

优化OpenVINO模型效能:参数设定影响实测
电子说
描述
三年前刚接触OpenVINO的时候,开始感觉机器学习发展的生态似乎有许多的转变,随着执行许多范例的过程中,渐渐了解Open Model Zoo的Github支持了许多可以下载的模型,有种感觉是不是模型加载与使用,会变成即插即用的状态。
以前要自己看许多论文,花时间搜集各种模型的执行方法,今年实验的模型,过一阵子想再执行时常会忘记如何使用,就算记得但碰到模型本身运作环境升级,或者平台不再支持某个方法,辛苦弄完的模型跟写好的程序又要重新再来一次,这样的感觉在接触OpenVINO之前,会觉的似乎是做机器学习的无奈与必然。
接触OpenVINO后,让人感觉是一个有趣的环境,过去在教学现场很难与学生介绍机器学习要怎么学跟用,虽然有云端的架构可以直接运作准备好的教学环境,实际现场要使用时,还是会碰到不知道如何安装跟配置的问题。
虽然一般的安装文件尝试尽可能写清楚了,但其实许多操作系统环境差异,或开发工具包兼容性的状态,常会造成这个月可以执行的模型跟架构,过几个月又开始不太支持,还好这两年容器环境相对更成熟,系统安装的生态也开始发生转变,透过容器化技术许多套件安装的流程跟问题,也随着容器化技术得到缓解。
本文尝试从两个观点出发,第一个是如何能够较为方便快速使用OpenVINO,主要的目的是介绍容器化的方式使用OpenVINO,相对过去需要阅读大量安装文件,目前已经有较为成熟稳定的容器化环境可以直接安装与启动OpenVINO。
第二个是了解如何利用OpenVINO跟Open Model Zoo所提供训练好的模型,在运作OpenVINO的过程,透过不同参数设定值,观察系统预测效率的改变,对于机器学习运作环境,除了程序设计技巧与架构整合外,累积模型运作与不同参数设定状态下需要具备的观念。
相对于操作系统调校的观念,在OpenVINO运作时可以观察系统在模型运作时预测效能的变化,这个部份可做为后续使用模型时经验的提升,在机器运作时累积更好的模型使用经验,观察同一台机器运作OpenVINO时,可以思考与注意的部份。
透过容器化技术快速部署OpenVINO运作环境
透过容器启动OpenVINO,可以快速方便的达成OpenVINO上线状态,相对省下非常多套件安装过程的时间,过去常认为要执行机器学习推论的环境会很复杂,或者需要许多步骤的执行过程。透过Docker容器的架构来执行OpenVINO,可以将过去系统在操作系统不同版本间运作环境产生问题的数量降低,大量减少系统除错、兼容性测试与环境安装配置的问题与步骤。
本文使用的运作环境是Ubutnu20.04.2 LTS,OpenVINO的docker容器是openvino/ubuntu20_data_dev:2021.4_tgl,使用docker在Linux运作OpenVINO最大的好处是几乎没有兼容性的问题,下载之后就可以直接执行,对于要直接使用或学习OpenVINO,相对过去容易非常非常多,透过下面的指令就可以执行OpenVINO的容器环境。
如果机器上面没有docker的环境,要先安装docker容器环境,在Linux上面执行以下指令,前面的指令会先把原来的docker环境移除,如果你已经安装过docker环境,可以跳过这个步骤,直接执行下载OpenVINO docker的pull指令:
sudo aptupdate
sudoapt-get remove docker docker-engine docker.io containerd runc
sudo aptinstall curl
curl-fsSL https://get.docker.com -o get-docker.sh
sudo shget-docker.sh
sudousermod -aG docker $USER
## Needto logout or reboot to run docker as non-root user
dockerrun hello-world
