

Redis分布式锁真的安全吗?
电子说
描述
今天我们来聊一聊Redis分布式锁。
首先大家可以先思考一个简单的问题,为什么要使用分布式锁?普通的jvm锁为什么不可以?
这个时候,大家肯定会吧啦吧啦想到一堆,例如java应用属于进程级,不同的ecs中部署相同的应用,他们之间相互独立。
所以,在分布式系统中,当有多个客户端需要获取锁时,我们需要分布式锁。此时,锁是保存在一个共享存储系统中的,可以被多个客户端共享访问和获取。
分布式锁(SET NX)
知道了分布式锁的使用场景,我们来自己简单的实现下分布式锁:
public class IndexController {
public String deductStock() {
String lockKey = "lock:product_101";
//setNx 获取分布式锁
String clientId = UUID.randomUUID().toString();
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS); //jedis.setnx(k,v)
if (!result) {
return "error_code";
}
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
//解锁
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
stringRedisTemplate.delete(lockKey);
}
}
}
以上代码简单的实现了一个扣减库存的业务逻辑,我们拆开来说下都做了什么事情:
1、首先声明了lockkey,表示我们需要set的keyName
2、其次UUID.randomUUID().toString();生成该次请求的requestId,为什么需要生成这个唯一的UUID,后面在解锁的时候会说到
3、获取分布式锁,通过stringRedisTemplate.opsForValue().setIfAbsent来实现,该语句的意思是如果存在该key则返回false,若不存在则进行key的设置,设置成功后返回true,将当前线程获取的uuid设置成value,给定一个锁的过期时间,防止该线程无限制持久锁导致死锁,也为了防止该服务器突然宕机,导致其他机器的应用无法获取该锁,这个是必须要做的设置,至于过期的时间,可以根据内层业务逻辑的执行时间来决定
4、执行内层的业务逻辑,进行扣库存的操作
5、业务逻辑执行完成后,走到finally的解锁操作,进行解锁操作时,首先我们来判断当前锁的值是否为该线程持有的,防止当前线程执行较慢,导致锁过期,从而删除了其他线程持有的分布式锁,对于该操作,我来举个例子:
时刻1:线程A获取分布式锁,开始执行业务逻辑
时刻2:线程B等待分布式锁释放
时刻3:线程A所在机器IO处理缓慢、GC pause等问题导致处理缓慢
时刻4:线程A依旧处于block状态,锁过期
时刻5:线程B获取分布式锁,开始执行业务逻辑,此时线程A结束block,开始释放锁
时刻6:线程B处理业务逻辑缓慢,线程A释放分布式锁,但是此时释放的是线程B的锁,导致其他线程可以开始获取锁
看到这里,为什么每个请求需要requestId,并且在释放锁的情况下判断是否是当前的requestId是有必要的。
以上,就是一个简单的分布式锁的实现过程。但是你觉得上述实现还存在问题吗?
答案是肯定的。若是在判断完分布式锁的value与requestId之后,锁过期了,依然会存在以上问题。
那么有没有什么办法可以规避以上问题,让我们不需要去完成这些实现,只需要专注于业务逻辑呢?
我们可以使用Redisson,并且Redisson有中文文档,方便英文不好的同学查看(开发团队中有中国的jackygurui)。
接下来我们再把上述代码简单的改造下就可以规避这些问题:
public class IndexController {
public String deductStock() {
String lockKey = "lock:product_101";
//setNx 获取分布式锁
//String clientId = UUID.randomUUID().toString();
//Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS); //jedis.setnx(k,v)
//获取锁对象
RLock redissonLock = redisson.getLock(lockKey);
//加分布式锁
redissonLock.lock();
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
//解锁
//if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
// stringRedisTemplate.delete(lockKey);
//}
//redisson分布式锁解锁
redissonLock.unlock();
}
}
可以看到,使用redisson分布式锁会简单很多,我们通过redissonLock.lock()和redissonLock.unlock()解决了这个问题,看到这里,是不是有同学会问,如果服务器宕机了,分布式锁会一直存在吗,也没有去指定过期时间?
redisson分布式锁中有一个watchdog机制,即会给一个leaseTime,默认为30s,到期后锁自动释放,如果一直没有解锁,watchdog机制会一直重新设定锁的过期时间,通过设置TimeTask,延迟10s再次执行锁续命,将锁的过期时间重置为30s。下面就从redisson.lock()的源码来看下:
lock的最终加锁方法:
RFuture tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand command) { internalLockLeaseTime = unit.toMillis(leaseTime); return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command, "if (redis.call('exists', KEYS[1]) == 0) then " + "redis.call('hset', KEYS[1], ARGV[2], 1); " + "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + "redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + "return redis.call('pttl', KEYS[1]);", Collections.
