

现代化的数据管理平台的性能
描述
今年9月8日,爱数AnyBackup神盾会(七)上首次剧透了AnyBackup Family 8,并正式亮相了AnyBackup Family 8的核心技术架构——备份数据湖。
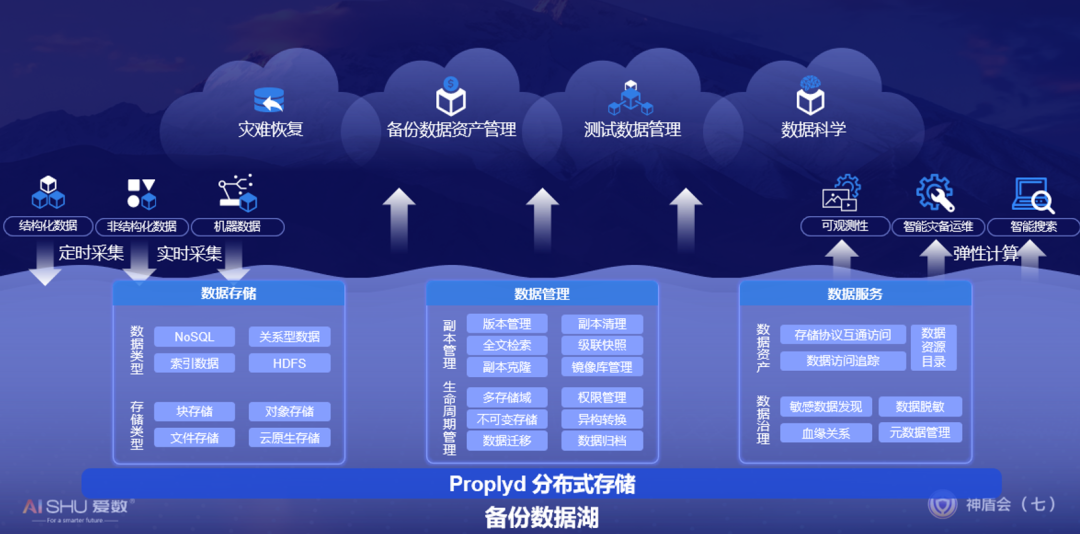
备份数据湖的概念不难理解,类似国外提到的第二存储理念,即把备份系统和数据湖系统合二为一。备份数据湖提供数据存储、数据管理和数据服务三大能力,除了支撑传统的灾难恢复、备份数据资产管理类应用外,还支持测试数据管理和数据科学类应用,有效降低企业在数据管理方面的TCO,提高企业数据的利用率,充分挖掘企业数据的价值。
但是,AnyBackup Family 8如此庞大和复杂的系统,功能已经完全超越了传统备份,对性能的要求也必须与时俱进,否则上面的理念都变为空谈。比如你从上面拉起一个数据库副本进行开发测试,性能比生产系统慢非常多,会大大影响企业的开发速度,造成人力的极大浪费,这样的备份数据湖也就没有什么实用价值。
爱数也了解大家的困惑,因此在10月27日下午,举办了以“性能爆表”为主题的神盾会(八),延续上一次神盾会,继续对神秘的AnyBackup Family 8进行剧透,展示AnyBackup Family 8领先技术的性能表现。