上面安装好docker的容器环境以后,可以用底下的指令直接下载OpenVINO的docker环境。
dockerpull openvino/ubuntu20_data_dev:2021.4_tgl
要执行docker环境的时候,如果是使用ubuntu桌面版内建的vnc环境,可以使用底下的指令来启动OpenVINO docker环境,这样之后在docker环境内如果需要使用到窗口环境,会比较方便做后续的测试。
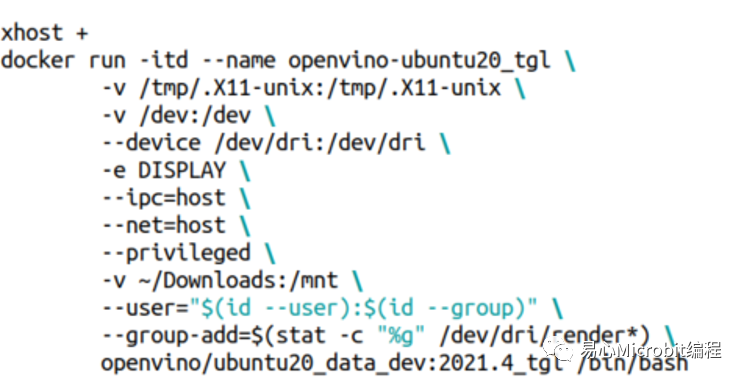
要进入docker环境下命令测试OpenVINO时,可以使用底下的指令,就可以顺利的在ubuntu桌面环境下同时使用多个OpenVINO docker环境终端做测试。
dockerexec -it openvino-ubuntu20_tgl /bin/bash
参数设定在模型运作时效能的变化
OpenVINO效能量测工具名称为benchmark_app,可以在机器上量测模型的执行效能,OpenVINO 2021.4的benchmark_app提供许多参数设定,另一个思考方向是自己写程序加载模型时,实际的效能是如何,或者日后如何能在自己写的程序达到测试环境相同的效能,如常用的ssd模型在执行object model zoo的范例时,运作过程中可以设定许多参数,例如nireq、nthreads、nstreams等,device参数可以设定运作的硬件环境CPU、GPU、同时使用CPU与GPU的MULTI: CPU,GPU等,令人好奇这些参数之间实际运作的情况,在运作过程中要如何设定,或者朝哪个方向去思考调整会有相对较好的执行结果。
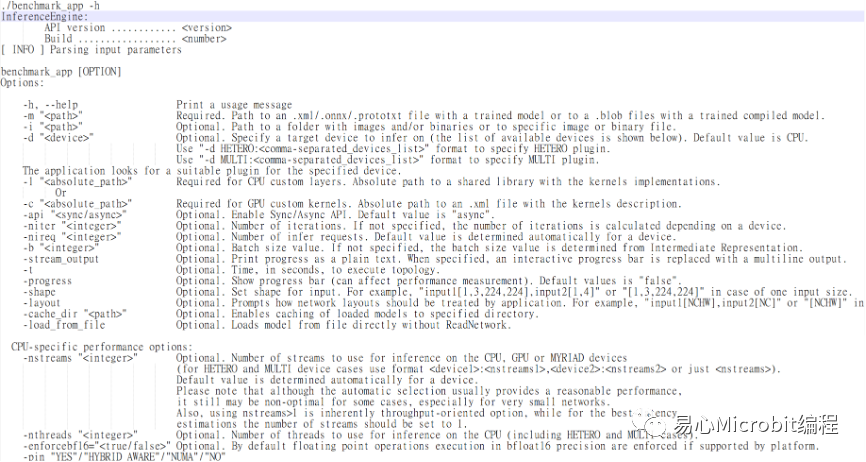
图1 – OpenVINO效能评估程序benchmark_app提供的部份参数
benchmark_app提供许多参数进行效能量测,相对当执行范例程序时,nireq、nthreads这样的参数做调整,会观察到什么结果,以下说明一些纪录与观察过程,同时可以更了解OpenVINO在docker环境下执行的方式。
在docker环境中包含OpenVINO2021.4.582的执行版本,并且提供许多模型运作范例,在Open Model Zoo中内含Object_sample_ssd的范例,内含models.lst档案。表1为models.lst档案里面支持部份的ssd模型列表,跟过去版本最大差异是多了-at参数设定,在models.lst中说明各种模型对应-at参数的设定值。
使用模型的时候可以使用download.py下载模型,如果下载的不是OpenVINO的IR格式(附档名为.xml与.bin),需要透过convert.py转换成OpenVINO的IR格式。
OpenVINO系统目录内定会安装在/opt/intel/openvino,内含子目录deployment_tools/open_model_zoo/demos/object_detection_demo/python,此目录主要为对象侦测的python范例程序,可以执行许多机器学习开发架构已经训练好的模型,包含 centernet、ctpn、faceboxes、ssd、yolo、yolov4等机器学习框架所训练好的对象侦测模型。
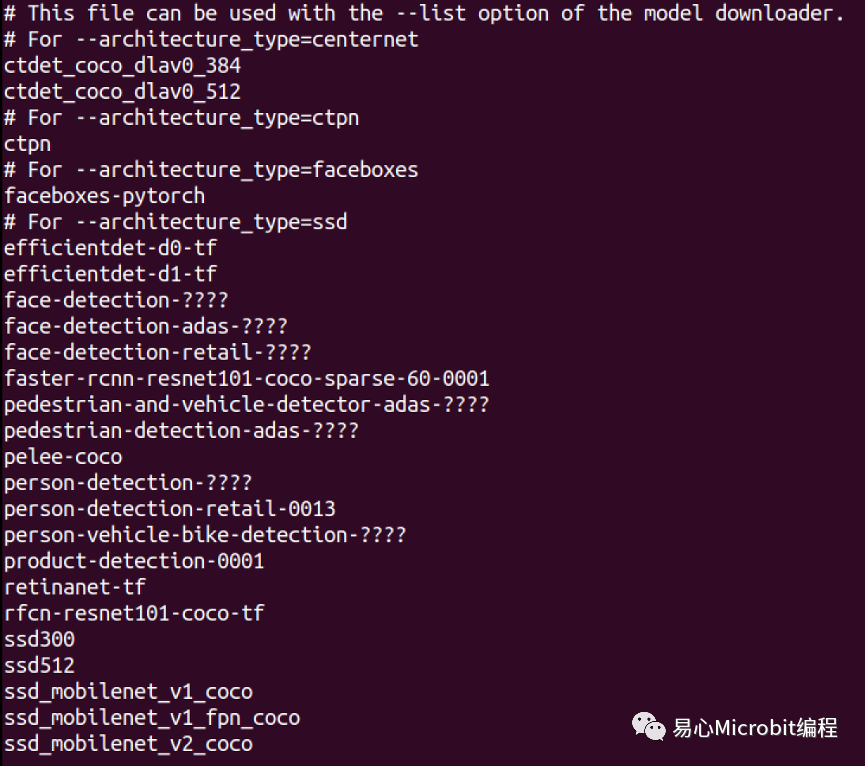
表1 – OpenVINOobject_detection_demo可以执行的机器学习模型
参数与预测效能之间的观察
两年前刚学习使用OpenVINO的时候,有很多时候觉得模型会动就好了,但是有些时候希望效能能够变快一点,尝试把某些参数调大,但是又感觉好像不是这样,本文透过object_detecion_demo运作观察,参数设定过程如何影响模型在同一台机器上推论效率的变化,接下来的内容为观察到的现象,可以作为日后模型推论在配置时参数设定的一些参考。
