

机器学习找一个好用的函数的原因是什么
电子说
描述
1、机器学习定义
我们一起看看AI界的大牛对机器学习的定义
(1)机器学习中经典的“支持向量机(SVM)”的主要提出者弗拉基米尔·万普尼克(Vladimir Vapnik),在其著作《统计学习理论的本质》中这样定义机器学习“机器学习就是一个基于经验数据的函数估计问题”。
(2)卡耐基梅隆大学的机器学习和人工智能领域知名教授汤姆·米切尔(Tom Mitchell),在他经典教材《机器学习》中很抽象的定义了机器学习:对于某类任务(Task,简称T)和某项性能评价准则(Performance,简称P),如果一个计算机程序在T上以P作为性能度量,随着经验(Experience,简称E)的积累,不断自我完善,那么我们称这个计算机程序从经验E中进行了学习。比如学习围棋的程序AlphaGo,它可以通过和自己下棋获取经验,那么它的任务T就是“参与围棋对弈”,它的性能P就是用“赢得比赛的百分比”来度量的。米切尔教授认为,在机器学习中我们需要明确三个特征:任务的类型、衡量任务性能提升的标准以及获取经验的来源。
(3)南京大学的机器学习专家周志华在经典教材《机器学习》中这样定义:机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能,而在计算机系统中,“经验”通常以“数据”形式存在,因此机器学习研究的主要内容是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”。有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型,而在面对新的情况时,模型会给我们提供相应的判断。比如我们在买瓜的时候看到一个没剖开的西瓜,我们可以利用经验对这个瓜的好坏进行判断。
结合这些行业大牛的定义,我们可以这样理解机器学习,“从数据中学习,形成有效经验,提升执行任务/工作的表现”,而我们对于机器学习的研究就是一个不断找寻更有效算法的过程。对于计算机系统而言,所有的“经验”都是以数据的形式存在的,而数据作为学习的对象类型是多样的,可以是数字、文字、图像、音频、视频,也可以是它们的各种组合。经典机器学习中还要依赖人类的先验知识,把原始数据预处理成各种特征,然后对特征进行分类。而这种分类的效果,高度取决于特征选取的好坏,因此传统的机器学习专家们,把大部分时间都花在如何寻找更加合适的特征上。我们进入在“数据泛滥,信息超量”的大数据时代后,能自动从大数据中获取知识的机器学习一定会扮演重要角色。
2、机器学习的主要形式
机器学习的主要形式有监督学习、无监督学习、半监督学习及强化学习,我们再来回顾一下每一种形式的特点
(1)有监督学习:有监督学习使用有标签的训练数据,“监督”可以理解为已经知道训练样本(输入数据)中期待的输出信号(标签)。监督学习过程是,先为机器学习算法提供打过标签的训练数据以拟合预测模型,然后用该模型对未打过标签的新数据进行预测。以垃圾邮件过滤为例,可以采用监督机器学习算法在打过标签的(正确标识垃圾与非垃圾)电子邮件的语料库上训练模型,然后用该模型来预测新邮件是否属于垃圾邮件。当前火热的神经网络就属于有监督学习。
(2)无监督学习:无监督学习的使用未标记过的训练数据,“无监督”就不知道输入对应的输出结果了,无监督学习让算法自身发现数据的模型和规律。比如“聚类”,利用距离的亲疏远近来衡量不同类型。还有“异常检测”,判断某些点不合群。“异常检测”也是“聚类”的反向应用。
(3)半监督学习:则采用“中庸之道”,利用聚类技术扩大已知标签范围,也就是说,训练中使用的数据只有一小部分是标记过的,而大部分是没有标记的,然后逐渐扩大标记数据的范围。
(4)强化学习:强化学习也使用未标记的数据,它可以通过某种方法(奖惩函数)知道你是离正确答案越来越近,还是越来越远。强化学习的目标是开发一个系统,通过与环境的交互来提高其性能,我们也可以把强化学习看作一个与监督学习相关的领域,然而强化学习的反馈并非标定过的正确标签或数值,而是奖励函数对行动度量的结果。强化学习的常见示例是国际象棋,系统根据棋盘的状态或环境来决定一系列的行动,奖励定义为比赛的输或赢。
3、机器学习系统的路线图
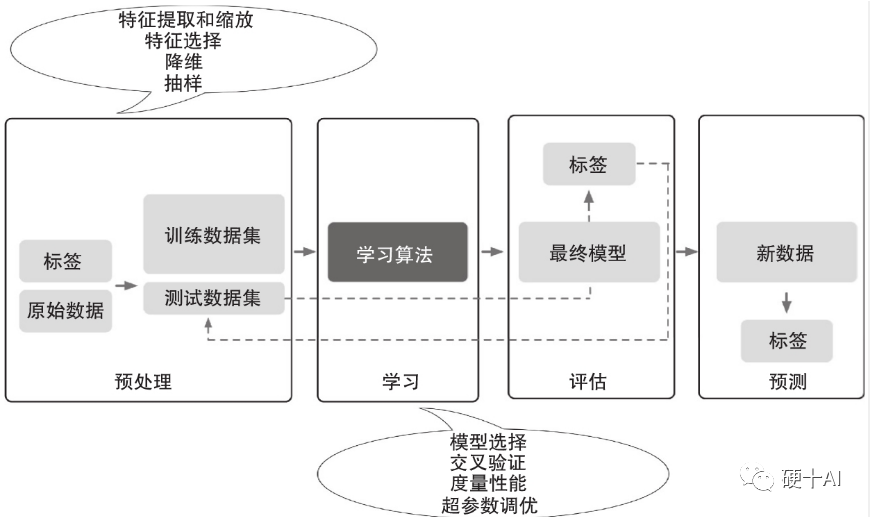