整体的会议内容很充实,从现代化数据管理平台“性能观”的思想碰撞,到火力全开、性能爆表的炸裂表现,再到超能打领先技术分享,非常值得一看。
西瓜哥作为多年存储从业人员,可谓阅存储无数,还是发现这个神盾会有很多技术干货,对专业的存储人士来说也非常有启发,因此,这次我就来解读一下其中的技术干货。
爱数的“性能观”
爱数认为,现代化的数据管理平台的性能是一个综合的指标,和相关的生产系统、传输网络都密切相关。
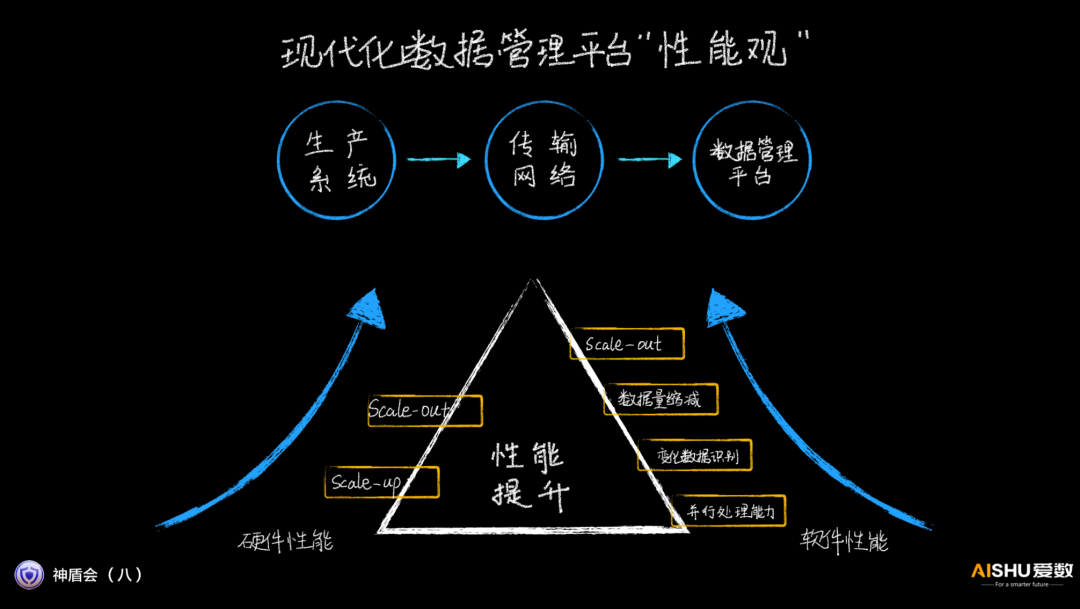
而性能的提升,也需要从硬件和软件两个方面努力。这次的会议,主要聚焦在AnyBackup Family 8在软件scale-out能力提升方面。
总体思路:和应用集成设计
首先,爱数认为,备份软件+分布式存储≠分布式备份系统。
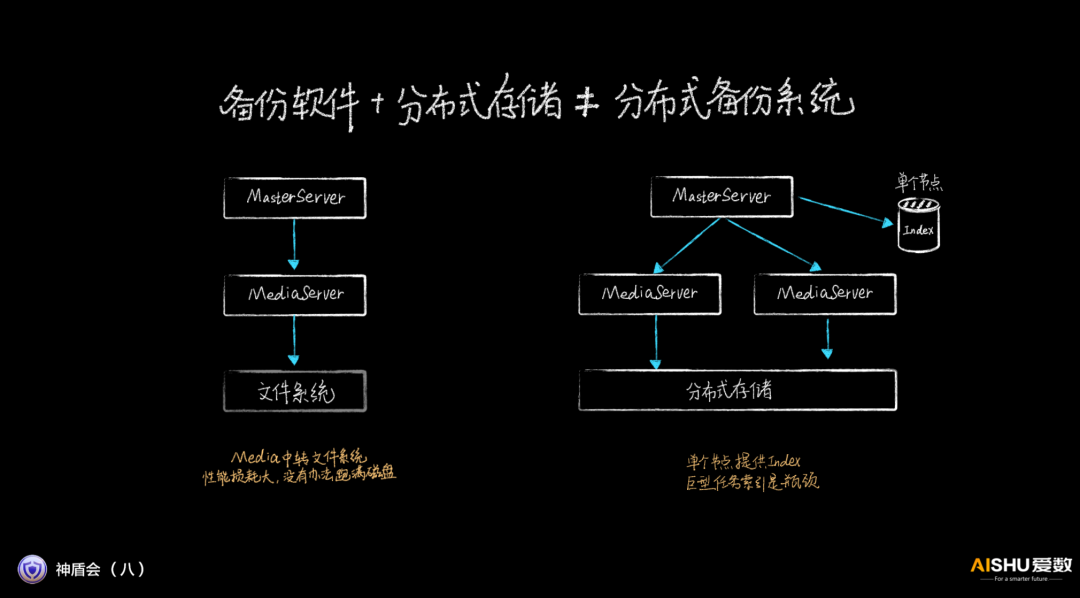
这个其实不难理解,因为备份系统本身没有分布式化,很多部件都不是分布式设计的。比如Media不能跨节点,单个节点依然是性能瓶颈;Media中转文件系统,性能损耗大,无法跑满磁盘带宽;单个节点提供Index,巨型应用索引是瓶颈。