可以看到lua脚本中redis.call('pexpire', KEYS[1], ARGV[1]);对key进行设置,并给定了一个internalLockLeaseTime,给定的internalLockLeaseTime就是默认的加锁时间,为30s。
接下来我们在看下锁续命的源码:
private void scheduleExpirationRenewal(final long threadId) {
if (!expirationRenewalMap.containsKey(this.getEntryName())) {
Timeout task = this.commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
public void run(Timeout timeout) throws Exception {
//重新设置锁过期时间
RFuture future = RedissonLock.this.commandExecutor.evalWriteAsync(RedissonLock.this.getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN, "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]); return 1; end; return 0;", Collections.singletonList(RedissonLock.this.getName()), new Object[]{RedissonLock.this.internalLockLeaseTime, RedissonLock.this.getLockName(threadId)});
future.addListener(new FutureListener() {
public void operationComplete(Future future) throws Exception {
RedissonLock.expirationRenewalMap.remove(RedissonLock.this.getEntryName());
if (!future.isSuccess()) {
RedissonLock.log.error("Can't update lock " + RedissonLock.this.getName() + " expiration", future.cause());
} else {
//获取方法调用的结果
if ((Boolean)future.getNow()) {
//进行递归调用
RedissonLock.this.scheduleExpirationRenewal(threadId);
}
}
}
});
}
//延迟 this.internalLockLeaseTime / 3L 再执行run方法
}, this.internalLockLeaseTime / 3L, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(this.getEntryName(), task) != null) {
task.cancel();
}
}
}
从源码层可以看到,加锁成功后,会延迟10s执行task中的run方法,然后在run方法里面执行锁过期时间的重置,如果时间重置成功,则继续递归调用该方法,延迟10s后进行锁续命,若重置锁时间失败,则可能表示锁已释放,退出该方法。
以上,就是关于一个redis分布式锁的说明,看到这里,大家应该对分布式锁有一个大致的了解了。
但是尽管使用了redisson完成分布式锁的实现,对于分布式锁是否还存在问题,分布式锁真的安全吗?
一般的,线上的环境肯定使用redis cluster,如果数据量不大,也会使用的redis sentinal。那么就存在主从复制的问题,那么是否会存在这种情况,在主库设置了分布式锁,但是可能由于网络或其他原因导致数据还没有同步到从库,此时主库宕机,选择从库作为主库,新主库中并没有该锁的信息,其他线程又可以进行锁申请,造成了发生线程安全问题的可能。
为了解决这个问题,redis的作者实现了redlock,基于redlock的实现有很大的争论,并且现在已经弃用了,但是我们还是需要了解下原理,以及之后基于这些问题的解决方案。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://gitee.com/zhijiantianya/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
分布式锁Redlock
Redlock是基于单Redis节点的分布式锁在failover的时候会产生解决不了的安全性问题而产生的,基于N个完全独立的Redis节点。
下面我来看下redlock获取锁的过程:
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁 的操作:
获取当前时间(毫秒数)。
按顺序依次向N个Redis节点执行获取锁 的操作。这个获取操作跟前面基于单Redis节点的获取锁 的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁 的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有
计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁 的操作。
好了,了解了redlock获取锁的机制之后,我们再来讨论下redlock会有哪些问题:
问题一:
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
客户端1成功锁住了A, B, C,获取锁 成功(但D和E没有锁住)。
节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