这两年间比较有趣的变化是同一个模型有FP32、FP16、FP16-INT8的版本可以选择,因此同一个模型在内存空间的使用量、运作效能以及预测的精确度,有许多部份可进一步观察运作过程中的变化。
本文针对object_detection_demo.py指令的参数,在执行person-detection-retail-0013模型中进行效能量测,分别就FP32、FP16、FP16-INT8等模型格式,在CPU、GPU、CPU+GPU的硬件条件下,分别进行不同的nireq以及nthreads参数设定,观察FPS(Frame per second)变化情形进行描述与讨论。
要注意的是本文所使用的是M.2 Key MSSD硬盘作为结果输出装置,用一般的USB随身碟作为预测档案结果输出时,会影响档案输出的效能,进而影响效能观察的结果。
在本文效能量测的结果呈现前,要注意的是FP16-INT8模型的运作方式,OpenVINO中POT套件转换FP16模型为INT8模型的方式,是经由在FP16模型各层间插入INT8格式的FakeQuantize,对于设定不同的POT模型优化参数, FakeQuantize将会自动调整的INT8的模型数值,或删除一些不需要的模型计算步骤,在可以满足精度要求的状态下,达成模型运作时真正的转换为INT8低精度模型,虽然层数相对可能会增加,但是因为INT8所需空间较小且执行效能相对快很多,因而能够获得真正的模型空间缩小与效能提升。
因此在FP16-INT8模型的运作过程中,透过了FP16与INT8整数运算于不同层之间的切换的运算过程,如果许多的FP16层级被转换为INT8,有机会得到储存空间的较小模型及较快速指令周期的推论效能。同时INT8的运算过程于i7第11代CPU中因为支持了AVX512的指令集,以及i7第11代所使用的内显GPU支持INT8运算处理,因此在本文量测的结果中FP16-INT8的效能将大幅度相对提升s。
object_detection_demo.py程序执行的参数如下:
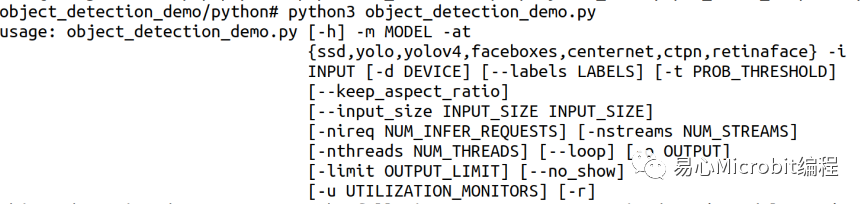
指令执行的参数常用的范例如下:
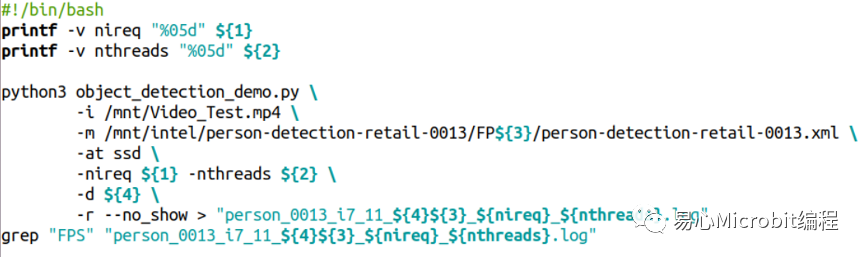
其中${1}、${2}分别代表nireq与nthreads的参数设定值,${3}表示32、16、16-INT8等设定值,${4}代表使用的是CPU、GPU、MULTI:CPU,GPU等设定值,透过这些设定值的更改,最后将执行过程输出至各个条件的文本文件,范例程序执行结束时,于各文本文件的尾端会得到此次执行的FPS数值结果,最后以这个FPS数值作为相关的量测效能结果进行讨论,详细的参数设定值说明如表2。
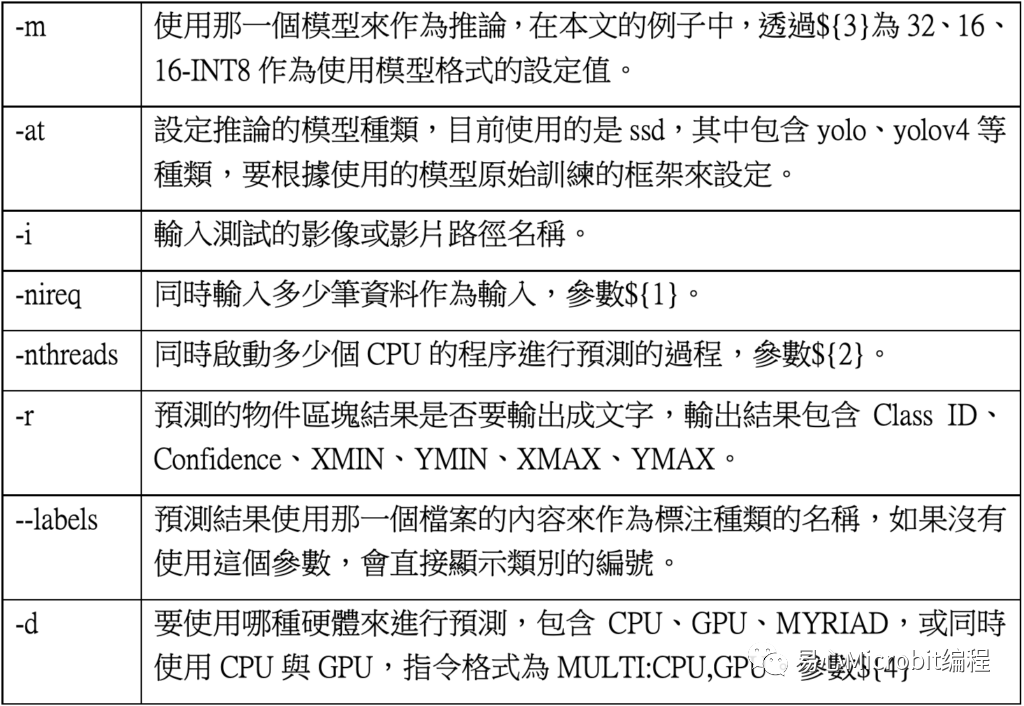
表2 –object_detection_demo.py相关的参数设定说明
本文量测数值使用之硬件环境
图2为本文以东擎NUCBOX-1165G7工业用计算机,硬件环境为Intel i7第11代CPU,软件环境使用Ubuntu 20.04.2 LTS为操作系统,执行OpenVINO 2021.4.582作为系统量测的运作环境,CPU型号为11th Gen Intel(R) Core(TM) i7-1185G7E @ 2.80GHz、cache 12288KB,共有8个Hyper-threading,内存为16GByte、硬盘型号为KINGSTON OM8PDP3256B-A01(NVM容量256GByte)。
特别要说明的是Intel第11代Core CPU内建的GPU,是第一个可以执行INT8的内建GPU,利用这个特性在执行OpenVINO时可以获得更好的效能提升。

图2 – 本文量测使用之工业用计算机,内含Intel第11代CPU与Wifi-6无线网络芯片
CPU执行person-detection-retail-0013模型效能变化情形