因此,AnyBackup Family 8把备份系统和分布式存储集成在一起设计,是一种集成系统的思路。AnyBackup Family 8通过三副本的存储池、NVMe分布式缓存、兼具快照系统和各类数据结构化服务的数据引擎服务、高性能客户端和协议网关,构建的分布式存储架构,全力打造超高性能,即使在海量数据场景下,依然表现优异。
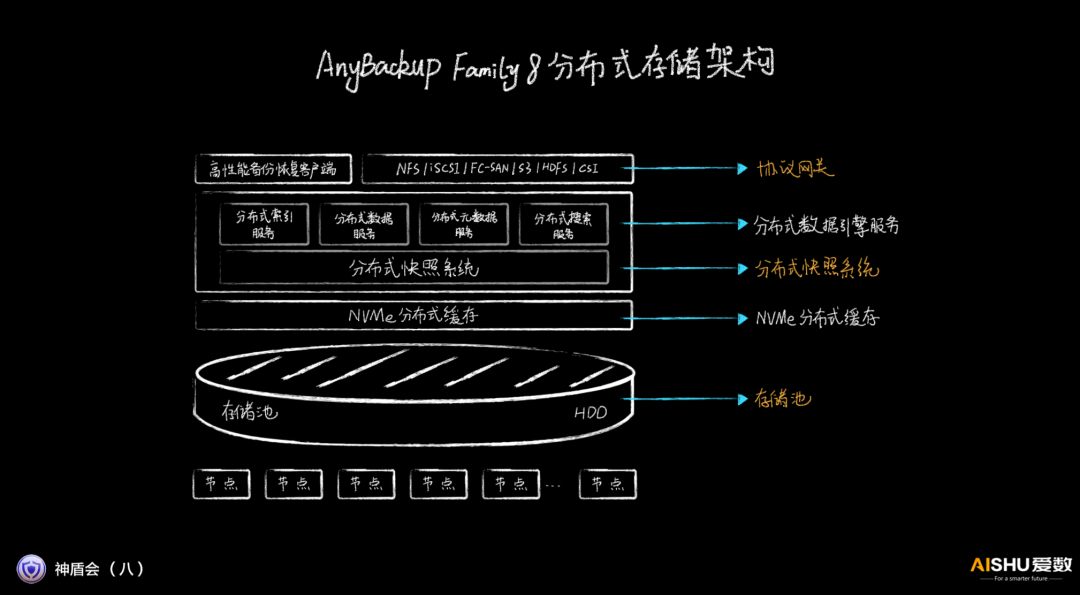
和业界的通用存储不同,AnyBackup Family 8特别清楚自己的定位,其优化思路和ORACLE数据库一体机类似,让存储在特定的应用场景下性能最优。
存储池采用三副本,而不是EC(纠删码)。这种做法类似Nutanix等很多超融合厂商,采用三副本,可以让应用直接感知副本的存储位置,能够大大提升数据的存取速度。
协议网关除了支撑通用的存储协议,还支持专用的备份恢复客户端。这种做法类似很多高性能文件系统,通过专用客户端来提升单客户端的性能。
在备份系统的分布式化上,爱数采用全分布式的设计思路。分布式索引服务、分布式数据服务、分布式元数据服务、分布式搜索服务,再加上底层分布式快照服务,可以提供无限快照能力,让所有可能成为性能瓶颈的部件全部都支持scale-out线性扩展,从架构上彻底解决性能问题。
下面我们来展开看看,AnyBackup Family 8的几个性能提升设计思路。
索引拆分和分布式化
