

NVIDIA Triton推理服务器的功能与架构简介
描述
前面文章介绍微软 Teams 会议系统、微信软件与腾讯 PCG 服务三个 Triton 推理服务器的成功案例,让大家对 Triton 有初步的认知,但别误以为这个软件只适合在大型的服务类应用中使用,事实上 Triton 能适用于更广泛的推理环节中,并且在越复杂的应用环境中就越能展现其执行成效。
在说明 Triton 推理服务器的架构与功能之前,我们需要先了解一个推理服务器所需要面对并解决的问题。
与大部分的服务器软件所需要的基本功能类似,一个推理服务器也得接受来自不同用户端所提出的各种要求(request)然后做出回应(response),并且对系统的处理进行性能优化与稳定性管理。
但是推理计算需要面对深度学习领域的各式各样推理模型,包括图像分类、物件检测、语义分析、语音识别等不同应用类别,每种类别还有不同神经网络算法与不同框架所训练出来的模型格式等。此外,我们不能对任务进行单纯的串行队列(queue)方式处理,这会使得任务等待时间拖得很长,影响使用的体验感,因此必须对任务进行并行化处理,这里就存在非常复杂的任务管理技巧。
下面列出一个推理服务器所需要面对的技术问题:
1.支持多种模型格式:至少需要支持普及度最高的
2. TensorFlow 的 GraphDef 与 SavedMode 中一种以上格式
(1) PyTorch 的 TorchScript 格式
(2) ONNX 开放标准格式
(3) 其他:包括自定义模型格式
3. 支持多种查询类型,包括
(1) 在线的实时查询:尽量降低查询的延迟(latency)时间
(2) 离线的批量处理:尽量提高查询的通量(throughput)
(3) 流水线传输的识别号管理等工作
4. 支持多种部署方式:包括
(1) 企业的 GPU 或 CPU 计算设备
(2) 公共云或数据中心
5. 对模型进行最佳缩放处理:让个别模型提供更好的性能
6. 优化多个 KPI:包括
(1) 硬件利用率
(2) 模型推理识别时间
(3) 总体成本(TCO)
7. 提高系统稳定性:需监控模型状态并解决问题以防止停机
在了解推理服务器所需要解决的关键问题之后,接着来看看下方的 Triton 系统高阶架构图,就能更清楚每个板块所负责的任务与使用的对应技术。
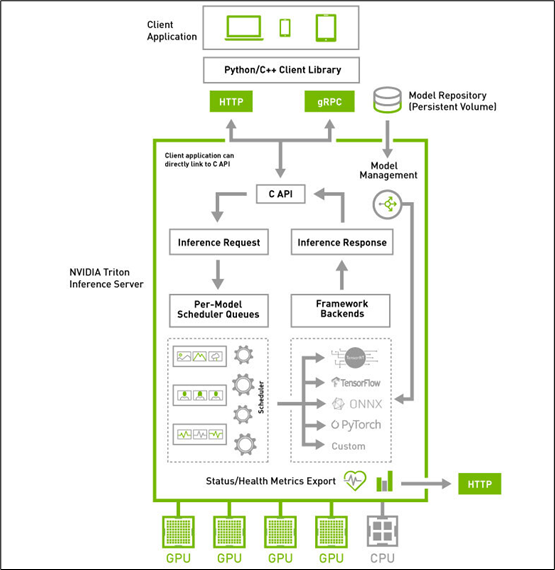
Triton 推理服务器采用属于 “主从(client-server)” 架构的系统,由图中的四个板块所组成:
1.模型仓(Model Repostory):存放 Triton 服务器所要使用的模型文件与配置文件的存储设备,可以是本地服务器的文件系统,也可以使用 Google、AWS、Azure 等云存储空间,只要遵循 Triton 服务器所要求的规范就可以;
2. 客户端应用(Client Application):基于 Triton 用户端 Python / C++ / Java 库所撰写,可以在各种操作系统与 CPU 架构上操作,对 Triton 服务器提交任务请求,并且接受返回的计算结果。这是整个 Triton 推理应用中代码量最多的一部分,也是开发人员需要花费最多心思的部分,在后面会有专文讲解。
3. HTTP / gPRC 通讯协议:作为用户端与服务端互动的通讯协议,开发人员可以根据实际状况选择其中一种通讯协议进行操作,能透过互联网对服务器提出推理请求并返回推理结果,如下图所示:
使用这类通讯协议有以下优点:
(1) 支持实时、批处理和流式推理查询,以获得最佳应用程序体验
(2) 提供高吞吐量推理,同时使用动态批处理和并发模型执行来满足紧张的延迟预算
(3) 模型可以在现场制作中更新,而不会中断应用程序
4. 推理服务器(Inference Server):这是整个 Triton 服务器最核心且最复杂的部分,特别在 “性能”、“稳定”、“扩充” 这三大要求之间取得平衡的管理,主要包括以下几大功能板块:
(1) C 开发接口:
在服务器内的代码属于系统底层机制,主要由 NVIDIA 系统工程师进行维护,因此只提供性能较好的 C 开发接口,一般应用工程师可以忽略这部分,除非您有心深入 Triton 系统底层进行改写。
(2) 模型管理器(Model Management):
支持多框架的文件格式并提供自定义的扩充能力,目前已支持 TensorFlow 的 GraphDef 与 SavedModel 格式、ONNX、PyTorch TorchScript、TensorRT、用于基于树的 RAPIDS FIL 模型、OpenVINO 等模型文件格式,还能使用自定义的 Python / C++ 模型格式;
(3) 模型的推理队列调度器(Per-Model Scheduler Queues):
将推理模型用管道形式进行管理,将一个或多个模型的预处理或后处理进行逻辑排列,并管理模型之间的输入和输出张量的连接,任何的推理请求都会触发这个模型管道。这部分还包含以下两个重点:
并发模型执行(Concurrent Model Execution):允许同一模型的多个模型和 / 或多个实例在同一系统上并行执行,系统可能有零个、一个或多个 GPU。
