

卷积神经网络是实现深度学习的重要方法之一
人工智能
描述
上一篇机器学习中的函数(4) - 全连接限制发展,卷积网络闪亮登场 ,我们理解到可以通过卷积进行特征提取,卷积之后我们通过池化层(又称亚采样层),我们可以降低数据规模,进一步完善特征提取和数据整理的工作,找到了这种“高效的执行特征抽取”的网络,卷积神经网络(CNN)终于登场了,卷积神经网络是实现深度学习的重要方法之一。我们今天一起从学习强大的卷积神经网络开始,继续走近“深度学习”。
1、典型的卷积神经网络(CNN)
典型的卷积神经网络通常(如下图)由若干个卷积层(Convolutional Layer)、激活层(Activation Layer)、池化层(Pooling Layer)及全连接层(Fully Connected Layer)组成,各个层各司其职,卷积层从数据中提取有用的特征;激活层在网络中引入非线性,通过弯曲或扭曲映射,来实现表征能力的提升;池化层通过采样减少特征维度,并保持这些特征具有某种程度上的尺度变化不变性;在全连接层实施对象的分类预测。
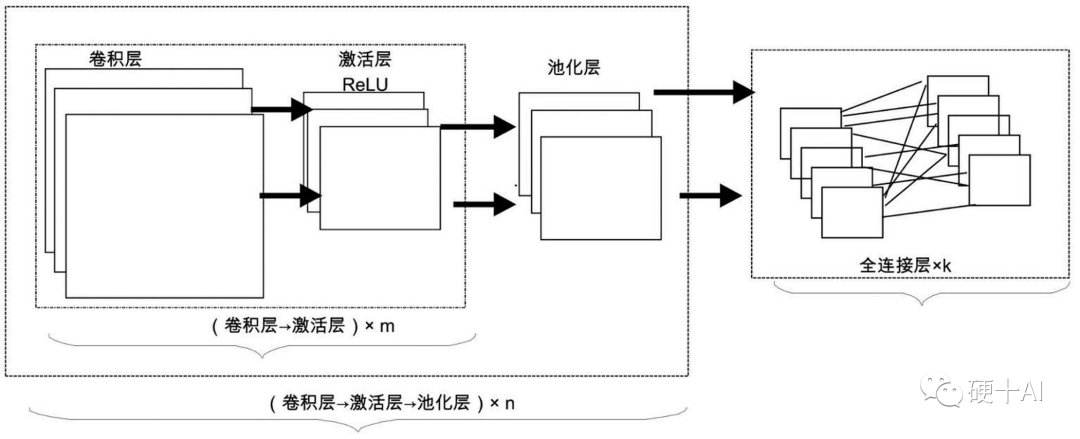
卷积层:这是上一篇我们重点介绍的,卷积神经网络的核心,决定卷积层(ConvNet)空间排列的4个参数,它们分别是卷积核的大小(通常多是3×3或5×5的方矩阵、深度(卷积核的个数)、步幅及补零。
激活层:其作用在于将前一层的线性输出,通过非线性的激活函数进行处理,这样用以模拟任意函数,从而增强网络的表征能力。在深度学习领域,ReLU(Rectified-Linear Unit,修正线性单元)是目前使用较多的激活函数,主要原因是它收敛更快。激活层存在的最大目的莫过于引入非线性因素,以增加整个网络的表征能力。
池化层:也将其称为子采样层或下采样层(Subsampling Layer),“采样”就意味着可以降低数据规模。通常来说,当卷积层提取目标的某个特征之后,我们都要在两个相邻的卷积层之间安排一个池化层,池化就是把小区域的特征通过整合得到新特征的过程。
全连接层:这层网络层相当于多层感知机,其在整个卷积神经网络中起到分类器的作用,通过前面多个“卷积-激活-池化”层的反复处理,待处理的数据特性已显著提高 ,输入数据的维度已下降到可用传统的前馈全连接网络来处理了,而且结果经过反复提纯后,输出的分类品质要高得多。实际应用中,通过前面的层层堆叠,将输入层导入的原始数据逐层抽象,形成高层语义信息,送到全连接层做分类,这一过程便是“前馈运算”(Feed-forward)。全连接层将其目标任务(如分类任务)形式化表达为损失函数,(参考机器学习中的函数(2)- 多层前馈网络巧解“异或”问题,损失函数上场优化网络性能 )。通过计算得到误差或损失(loss),然后再通过机器学习中的函数(3) - "梯度下降"走捷径,"BP算法"提效率 讲到的反向传播算法(即BP),将误差逐层向后反馈(Back-forward),从而更新网络连接的权值。多次这样的“前馈计算 ->反馈更新”,直到模型收敛。此时,一个CNN模型就训练完成了。
