

OpenMMLab 各算法库的评测指标集成
电子说
描述
在前段时间 2022 世界人工智能大会(WAIC)上, OpenMMLab 基于新一代训练架构 MMEngine ,发布了全新的 OpenMMLab 2.0 视觉算法体系,详细见上一期内容。
MMEngine 提供了强大灵活的训练引擎,以及常见的训练技术,以满足用户多样的模型训练需求。对于模型评测的需求,MMEngine 也提供了评测指标(Metric)和评测器(Evaluator)模块,下游算法库基于 MMEngine 提供的评测指标基类,实现对应任务所需的评测指标。
OpenMMLab 是深度学习时代最完整的计算机视觉开源算法体系,目前已涵盖 30+ 研究领域,这些研究领域都有各自任务的评测指标。我们希望能够将这些评测指标统一起来,以更加易用和开放的方式服务于更多用户。因此,我们在 MMEngine 中的评测指标模块基础上,将原 OpenMMLab 各算法库的评测指标集成进来,开发了一个统一开放的跨框架算法评测库:MMEval。
GitHub 主页:
https://github.com/open-mmlab/mmeval
(文末点击阅读原文可直达)
欢迎大家来 star~
中文文档:
https://mmeval.readthedocs.io/zh_CN/latest
MMEval 简介
MMEval 是一个跨框架的机器学习算法评测库,提供高效准确的分布式评测以及多种机器学习框架后端支持,具有以下特点:
提供丰富的计算机视觉各细分方向评测指标(自然语言处理方向的评测指标正在支持中)
支持多种分布式通信库,实现高效准确的分布式评测
支持多种机器学习框架,根据输入自动分发对应实现
MMEval 的架构如下图所示:
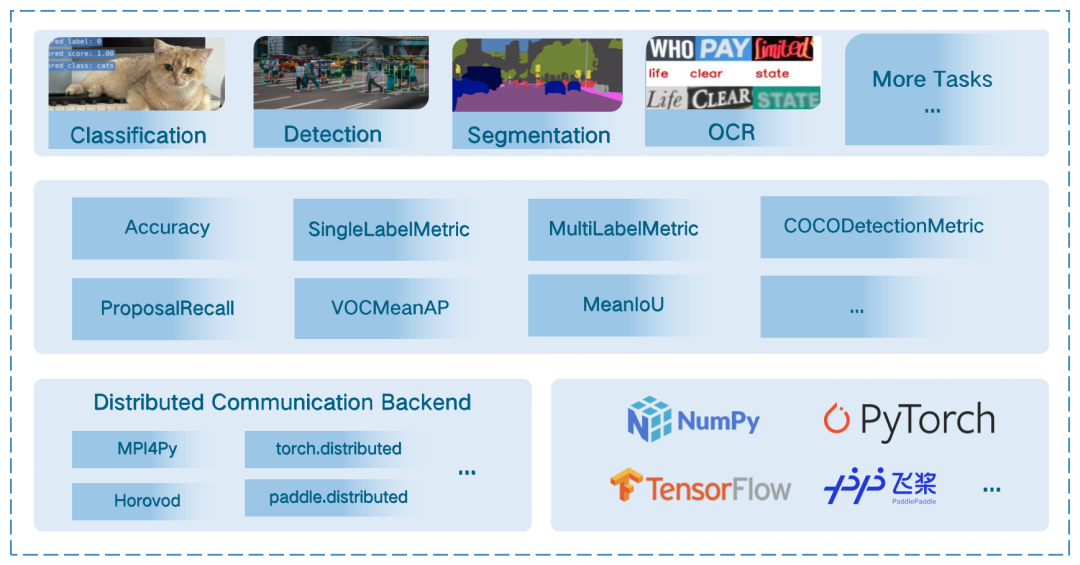
和已有一些开源的算法评测库相比,比如 Lightning-AI/metrics,huggingface/evaluate,以及近日开源的 pytorch/torcheval,MMEval 的区别主要在于对计算机视觉领域评测指标的更全面支持,以及提供跨框架评测的能力。
MMEval 目前提供了 20+ 评测指标,涵盖了分类,目标检测,图像分割,点云分割,关键点检测和光流估计等任务,MMEval 已支持的评测指标可以在文档中的支持矩阵中查看:https://mmeval.readthedocs.io/zh_CN/latest/get_started/support_matrix.html
MMEval 安装与使用
MMEval 依赖 Python 3.6+,可以通过 pip 来安装 MMEval:pip install mmeval
MMEval 中的评测指标提供两种使用方式,以 Accuracy 为例:
from mmeval import Accuracy
import numpy as np
accuracy = Accuracy()
# 第一种是直接调用实例化的 Accuracy 对象,计算评测指标。
labels = np.asarray([0, 1, 2, 3])
preds = np.asarray([0, 2, 1, 3])
accuracy(preds, labels)
# {'top1': 0.5}
# 第二种是累积多个批次的数据后,计算评测指标。
for i in range(10):
labels = np.random.randint(0, 4, size=(100, ))
predicts = np.random.randint(0, 4, size=(100, ))
# 调用 `add` 方法,保存指标计算中间结果。
accuracy.add(predicts, labels)
# 调用 compute 方法计算评测指标
accuracy.compute()
# {'top1': ...}
# 调用 reset 方法,清除保存的中间结果。
accuracy.reset()
MMEval 中的评测指标还支持分布式评测功能,关于分布式评测的使用方式可以参考教程:https://mmeval.readthedocs.io/zh_CN/latest/tutorials/dist_evaluation.html
多分布式通信后端支持
在评测过程中,通常会以数据并行的形式,在每张卡上推理部分数据集的结果,以加快评测速度。而在每个数据子集上计算得到的评测结果,通常不能通过简单的求平均来与整个数据集的评测结果进行等价。因此,通常的做法是在分布式评测过程中,将每张卡得到的推理结果或者指标计算中间结果保存下来,在所有进程中进行 all-gather 操作,最后再计算整个评测数据集的指标结果。
MMEval 在分布式评测过程中所需的分布式通信需求,主要有以下两个:
将各个进程中保存的评测指标计算中间结果 all-gather
将 rank 0 进程计算得到的指标结果 broadcast 给所有进程
为了能够灵活的支持多种分布式通信库,MMEval 将上述分布式通信需求抽象定义了一个分布式通信接口 BaseDistBackend,其接口设计如下图所示:

MMEval 中已经预置实现了一些分布式通信后端,如下表所示:
| MPI4Py | torch.distributed | Horovod | paddle.distributed |
| MPI4PyDist | TorchCPUDist & TorchCUDADist | TFHorovodDist | PaddleDist |
多机器学习框架支持
MMEval 希望能够支持多种机器学习框架,一个最为简单的方案是让所有评测指标的计算都支持 NumPy 即可。这样做可以实现大部分评测需求,因为所有机器学习框架的 Tensor 数据类型都可以转为 NumPy 的数组。
但是在某些情况下可能会存在一些问题:
NumPy 有一些常用算子尚未实现,如 topk,会影响评测指标的计算速度
大量的 Tensor 从 CUDA 设备搬运到 CPU 内存会比较耗时
如果希望评测指标的计算过程是可导的,那么就需要用各自机器学习框架的 Tensor 数据类型进行计算
为了应对上述问题,MMEval 的评测指标提供了一些特定机器学习框架的指标计算实现。同时,为了应对不同指标计算方式的分发问题,MMEval 采用了基于类型注释的动态多分派机制,可以根据输入的数据类型,动态的选择不同的计算方式。
一个基于类型注释的多分派简单示例如下:
from mmeval.core import dispatch
@dispatch
def compute(x: int, y: int):
print('this is int')
@dispatch
def compute(x: str, y: str):
print('this is str')
compute(1, 1)
# this is int
compute('1', '1')
# this is str
愿景
在机器学习模型实验和生产过程中,训练和评测是其中两个非常重要的阶段。
MMEngine 已经提供了一个灵活强大的训练架构,而 MMEval 则希望能够提供一个统一开放的模型评测库。其中,统一体现在不同领域不同任务的模型评测需求都能够满足,开放则体现为与机器学习框架解耦,以更加开放的方式为不同的机器学习框架生态提供评测功能。
目前 MMEval 仍处于早期阶段,有很多评测指标仍在添加当中,有一些架构设计可能不够成熟。在之后的一段时间里,MMEval 将主要围绕以下两个方向去持续迭代完善:
持续的补充添加评测指标,不断扩展到 NLP、语音、推荐系统等更多的任务领域
支持更多机器学习框架,并且探索多机器学习框架支持的新方式
-
新唐有提供BLDC软件算法库吗?2023-09-06 655
-
mini57系列运行带算法库的程序,编译没有错误但无法运行是为什么?2023-08-22 518
-
深度学习算法库框架学习2023-08-17 1915
-
mini57系列运行带算法库的程序,编译没有错误,但无法运行是为什么?2023-06-13 637
-
N32G032算法库使用指南2022-11-11 579
-
摩尔线程与OpenMMLab战略合作:推动算法框架与GPU协同发展,共筑AI开发者繁荣生态2022-11-09 1117
-
Crypto算法库使用技巧 —— 基于STM32 AES GCM应用提示2022-02-08 906
-
Crypto算法库使用技巧之基于STM32 AES GCM应用提示2021-09-24 4944
-
ADI音效算法库2018-10-17 2796
-
请问关于SigmaStudio的算法库资源主要有哪些?2018-08-06 5614
-
C6678算法库问题2018-06-21 3373
-
ADI算法库,“警告”解决方案2016-09-12 2128
-
lpc1700开发板_dsp算法库2016-01-13 940
全部0条评论

快来发表一下你的评论吧 !
