

间隔校准算法Margin Calibration来了!
描述
长尾视觉识别任务对神经网络如何处理头部(常见)和尾部(罕见)类之间的不平衡预测提出了巨大挑战。模型倾向于将尾部类分类为头部类。虽然现有的研究侧重于数据重采样和损失函数工程,但在本文中,我们采用了不同的视角:分类间隔。我们研究了间隔(margin)和预测分数(logit)之间的关系,并凭经验观察到「未校准的边距和预测分数呈正相关」。我们提出了一种「简单而有效的边距校准方法 (Margin Calibration,MARC) 来校准边距以获得更平衡的预测分数」,从而提升分类性能。我们通过对常见长尾基准(包括 CIFAR-LT、ImageNet-LT、Places-LT 和 iNaturalist-LT)的广泛实验来验证MARC。实验结果表明,我们的MARC方法在这些基准上取得了良好的结果。此外,「只需三行代码」就能实现MARC。我们希望这种简单的方法能够激发人们重新思考长尾视觉识别中未校准的边距与预测分数之间的关系。
文章已被机器学习会议ACML 2022录用, 由东京工业大学、微软STCA、南京大学、及微软亚洲研究院共同完成,第一作者为东京工业大学王一栋同学。
论文:https://arxiv.org/abs/2112.07225

间隔与预测分数的关系
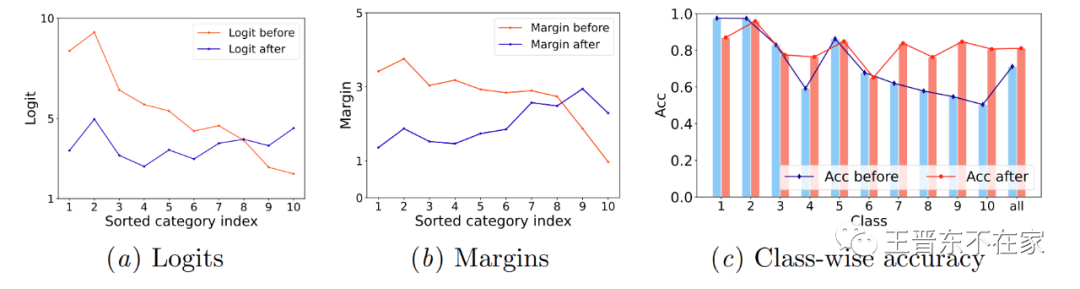
在本文中,我们研究了「间隔(Margin)」和「预测分数 (logits)」之间的关系,这是主导长尾绩效的关键因素。
如下图所示,我们凭经验发现边距和预测分数与每个类的基数相关(一个类的基数即该类别拥有数据的数量)。具体来说,在校准之前,头类往往比尾类具有更大的边距和预测分数。因此,需要校准这种不平衡的边距以获得平衡的预测分数去避免未校准的边距对分类性能产生负面影响。
间隔校准方法MARC: Margin Calibration
我们提出一个简单的间隔校准方法「MARC (margin calibration)」来解决长尾问题。
具体而言,我们训练了一个简单的特定于类别的边距校准模型,其中原始边距固定, 和 是可学习参数:
的推理公式如下,最终是由预测分数(logit=)除以线性分类器(Linear Classifier Head)的权重(Weight)的模()取得,其中为线性分类器的偏差(bias):
因此,校准后的预测分数为
其中是固定的原始预测分数。
此外,我们还对不同类进行加权操作,最终通过训练 和 来获得更平衡的预测分数。
核心算法:仅需三行代码
MARC可以被分类为决策边界(间隔)调整算法,其与之前的一些同类算法如Decouple (ICLR'20, 评论区提到的)和DisAlign等的区别如下:

MARC的核心算法如下图所示,核心部分如红框所示。「仅需三行代码」即可实现MARC:

实验
分类结果
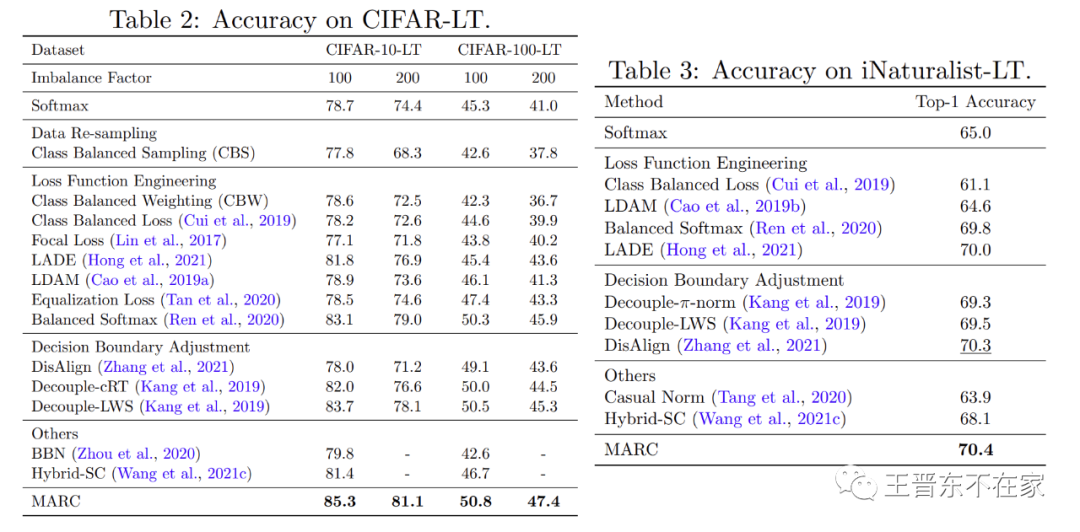
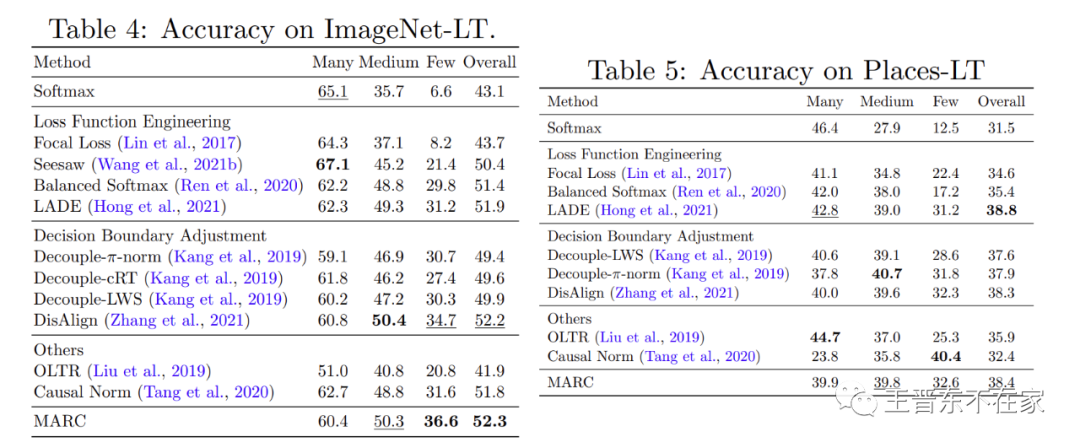
实验表格如下。我们在众多被广泛使用的长尾分类图像数据集中进行了对比。从实验结果可以看出MARC相比于其他方法取得了良好的性能,并且MARC十分容易实现。
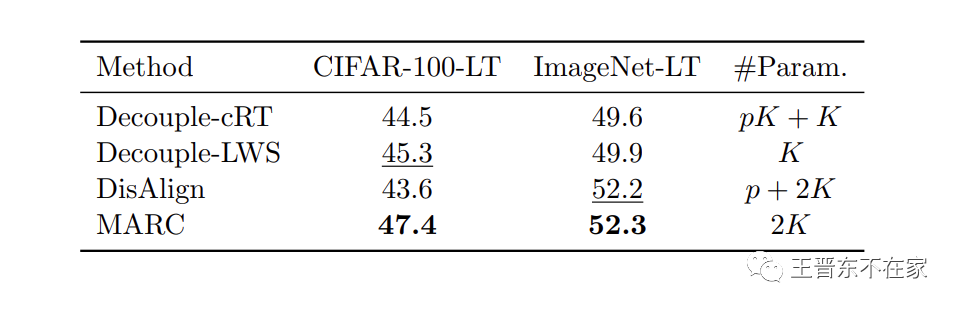
复杂度
下图是MARC和另一个决策边界调整算法Dis-Align的对比试验,可以发现MARC取得了更平衡的边距和预测分数。
总结
本文研究了长尾视觉识别问题。具体来说,我们发现头类往往比尾类具有更大的边距和预测分数。受此发现的启发,我们提出了一个只有 2K(K是类别数)可学习参数的边距校准函数,以获得长尾视觉识别中的平衡预测分数。尽管我们的方法实现起来非常简单,但大量实验表明,与以前的方法相比,MARC在不改变模型表示的情况下取得了有利的结果。我们希望我们对预测分数和边距的研究能够为模型表示和边距校准的联合优化提供经验。未来,我们的目标是发展一个统一的理论来更好地支持我们的算法设计,并将该算法应用于更多的长尾应用。
Reference
[1] 本文所介绍的论文:Wang et al. Margin calibration for long-tailed visual recognition. Asian Conference on Machine Learning (ACML) 2022.
审核编辑 :李倩
-
是否必须使用SOLT校准校准电缆2019-05-09 1796
-
PLTS中DUT不同的校准问题2019-07-15 2150
-
波形发生器33210A精度规格在1年校准间隔后无效2019-07-31 1650
-
KiCad中的Edge.Cut与Margin层2023-06-06 6354
-
Digital calibration makes auto2010-07-04 1476
-
仪表校准程序(Meter Calibration Procedures)2011-02-06 1159
-
基于MMSE的触摸屏应用多点校准算法2011-11-28 855
-
CALIBRATION相机标定模块2015-12-10 997
-
【英文教程】Calibration and Operating Characteristic 校准及运行特性2016-11-18 916
-
基于保护间隔的OFDM信号信噪比估计算法2017-01-07 765
-
基于间隔链表改进的频繁项集挖掘算法2017-12-20 898
-
ADE9000 Calibration Tool2021-02-20 871
-
ADE9078 Calibration Tool2021-03-09 781
-
深入理解Res-calibration电阻校准技术2023-06-02 4302
-
基于机器学习算法的校准优化方案2023-06-29 973
全部0条评论

快来发表一下你的评论吧 !