2、经典的AlexNet神经网络
深度学习历史上,AlexNet当属经典中的经典,AlexNet出现之前,深度学习已经沉寂良久,终于在2012年,辛顿(Hinton)和他的博士生(Alex Krizhevsky)等提出了AlexNet,并一举拿下当时ImageNet比赛的冠军。相比于前一年的冠军,Top-5的错误率一下子下降了10个百分点,远远超过当年的第二名(26.2%),可见其功力非同一般,从而也确立了深度卷积神经网络在计算机视觉领域的统治地位。Alexnet强化了典型CNN的架构,应用到更深更宽的网络中,由于它的出现,人们更加相信深度学习可以被应用于机器视觉领域,点燃了深度学习的热情,深度学习很快进入了一个繁荣期。
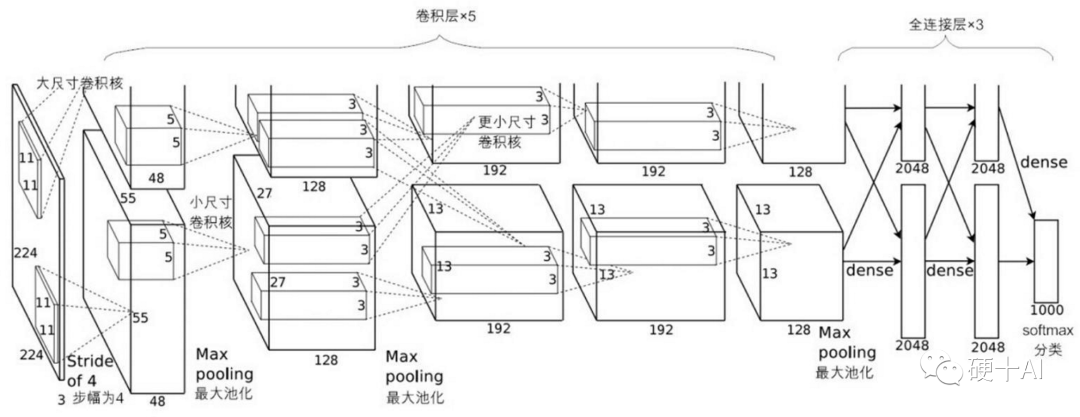
AlexNet除了在网络架构上的优化外,它还提出了几项很酷的技术,包括
成功应用了ReLU激活函数,虽然非AlexNet的原创,最早(2000年)在《自然》(Nature)中的一篇文章中就被提出来了,但真正能发挥神奇功效、并被世人所知的时间节点,还要当属它在AlexNet中的成功应用。
成功使用了Dropout机制,在AlexNet中的最后几个全连接层,Dropout都被用来减轻过拟合。
成功使用了重叠的最大池化(Max pooling),传统的CNN通常使用平均池化,而AlexNet全部使用最大池化避免了平均池化带来的模糊化效果。
成功使用GPU加速训练过程,并开源了CUDA代码,以前Yann LeCun等人之所以止步,就是CNN受限于当时计算机硬件的“算力”,而从这个时代开始,深度学习快速进入“暴力计算”时代。
3、深度学习的核心就是"深度"
故事说到这里,我们再回头认识一下深度学习(Deep Learning)。深度学习是人工神经网络研究不断深化的产物,其概念最早由辛顿(Geoffrey Hinton)等人于2006年提出(就是我们在机器学习中的函数(3) - "梯度下降"走捷径,"BP算法"提效率 中提到的那位通过推动BP算法优化,“吻”醒了沉睡多年的人工智”大神,也是上文说到的参与提出AlexNet的牛人),针对深度学习他的核心理念有两个。
第一:多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类。
