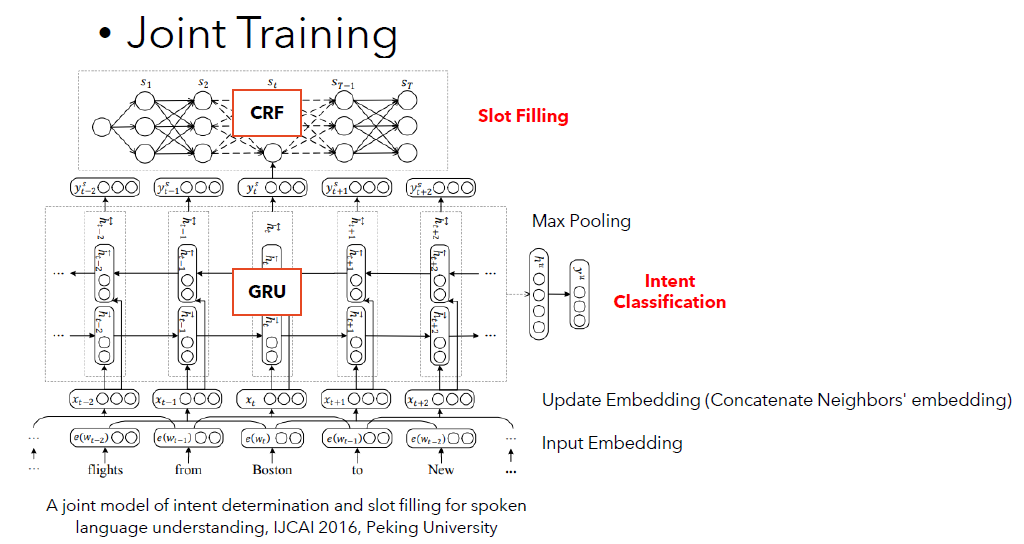
需要注意的是,这里的输入是经过小小的精心设计的。首先,每一个词会拥有自己的向量。虽然如此,真正直接进入模型的,并不是每个词的向量。而是每连续3个词向量,组成新的向量。而这个新的向量才是与GRU部分直接接触的输入。It should be noted that the input here is carefully designed. Firstly, each word will have its own vector. Despite this, it is not the vector of each word that goes directly into the model. Rather, it is every three consecutive word vectors that make up a new vector, and this new vector goes into directly the GRU part.
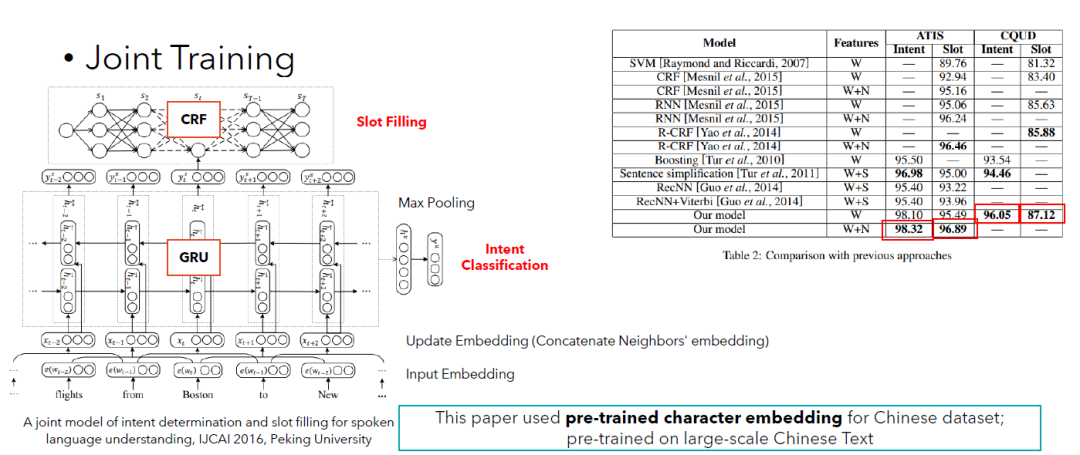
下图展示了模型可以获得效果。在图中我们也写了一个小提醒:本文使用的词向量是在中文大数据上经过训练的词向量。The figure below shows the results. Note that the word vectors used in this paper are word vectors that have been pre-trained on large Chinese text.
Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling, Interspeech 2016, Carnegie Mellon University
这篇论文提出了2个模型。This paper proposes 2 models.
模型1:基于注意力机制的RNN (Model1: Attention-Based RNN)
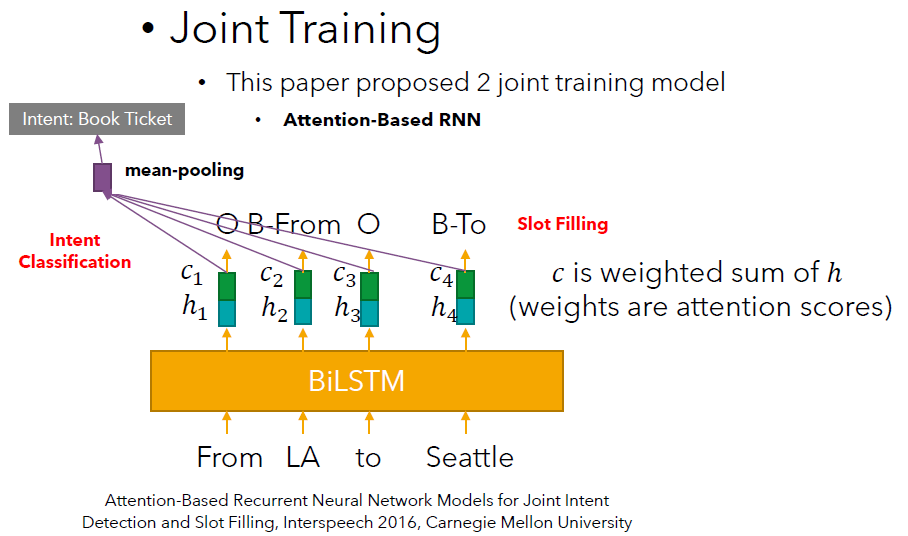
共享部分: 输入→BiLSTM→输出→计算注意力权重分数(在这个例子中,应该总共为16个分数。例如在“From”这个位置,,我们需要得出这4个权重。在其他位置的情况是类似的。每一步都需要计算4个注意力权重分数)→根据注意力权重分数计算
Shared: Input → BiLSTM → Output → Compute attention weight scores (in this example, there should be a total of 16 scores. For example in the position "From",, we need to derive the 4 weights . The situation is similar in the other positions. (Each step requires the calculation of 4 attentional weight scores) → Calculate based on the attention scores
有的小伙伴可能要问了,这个注意力分数是如何计算的呢?现在注意力分数的计算其实已经有了很多不同的做法。它既可以是简单的矩阵、向量之间的操作,也可以是由一个小型的神经网络来决定的。如果感兴趣,可以仔细阅读论文,来研究一下这篇文章是如何计算的。Some of you may be asking, how is this attention score calculated? Nowadays the calculation of the attention score has actually been studied in many different ways. It can either be as simple as manipulating matrices and vectors or it can be determined by a small neural network. If interested, you can read the paper carefully to figure out how this is calculated in this paper.
意图分类部分: 比如图中有4个向量,那么将这几个向量组成一个矩阵,然后使用mean-pooling操作得到一个新的向量。再利用这个新的向量来做分类任务。
Intent Classification Part: For example, if there are 4 vectors in the figure, then form a matrix of these vectors and use the mean-pooling operation to get a new vector. This new vector is used to complete the classification task.
槽位填充部分: 利用向量来预测每一个位置应该是什么标签(比如:From→O,LA→B-From,to→O,Seattle→B-To)。
Slot-Filling Part: Use the vectors to predict what label should be at each position (e.g. From→O, LA→B-From, to→O, Seattle→B-To).
