

Nvidia的Ada Lovelace架构深度解读!
描述
Nvidia 的 RTX 4090 采用 Nvidia 的最新架构,以早期计算先驱Ada Lovelace的名字命名。与之前的架构 Ampere 相比,Ada Lovelace 享有制程节点优势,使用台积电为 GPU 定制的 4 纳米制程。Nvidia 还强调了光线追踪性能,以及旨在弥补启用光线追踪对性能造成的巨大影响的技术。但光线追踪性能并不是唯一重要的事情,因为有很多游戏根本不支持光线追踪。此外,大多数使用光线追踪的游戏仅使用它来渲染某些效果;传统的光栅化仍然负责渲染大部分场景。
我还觉得对光线追踪的关注掩盖了 Nvidia 工程师为提高其他领域的性能所做的工作。在本文中,我们将使用一组正在进行的微基准测试来研究 Nvidia 的 Ada Lovelace 架构。我们将关注影响各种工作负载性能的领域,无论是否有光线追踪,特别强调缓存和内存子系统。
特别感谢Skyjuice在 RTX 4090 上运行测试。
GPU 概览
SM 或流式多处理器构成了 Nvidia GPU 的基本构建块。它们与 AMD 的 RDNA 和 RDNA 2 架构上的 WGP 或工作组处理器大致相当。SM 和 WGP 都具有 128 个 FP32 通道(或着色器,如果您愿意的话),并进一步分为四个块,每个块有 32 个通道。Ampere 最大的客户端芯片 GA102 已经非常庞大。
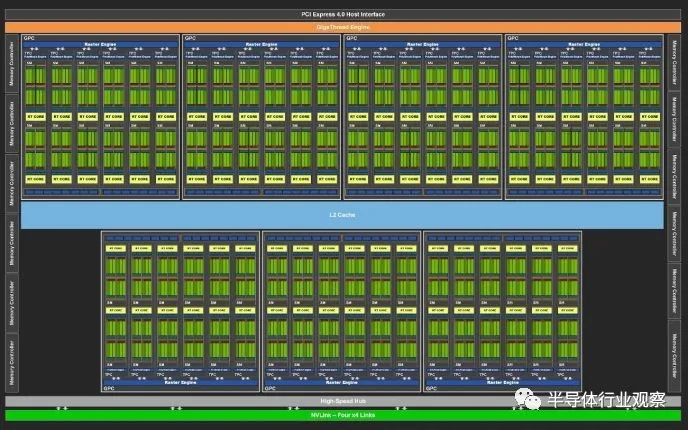
GA102 框图,来自 Nvidia 的白皮书 Ada Lovelace 表面上与 Ampere 相似,每个 SM 具有相似的计算特性。然而,它已经通过roof扩大了规模。AD102 有 144 个 SM,而 GA102 有 84 个,代表 SM 数量增加了 71%。RTX 4090 仅启用了 128 个 SM,但这仍然代表了 52% 的增长。将其与较大的时钟速度提升相结合,我们正在研究计算能力的巨大飞跃。
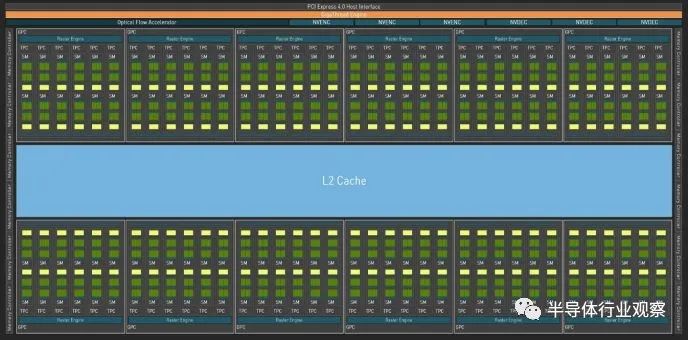
AD102 框图,来自 Nvidia 的白皮书 但扩大 GPU 的规模不仅仅是复制和粘贴工作。GPU 往往需要来自内存子系统的大量带宽,所有这些额外的 SM 都必须以某种方式提供。让我们转向我们正在进行的微基准测试,看看 Ada Lovelace 的内存层次结构。
缓存和内存延迟