图3为CPU使用person-detection-retail-0013FP32模型的执行结果,可以观察当nireq(nr)为1、nthreads(nt)为1时,每秒钟可以辨识的画面张数为35.1 FPS(每秒钟能预测35.1张影像),进一步调整nireq、nthreads参数的数值进行预测,会发现nireq(nr)与nthreads(nt)设定不同数值时,会影响每秒所能预测的FPS效能。
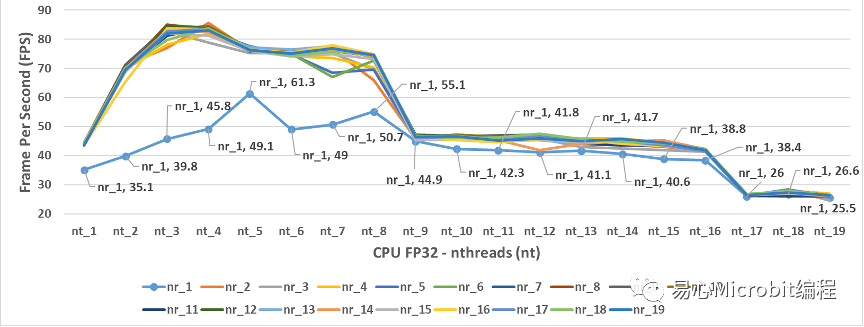
图3 – CPU执行person-detection-retail-0013FP32模型结果
图3中可以观察到一个现象,当nthreads设定的值为3时,会得到相对最高的FPS结果,图4为将图3放大之后,由nthreads(nt)数值为2到8的设定值,分别在不同的nireq(nr)条件下,nireq(nr)数值为3到8的执行结果。
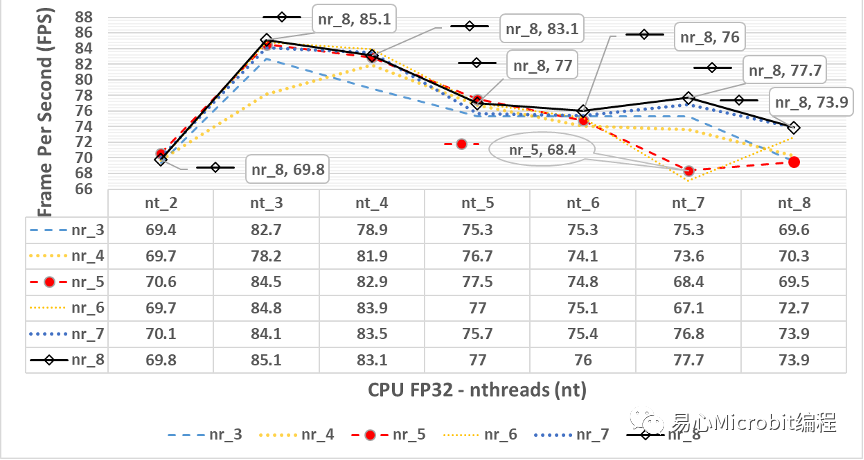
图4 – CPU执行person-detection-retail-0013.xmlFP32模型,nthreads(nt)数值为2到8、nireq(nr)为3到8的FPS变化情形
由图4中可以观察到当nthreads设定值为3、nireq等于8,CPU执行FP32模型FPS此时为85.1 FPS,之后无论nthreads与nireq调整为其他数值,执行结果都无法超过此FPS,一般概念上会认为同时输入的影像稍微多一点比较好,因为同时处理多一点影像,在机器有能力响应的状态下,执行结果的效能相对应该会高一些,从这个观点得到的FPS为nthreads为3与nireq为8时,表示一次输入8张影像时,同时使用3个CPU的处理程序来处理person-detection-retail-0013模型的运作过程,会有较好的执行效能。
图4同时显示如果我们认为将nireq与nthreads的值设的越大越好可以得到更好的效能,结果显示并不会有这样的状态产生,甚至当nthreads(nt)为19时,不管nireq(nr)设定多大的值,会发现此时约为25.1FPS,这样的执行效能相对nthreads(nt)为3时的85.1 FPS,相当于只能得到最高效能的1/3执行效率,可以观察到很明显的,单纯将nthreads与nireq值调大,只会效能更差而不会变好。
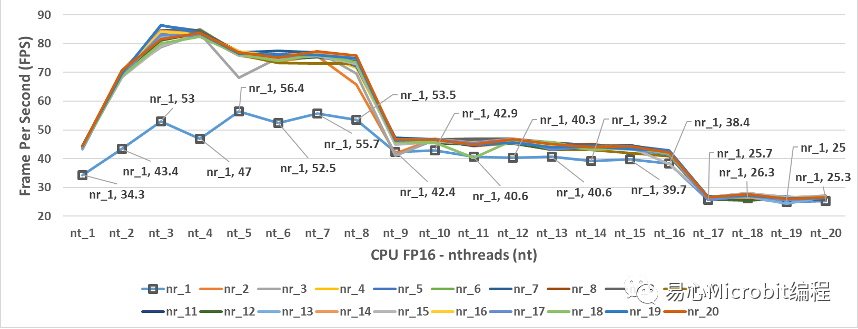
图5 – CPU执行person-detection-retail-0013FP16模型效能的变化情形
图5为CPU执行person-detection-retail-0013FP16模型的结果,相对CPU执行FP32模型效能的情形,观察图3与图5可以发现最高的FPS都约为86 FPS,图3与图5的效能变化非常相似,这个状态显示CPU在FP32与FP16的执行具有相同的效能变化趋势,nthreads为9时同样会有一个很大的效能下降,原因与执行环境所采用的硬件有关,本文章所使用硬件为i7第11代核心,包含4核心共8个Hyper-threading,发现nthreads分别在9与17的设定值时,会产生一个相对陡降的FPS结果。
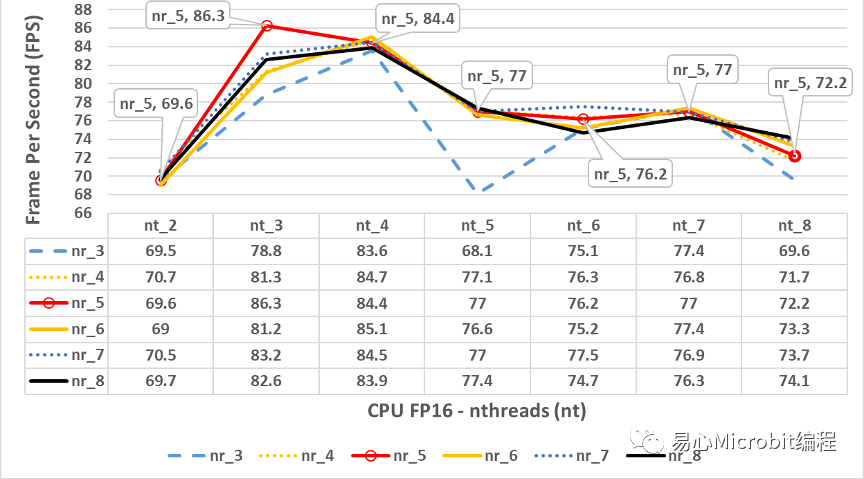
图6 – CPU执行person-detection-retail-0013FP16模型效能的变化情形,nthreads(nt)数值为2到8、nireq(nr)为3到8的FPS变化情形
由图6中会发现最高效能的值虽然在nthreads为3的时候,但是相对的此时的nireq为5,与图4的nireq为8的情况并不同,此种最佳效能点的差异在各个模型选用时,可以再针对不同的nireq的数值做最后的量测进行寻找最佳参数点。
