
资料下载


让人们在COVID时代移动和互动
Petc
分享资料个
描述
激励
今天的生活与 COVID-19 之前的生活大不相同。成人和儿童都被迫隔离,事实证明这不仅对身体有害,而且对精神和情感造成伤害。我们的目标是提供一种不仅安全,而且具有娱乐性和挑战性的娱乐方式。
MOTIVATE 是我们的创作,它提供了一个虚拟迷宫,用户在其中与其他用户和 AI 机器人竞争以完成迷宫而不被捕获。完成迷宫不仅需要身体能力,还需要空间和逻辑推理。
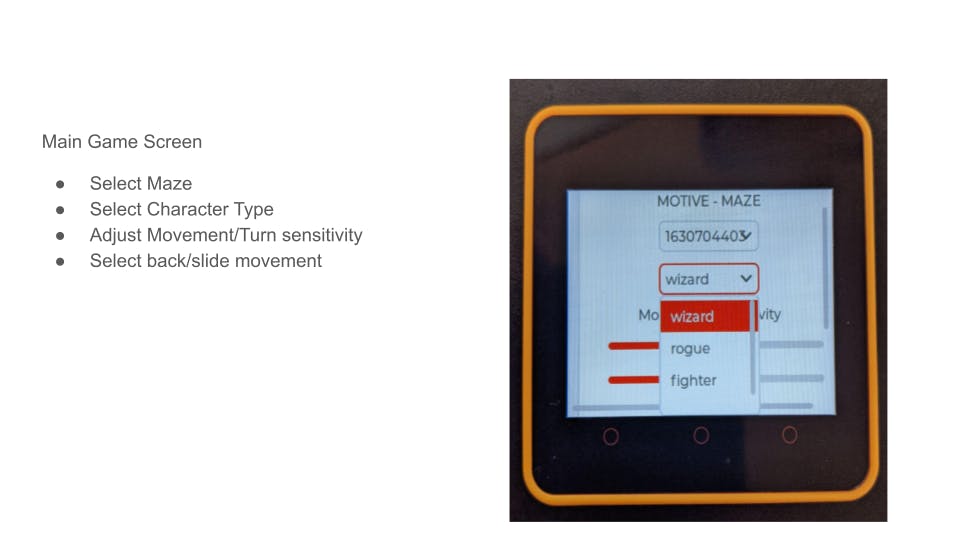
游戏设置
玩家首先选择他们的迷宫。他们可以选择一个活跃的游戏或请求一个新生成的迷宫。活跃游戏可以有其他活跃玩家或机器人,而新游戏是本地游戏而不是多人游戏。然后玩家继续选择他们的角色类别。职业是:巫师、盗贼和战士。奇才将盗贼送回开始,盗贼将战士送回开始,战士将奇才送回(roshambo风格)。玩家还可以通过选择游戏选项卡并使用灵敏度滑块随时设置移动和转动灵敏度以及“后退”和“左/右滑动”动作。一旦用户做出他/她的选择,他们通过滑动并选择游戏选项卡来继续游戏。
游戏玩法
游戏是实时进行的,玩家使用动作来导航迷宫。玩家的目标是在最短的时间内走到迷宫的尽头。不过也有障碍。玩家必须找出最短路径,同时在可能属于竞争角色类别的其他玩家周围导航。捷径确实存在。如果使用正确的动作,迷宫将包含“高”和“低”的墙壁,用户可以通过这些墙壁。高墙是绿色的,可以“蹲”过,低墙是黄色的,可以“跳”过。
游戏运动
玩家可以使用以下动作在迷宫中导航:
- 向前——向前走。将玩家向前移动 1 步
- 左/右转 - 向左或向右旋转。向左或向右改变玩家方向 90 度。
- *向后 - 向后走。将玩家向后移动 1 步
- *左/右滑动 - 向左或向右侧步。将玩家向左或向右移动 1 步。
*可选,可以在游戏选项卡上切换。
迷宫标签
迷宫选项卡是玩游戏的主要选项卡。玩家有两张地图;以玩家为中心并以玩家为中心的主要相对地图以及具有静态方向并显示整个地图以及所有玩家和位置的较小绝对地图。选项卡的右下部分有信息窗格。在这个窗格中,玩家可以看到他们的步数、活动动作分类、对手的名字、经过的时间以及稳定性和动作 LED。稳定性 LED 指示设备被保持在正确的位置。如果设备未保持在正确位置,此 LED 将闪烁。运动 LED 指示分类器正在运行并处理来自 IMU 的信号。
训练选项卡
训练选项卡用于收集用于构建激励 CNN 模型的训练样本。用户可以使用右侧控制按钮选择他们的类操作,并使用中间控制按钮打开/关闭收集。将以 30Hz 的频率收集样本。并通过 AWS IoT (MQTT) 提供给激励后端。
建造
激励具有三个主要组成部分;激励模型、后端和应用程序。该模型是一个基本的 CNN 分类器,在 Core2 上本地运行,并提供 IMU 测量的实时分类以确定玩家运动。后端用于生成和分发迷宫、收集训练数据和多人游戏管理。应用程序是在 Core2 上本地编译和运行的一组代码和包。
模型
训练中使用的模型数据是;20 个标准化 IMU 读数样本 @ 30 Hz。(约 2/3 秒的训练样本)。标准化通过以下方式完成:
(Sa-Samin)/(Samax-Samin) * 255和(Sg-Sgmin)/(Sgmax-Sgmin) * 255
在哪里:
- Sa - 加速度计 XYZ 样本
- Sg - 陀螺仪 XYZ 样本
- Samin/max - 加速度计最小值/最大值(通过检查发现)
- Sgmin/max - 陀螺仪最小/最大值(通过检查发现)
模型数据标注如下:
- 0 - 休息
- 1 - 前锋
- 2 - 向后
- 3 - 左转
- 4 - 右转
- 5 - 向上(跳跃)
- 6 - 向下(蹲下)
- 7 - 左侧台阶
- 8 - 右侧踏步
该模型是一个简单的卷积神经网络,具有以下架构:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 20, 6, 16) 208
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 6, 2, 16) 0
_________________________________________________________________
dropout (Dropout) (None, 6, 2, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 6, 2, 16) 1040