我们正在启动缓存和内存延迟基准测试,因为这将使我们对缓存设置有一个很好的了解。 与 Ampere 一样,Ada Lovelace 坚持使用经过验证的真正的两级缓存方案。Nvidia 最近的两种架构都为每个 SM 提供了一个大型 L1 缓存,但 Ada Lovelace 大大扩展了 L2 缓存。Ampere 具有传统大小的 6 MB L2,但 AD102 包含 96 MB L2。RTX 4090 启用了 72 MB 的二级缓存。从 Ampere 到 Ada Lovelace,Nvidia 没有享受到显着的 VRAM 带宽增加,因此 Ada 的 L2 获得了巨大的容量提升,以防止随着计算容量的扩大而出现内存带宽瓶颈。 AMD 的 RDNA 2 架构选择了复杂的四级缓存系统,具有三级共享缓存。每个着色器阵列中有一个 128 KB 的 L1 来吸收来自相对较小 (16KB) 的 L0 缓存的缓存未命中流量。L2 的作用可与 Ampere 的 L2 相媲美,而大型 Infinity Cache 可帮助 AMD 通过更便宜(且功耗更低)的 VRAM 子系统实现高性能。
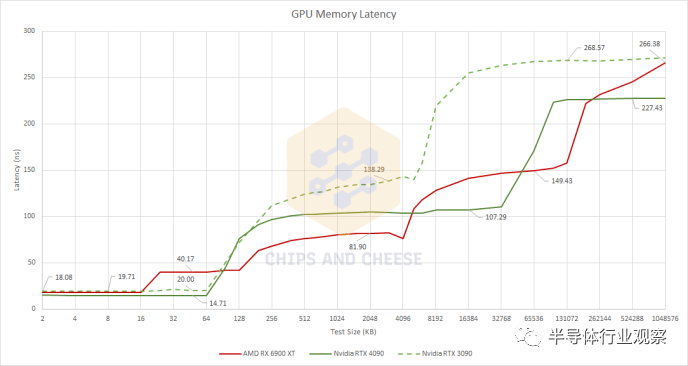
有趣的是,英特尔的 A770 的 L2 延迟与 RTX 4090 相似 Ada Lovelace 的缓存子系统具有令人印象深刻的延迟特性。第一级 SM 私有缓存看起来与 Ampere 的相似,但 Ada Lovelace 的更高时钟速度使其具有整体延迟优势。但 L2 是乐趣的开始。尽管容量比 Ampere 的 L2 增加了 12 倍,但 Nvidia 还是设法将延迟降低了大约 30 ns。Ampere 的 L2 在延迟方面接近 AMD 的 Infinity Cache,但 Ada Lovelace 的 L2 现在在容量和延迟方面位于 RDNA2 的 L2 和 Infinity Cache 之间。 与 Ampere 相比,RDNA 2 的缓存子系统看起来很有竞争力。这两个交易在小测试规模上受到打击,而 AMD 在 L2 规模及以上区域具有明显优势。Ada Lovelace 改变了这一点,随着测试规模从 AMD 的 L2 溢出,Nvidia 现在享有明显的优势。Ada Lovelace 的内存延迟也有所下降,尽管这在很大程度上可能是由于更好的 L2 性能,因为必须在通往内存的路上检查 L2。 随着 Ada Lovelace 改进 L2,AMD 发现自己处于一个不舒服的位置,Nvidia 使用单级缓存来填补 AMD 的 L2 和 Infinity Cache 的角色。更少的缓存级别意味着更低的复杂性,以及更少的潜在标签和每次内存访问的状态检查。当然,更多的缓存级别意味着在容量、延迟和带宽权衡方面具有更大的灵活性。RDNA 2 与 Ampere 相比无疑证明了这一点,它具有更快的 L2 缓存和更大的 Infinity Cache,几乎与 Ampere 的 L2 一样快。但艾达洛夫莱斯是一个不同的故事。