观察CPU执行FP32与FP16的模型效能变化状态后,图7中为CPU模式执行person-detection-retail-0013FP16-INT8模型的结果,当nthreads(nt)设定的值为4、nireq(nr)等于20,量测范围中最高的效能为116.5 FPS,很明显的相较于FP32条件下最高为86 FPS高出许多。
从图7中也可以观察到nireq等于1,每次输入1个影像,可以发现nthreads为4时,最高的效能为68.3FPS,无论nthreads设定多大,预测的FPS效能也无法提升,从这个结果可以观察到,就算是硬件有很大的效能,nireq控制同时输入数据的数量,nireq太小相对也会影响整体工作效能。
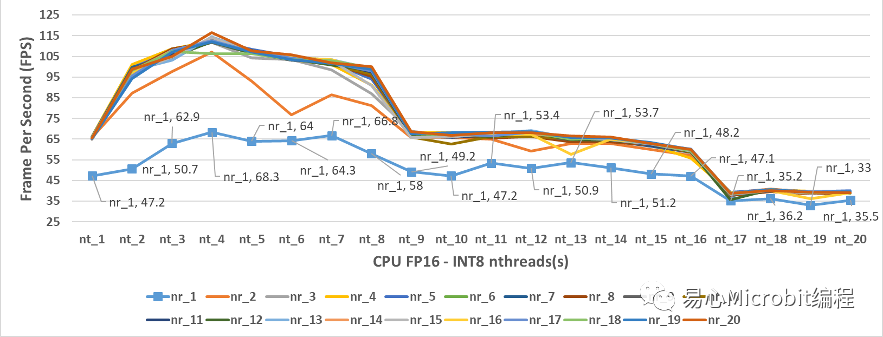
图7 – CPU执行person-detection-retail-0013FP16-INT8模型效能的变化情形
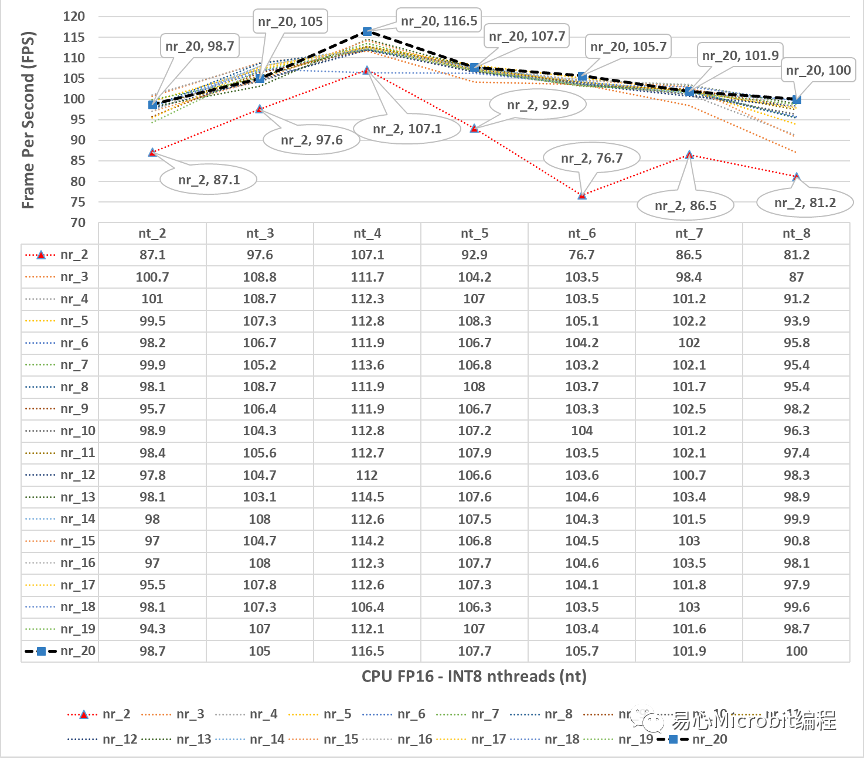
图8 – CPU执行person-detection-retail-0013FP16-INT8模型效能的变化情形,nthreads(nt)数值为2到8、nireq(nr)为2到20的FPS变化情形
图8为图7详细的变化情形,可以观察到当nthreads(nt)的数值是4的时候,nireq设定值大于等于3之后,相对每秒可以执行推论的影像效能,相对高于其他的nthreads数值的推论效能,可以很明显的感觉在CPU执行FP16-INT8的条件下,CPU的核心数量、nthreads设定数值,与推论效能最高点较为一致,进一步要注意的是,虽然印象上FP16-INT8执行效率相对会好很多,可是同样的在nthreads为9的时候,一样会有很大的效能陡降现象出现,在模型实际上线运作时候,需要先注意到这样的现象对应于所使用的硬件运作条件(如核心数量、最大的Hyper-threading数量)。
GPU执行person-detection-retail-0013模型效能变化情形
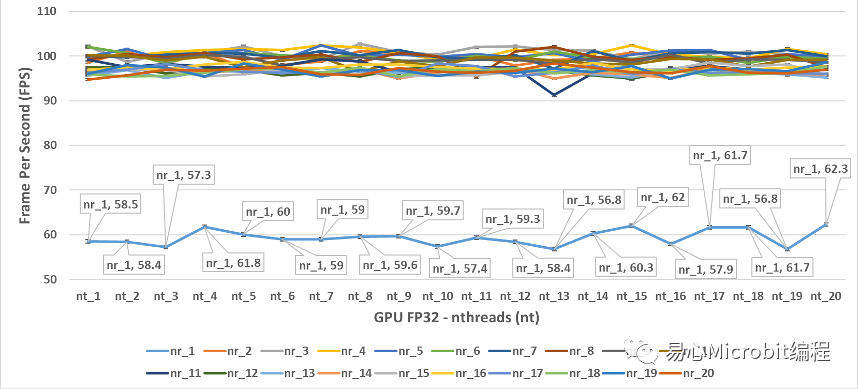
图9 – GPU执行person-detection-retail-0013FP32模型效能的变化情形
图9为GPU执行person-detection-retail-0013FP32模型效能的变化情形,相对CPU的运作状态,以nthreads的形式为横轴坐标轴时,会观察到nireq为1的时候,系统的运作效能相对是最低的,nireq大于1以上很明显FPS效率好很多,有趣的情况是将图9转换坐标轴,以nireq作为横轴的状态下,可以得到图10的结果,此时会发现有趣的现象,当nireq大于3之后,在nireq持续增加相当于不断的将同时输入的影像数量提高时,在同样的nthreads的情况下,GPU执行FP32模型的状态,效能其实会持续降低。
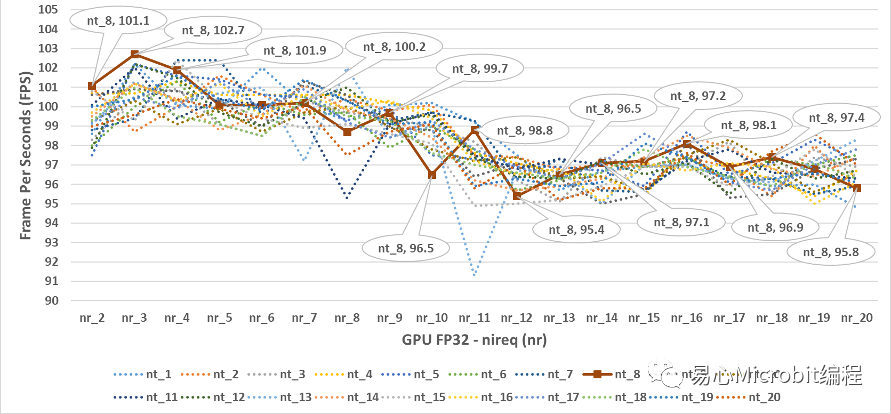
图10 – GPU执行person-detection-retail-0013FP32模型效能的变化情形
由图10的结果可以得到一个概念,在单纯使用GPU状态下执行FP32模型的时候,同时输入影像的数量增大并没有帮助,GPU执行FP32的效能最高为102.7FPS,相对CPU执行FP32的效能为86 FPS的状态下,单纯使用GPU执行FP32模型对于单独CPU执行FP32模型约为1.18倍的效能,相对另一个有趣的状态是,nthreads设定的数值超过8之后,似乎在单纯GPU执行FP32模型的状态下似乎对于推论效能不会有太大的影响,似乎此时设定nthreads的值,没有真正的对应多个CPU核心运作的效能。
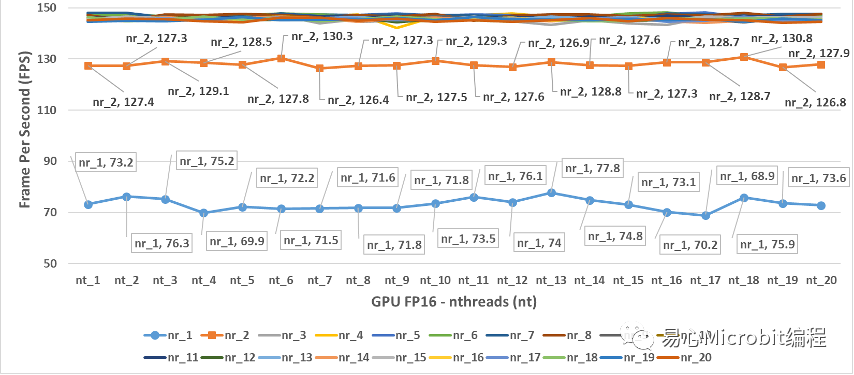
图11- GPU执行person-detection-retail-0013FP16模型效能的变化情形