模型和调度程序(Models And Schedulers):支持多种调度和批量处理算法,可为每个模型单独选择无状态(stateless)、有状态(stateful)或集成(ensemble)模式。对于给定的模型,调度器的选择和配置是通过模型的配置文件完成的。
(4) 计算资源的优化处理:
这是作为服务器软件的最重要工作之一,就是要将设备的计算资源充分调度,并且优化总体计算性能,主要使用以下三种技术。
支持异构计算模式:可部署在纯 x86 与 ARM CPU 的计算设备上,也支持装载 NVIDIA GPU 的计算设备。
动态批量处理(Dynamic batching)技术:对支持批处理的模型提供多个内置的调度和批处理算法,并结合各个推理请求以提高推理吞吐量,这些调度和批量处理决策对请求推理的客户端是透明的。
批量处理推理请求分为客户端批量处理和服务器批量处理两种,通过将单个推理请求组合在一起来实现服务器批处理,以提高推理吞吐量;
构建一个批量处理缓存区,当达到配置的延迟阈值后便启动处理机制;
调度和批处理决策对请求推断的客户机是透明的,并且根据模型进行配置。
c.并发模型(Concurrent model)运行:多个模型或同一模型的多个实例,可以同时在一个 GPU 或多个 GPU 上运行,以满足不同的模型管理需求。
(5) 框架后端管理器(Framework Backends):
Triton 的后端就是执行模型的封装代码,每种支持的框架都有一个对应的后端作为支持,例如 tensorrt_backend 就是支持 TensorRT 模型推理所封装的后端、openvino_backend 就是支持 openvine 模型推理所封装的后端,目前在 Triton 开源项目里已经提供大约 15 种后端,技术人员可以根据开发无限扩充。
要添加一个新的后台是相当复杂的过程,因此在本系列文章中并不探索,这里主要说明以下 Triton 服务器对各个后端的管理机制,主要是以下重点:
采用 KFServing 的新社区标准 gRPC 和 HTTP/REST 数据平面(data plane)v2 协议(如下图),这是 Kubernetes 上基于各种标准的无服务器推理架构
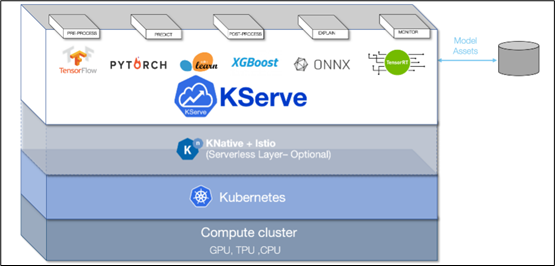
通过配置自动化和自动扩展简化 Kubernetes 中的推理服务部署
透明地处理负载峰值,即使请求数量显著增加,请求的服务也将继续顺利运行
可以通过定义转换器,轻松地将标记化和后处理等预处理步骤包含在部署中
可以用 NGC 的 Helm 命令在 Kubernetes 中部署 Triton,也可以部署为容器微服务,为 GPU 和 CPU 上的预处理或后处理和深度学习模型提供服务,也能轻松部署在数据中心或云平台上
将推理实例进行微服务处理,每个实例都可以在 Kubernetes 环境中独立扩展,以获得最佳性能
通过这种新的集成,可以轻松地在 Kubernetes 使用 Triton 部署高性能推理
以上是 Triton 推理服务器的高级框架与主要特性的简介,如果看完本文后仍感觉有许多不太理解的部分,这是正常的现象,因为整个 Triton 系统集成非常多最先进的技术在内,并非朝夕之间就能掌握的。
后面的内容就要进入 Triton 推理服务器的环境安装与调试,以及一些基础范例的执行环节,透过这些实际的操作,逐步体验 Triton 系统的强大。
审核编辑:汤梓红
-
使用NVIDIA Triton推理服务器来加速AI预测2024-02-29 1942
-
如何使用NVIDIA Triton 推理服务器来运行推理管道2023-07-05 2331
-
NVIDIA Triton 系列文章(6):安装用户端软件2022-11-29 3569
-
NVIDIA Triton 系列文章(5):安装服务器软件2022-11-22 3374
-
NVIDIA Triton推理服务器的基本特性及应用案例2022-10-26 3880
-
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求2022-09-05 3555
-
NVIDIA Triton的概念、特性及主要功能2022-07-18 5492
-
NVIDIA Triton助力腾讯PCG加速在线推理2022-05-20 3132
-
利用NVIDIA Triton推理服务器加速语音识别的速度2022-05-13 3143
-
使用NVIDIA Triton推理服务器简化边缘AI模型部署2022-04-18 3796
-
NVIDIA Triton推理服务器简化人工智能推理2022-04-08 3330
-
使用MIG和Kubernetes部署Triton推理服务器2022-04-07 4816
-
NVIDIA Triton开源推理服务软件三大功能推动效率提升2022-01-04 2966
-
NVIDIA Triton 推理服务器助力西门子提升工业效率2021-11-16 4473
全部0条评论

快来发表一下你的评论吧 !