带宽
延迟是影响 GPU 性能的一个因素,但带宽也是一个因素,而且 GPU 往往比 CPU 更需要带宽。首先,我们将使用单个 OpenCL 工作组测试带宽。属于同一工作组的线程能够共享本地内存,这意味着它们将被限制在单个 WGP 或 SM 上运行。这是我们可以得到的最接近 GPU 单核带宽测试的结果。
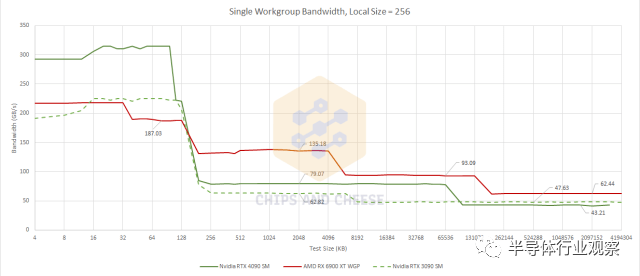
一旦我们进入 L2 及更高级别,RDNA 2 WGP 就比 Ampere SM 享有良好的带宽优势。Ada Lovelace 并没有改变这一点,但 L2 带宽确实比 Ampere 有所提高。再次,我们看到 Nvidia 的工程师在 L2 上做得非常出色。在 AMD 方面,我们开始看到 RDNA 2 非常擅长处理低占用工作负载的迹象。让我们增加工作组数量来测试扩展,看看这种优势能持续多久。
带宽扩展
共享缓存设计很难,尤其是在 GPU 中,因为缓存必须连接到大量客户端并满足它们的带宽需求。在这里,我们正在使用越来越多的工作组来测试带宽。和以前一样,每个工作组都必须使用单个 WGP 或 SM,因此我们看到共享缓存可以应对更多 WGP 和 SM 发挥作用并开始要求带宽的能力。 Ada Lovelace 是对 Ampere 的明显改进,并且在匹配的工作组数量下实现了更高的带宽。使用 RTX 4090 的所有 SM 时,我们看到了惊人的 5 TB/s 带宽——几乎是使用 RTX 3090 的 84 个 SM 时看到的两倍。Nvidia 成功地扩大了 L2 容量,同时也扩大了带宽以支持大量 SM,这是一项了不起的成就。Ada Lovelace 在低入住率的情况下超越 Ampere 的能力是锦上添花。
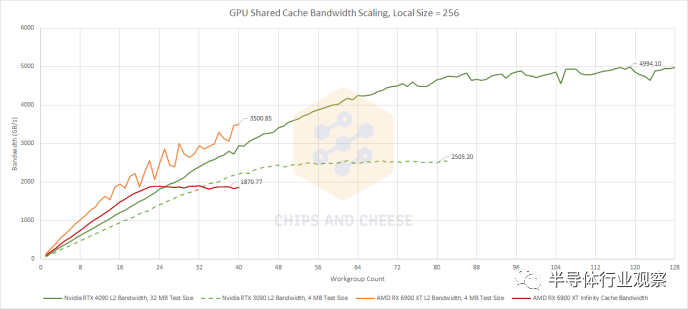
AMD 在小型工作负载方面仍然具有优势。RDNA 2 的 L2 在扩展方面尤其令人印象深刻,可以处理 40 个 WGP,要求最大带宽,而不会出现争用问题。大型 Infinity Cache 也表现不错,在low occupancy.的情况下击败了 Ampere 和 Ada Lovelace。但与我们在英特尔的 Arc A770 上看到的不同,英伟达也不甘落后。 更重要的是,Ada Lovelace 在低占用率下的性能提升意味着 RDNA 2 失去优势的速度比对抗 Ampere 的速度更快。