图11为GPU执行person-detection-retail-0013FP16模型效能的变化情形,由图11的结果可以得到一个概念,在单纯使用GPU状态执行FP16模型的时候,nireq在小于3的状态下,GPU相对的执行效能并没有达到满载的状态,相对GPU执行FP32模型效能最高为102.7FPS,很明显GPU 在执行FP16模型nireq等于2时就已经接近130 FPS。
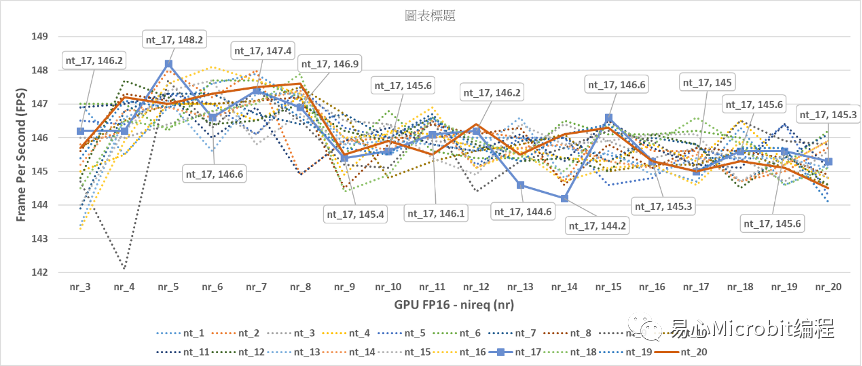
图12- GPU执行person-detection-retail-0013FP16模型,显示nireq(nr)为3到20,nthreads(nt)为1到20的效能变化情形
由图12的结果可以观察到,当GPU执行nireqperson-detection-retail-0013 FP16模型,最高的效能在nireq为5、nthreads(nt)为17此时为148.2FPS,相对在FP32的GPU与CPU运作条件下已有大幅度性能提升,可以观察到nireq大于等于5之后效能会微幅的下降,nthreads的设定值大小对于效能的影响并不算太明显,总结来说nireq大于3、nthreads设定值不论是多少,效能都会大于140FPS。
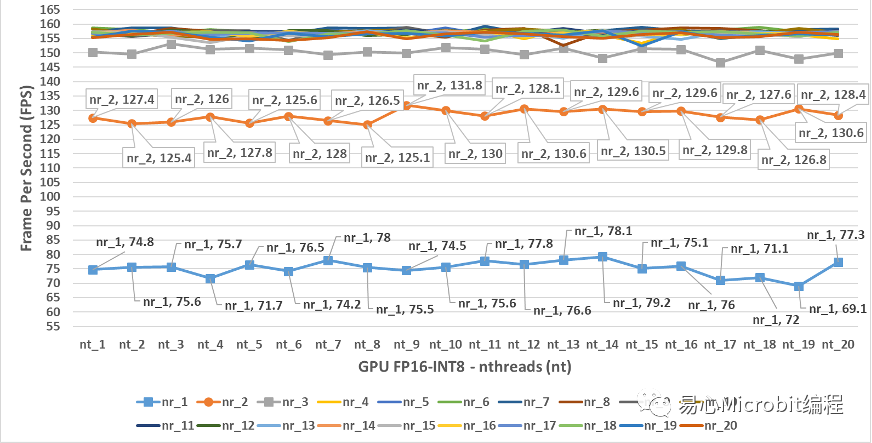
图13 – GPU执行person-detection-retail-0013FP16-INT8模型效能变化
图13为GPU执行person-detection-retail-0013FP16-INT8模型效能变化,与GPU执行person-detection-retail-0013 FP16模型比较时,会发现GPUFP16-INT8之nireq为1与2时,执行的FPS与GPU FP16时nireq为1与2的结果相当,而nireq为3时,执行效能与GPU执行FP16模型的最高FPS相当,进一步的当nireq持续增加大于5时,nthreads无论是哪种数值,均可达到150FPS以上,此结果显示GPU执行FP16-INT8的效能相对在CPU与其他的GPU模式下,有着非常高的FPS执行效率。
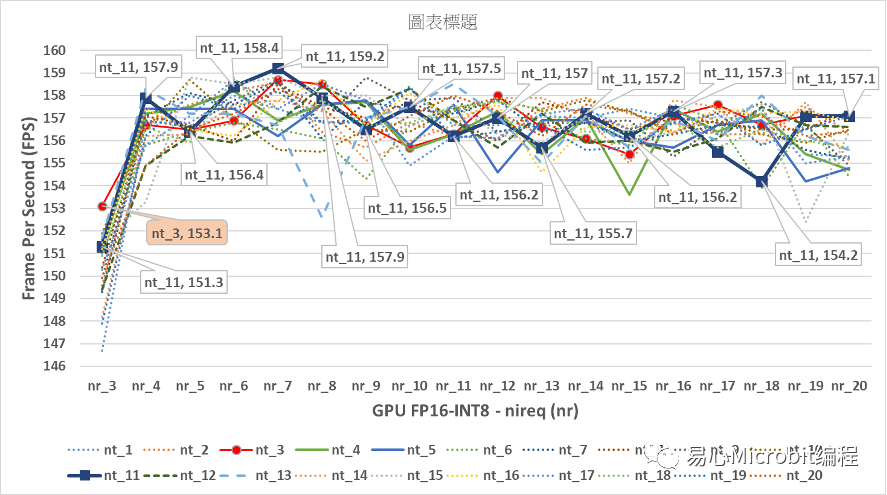
图14 – GPU执行person-detection-retail-0013FP16-INT8模型效能变化
由图14的结果可以观察到GPU执行person-detection-retail-0013FP16-INT8模型效能,与GPU执行nireq person-detection-retail-0013 FP16模型比较时会发现,最高效能为nireq为7、nthreads(nt)为11,此时效能为159.2FPS,明显高于GPU执行FP16模型的148.2FPS的效能。
CPU+GPU执行person-detection-retail-0013模型效能变化情形
图15的结果可以观察到CPU+GPU执行person-detection-retail-0013FP32模型效能的变化,要注意的是OpenVINO在同时使用CPU与GPU运作时,nthreads最大的数值在使用本硬件时只能设定到7,超过8之后会显示只能最大设定到7的讯息,nthreads超过8之后就会显示会将nthreads 自动设定为7进行预测,因此CPU+GPU同时运作的环境,nthreads的量测结果只有1到8的范围,而nireq维持1到20的设定值。另外,在运作的参数-d中,采用的设定值是MULTI:GPU,CPU,这样的条件下会将输入数据优先派送GPU,之后再给CPU进行处理。
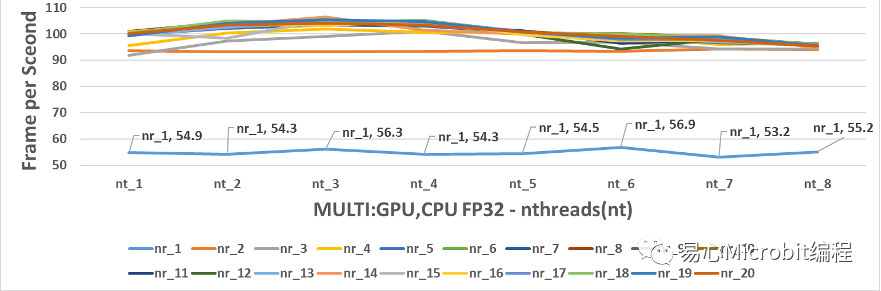
图15 – CPU+GPU执行person-detection-retail-0013FP32模型效能变化