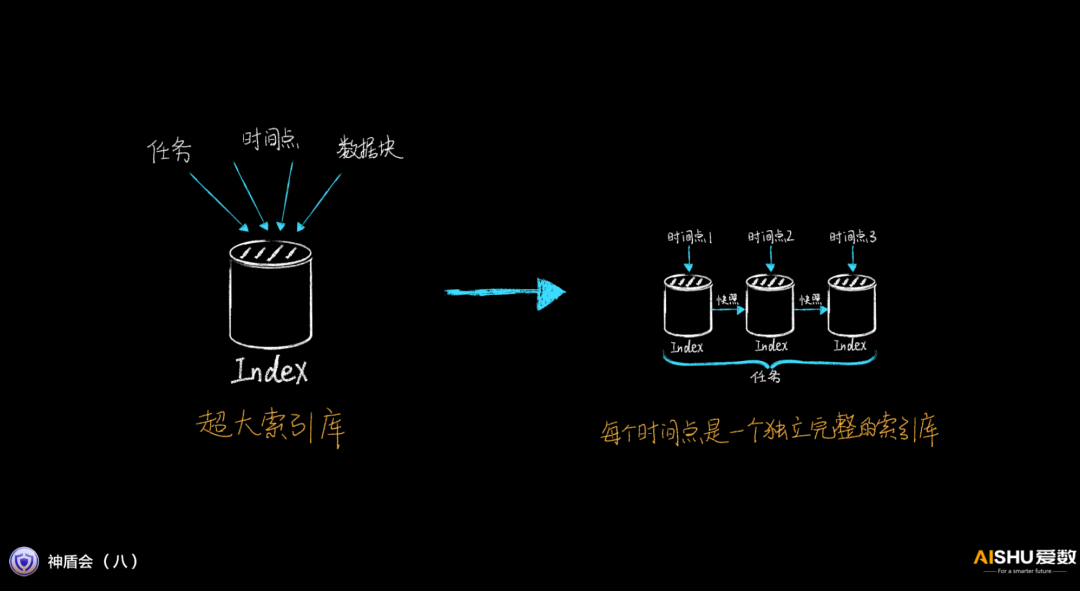
爱数第一件事就是在索引库引入快照机制,每次增量备份完成就做一个快照,全量备份就产生一个新的索引。这样做的好处就是每个时间点都有一个独立完整的索引库,每个索引库都不大,后期的数据管理动作,存取该索引库的速度就快得多。
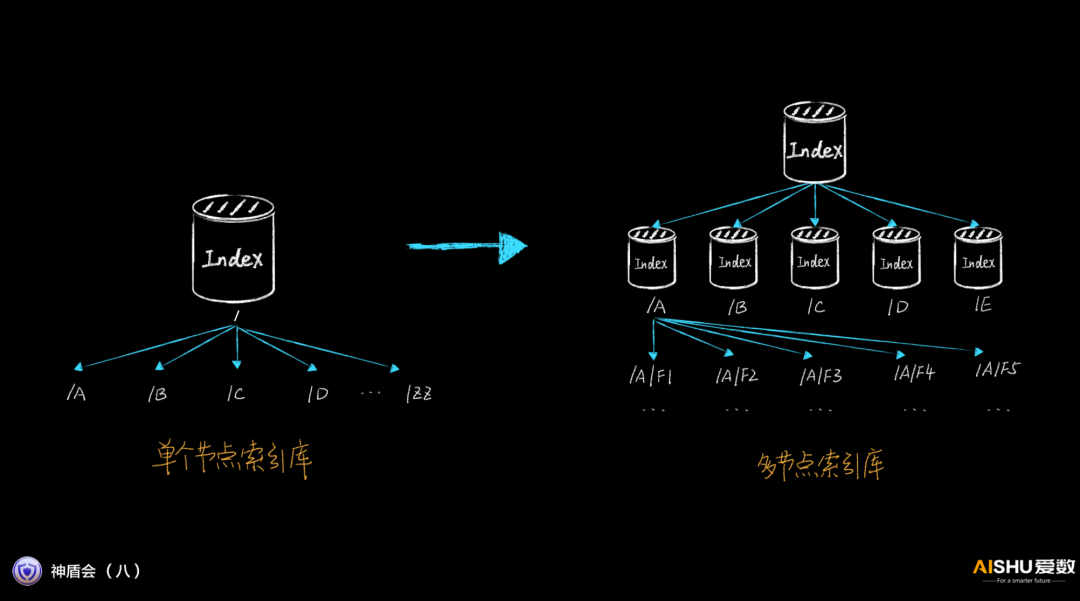
第二件事就是对单个节点索引库进行拆分,变成多节点索引库的架构,实现索引性能按需线性增长。拆分的策略有很多,按照应用数据源的不同,可以均衡负载,就近负载。
读写流程简化,减少网络传输
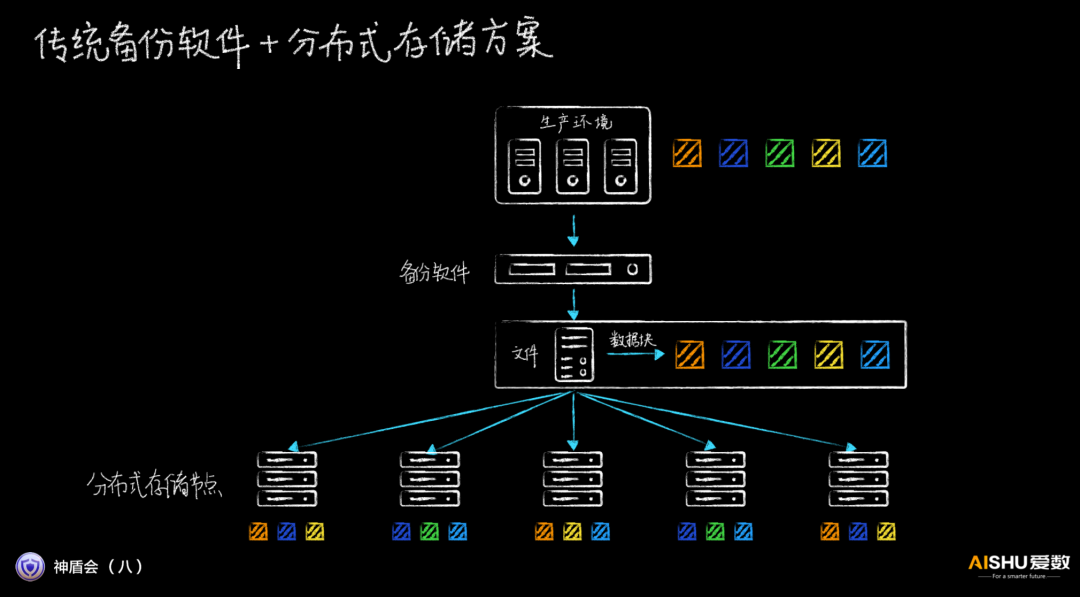
备份软件+分布式存储的松耦合设计,由于备份软件无法感知底层分布式存储的存放位置,因此,数据需要先送到备份系统,然后备份系统再送到底层分布式存储系统,分布式存储再找具体节点落盘,中转太多。
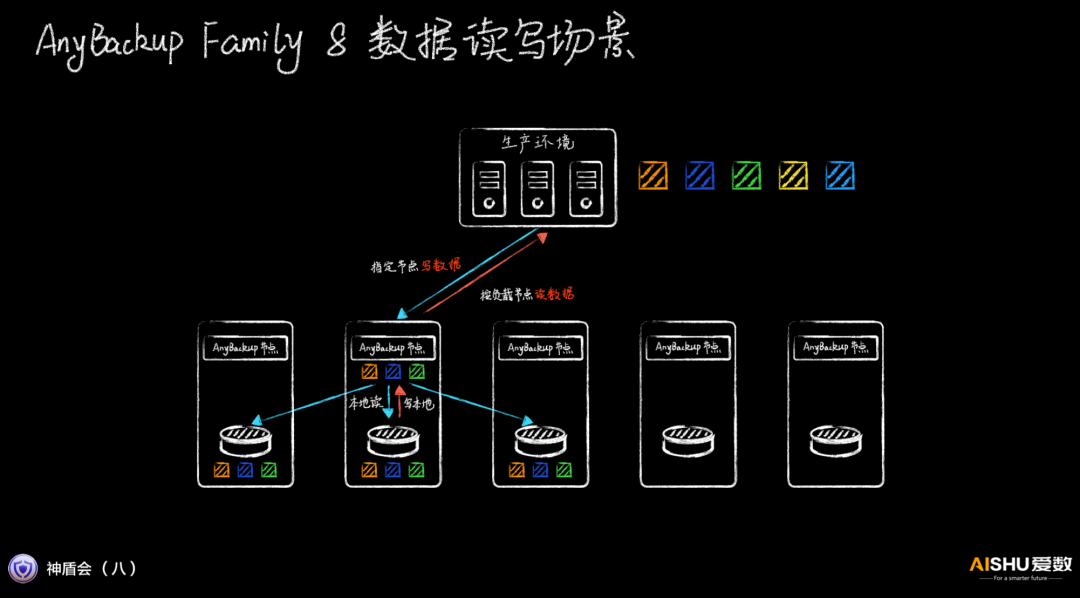
而AnyBackup Family 8则另辟蹊径,把AnyBackup节点和存储节点集成设计,备份客户端按照策略,直接把备份数据写入指定节点(比如负载最轻的),该节点再复制到其他两个节点。这样做的好处就是减少了一次网络转发,写性能会大大提高。由于恢复客户端也能感知到副本的位置,可以直接读取负载最轻的某个副本,恢复性能也会大大提高。