由于有超过 24 个工作组在运行,Ada Lovelace 的 SM 可以从 L2 提取比 RDNA 2 的 WGP 从 Infinity Cache 获得的更多带宽。RDNA 2 的 L2 带宽优势一直持续到 Nvidia 拥有超过 50 个 SM。但是 RDNA 2 和 Ada Lovelace 之间的 L2 比较就不那么简单了,因为 L2 容量不再像 RDNA 2 和 Ampere 那样处于同一个范围内。在高入住率下,Ampere 比 RDNA 2 具有相当大的优势,但 Ada Lovelace 更进一步。RDNA 2 的 L2 和 Infinity Cache 与 Lovelace 的 L2 相比都处于明显劣势。 接下来,让我们看看当测试大小大到足以溢出缓存时会发生什么。
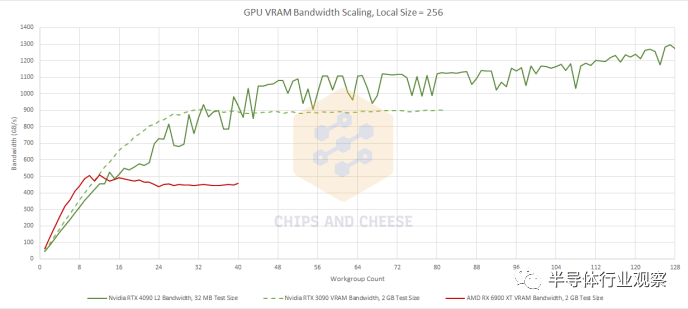
我们测量的 RTX 4090 在高占用率下的理论带宽高于理论带宽,这可能是因为一些重复读取被合并并广播到多个 SM。我有没有提到 GPU 测试很难? Ada Lovelace 的扩展速度不如 Ampere,但这种优势并不是特别重要,因为 Ada Lovelace 应该为 L2 之外的更多内存访问提供服务。VRAM 带宽也没有比 Ampere 显着增加,但两张 Nvidia 卡的绝对带宽仍然很大。从角度来看,它们的理论显存带宽几乎与 AMD 的 Radeon VII 一样多,后者具有基于 HBM2 的显存子系统。 AMD 的 RDNA 2 在低占用率下再次享有带宽优势,但 Nvidia 最近的架构为大型工作负载提供了更多的 VRAM 带宽。AMD 也更依赖于他们的 Infinity Cache,因为他们的 VRAM 带宽在加载十几个 WGP 后停止扩展。 最后,让我们测试 512 个工作组在高占用率下的带宽。这应该让每个 SM 或 WGP 有多个工作组可供使用,每个工作组中都有大量的并行性。
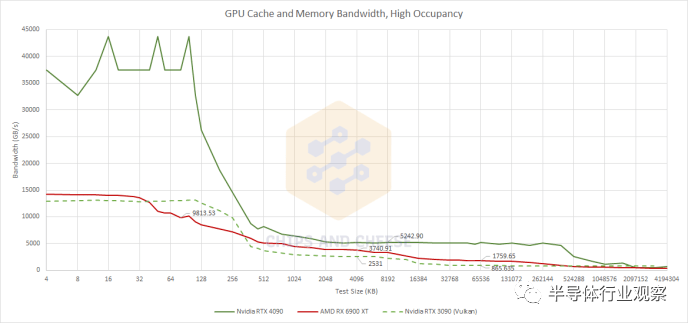
使用Nemes的基于 Vulkan 的带宽测试获得的 RTX 3090 结果。与此处的 OpenCL 结果不直接可比较,但无论如何都提供了上下文 由于 RTX 4090 的高时钟速度和疯狂的 SM 数量,Ada Lovelace 的 L1 带宽突破了roof并破坏了该图表上的比例。L2 缓存带宽也不是开玩笑的,它比 Ampere 的带宽有了很大的改进。即使 RDNA 2 可以为 L2 或 Infinity Cache 的内存访问提供服务,RDNA 2 也难以与之竞争。AMD 确实为他们完成了工作。