图15的结果可以观察到CPU+GPU执行person-detection-retail-0013FP32模型效能的变化,与单纯使用GPU执行nireq person-detection-retail-0013 FP32模型比较时,将图15放大为图16,会发现最高的效能为nireq为14、nthreads(nt)为3,此时效能为106.4FPS,综合图15与图16并且比较单纯 CPU执行FP32的模型时,当nireq大于3时,nthreads持续增加效能同样无法继续提升。
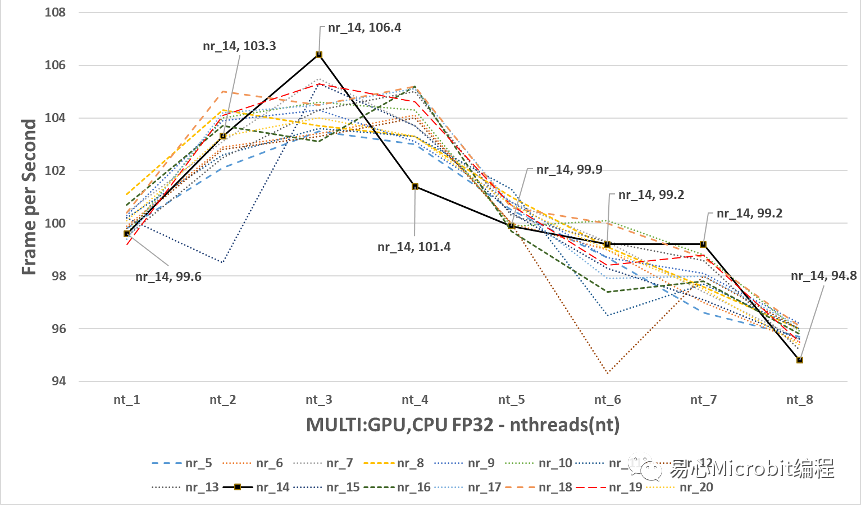
图16 – CPU+GPU执行person-detection-retail-0013FP32模型,nireq由5到20,nthreads由1到8的效能变化
图16的结果会发现CPU+GPU执行FP32模型最高的106.4FPS,与CPU执行FP32的最高85.1FPS相比多了约20FPS,另一方面如果与单纯GPU执行FP32模型最高95.3FPS相比,大约多10FPS。因此可以得到CPU+GPU的执行person-detection-retail-0013 FP32的模型的状态下,为FP32模型下最高的执行效能(106.4FPS)。
因此如果要求预测精度为FP32,能够预期最好的FPS会在106附近。(nthreads设定为3、nireq设定为14、运作装置为MULTI:GPU,CPU)。
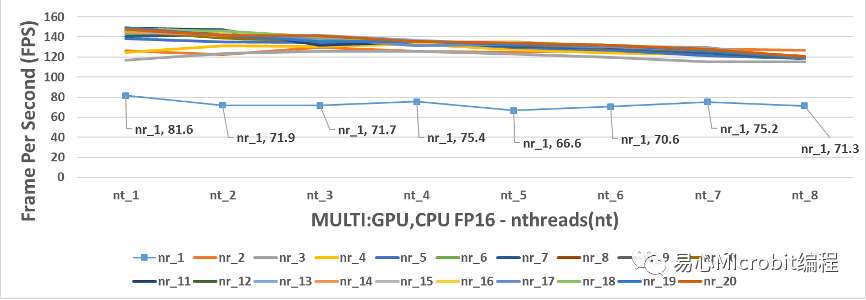
图17 – CPU+GPU执行person-detection-retail-0013FP16模型效能变化
相对图CPU+GPU执行FP32的结果,图17与18为CPU+GPU执行person-detection-retail-0013F16模型效能的变化。图18中显示nthreads为1的状态下,nireq为11与19时分别为149与149.5FPS,这两个数值都非常高,但是由图18会发现与单纯GPU执行FP16的模型(图12)有着几乎相同的最高执行FPS,同时nthreads持续变大时FPS呈现持续下降,这种结果呈现CPU+GPU执行FP16模型的情况下,GPU与CPU+GPU执行的最高效能似乎非常接近。
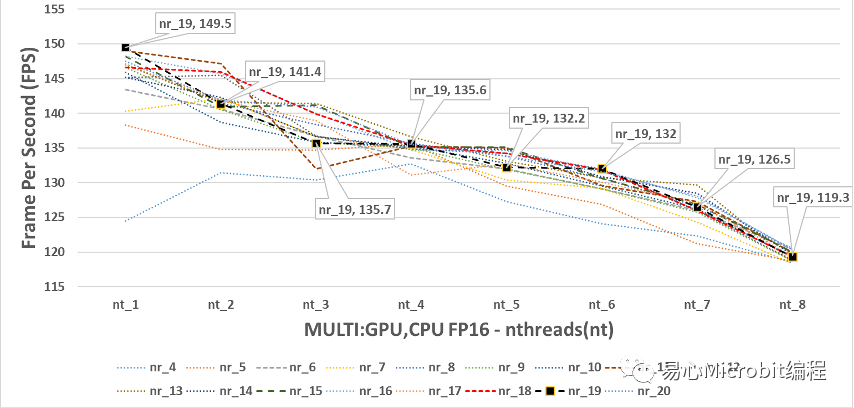
图18 – CPU+GPU执行person-detection-retail-0013FP16模型,nireq由4到20,nthreads由1到8的效能变化
进一步的回头观察CPU执行FP16模型最高为86.3 FPS,由此也可以发现单纯执行GPU或GPU+CPU执行FP16的效能,约提高1.73倍的效率,每秒钟多63FPS。我们可以从上述的观察中发现,GPU的运作环境下,其实nthreads为1的效能就是最好的状态,至于nireq要设定多少,如果在不能够有太多延迟画面时间输入的状态下,建议一次输入6张数据以上会有不错的整体预测输出效能,推论速度可以到140 FPS以上。
最后来看图19中,显示GPU+CPU执行FP16-INT8的模型状态,会发现在nireq小于5的情形下,最高的预测效能都无法大于160FPS,可以明显的看到,当nthreads为1、nireq大于5的条件下,观察FPS效能会发现nireq为14、nthreads为1的状态下,可跑出176.9FPS的最高效能,此效能值相对也是CPU、GPU、CPU+GPU执行FP16-INT8状态下最高的结果。
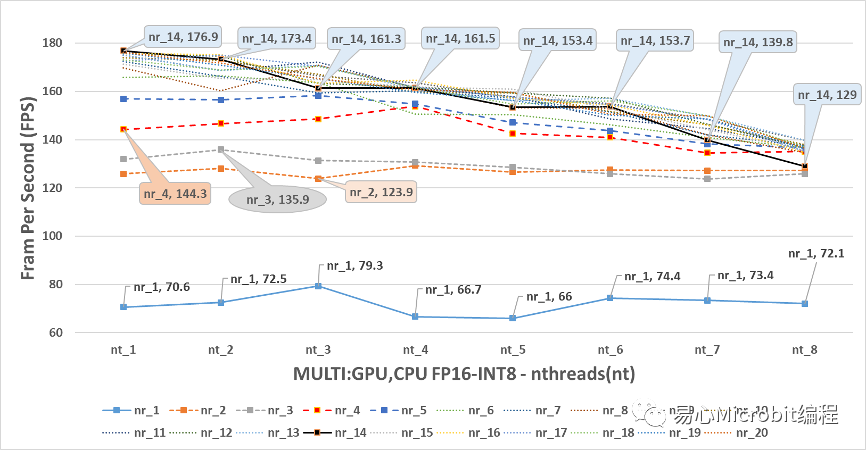
图19 – CPU+GPU执行person-detection-retail-0013FP16-INT8模型效能变化