由于备份系统可以控制数据具体的存储位置,相关的数据可以尽量放在一起,减少跨节点的传输。不相关的数据则可以跨节点并发读写,整体的集群的性能要比备份软件+分布式存储的松耦合情况要高出很多。唯一的问题是集群的容量可能出现不均衡,可以通过自动重平衡闲时进行处理。

专用客户端,实现直通挂载
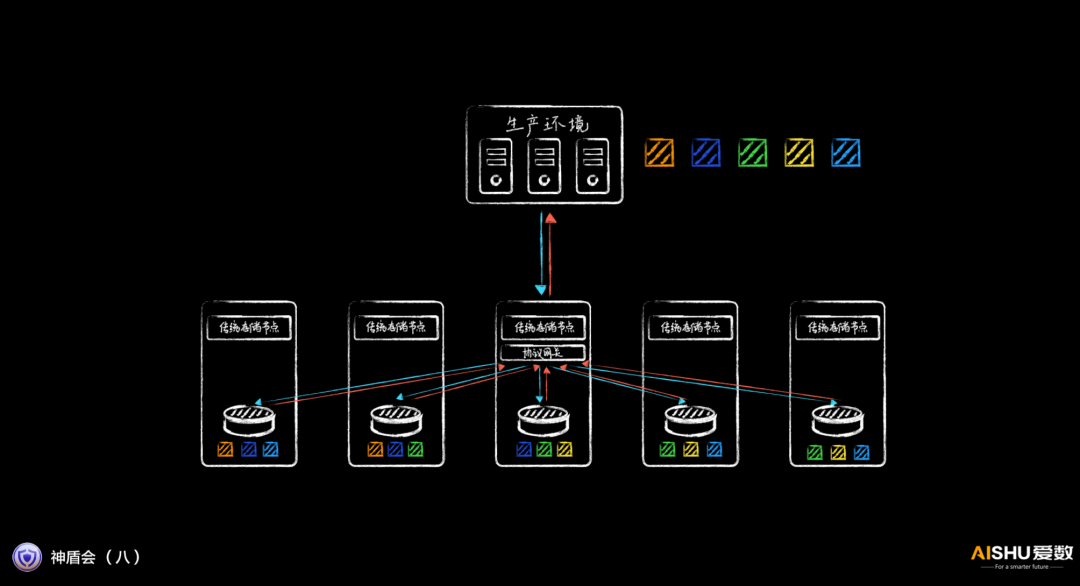
如果采用通用的存储协议,挂载一般需要通过特定协议网关,该网关再去其他节点取数据,性能较差。
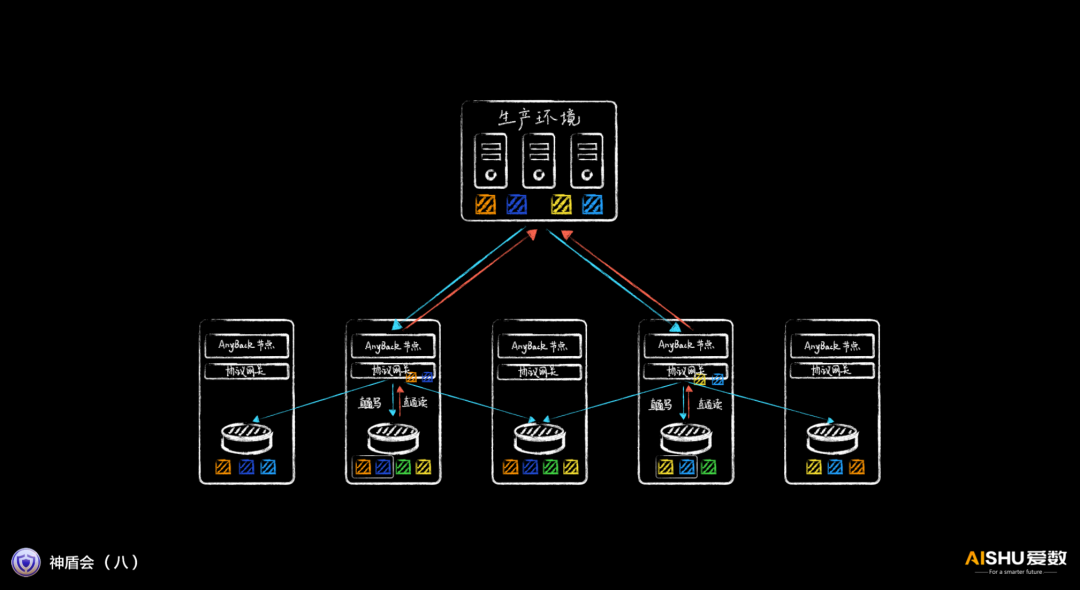
由于AnyBackup Family 8采用专门的备份恢复客户端,可以感知数据的存放位置,因此可以直接定位到数据所在节点的协议网关,实现直通挂载,时延更低,IOPS更高。
这种高速挂载的能力,让备份数据湖快速提供开发测试环境,快速提供分析应用所需的数据成为功能。
无合成永久增量备份
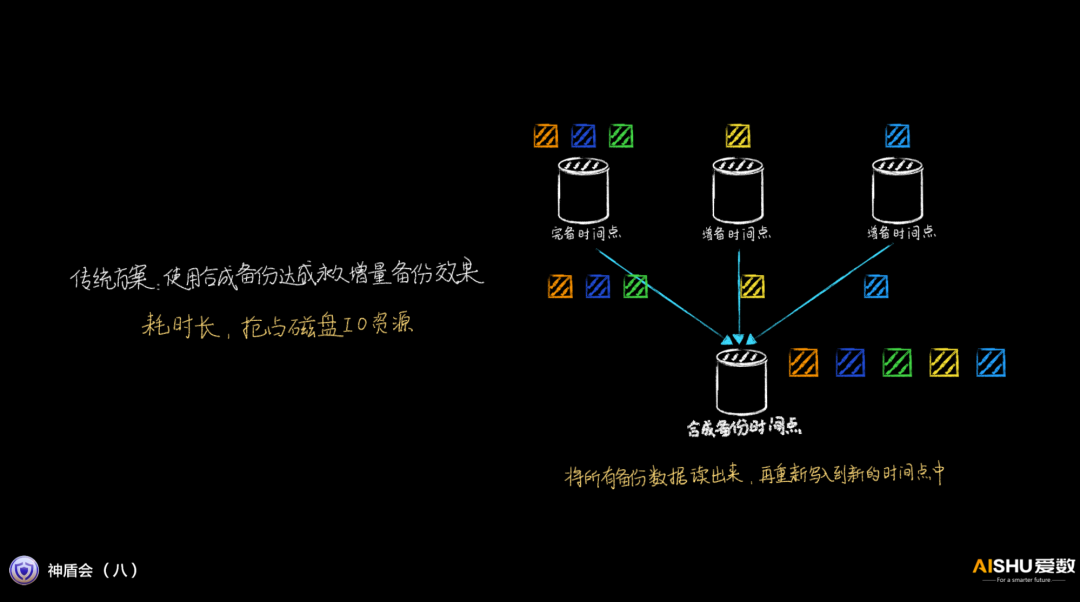
传统的增量备份,需要在后台进行数据的合成,对系统的性能影响很大。
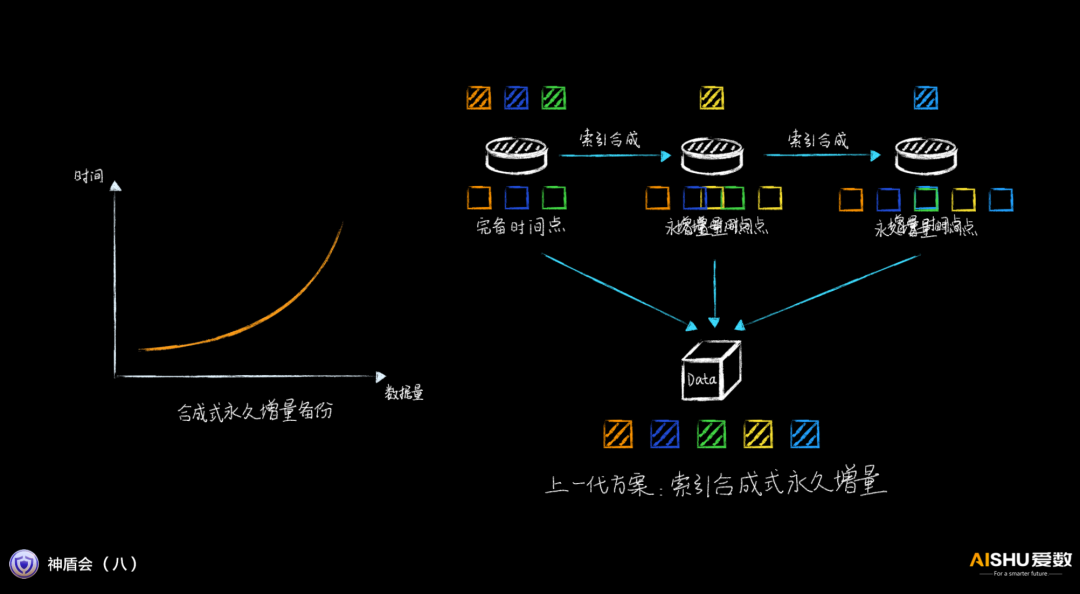