模型2:基于注意力机制的编码-解码器结构 (Model2: Attention-Based Encoder-Decoder)
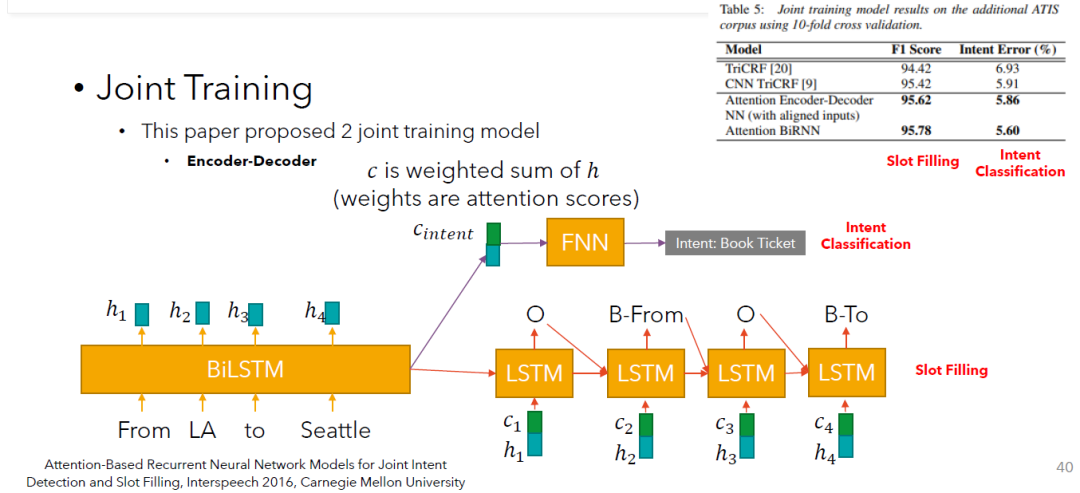
共享部分: 这一部分和模型1是一样的。输入→BiLSTM→输出→计算注意力权重分数(在这个例子中,应该总共为16个分数。例如在“From”这个位置,,我们需要得出这4个权重。在其他位置的情况是类似的。每一步都需要计算4个注意力权重分数)→根据注意力权重分数计算
Shared: Input → BiLSTM → Output → Compute attention weight scores (in this example, there should be a total of 16 scores. For example in the position "From",, we need to derive the 4 weights . The situation is similar in the other positions. (Each step requires the calculation of 4 attentional weight scores) → Calculate based on the attention scores
意图分类部分: 将BiLSTM最后一刻的输出与1个向量(4个的加权求和结果)组合到一起→一个简单的前馈神经网络→分类结果
Intent Classification Part: Combining the last output of the BiLSTM with 1 vector (the weighted summation result of 4 s) → a simple feed-forward neural network → classification result
槽位填充部分: 这一部分相当于是一个文字生成过程,只不过这里生成的是序列标注的标签。每一步的输入由2部分组成:BiLSTM相关的输出结果(和)+ 前一时刻LSTM的输出。每一步根据输入的内容来预测序列标注的标签。
Slot-Filling Part: This part is equivalent to a token-by-token sentence generation process, except that here the labels are generated for the sequence labelling. The input to each step consists of 2 parts: the output results associated with the BiLSTM ( and ) + the output of the LSTM from the previous step. Each step predicts the label based on the input.