进一步讨论CPU+GPU执行FP16-INT8的结果,会发现其实随着nthreads的增大,在nthreads由2到8之间,其实对nireq为1到5以下似乎没有变快的效果,另外在nireq为6到20的情况下,在nthreads大于1之后,明显的预测的效能不升反将,推想这种情形发生的原因在于nireq其实也是需要CPU的执行资源,当把nthreads增大的时候,CPU的资源被瓜分至进行预测处理的后续工作的部份,然而实际上从数据执行结果的现象观察,似乎只要nthreads设定为1,让其他的CPU专心的进行数据读取的动作把数据喂给GPU,然后CPU只需要用1个核心,专心的把GPU预测完的结果进行后续的处理,这样的协同状态下的工作组合,就可以达到很高的效率了。
结论
将目前观察到的结果做一个总结,你的机器上面如果只有CPU,当然的状态只能执行CPU运作FP32、FP16、FP16-INT8模型,FP16与FP32的模型在CPU模式下有同样的效能,主要是系统会先将FP16转换成FP32之后执行,要注意的是nthreads的值不能设定超过核心的Hyper-threading的最大总数量,否则会有效能陡降的情形。
本文目前测试的模型显示nthreads的数量设定在CPU的核心数量减1,这个时候的CPU预测效能会是最好的状态,当然部份的时候也可以试试看nthreads的数值设定与CPU的核心数量一样,因为nthreads的数值超过CPU核心数目之后,FPS就只会变慢而不会变快了。
如果你的机器上面有Intel GPU的显示芯片,目前许多桌上型机器内建Intel GPU显示芯片,过去只能用来作为显示适配器使用,其实这时可以将这样的机器作为机器学习预测使用,在本文中所测试的状态,单纯使用GPU实际上有着非常好的运作效能,如果需要维持预测精准度又不希望占用CPU的运算效能,可以单纯使用GPU执行FP32模型,相对已经可以快过单纯使用CPU执行FP32预测的效能。
最后如果你可以提供机器全部的效能进行机器学习的预测,在这样的状态CPU+GPU同时协作,如果你使用的机器学习模型在FP16-INT8的状态下可以维持预测的精确度,则使用CPU+GPU的状态下,运作FP16-INT8将大幅度提升预测的FPS效率,相对CPU FP32格式的模型,CPU+GPU执行FP16-INT8相当于在同一台机器上获得2倍的预测效能。
后记
初学者透过MakerPRO系列文章可以学习OpenVINO操作,本文描述了参数调整的概念如何的影响OpenVINO模型上线时注意的事项,希望能够让系统上线运作模型时,有一定比较清楚要注意的观念。
本文并没有提及如何将模型换成FP16-INT8,以及使用benchmark_app比较FP32、FP16、FP16-INT8的结果,benchmark_app内定可以使用随机值作为输入,并单纯的测试硬件计算效能对应模型推论的FPS结果。最后,对于多摄影机、多模型同时运作在OpenVINO的状态,之后有机会再分享了。
审核编辑:汤梓红
-
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?2025-07-11 440
-
请问使用2022.2时是否可以读取模型OpenVINO™层?2025-03-06 307
-
为什么无法在运行时C++推理中读取OpenVINO™模型?2025-03-05 490
-
C#集成OpenVINO™:简化AI模型部署2025-02-17 3103
-
C#中使用OpenVINO™:轻松集成AI模型!2025-02-07 2166
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2969
-
自训练Pytorch模型使用OpenVINO™优化并部署在AI爱克斯开发板2023-05-26 1892
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 12036
-
OpenVINO模型优化实测:PC/NB当AI辨识引擎没问题!2022-12-09 3537
-
ORCAD 电感参数设定问题2018-03-29 6155
全部0条评论

快来发表一下你的评论吧 !