爱数的上一代产品,采用索引合并的方式,性能有所提升,但当索引的数据量上升,耗时还是很长的。
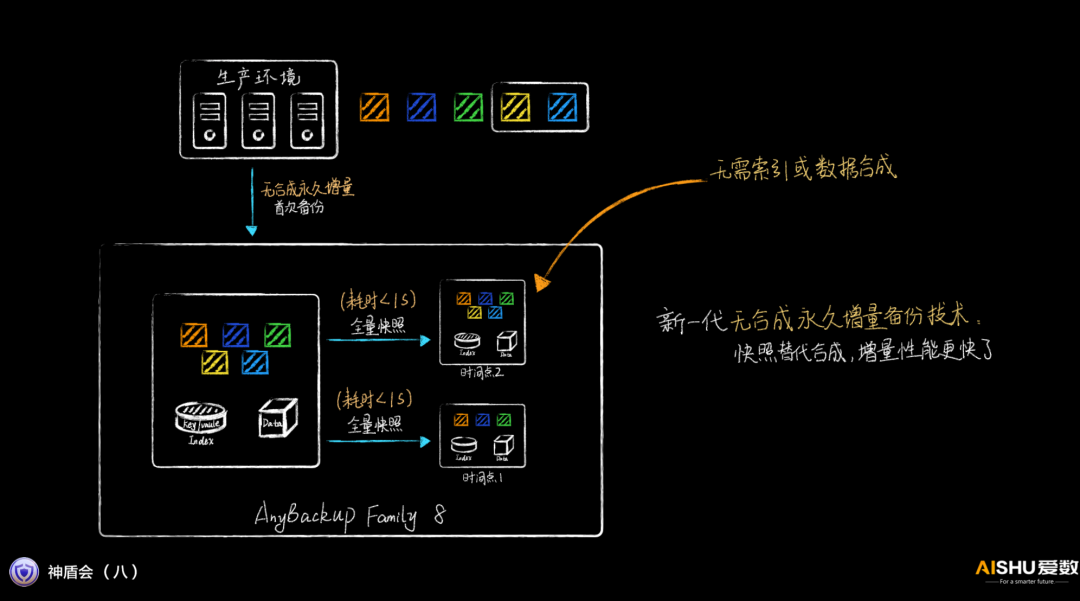
而在AnyBackup Family 8里,爱数取消了后台合成的过程,在增量备份的时候,实时修改索引,然后利用全量快照就可以生成黄金副本,无需后台合成过程,增量备份的性能得到巨大的提升。
无索引文件提高挂载速度
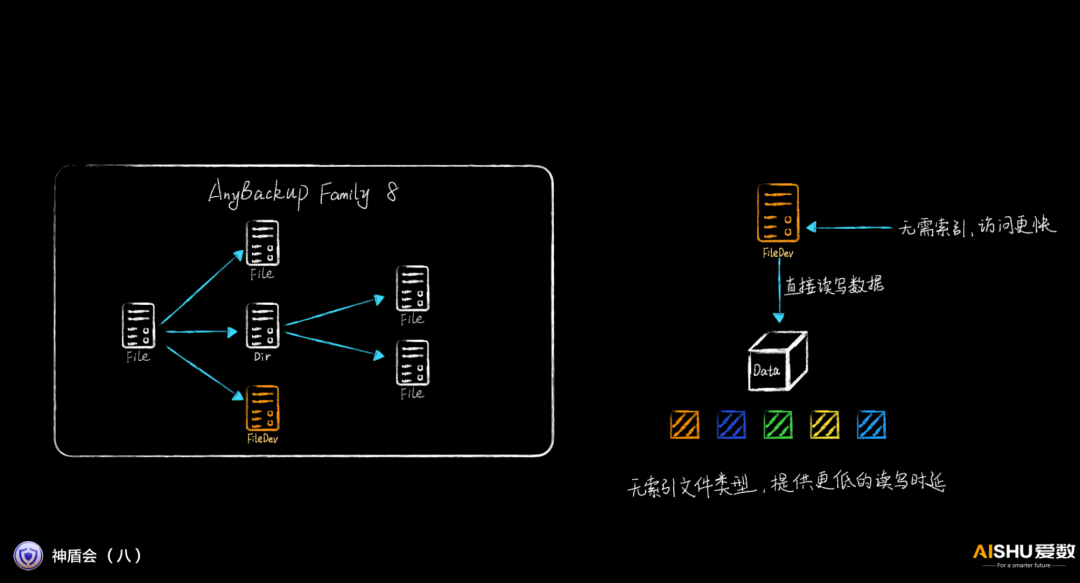
通用的文件系统,需要访问索引,然后才能访问到数据,因此其性能一般来说不如块设备。AnyBackup Family 8引入一种新的文件类型FileDev,没有索引,节省了查询索引的过程,直接访问数据,性能更好。
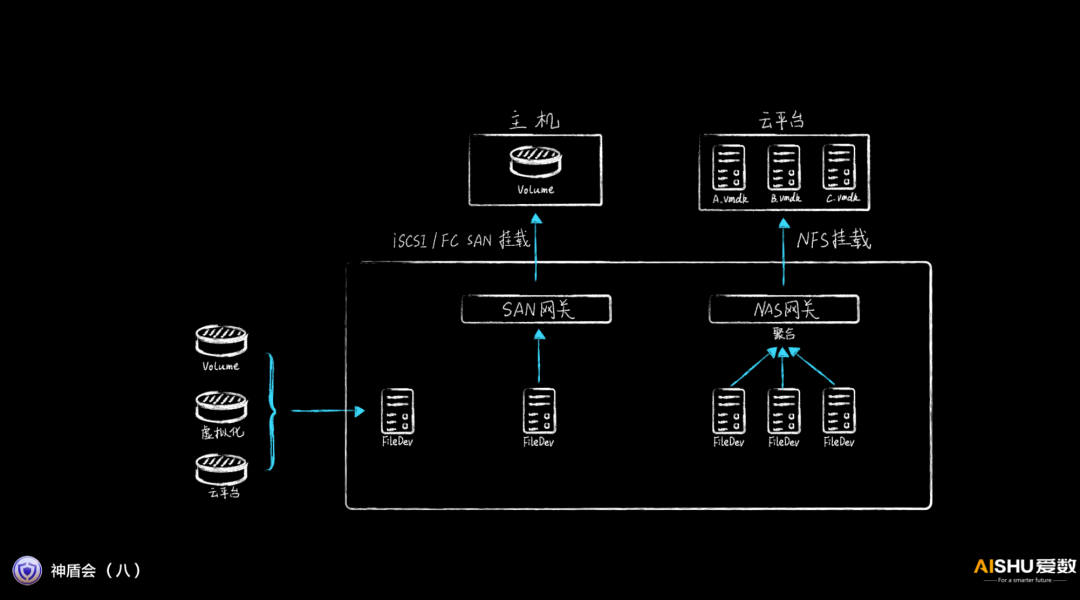
这些无索引文件FileDev,其实就是一种VMDK文件,它可以通过iSCSI挂载,也可以通过NFS进行聚合挂载,可以实现即时的数据服务。
性能爆表
正是上面的性能优化技术,将AnyBackup Family 8的3节点的备份恢复吞吐直接提升至5.1GB/s和9.21GB/s。
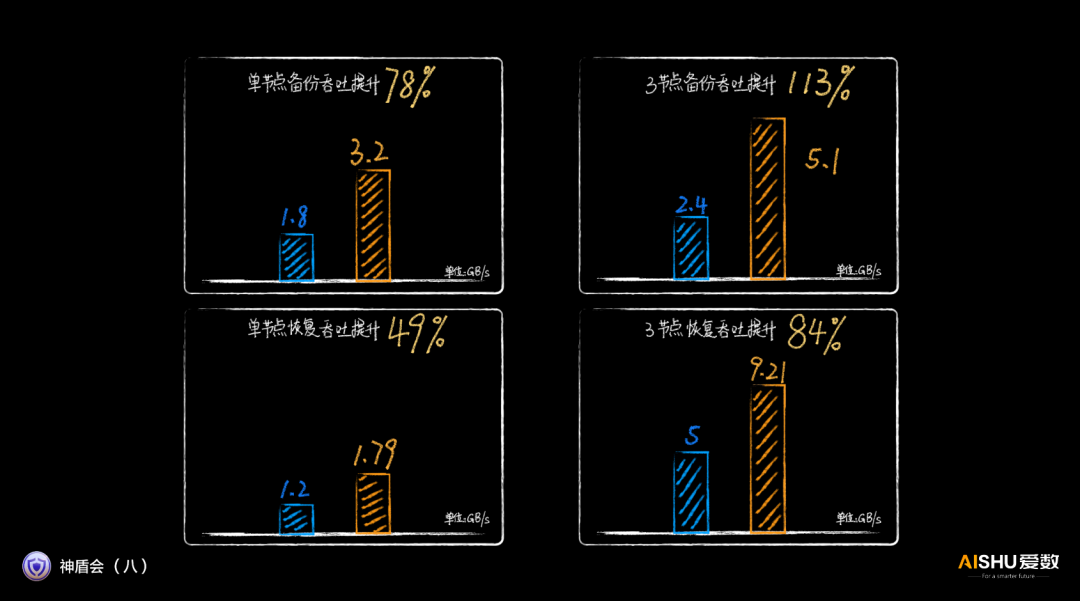