节点C重启后,客户端2锁住了C, D, E,获取锁 成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,Redis作者antirez又提出了延迟重启 (delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
关于Redlock还有一点细节值得拿出来分析一下:在最后释放锁 的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁 的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?设想这样一种情况,客户端发给某个Redis节点的获取锁 的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
所以,如果不进行延迟重启,或者对于同一个主节点进行多个从节点的备份,并要求从节点的同步必须实时跟住主节点,也就是说需要配置redis从库的同步策略,将延迟设置为最小(主从同步是异步进行的),通过min-replicas-max-lag(旧版本的redis使用min-slaves-max-lag)来设置主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟(以秒为单位),也就是说,这个值需要设置为0,否则都有可能出现延迟,但是这个实际上在redis中是不存在的,min-replicas-max-lag设置为0,就代表着这个配置不生效。redis本身是为了高效而存在的,如果因为需要保证业务的准确性而使用,大大降低了redis的性能,建议使用的别的方式。
问题二:
如果客户端长期阻塞导致锁过期,那么它接下来访问共享资源就不安全了(没有了锁的保护)。在RedLock中还是存在该问题的。
虽然在获取锁之后Redlock会去判断锁的有效性,如果锁过期了,则会再去重新拿锁。但是如果发生在获取锁之后,那么该有效性都得不到保障了。
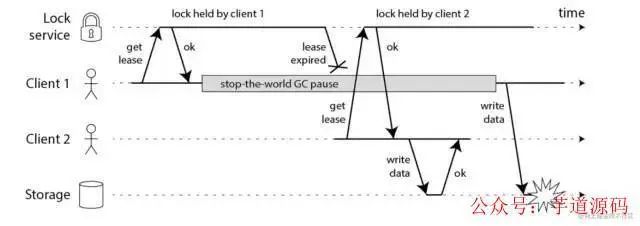
在上面的时序图中,假设锁服务本身是没有问题的,它总是能保证任一时刻最多只有一个客户端获得锁。上图中出现的lease这个词可以暂且认为就等同于一个带有自动过期功能的锁。客户端1在获得锁之后发生了很长时间的GC pause,在此期间,它获得的锁过期了,而客户端2获得了锁。当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源(上图中是一个存储服务)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。
初看上去,有人可能会说,既然客户端1从GC pause中恢复过来以后不知道自己持有的锁已经过期了,那么它可以在访问共享资源之前先判断一下锁是否过期。但仔细想想,这丝毫也没有帮助。因为GC pause可能发生在任意时刻,也许恰好在判断完之后。
也有人会说,如果客户端使用没有GC的语言来实现,是不是就没有这个问题呢?质疑者Martin指出,系统环境太复杂,仍然有很多原因导致进程的pause,比如虚存造成的缺页故障(page fault),再比如CPU资源的竞争。即使不考虑进程pause的情况,网络延迟也仍然会造成类似的结果。
总结起来就是说,即使锁服务本身是没有问题的,而仅仅是客户端有长时间的pause或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。
那怎么解决这个问题呢?Martin给出了一种方法,称为fencing token。fencing token是一个单调递增的数字,当客户端成功获取锁的时候它随同锁一起返回给客户端。而客户端访问共享资源的时候带着这个fencing token,这样提供共享资源的服务就能根据它进行检查,拒绝掉延迟到来的访问请求(避免了冲突)。如下图:
在上图中,客户端1先获取到的锁,因此有一个较小的fencing token,等于33,而客户端2后获取到的锁,有一个较大的fencing token,等于34。客户端1从GC pause中恢复过来之后,依然是向存储服务发送访问请求,但是带了fencing token = 33。存储服务发现它之前已经处理过34的请求,所以会拒绝掉这次33的请求。这样就避免了冲突。
但是,对于客户端和资源服务器之间的延迟(即发生在算法第3步之后的延迟),antirez是承认所有的分布式锁的实现,包括Redlock,是没有什么好办法来应对的。包括在我们到生产环境中,无法避免分布式锁超时。
在讨论中,有人提出客户端1和客户端2都发生了GC pause,两个fencing token都延迟了,它们几乎同时到达了文件服务器,而且保持了顺序。那么,我们新加入的判断逻辑,即判断fencing token的合理性,应该对两个请求都会放过,而放过之后它们几乎同时在操作文件,还是冲突了。既然Martin宣称fencing token能保证分布式锁的正确性,那么上面这种可能的猜测也许是我们理解错了。但是Martin并没有在后面做出解释。
问题三:
Redlock对系统记时(timing)的过分依赖,下面给出一个例子(还是假设有5个Redis节点A, B, C, D, E):
客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
客户端1和客户端2现在都认为自己持有了锁。
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。
但是作者反驳到,通过恰当的运维,完全可以避免时钟发生大的跳动,而Redlock对于时钟的要求在现实系统中是完全可以满足的。哪怕是手动修改时钟这种人为原因,不要那么做就是了。否则的话,都会出现问题。
说了这么多关于Redlock的问题,到底有没有什么分布式锁能保证安全性呢?我们接下来再来看看ZooKeeper分布式锁。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
基于ZooKeeper的分布式锁更安全吗?