本地内存延迟
在 GPU 上,本地内存是一小块暂存器内存,由工作组中的所有线程共享,并且在工作组之外无法访问。软件必须明确地将数据加载到本地内存中,一旦工作组完成执行,本地内存内容就会消失。这使得本地内存更难使用,但作为交换,本地内存通常比普通的全局内存子系统提供更快和更一致的性能。本地内存的一种用途是在光线追踪时存储 BVH 遍历堆栈。 Nvidia 将本地内存称为“共享内存”,而 AMD 将其称为“本地数据共享”或 LDS。
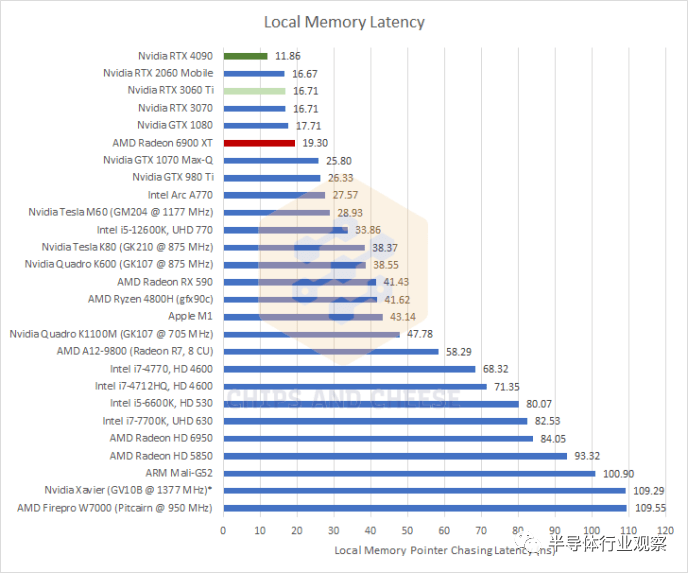
*由于时钟斜坡非常缓慢,Nvidia Xavier 的测量可能不准确 与 Ampere 相比,Ada Lovelace 在本地内存延迟方面提供了不错的改进,从而扩大了 Nvidia 在 RDNA 2 上的领先优势。这里需要注意的是,Nvidia 的两种架构都使用单个 128 KB 的 SRAM 块作为 L1 缓存和本地内存。该架构可以通过改变标记 SRAM 的数量来提供 L1 高速缓存和本地内存大小的不同组合。相比之下,AMD 为每个 CU(WGP 的一半)使用 16 KB 的专用 L0 矢量缓存,以及 128 KB 的专用本地内存。这意味着 Nvidia 在实践中将拥有更少的本地内存容量。
计算
试图确定每个周期、每个 WGP 的吞吐量数据是一种令人沮丧的练习,因为很难确定 GPU 运行的时钟速度。我们还需要调查 Nvidia 的 Ampere 和 Ada Lovelace 架构是否在我们的指令速率测试中做了一些奇怪的事情,这很难,因为我也不拥有。 至少据我们所知,Ada Lovelace 的表现很像 Ampere。常见 FP32 操作(如加法和融合乘法加法)的延迟保持在 4 个周期。用于比较的 RDNA 2 对这些操作有 5 个周期延迟。 总结各种操作的吞吐量特征:
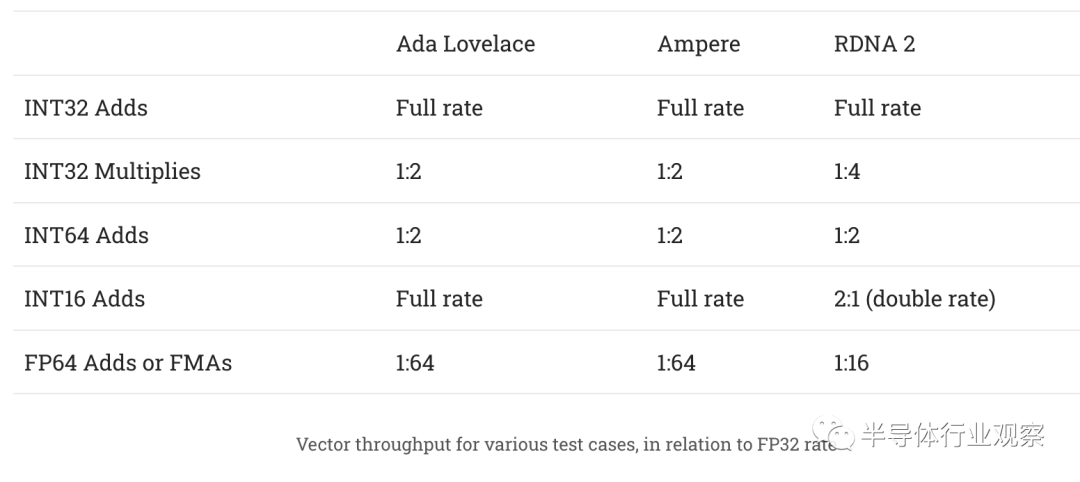
RDNA 2 还以双倍速率执行 FP16 操作。根据 Ada 白皮书,Ampere 和 Ada Lovelace 可以以 1:1 的速率执行 FP16,但我们无法验证这一点,因为 Nvidia 卡都不支持 OpenCL 的 FP16 扩展。
Atomics延迟