根据爱数发布的数据,相比上一代产品,AnyBackup Family 8在各方面的性能提升基本都在50%以上。
神盾会上,爱数还展示了AnyBackup Family 8在百亿级小文件保护、百TB级数据库分钟级挂载、海量虚拟机保护、PB级数据仓库高效备份、大规模测试数据管理等数据管理场景下的性能数据,显示其备份数据湖的卓越性能。
小结
从上面的分析,我们看到,爱数并没有把AnyBackup Family 8备份数据湖底层的分布式存储做成通用的存储,来和其他厂商的软件定义存储产品竞争。而是采用集成系统的思路,把数据管理应用和分布式存储进行紧耦合的设计,让整体数据管理平台的性能不仅能够进行快速的备份和恢复,也能进行高速的挂载,提供接近生产系统的高性能的数据服务,真正发挥备份数据湖的价值。
爱数的很多的性能优化思路,在业界都是独创的,如无合成的永久增量备份等,值得其他做第二存储的公司借鉴。当然,需要了解更多的细节,还是建议大家回看爱数的神盾会(八)。
-
可视化数据管理平台有哪些常见的功能模块?#数据管理平台 #光点科技光点科技 2023-12-01
-
基于RFID的现代化奶牛场管理应用2019-07-17 2078
-
数据管理功能详解2020-11-03 2097
-
SLM仿真过程与数据管理平台介绍2021-01-07 1548
-
怎么强化现代化IC的设计环境?2021-04-09 1529
-
HarmonyOS数据管理与应用数据持久化(一)2023-11-01 366
-
ONTAP_9_数据管理软件_简化向现代化数据中心的过渡2016-12-28 747
-
数据管理驾驶舱(工业数据可视化平台)是什么?有什么功能?2023-07-20 2832
-
喜报丨软通动力应用现代化平台工程产品及服务解决方案荣获“2023年应用现代化典型案例”称号2023-11-13 1872
-
软通动力应用现代化平台工程产品及服务解决方案荣获“2023年应用现代化典型案例”称号2023-11-14 1492
-
智慧农业平台:推动农业现代化的科技力量2024-10-15 1260
-
智慧营区综合管理平台:现代化进程中的重要产物2024-11-22 1100
-
龙智直播预告:揭示现代化数据管理与版本控制优势、从SVN迁移到Helix Core的实践指导、迁移步骤等2024-12-16 940
-
可视化组态数据管理平台是什么2025-04-21 1027
-
微型气象站系统:为智慧气象建设和应急管理体系现代化提供关键技术支撑2025-08-13 963
全部0条评论

快来发表一下你的评论吧 !