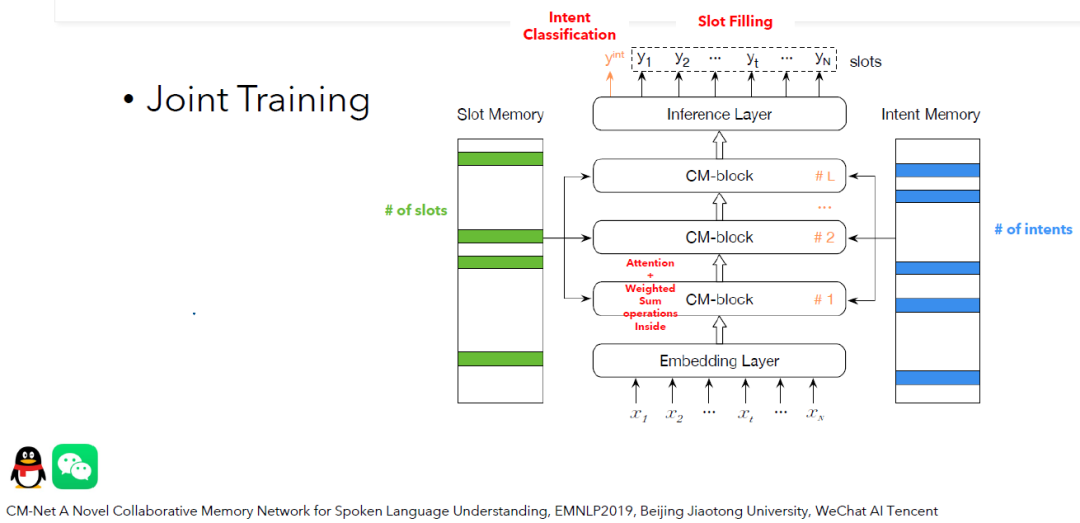
CM-Net A Novel Collaborative Memory Network for Spoken Language Understanding, EMNLP2019, Beijing Jiaotong University, WeChat AI Tencent
这篇论文引入了2个记忆模块:槽位记忆和意图记忆。在这个任务中,有多少个槽位,槽位记忆中就有几个向量。类似的,任务中有多少个意图,意图模块中就会有几个意图向量。我们的期待是这2个模块可以记住一些有用的信息,并且在模型做预测的时候,它们的记忆会有助于提高预测的准确度。This study introduces 2 memory modules: Slot Memory and Intent Memory. There are as many slots of this task as there are vectors in the slot memory (this is similar to intent memory). Our expectation is that these 2 modules will remember useful information and their memory will help to improve the model performance.
那么记忆模块有了,该怎么让他们在模型做预测的时候提供帮助呢?这篇论文还设计了一个特别的神经网络块:CM-block。它的作用就是聪明地综合输入的文本以及记忆模块中的信息,来辅助最终输出层(Inference Layer)做决策。如果你想增强整个模型的推理能力,可以考虑叠加更多的这种神经网络块。The problem is how they work when the model is making predictions. This paper designed a special neural network block: the CM-block. This block is able to intelligently combine input text and the information from the memory block to improve the Inference Layer in making decisions. One way which may increase the reasoning ability of this model is to stack more of these neural network blocks.
需要注意的是,针对序列标注任务,这篇论文采用的不是BIO2序列标签框架。而是采用了BIOES的标签框架。在下面这个图中可以看出,针对同一句话,这两种不同的标注框架会有哪些不同。It should be noticed that for the slot-filling task (a type of sequence labelling task), this paper did not use the BIO2 sequence tagging framework. Instead, the BIOES was used. The picture below explains how these two different labelling frameworks would differ for the same sentence.