第二:深度神经网络在训练上的难度,可以通过无监督学习实现的“逐层初始化”来有效克服。
神经网络发展到这个阶段,通过一步步加深把学习的性能提升到另一个高度,学习的层次多了、学习的套路也深了。从实现上,深度学习神经网络就是一种包括多个隐含层(越多即为越深)的多层感知机,它通过组合低层特征,形成更为抽象的高层表示,用以描述被识别对象的高级属性类别或特征。具备“自生成数据的中间表示”的能力,是深度学习区别于其他机器学习算法的独门绝技,虽然这个表示并不能被人类理解,因此也有工程师把深度学习比喻为“机器炼丹”。
再展开讨论一下,深度学习的“深”就是指层数多,相比深度学习,其他的许多机器学习就是浅层学习(比如曾经火热过一段时间的SVM),因为它们并没有多层的深架构。目前的深度学习网络已经有百层甚至千层结构了,这种多层的架构允许后面的计算建立在前面的计算之上,这使得网络能够学习到更多的抽象特征,特征提取(feature extraction)就是深度学习网络安身立命的基本功,无论是深度置信网络(DBN),还是卷积神经网络(CNN),都是多隐层堆叠,每层对上一层的输出进行处理,就是在做输入信号进行逐层加工,从而把初始的、与输出目标之间联系不太密切的输入表示,转化成与输出目标联系更密切的表示,使得原来仅基于最后一层输出映射难以完成的任务成为可能。换言之,通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。深度学习网络通过向网络展示大量有标记的样本来训练网络,通过检测误差并调整神经元之间连接的权重来改进结果,重复该优化过程以创建微调后的网络,一旦部署之后,就可以利用这种优化后的网络来评估没有标记的样本。
这个看深度学习看起来无比强大,但为什么深度学习网络直到这十多年才火热起来呢?从理论上来说,参数越多的模型复杂度越高、容量越大,这意味着它能完成更复杂的学习任务。但实际使用时,复杂模型的训练效率低,易陷入过拟合,因此难以受到人们青睐。而随着云计算、大数据时代的到来,计算能力的大幅提高可缓解训练低效性,训练数据的大幅增加则可降低过拟合风险。因此,以深度学习为代表的复杂模型开始受到人们的关注。不得不感叹深度学习生逢其时,当有了大数据和大算力的支持时,深度学习终于能登上舞台中心了。到2015 年,CNN 首次在物体识别挑战中击败了人类,展示了它强大的潜力。
4、CNN、RNN、GAN等深度学习方法各显神通
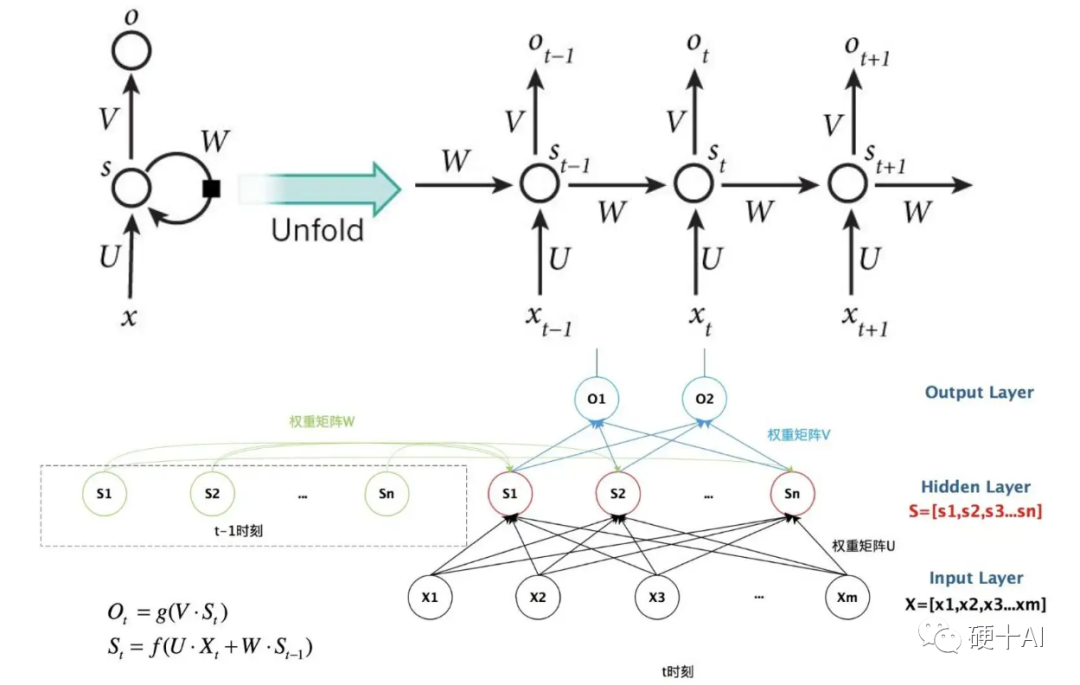