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 2, 2, 16) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 2, 2, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 64) 0
_________________________________________________________________
dense (Dense) (None, 16) 1040
_________________________________________________________________
dropout_2 (Dropout) (None, 16) 0
_________________________________________________________________
dense_1 (Dense) (None, 9) 153
=================================================================
Total params: 2,441
Trainable params: 2,441
Non-trainable params: 0
培训结果
以下是每个标签的 F1 分数。达到了 A.95 F1 复合精度。
class precision recall f1-score support
0 1.00 0.95 0.98 44
1 0.90 0.94 0.92 95
2 0.93 0.91 0.92 109
3 1.00 1.00 1.00 52
4 1.00 1.00 1.00 41
5 1.00 1.00 1.00 38
6 0.99 1.00 0.99 71
7 0.88 0.91 0.89 54
8 0.95 0.91 0.93 45
accuracy 0.95 549
macro avg 0.96 0.96 0.96 549
weighted avg 0.95 0.95 0.95 549
将模型部署到设备
提供的 jupyter notbook 的最后一步是下载模型结果。在将模型导入您的应用程序时,请使用 `xxd` 工具将 tflite 模型文件转换为 ac 源文件并将结果复制到您的项目中。
xxd -i mot-imu-quant.tflite > mot-imu-model.cc
sed -i 's/mot_imu_quant_tflite/g_model/g' mot-imu-model.cc # change model name to match code
cp mot-imu-model.cc <to your project>
后端
后端由一些不同的 AWS 服务组成,如下所示:
- Maze Proxy - 为 Maze 服务提供 HTTP 前端。
- Maze API - 用于迷宫生成和传播的 HTTPS Restful 接口。
- Maze Generator - 用于检索和生成迷宫的 Lambda。
- MOT MQTT - MQTT 中间件,用于定义主题拓扑、生成 MOT 设备密钥和 MQTT 消息传播以进行游戏。
- 游戏管理器 - 运行 MOT 机器人和游戏管理器的 EC2 系统。
迷宫生成和游戏机器人/管理器的代码可以在mot-play存储库中找到。后端当前存在并且可用。如果您希望构建此项目而不提供后端,请联系一组密钥。
应用
该应用程序由 platformio 项目中的一组 c++ 和 c 代码组成。重新创建应用程序的步骤如下:
pio run -t menuconfig
# Update the following to be unique
MOT MQTT Config -> MOT Client ID
# Update the following with your WiFi Config
WiFi Configuration -> SSID
WiFi Configuration -> WiFi Password
- 为 AWS IoT 连接请求(或生成)MOT 证书并复制到:
.../motivate/maze-app/certs
- 构建并刷新您的设备
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