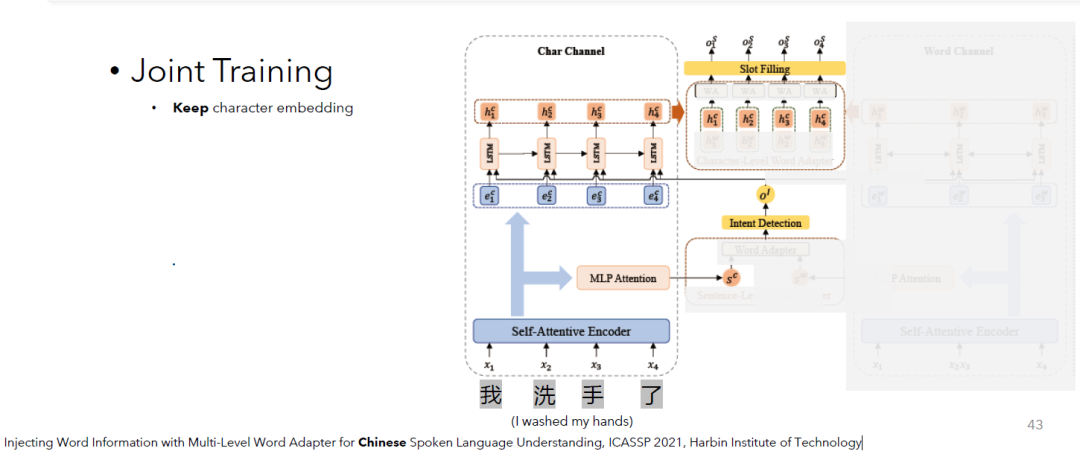
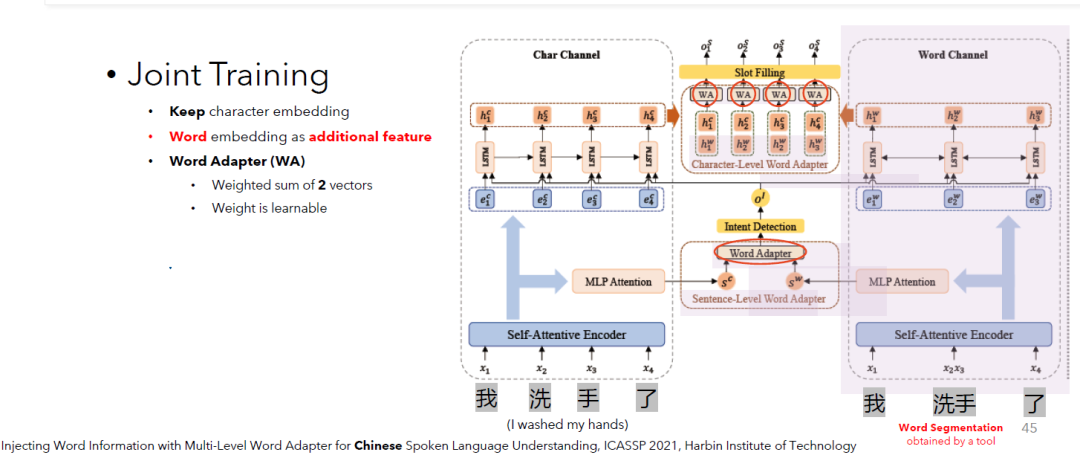
Injecting Word Information with Multi-Level Word Adapter for Chinese Spoken Language Understanding, ICASSP 2021, Harbin Institute of Technology
从这一篇工作中你会发现,它不仅使用了基本的中文字符向量。同时,它还对句子进行了分词预处理,然后将分词后的信息融合在模型中。As you will see from this work, it not only uses basic Chinese character features. It also pre-processes the utterances by word segmentation and then incorporates such word information into the model.
下图中模型看起来有一些复杂。我们不会展开说模型结构的细节。这里是想为大家展示,这个工作综合了字符和分词两者的信息。作者们认为,虽然偶尔可能会有错误的分词结果,但是这不会影响模型从分词结果中获取对理解中文有帮助的信息。The model architecture below looks somewhat complex. We will not describe the details of the model structure. The point here is to show that this work combines information from both characters and words. Although there may be occasional incorrect word segmentation results, this does not affect the model's ability to capture useful information from the words for a better understanding of Chinese.
图中我们可以看出,这个模型的基本输入为中文字符(我,洗,手,了)。As we can see in the figure, the basic input is Chinese characters.
同时,模型也考虑了,中文分词后的结果:我,洗手,了。Moreover, the model takes into account the word segmentation results.