卷积神经网络是实现深度学习的重要方法之一,但它也不是能包揽所有应用的,我们再一起看一下目前在深度学习领域有以下几个类别 (1)卷积神经网络(CNN,Convolutional Neural Network),破译图像的神器:这是我们最近一起学习的重点,它利用卷积和池化把关键特征提取出来进行处理,就是相当于考试之前的复习划重点,学习效率大大提高了。 (2)循环神经网络( RNN,Recurrent Neural Network),洞悉语言的内涵:传统的神经网络很少考虑输入信号在时间上的联系,但是现实中很多问题都是一个时序分析问题,例如语言文字分析问题,思考一个词在句子中的含义,那么必然要考虑上下文语境的影响。因此循环神经网络就是在传统神经网络的基础上加入了时序分析的能力,就相当于帮助学生将前面所学的知识点和现在所学的知识点放在一起分析,从而在时间上形成系统的知识体系。参考下图,加入时间元素的神经网络。
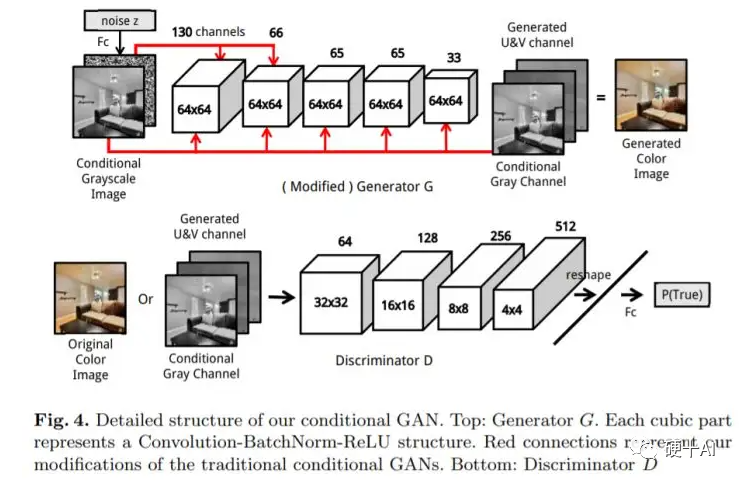
(3)生成对抗网络(GAN, Generative Adversarial Network),引入对抗,棋逢对手:生成对抗网络是在深度学习中产生的一种全新的学习框架。它包括了一位出题者(生成器Generator)和解题者(判别器Disciminator),出题者希望出一道解题者无法解出来的难题,所以他需要不断学习努力提高,使得出的题目越来越难,而解题者也在不断学习,尽力解出出题者出的难题。两者不断博弈,出题者的水平越来越高,题目也越来越难,解题者也不断学习,结题的水平也在提高,最终两者共同进步,出题者(生成器)和解题者(判别器)的知识和能力都不断增强。
到这里,经过三周时间,我们从神经网络的起点“激活函数和感知机”,走到“用多层前馈网络解决异或问题”,“用损失函数优化网络性能”,然后再前进到针对不断变得复杂的网络我们“用BP算法提升效率”,“用卷积核强化特征提取”,最后我们跟随经典的卷积神经网络,终于触摸到了深度学习。
编辑:黄飞
-
卷积神经网络的基本结构及其功能2024-07-02 5147
-
详解深度学习、神经网络与卷积神经网络的应用2024-01-11 3964
-
卷积神经网络概述 卷积神经网络的特点 cnn卷积神经网络的优点2023-08-21 4817
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2598
-
什么是神经网络?什么是卷积神经网络?2023-02-23 5290
-
卷积神经网络模型发展及应用2022-08-02 13375
-
卷积神经网络CNN介绍2020-06-14 2265
-
卷积神经网络—深度卷积网络:实例探究及学习总结2020-05-22 3510
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 4250
全部0条评论

快来发表一下你的评论吧 !