很多人(也包括Martin在内)都认为,如果你想构建一个更安全的分布式锁,那么应该使用ZooKeeper,而不是Redis。那么,为了对比的目的,让我们先暂时脱离开本文的题目,讨论一下基于ZooKeeper的分布式锁能提供绝对的安全吗?它需要fencing token机制的保护吗?
Flavio Junqueira是ZooKeeper的作者之一,他的这篇blog就写在Martin和antirez发生争论的那几天。他在文中给出了一个基于ZooKeeper构建分布式锁的描述(当然这不是唯一的方式):
客户端尝试创建一个znode节点,比如/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。
持有锁的客户端访问共享资源完成后,将znode删掉,这样其它客户端接下来就能来获取锁了。
znode应该被创建成ephemeral的。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
看起来这个锁相当完美,没有Redlock过期时间的问题,而且能在需要的时候让锁自动释放。但仔细考察的话,并不尽然。
ZooKeeper是怎么检测出某个客户端已经崩溃了呢?实际上,每个客户端都与ZooKeeper的某台服务器维护着一个Session,这个Session依赖定期的心跳(heartbeat)来维持。如果ZooKeeper长时间收不到客户端的心跳(这个时间称为Sesion的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
设想如下的执行序列:
客户端1创建了znode节点/lock,获得了锁。
客户端1进入了长时间的GC pause。
客户端1连接到ZooKeeper的Session过期了。znode节点/lock被自动删除。
客户端2创建了znode节点/lock,从而获得了锁。
客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
最后,客户端1和客户端2都认为自己持有了锁,冲突了。这与之前Martin在文章中描述的由于GC pause导致的分布式锁失效的情况类似。
看起来,用ZooKeeper实现的分布式锁也不一定就是安全的。该有的问题它还是有。但是,ZooKeeper作为一个专门为分布式应用提供方案的框架,它提供了一些非常好的特性,是Redis之类的方案所没有的。像前面提到的ephemeral类型的znode自动删除的功能就是一个例子。
还有一个很有用的特性是ZooKeeper的watch机制。这个机制可以这样来使用,比如当客户端试图创建/lock的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。客户端可以进入一种等待状态,等待当/lock节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这样的特性Redlock就无法实现。
小结一下,基于ZooKeeper的锁和基于Redis的锁相比在实现特性上有两个不同:
在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于Redis的锁对于有效时间(lock validity time)到底设置多长的两难问题。实际上,基于ZooKeeper的锁是依靠Session(心跳)来维持锁的持有状态的,而Redis不支持Session。
基于ZooKeeper的锁支持在获取锁失败之后等待锁重新释放的事件。这让客户端对锁的使用更加灵活。
总结
综上所述,我们可以得出两种结论:
如果仅是为了效率(efficiency),那么你可以自己选择你喜欢的一种分布式锁的实现。当然,你需要清楚地知道它在安全性上有哪些不足,以及它会带来什么后果,这也是为什么我们需要了解实现原理的原因,大多数情况下不会出问题,但是就万一的情况,处理起来可能需要大量的时间定位问题。
如果你是为了正确性(correctness),那么请慎之又慎。就目前来说ZooKeeper的分布锁相对于redlock更加合理。
最后,由于redlock的出现其实是为了保证分布式锁的可靠性,但是由于实现的种种问题其可靠性并没有ZooKeeper分布式锁来的高,对于可容错的希望效率的场景下,redis分布式锁又可以完全满足,这也是导致了redlock被弃用的原因。
-
redis分布式锁的应用场景有哪些2023-12-04 2897
-
redis分布式锁如何实现2023-11-16 1597
-
深入理解redis分布式锁2023-10-08 2160
-
redis分布式锁场景实现2023-09-25 1785
-
如何使用注解实现redis分布式锁!2023-04-25 1122
-
使用Redis作为分布式锁的详细方案2022-04-10 2757
-
为什么需要分布式锁 基于Zookeeper锁安全吗2021-08-10 6468
-
Redis 分布式锁的正确实现方式2019-05-31 4550
全部0条评论

快来发表一下你的评论吧 !