与 CPU 非常相似,现代 GPU 支持原子操作以允许线程之间的同步。OpenCL 通过 atomic_cmpxchg 内在函数公开这些原子操作。这是我们可以在 GPU 上进行的最接近内核到内核延迟测试的方法。跟游戏有关系吗?可能不会,因为我从未见过在游戏着色器代码中使用这些指令。但是测试有趣吗?是的。 与 CPU 不同,GPU 具有不同的atomic指令来处理本地和全局内存。本地内存(共享内存或 LDS)上的原子应该完全包含在 SM 或 WGP 中,因此应该比全局内存上的原子快得多。如果我们想稍微扩展一下,本地内存上的原子延迟大致相当于测量 CPU 内核上兄弟 SMT 线程之间的内核到内核延迟。
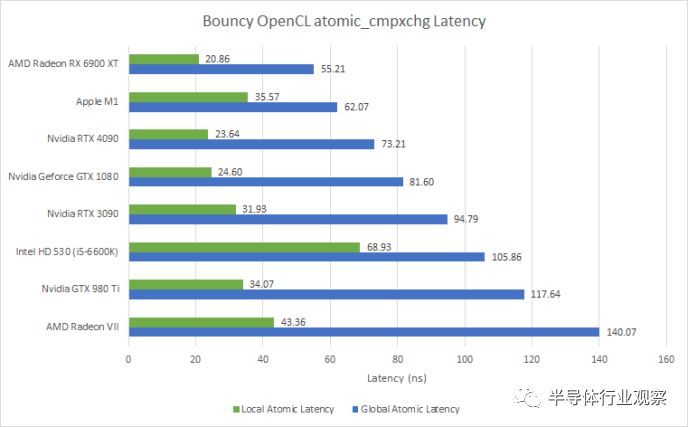
Ada Lovelace 在这里提供了对 Ampere 的增量改进,这在很大程度上可能是由于更高的时钟速度。AMD 的 RDNA 2 在这项测试中表现非常出色。从绝对意义上说,有趣的是 GPU 上的“核心到核心”延迟如何与 Ryzen CPU 上的跨 CCX 访问相媲美。
最后的话
审核编辑 :李倩
-
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践2025-06-12 2414
-
NVIDIA RTX 4500 Ada与NVIDIA RTX A5000的对比2025-03-05 5932
-
RTX 5880 Ada Generation GPU与RTX™ A6000 GPU对比2024-04-19 7092
-
NVIDIA发布两款新的专业显卡RTX A1000、RTX A4002024-04-18 6871
-
COMPUTEX2023 | 为加速生成式 AI 而设计的 NVIDIA Grace Hopper 超级芯片全面投产2023-05-30 1937
-
CES | NVIDIA Ada 架构和40系列GPU引入笔记本电脑,RTX 4070 Ti 显卡,以及创作者重大更新2023-01-06 1971
-
全新 NVIDIA RTX Enterprise 驱动程序支持最新的 RTX 6000 Ada 架构 GPU,助力改进图形工作流2022-12-27 2933
-
盘点历代NVIDIA GPU架构命名背后的行业先锋2022-10-26 1622
-
NVIDIA Ada Lovelace架构的NVIDIA RTX 6000工作站GPU2022-09-22 2555
-
曝料称NVIDIA RTX 40系列由台积电代工2020-12-29 6577
-
NVIDIA下一代GPU曝光:5nm Lovelace、Hopper被延后2020-12-21 2486
-
NVIDIA火热招聘深度学习/高性能计算解决方案架构师2017-08-25 5534
全部0条评论

快来发表一下你的评论吧 !