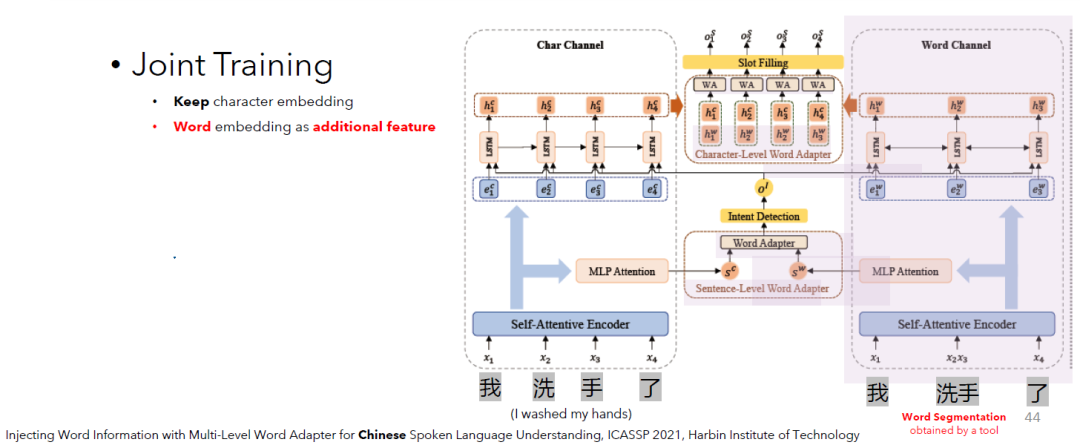
论文还提出了一个小模块Word Adapter。你可以把它看成是一个通用的小工具。我们期待这个小工具的作用是将两种不同的信息聪明的结合。这里聪明的含义便是它可以判断谁轻谁重(weighted sum)。而这种判断的能力,是可以伴随着模型的训练习得的(learnable)。为了将字符和分词结果两者的信息更聪明的结合到一起,便使用了这个聪明的小工具。The paper also presents a small module Word Adapter. You can think of it as a smart mini-module. The purpose of it is to cleverly combine two different kinds of information. We expect that it can determine which information is more important and which is not (weighted sum). Such ability can be learned with the training of the model. You can see that this module is used in combining the information from Chinese characters and words.
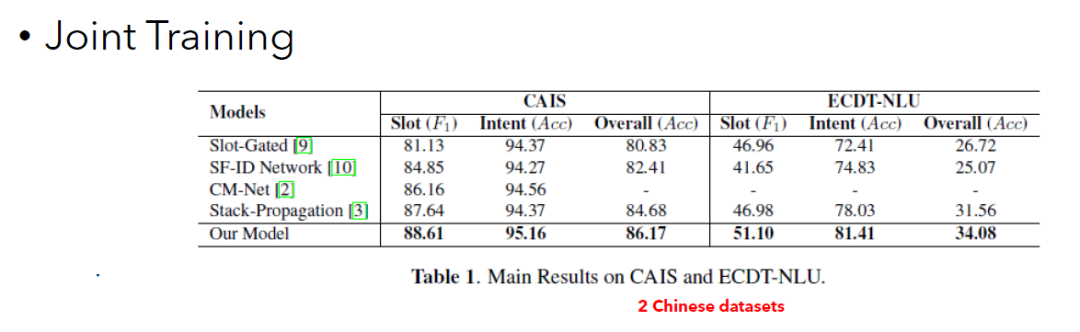
这张表格展示了模型的效果。可以看出,和很多很厉害的其他工作相比,这个模型带来的提升是很明显的。This table shows the model performance. As you can see, the improvement is significant compared to several strong baselines.
下一篇 (Next)
会回顾几篇工作来解释它们是如何单独解决“意图分类”或者“槽位填充”这两个任务的~ The next article will present several studies addressing the two tasks of "Intent Classification" or "Slot Filling" individually~
审核编辑 :李倩
-
python自然语言2018-05-02 6428
-
NLPIR语义分析是对自然语言处理的完美理解2018-10-19 2991
-
自然语言处理中的分词问题总结2018-10-26 2463
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 2595
-
什么是自然语言处理2021-09-08 2775
-
深度视频自然语言描述方法2017-12-04 1135
-
基于复述的中文自然语言接口NLIDB实现方法2017-12-19 765
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5694
-
Facebook人工智能在自然语言理解方面取得重大突破2019-09-17 3472
-
结合NLU在面向任务的对话系统中的具体应用进行介绍2019-03-21 6381
-
谷歌和微软自然语言理解榜单中超越人类表现2021-01-08 2592
-
关于三篇论文中自然语言研究进展与发展方向详解2021-03-30 4184
-
自然语言理解的数据定制服务:赋能智能化应用的关键2023-06-18 905
-
自然语言理解问答对话文本数据,赋予计算机智能交流的能力2023-08-07 1461
-
神经网络在自然语言处理中的应用2024-07-01 1625
全部0条评论

快来发表一下你的评论吧 !