(1)预处理:我们能够获得的原始数据很少以理想形式出现,无法满足学习算法的最佳性能,因此数据的预处理是所有机器学习应用中最关键的步骤。为了获得模型的最佳性能,许多机器学习算法要求所选特征的测量结果单位相同,通常通过把特征数据变换到[0,1]的取值范围,或者均值为0、方差为1的标准正态分布来实现。由于某些选定的特征相互之间可能高度相关,因此在某种程度上呈现冗余的现象。在这种情况下,可以通过降维技术将特征压缩到低维子空间,减少存储空间,提高算法的运行速度。预处理中为了确定机器学习算法不仅在训练数据集上表现良好,而且对新数据也有很好的适应性,我们将数据集随机分成单独的训练数据集和测试数据集。用训练数据集来训练和优化机器学习模型,同时把测试数据集保留到最后以评估最终的模型。
(2)训练和选择预测模型:为了完成各种不同的任务,目前开发了许多不同的机器学习算法,但没有哪个分类算法是完美的。例如,每个分类算法都存在着固有的偏置,如果不对分类任务做任何假设,没有哪个分类模型会占上风。因此,在实际应用中我们至少要比较几种不同的算法,以便训练和选择性能最好的模型。在比较不同的模型之前,我们首先要确定度量性能的指标,通常用分类准确率作为度量指标,其定义为正确分类的个体占所有个体的百分比。我们不能期望软件库所提供的不同机器学习算法的默认参数值对特定问题最优,因此使用超参数调优技术来调优模型的性能就特别重要,我们可以这样理解超参数,这不是从数据中学习的参数,而是模型的调节旋钮,可以来回旋转调整模型的性能。
(3)评估模型并对未曾谋面的数据进行预测:在训练数据集上拟合并选择模型之后,我们可以用测试数据集来评估它在从来没见过的新数据上的表现,以评估泛化误差。如果我们对模型的表现满意,那么就可以用它来预测未来的新数据。
4、机器学习函数化
(1)机器学习就是找一个好用的函数
《未来简史》的作者赫拉利这样定义,人工智能实际上就是找到一种高效的“电子算法”,用以代替或在某项指标上超越人类的“生物算法”。那么,任何一个“电子算法”都要实现一定的功能(Function)才有意义,这种“功能”就是我们使用的“函数”。
台湾大学李宏毅博士的说法更通俗一些,机器学习在形式上可近似等同于在数据对象中通过统计或推理的方法,寻找一个有关特定输入和预期输出的功能函数f。
通常我们把输入变量空间记作X,也就是特征,变量既可以是标量(scalar),也可以是向量(vector),包括各种数据表或矩阵的列;而把输出变量空间记作Y,也就是目标。所谓的机器学习就是完成如下变换:Y=f (X)。
在这样的函数中,针对语音识别功能,如果输入一个音频信号,就能输出诸如“你好”或“How are you?”等这类识别信息;针对图片识别功能,如果输入的是一张图片,在这个函数的加工下,就能输出一个或猫或狗的判定;针对下棋博弈功能,如果输入的是一个围棋的棋谱局势,它能输出这盘围棋下
一步的“最佳”走法;而对于具备智能交互功能的系统(比如微软小冰),当我们给这个函数输入诸如“How are you?”,它就能输出诸如“I am fine,thank you,and you?”等智能的回应。
总结这一下,机器学习的过程和目标就是在寻找一个“好用的”函数。
(2)如何才能寻找到一个好用的函数
“好用的”函数并不那么好找,输入一只猫的图像后,这个f函数并不一定就能输出一只猫,可能它会错误地输出为一条狗或一条蛇,开发者想要找到好的函数必须要走好三大步
如何找一系列的函数来实现预期的功能,这是建模问题。
如何找出一系列评价标准来评估函数的好坏,这是评估问题。
如何快速找到性能最佳的函数,这是优化问题。
审核编辑:郭婷
-
单片机函数传参被改变的原因是什么?2021-10-19 1686
-
STM32接收中断服务函数打印函数会造成错误的原因是什么?2021-12-02 1369
-
机器学习中几种常见回归函数的概念学习2017-12-15 5062
-
机器学习经典损失函数比较2018-06-13 9542
-
机器学习的logistic函数和softmax函数总结2018-12-30 11020
-
开发成功的机器学习应用程序需要一定的“民间技巧”2019-05-16 3038
-
机器学习项目难管理的原因是什么2020-04-19 2164
-
对象存储适合AI和机器学习工作负载的三个原因2020-07-06 3502
-
机器视觉的下一个阶段可能就是机器学习2020-10-12 2946
-
机器学习中若干典型的目标函数构造方法2020-12-26 5381
-
当前芯片短缺的原因是什么2021-12-21 5551
-
芯片短缺原因是什么2021-12-23 3718
-
在Python中实现更简单好用的函数运算缓存2022-08-05 1735
-
推荐一个Python超级好用的内置函数lambda2022-09-13 1668
-
AI是干什么的?机器学习的基础流程和理论基础2023-02-01 1427
全部0条评论

快来发表一下你的评论吧 !
